

4.2. Реализация классов
Все классы разрабатываемого модуля можно разделить на несколько функциональных групп:
классы для обучения классификатора на основе обучающей выборки (подсистема обучения);
классы для проведения экспериментов на основе тестовой выборки (подсистема для проведения экспериментов);
классы для рубрикации введенного объявления (подсистема классификации);
классы для работы трех предыдущих функциональных групп:
классы для работы с базой данных;
класс, содержащий вспомогательные функции.
На рисунке 4.2 изображена диаграмма классов разрабатываемого модуля автоматической классификации объявлений.
На диаграмме представлены не все классы, чтобы не делать ее запутанной. Классы, которые не изображены на диаграмме, имеют аналогичное строение и функциональную нагрузку с классами, которые присутствуют на изображении. Также, чтобы не делать диаграмму запутанной, у классов не указаны поля и некоторые методы.
Обучение классификатора происходит в классе StartLearning. Данный класс работает по алгоритму, описанному в пункте 2.5.
В результате в базе данных будет заполнена таблица для проведения экспериментов. Кроме того, будет выведено время обучения классификатора, которое потребуется в ходе проведения экспериментов.
Эксперименты проводятся в классе StartClassifier. Данный класс работает по алгоритму, описанному в пункте 2.5.
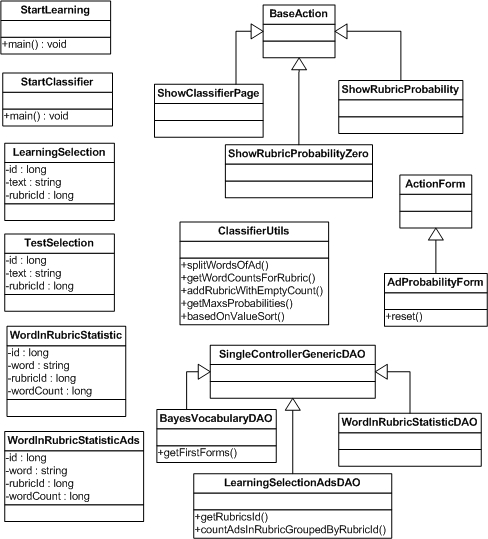
Рис.4.2. Диаграмма классов для платформы по автоматической классификации объявлений
Подсистема обучения и подсистема для проведения экспериментов взаимодействуют с базой данных через DAO-классы и фреймворк Hibernate. Описание DAO-классов будет произведено при рассмотрении классов для работы с базой данных.
Подсистема классификации введенного объявления представляет собой веб-приложение, результатом работы которого является выведенный список наиболее вероятных рубрик. Данная подсистема построена согласно архитектуре MVC:
DAO-классы и фреймворк Hibernate позволяют подсистеме работать с базой данных;
классы action-servlets выполняют функцию контроллера, то есть связывают базу данных и отображение;
jsp-страницы и класс, работающий с формой ввода данных, выполняют функцию отображения.
Подсчет вероятностей происходит в сервлетах:
ShowRubricProbability – вероятности для рубрик рассчитываются по алгоритму, согласно которому в формуле 2.2.4 в числителе прибавляется единица в случае, если слово не встретилось в документах обучающей выборки. Фрагмент кода представлен в приложении 1;
ShowRubricProbabilityZero – вероятности для рубрик рассчитываются по алгоритму, согласно которому в формуле 2.2.4 в числитель подставляется малая величина, если слово не встретилось в документах обучающей выборки. В данной реализации было взято число 0.0000000000000001. Фрагмент кода представлен в приложении 2.
Оба сервлета, которые классифицируют отдельное объявление, работают по схожему алгоритму, описанному в пункте 2.5.
