

2.3. Метрики оценки качества рубрицирования
Согласно РОМИП (Российский семинар по Оценке Методов Информационного Поиска), для оценки качества классификации текстов (также существуют метрики для оценки качества поиска) чаще всего используются следующие метрики [3]:
полнота (recall);
точность (precision);
аккуратность (accuracy);
ошибка (error);
F-мера (F-measure).
Данные метрики основываются на матрице классификации (табл.2.3.1).
Табл.2.3.1. Матрица классификации документов
|
Релевантны |
Не релевантны |
Найдено системой |
A |
b |
Не найдено системой |
C |
d |
В таблице описываются следующие переменные:
a – количество документов, найденных системой и релевантных с точки зрения экспертов;
b – количество документов, найденных системой, но не релевантных с точки зрения экспертов;
c – количество релевантных документов, не найденных системой;
d – количество нерелевантных документов, не найденных системой.
1. Полнота – характеризует способность системы находить нужные пользователю документы, но не учитывает количество нерелевантных документов, выдаваемых пользователю. Например, если полнота равна 50%, то это значит, что половина релевантных документов системой не найдена. Вычисляется по формуле:
![]() (2.3.1)
(2.3.1)
2. Точность – характеризует способность системы выдавать в списке результатов только релевантные документы. Например, если точность равна 50%, то это значит, что среди найденных документов половина релевантных и половина нерелевантных. Вычисляется по формуле:
![]() (2.3.2)
(2.3.2)
Аккуратность. Вычисляется по формуле:
![]() (2.3.3)
(2.3.3)
Ошибка. Вычисляется по формуле:
![]() (2.3.4)
(2.3.4)
F-мера используется как единая метрика, объединяющая метрики полноты и точности. Вычисляется по формуле:
 (2.3.5)
(2.3.5)
В случае классификации документов одним из важных вопросов построения метрик является метод усреднения результатов. Можно выделить две последовательности действий [3]:
сначала вычислить метрики по каждому запросу отдельно и затем усреднить их;
найти общее количество документов, относящихся к категориям матрицы классификации, и на их основе вычислить искомую метрику.
Первый способ принято называть макроусреднением, второй - микроусреднением. Первый способ характерен для оценки задач поиска, в которых важен результат в среднем по запросу, независимо от мощности ответа на этот запрос. Второй же способ чаще применяется в оценке классификации и фильтрации.
В рамках данной работы достаточно будет оценить полноту, точность и F-меру.
2.4. Существующие решения
На данный момент времени существует три самые известные системы контекстной рекламы:
Яндекс.Директ;
Бегун;
Google AdWords.
В каждой из этих систем предлагается автоматический подбор ключевых слов или фраз. Поэтому был проведен анализ системы подбора ключевых слов и фраз в системах контекстной рекламы «Яндекс.Директ» и «Бегун».
В ходе анализа было установлено, что обе эти системы подбирают ключевые слова аналогичными способами: пользователь вводит свое ключевое слово. После этого система предлагает список ключевых слов и фраз. Например, если ввести ключевое слово «ВАЗ», то среди предлагаемых вариантов ключевых слов находятся такие слова как:
для «Яндекс.Директ»: тойота/toyota, nissan, рено, киа, мерседес.
Также были выведены и другие наименования марок иностранных автомобилей (рисунок 2.3.1);
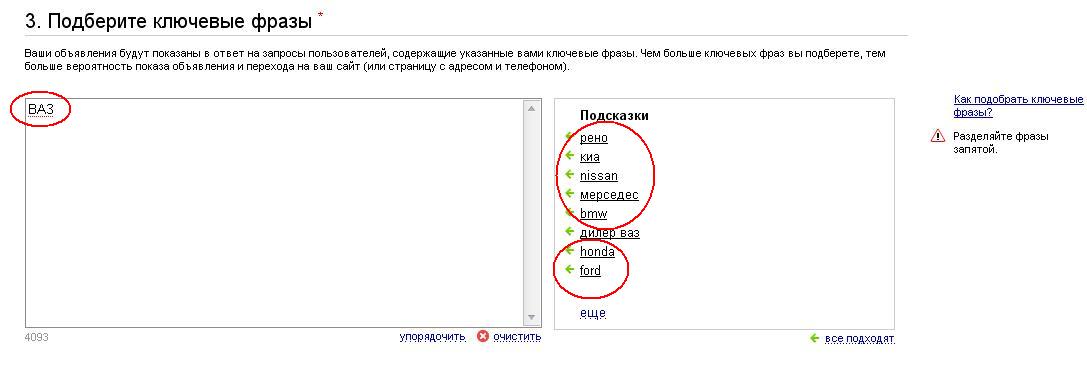
Рис.2.3.1. Подобранные ключевые слова в системе контекстной рекламы «Яндекс.Директ»
для «Бегун»: nissan, toyota, honda, mitsubishi.
