

2.1. Анализ предметной области
Поскольку одним из проектов, где будет использован разрабатываемый модуль, – это система контекстной рекламы, а именно подбор ключевых слов, то необходимо провести анализ предметной области.
Контекстная реклама [25] — это Интернет-реклама, максимально отвечающая тематике запросов (контексту) пользователей сети Интернет.
Контекстную рекламу можно классифицировать по нескольким показателям [25]:
по визуальному представлению:
текстовая контекстная реклама (рекламные сообщения);
медийная контекстная реклама (flash-баннеры и другая графическая реклама);
по способу показа:
поисковая контекстная реклама — показывается в результатах поиска на сайтах-поисковиках или на страницах поиска обычных сайтов. Подбор данного вида рекламы определяют слова, которые пользователь ввел в форму поиска. В данном случае заказчик имеет возможность выкупить ключевые слова или фразы;
тематическая реклама — отображается на страницах, содержание которых соответствует рекламируемому тексту.
Основные преимущества контекстной рекламы:
привлечение тех пользователей, которые действительно заинтересованы в поставляемых товарах и услугах;
контекстная реклама воспринимается как дополнительная информация, а не как реклама, которая «навязывается» пользователю. Таким образом создается эффект заботы о покупателе;
возможность показа контекстной рекламы в определенное время суток, в определенные дни недели, а также в определенных географических зонах.
Успех того, будет ли показано контекстное объявление после поискового запроса пользователя очень сильно зависит от правильного подбора ключевых слов или фраз. Поэтому необходимо проанализировать какие варианты совпадения ключевых слов возможны. Для этого рассмотрим какую классификацию предлагает система контекстной рекламы «Google AdWords». В данной системе существуют следующие варианты совпадения:
общее совпадение;
расширенное совпадение;
совпадение фразы;
точное совпадение;
отрицательное ключевое слово.
2.2. Методы автоматической классификации текстов
Рубрикаторы подразделяются на несколько типов[1]:
плоские;
иерархические;
сетевые.
На сайте компании «Камелот» используется плоский рубрикатор. Плоский рубрикатор — это рубрикатор, состоящий из двух уровней: на первом уровне размещается корневая рубрика, а на втором — дочерние к корневой рубрики[1]. Поэтому в модуле автоматического рубрицирования объявлений будет использован уже имеющийся рубрикатор.
Общая модель плоского рубрикатора может быть представлена следующим образом[1]:
R = <T, C, F, Rc, f>, (2.2.1)
где T — множество текстов, подлежащих рубрицированию;
C — множество классов-рубрик;
F — множество описаний;
Rc — отношение на С×F, которое имеет свойство, согласно которому каждому классу-рубрике соответствует единственное описание;
f — операция рубрицирования вида T→C.
В настоящее время можно выделить два принципиально разных подхода к классификации текстов:
экспертный подход (ручное рубрицирование) [11] – правила отнесения документа к рубрике задаются экспертами;
подход, основанный на какой-либо математической модели.
Характерными особенностями ручного рубрицирования являются:
высокая точность рубрицирования (процент документов, в которых проставлена явно неправильная рубрика, мал);
низкая скорость обработки документов.
Проблемы, которые могут возникнуть при ручном рубрицировании:
сложность ориентирования в классификаторе с большой размерностью и иерархической структурой;
неуверенность эксперта в принятии решения, потому что эксперт чаще всего является специалистом по ограниченному кругу вопросов;
при сравнении результатов рубрикации разными экспертами одних и тех же документов процент совпадения проставленных рубрик может оказаться низким – 60%. Этот факт можно объяснить субъективизмом выбора рубрики экспертом, так как разные эксперты могут проставить одному и тому же документу имеющие что-то общее, но все же разные рубрики.
В связи с появлением подобных проблем, возникает необходимость в применении автоматической классификации документов.
В ходе изучения и анализа работ [1, 2], был сделан вывод о том, что для автоматической рубрикации документов применяется четыре основных подхода:
нейросетевой;
статистический;
векторный;
деревья решений.