После работы сервлетов полученные данные передаются на jsp-страницу для вывода. В данном случае страница bayes_ads_classifier.jsp кроме области вывода результатов содержит поле для ввода объявления, которое связано с классом AdProbabilityForm через фреймворк Struts. Таким образом, можно работать с введенным текстом как с данными из поля класса. Для такого сопоставления используется библиотека тегов struts-html. Пример использования тегов приводится ниже:
<%@ page contentType="text/html; charset=windows-1251" session="false" %>
<%@ taglib uri="struts-html" prefix="html" %>
<html:form action="/ad-probability">
<html:textarea property="adText" rows="5" cols="50"/>
<html:submit value="Показать вероятности"/>
</html:form>
Кроме того, данные на jsp-странице выводятся при помощи библиотеки тегов jstl. Пример использования jstl-тегов приводится ниже:
<%@ page contentType="text/html; charset=windows-1251" session="false" %>
<%@ taglib uri="jstl-core" prefix="c" %>
<c:forEach items="${requestScope.maxContProbsZero}" var="maxContProbZero">
<tr>
<td>
<h5><c:out value="${maxContProbZero.key}"/></h5>
</td>
<td>
<h5><c:out value="${maxContProbZero.value}"/></h5>
</td>
</tr>
</c:forEach>
Все три подсистемы работают с базой данных через DAO-классы и фреймворк Hibernate, который позволяет представлять таблицы из базы данных в объектном виде. Каждой таблице из базы данных соответствует класс в приложении. Все они устроены по одному принципу: полю из таблицы соответствует поле класса. Например, таблице «КЛАССИФИКАТОР_ИНФ_ЧАСТЕЙ» соответствует класс «LearningSelection». Соответствия «Имя таблицы->Класс» приведены в табл.4.2.1.
Табл. 4.2.1. Соответствие таблиц из базы данных и классов модуля
Имя таблицы |
Имя класса |
КЛАССИФИКАТОР_ИНФ_ЧАСТЕЙ |
LearningSelection |
КЛАССИФИКАТОР_ОБЪЯВЛЕНИЙ |
LearningSelectionAds |
КЛАССИФИКАТОР_ТЕСТ |
TestSelection |
КЛАССИФИКАТОР_СЛОВ_РУБРИК |
WordInRubricStatistic |
КЛАССИФИКАТОР_СЛОВ_РУБРИК_ОБ |
WordInRubricStatisticAds |
Кроме того, Hibernate позволяет создавать hql-запросы, которые используются в DAO-классах (классы, которые содержат методы для работы с базой данных: выборка и вставка различных данных). Пример использования hql-запроса приведен ниже:
public List<Long> getRubricIds() {
Session session = getHibernateController().getSession();
return session.createQuery("select distinct ls.rubricId from LearningSelection ls").list();
}
Соответствия DAO-классов и таблиц базы данных, с которыми работают эти DAO-классы приведены в табл. 4.2.2.
Табл. 4.2.2. Соответствие таблиц из базы данных и DAO-классов модуля
Имя таблицы |
Имя класса |
КЛАССИФИКАТОР_ИНФ_ЧАСТЕЙ |
LearningSelectionDAO |
КЛАССИФИКАТОР_ОБЪЯВЛЕНИЙ |
LearningSelectionAdsDAO |
КЛАССИФИКАТОР_СЛОВ_РУБРИК |
WordInRubricStatisticDAO |
КЛАССИФИКАТОР_СЛОВ_РУБРИК_ОБ |
WordInRubricStatisticAdsDAO |
Вспомогательные функции для работы с разрабатываемым модулем реализованы в классе ClassifierUtils. Методы данного класса приведены ниже:
public static List<String> splitWordsOfAd(String adText) — метод для разделения текста объявления на отдельные слова и отбрасывания слов, длина которых меньше трех символов и слов, полностью состоящих из цифр. Параметр adText — текст объявления. Код данного метода приведен в приложении 3;
public static List<WordCount> getWordCountsForRubric(Long rubricId, HashMap<String, Long> groupedWords) — метод, возвращающий список объектов, которые будут записаны в базу данных при обучении классификатора. Параметры: rubricId — id рубрики; groupedWords — карта, ключом которой является слово, а значением — количество вхождений слова в рубрику;
public static void addRubricWithEmptyCount(HashMap<Long, Long> groupedCount, List<Long> rubricIds) — метод, добавляющий рубрики, в обучающих объявлениях которых, ни разу не встретилось какое-либо слово. Параметры: groupedCount — карта, ключом которой является id рубрики, а значением — количество вхождений слова в рубрику;
public static HashMap<String, Double> getMaxsProbabilities(HashMap<Long, Double> probabilities, int elementsNumber) — метод, отбирающий n рубрик с максимальными вероятностями. Параметры: probabilities — карта, из которой надо выбрать n максимальных элементов; elementsNumber — количество элементов, которое необходимо выбрать. Код данного метода приведен в приложении 4;
public static HashMap<String, Object> basedOnValuesSort(HashMap<String, Double> inputMap) — метод, сортирующий карту по значениям. Парамеиры: inputMap — карта, которую необходимо отсортировать по значениям. Код данного метода приведен в приложении 5.