Также были выведены и другие наименования марок иностранных автомобилей (рисунок 2.3.2).
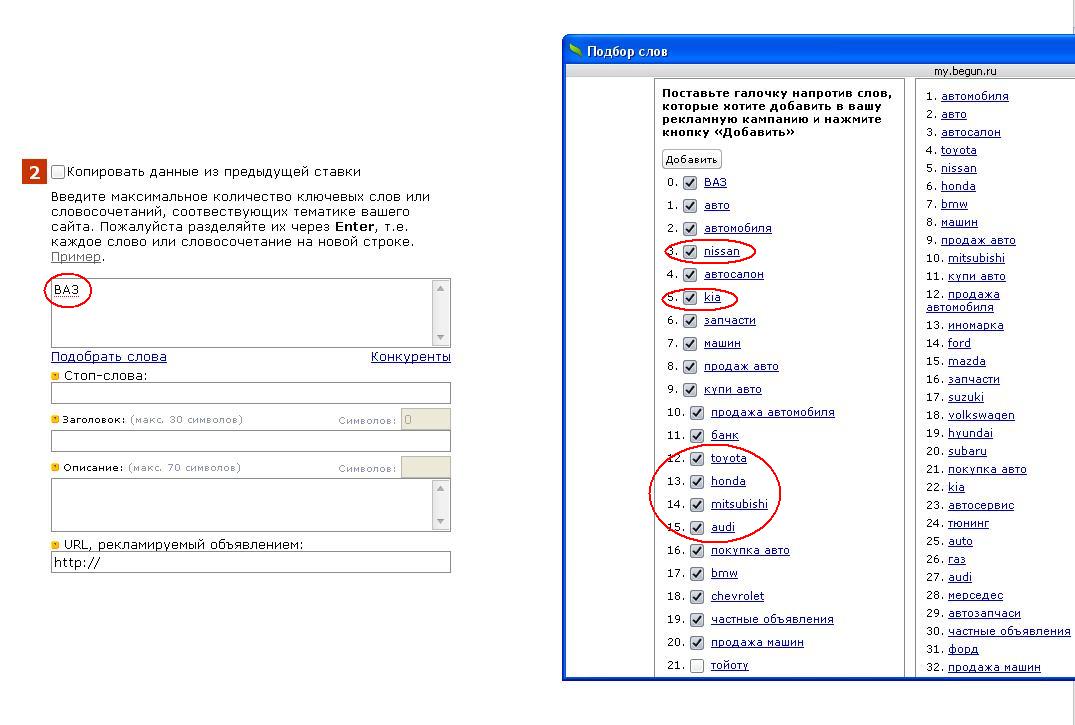
Рис.2.3.2. Подобранные ключевые слова в системе контекстной рекламы «Бегун»
С одной стороны, такой результат может показаться странным: Для слова «ВАЗ» подобраны названия иностранных автомобилей. Вероятность того, что потенциальный покупатель, который в строке запроса вводит слово «мерседес», передумает покупать иномарку и предпочтет «ВАЗ» очень мала. С другой стороны, подбор ключевых слов и фраз в данных системах также основан на статистике. И, добавляя ключевые слова, которые на первый взгляд абсолютно не подходят для объявления, заказчик может увеличить число просмотров своего объявления.
Для анализа способа подбора ключевых фраз в системе контекстной рекламы «Google AdWords» была использована подробная документация по работе с данной системой. В ходе анализа было выявлено, что система подбора ключевых слов работает в «Google AdWords» аналогично с ранее рассмотренными системами.
Подобный подбор ключевых слов и фраз не подходит для системы контекстной рекламы «Камелот.Контекст». Основная причина этого в том, что в разрабатываемой системе подбор ключевых слов и фраз должен основываться не на введенных пользователем ключевых словах, а на введенном тексте объявления. Необходимо определить к какой рубрике относится введенное объявление. После этого будут подбираться ключевые слова и фразы на основе статистики. Таким образом, необходимо подобрать алгоритм рубрицирования объявлений.