

Алгоритм на псевдокоде
Алгоритм построения кода Шеннона
p0:=0, Q0:=0
DO (i=1,…,n)
Qi := Qi-1+pi
Li:= -log2pi
OD
DO (i=1,…,n)
DO (j=1,…,Li)
Qi-1:=Qi-1 *2
C[i,j]:= Qi-1
IF (Qi-1>1) Qi-1:=Qi-1-1 FI
OD
OD
Код Фано
Метод Фано построения префиксного почти оптимального кода заключается в следующем. Упорядоченный по убыванию вероятностей список букв алфавита источника делится на две части так, чтобы суммы вероятностей букв, входящих в эти части, как можно меньше отличались друг от друга. Буквам первой части приписывается 0, а буквам из второй части – 1. Далее также поступают с каждой из полученных частей. Процесс продолжается до тех пор, пока весь список не разобьется на части, содержащие по одной букве.
Пример. Пусть дан алфавит A={a1, a2, a3, a4, a5, a6} с вероятностями p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07. Построенный код приведен в таблице и на рисунке.
Таблица 12 Код Фано
ai |
Pi |
кодовое слово |
Li |
|||
a1 |
0.36 |
0 |
0 |
|
|
2 |
a2 |
0.18 |
0 |
1 |
|
|
2 |
a3 |
0.18 |
1 |
0 |
|
|
2 |
a4 |
0.12 |
1 |
1 |
0 |
|
3 |
a5 |
0.09 |
1 |
1 |
1 |
0 |
3 |
a6 |
0.07 |
1 |
1 |
1 |
1 |
4 |
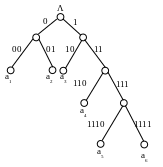
Рисунок 68 Кодовое дерево для кода Фано
Полученный код является префиксным и почти оптимальным со средней длиной кодового слова
Lср=0.36.2+0.18.2+0.18.2+0.12.3+0.09.4+0.07.4=2.44
Алгоритм на псевдокоде
Алгоритм Фано
P–массив вероятностей, упорядоченный по убыванию
L – левая граница обрабатываемой части массива P
R– правая граница обрабатываемой части массива P
k – длина уже построенной части элементарных кодов
С – массив элементарных кодов
Length – массив длин элементарных кодов.
Fano(L,R,k)
IF (L<R)
k:=k+1
m:=Med(L,R)
DO (i=L,…,R)
IF (i≤m) C[i,k]:=0, Length[i]:= Length[i]+1
ELSE C[i,k]:=1, Length[i]:= Length[i]+1
FI
OD
Fano (L,m,k)
Fano (m+1,R,k)
FI
Функция Med находит медиану массива P, т.е. такой индекс L≤m≤R, что
величина
![]() минимальна.
минимальна.
Med (L,R)
SL:=0
DO (i=L,…,R-1)
SL:=SL+p[i] <сумма элементов первой части>
OD
SR:=p[R] <сумма элементов второй части>
m:=R
DO (SL ≥ SR)
m:=m-1
SL:=SL-p[m]
SR:=SR+p[m]
OD
Med:=m
Алфавитный код Гилберта – Мура
Рассмотрим источник с алфавитом А={a1,a2,…,an} и вероятностями p1,…pn. Пусть символы алфавита некоторым образом упорядочены, например, a1≤a2≤…≤an. Алфавитным называется код, в котором кодовые слова лексико-графически упорядочены, т.е. φ(a1)≤φ(a2)≤…≤φ(an).
Е.Н. Гилбертом и Э.Ф. Муром предложили метод построения алфавитного кода, для которого Lср < H+2. Процесс построения происходит следующим образом.
Составим суммы Qi, i=1,n, вычисленные следующим образом:
Q1=p1/2, Q2=p1+p2/2, Q3=p1+p2+p3/2,…, Qn=p1+p2+…+pn-1+pn/2.
Представим суммы Qi в двоичном виде.
В качестве кодовых слов возьмем -log2pi +1 младших бит в двоичном представлении Qi.
Пример. Пусть дан алфавит A={a1, a2, a3, a4, a5, a6} с вероятностями p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07. Построенный код приведен в таблице.
Таблица 13 Код Гилберта-Мура
ai |
Pi |
Qi |
Li |
кодовое слово |
a1 a2 a3 a4 a5 a6 |
1/23≤0.18 1/23≤0.18<1/22 1/22≤0.36<1/21 1/24≤0.07 1/24≤0.09 1/24≤0.12 |
0.09 0.27 0.54 0.755 0.835 0.94 |
4 4 3 5 5 5 |
0001 0100 100 11000 11010 11110 |
Средняя длина кодового слова не превышает значения энтропии плюс 2
Lср=4.0.18+4.0.18+3.0.36+5.0.07+5.0.09+5.0.12=3.92<2.37+2