Для всех подходов существуют общие термины:
обучающая выборка – набор отрубрицированных экспертом документов, которые используются для обучения классификатора;
тестовая выборка – набор отрубрицированных экспертом документов, которые используются для проведения экспериментов для получения данных о качестве построенного классификатора.
Нейронные сети [2].
Искусственные нейронные сети (ИНС) – это большой класс систем, архитектура которых имеет аналогию с построением нервной ткани из нейронов. ИНС состоит из набора нейронов, соединенных между собой. Каждый нейрон представляет собой элементарный преобразователь входных сигналов в выходные. Выходные сигналы вычисляются как функция от входных сигналов. Передаточные функции всех нейронов фиксированы, а веса являются параметрами сети и могут изменяться. Некоторые входы нейронов помечены как внешние входы сети, а некоторые выходы – как внешние выходы сети. Подавая любые числа на входы сети, на выходах сети будет получен набор других чисел. Таким образом, работа нейросети состоит в преобразовании входного вектора в выходной, причем это преобразование зависит от весов сети.
Для того, чтобы сеть решала заданную функцию, ее необходимо «натренировать» на обучающих данных. В случае с классификацией текстов – это обучающая выборка. Тренировка состоит в подборе весов межнейронных связей, которые обеспечивают наибольшую близость ответов сети к правильным ответам.
Нейронные сети имеют очень широкий спектр применения. Имеется ряд экспериментов по использованию нейронных сетей для классификации текстов. В работе [8] показано, что нейросетевой подход показывает хорошие результаты при классификации текстов. Но также в этой работе отмечен тот факт, что на обучение рубрикатора, основанного на нейронных сетях, уходит больше времени, чем на обучение классификаторов, основанных на других алгоритмах.
Статистический подход.
Статистические методы основаны на вероятности выбора рубрики. Другими словами, выбирается та рубрика, у которой вероятность принадлежности ей документа больше. Данная вероятность рассчитывается на основе вхождения слов из классифицируемого текста в документы из обучающей выборки.
Вероятность принадлежности документа d к категории C можно вычислить по формуле [14]:
![]() , (2.2.2)
, (2.2.2)
где
![]() - вероятность принадлежности документа
d
к категории
C;
- вероятность принадлежности документа
d
к категории
C;
![]() - априорная вероятность выбора категории
C,
которая равна отношению количества
документов в категории C
к общему числу документов;
- априорная вероятность выбора категории
C,
которая равна отношению количества
документов в категории C
к общему числу документов;
![]() - вероятность принадлежности слова w
к категории
C.
- вероятность принадлежности слова w
к категории
C.
Произведение в данном случае применяется, потому что предполагается, что появление слов – независимые друг от друга события.
Вероятность появления слова в категории можно найти через частоту этого слова в категории [14]:
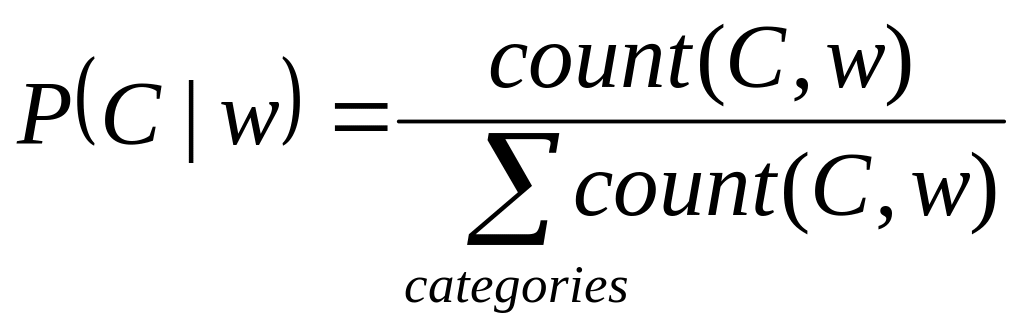 , (2.2.3)
, (2.2.3)
где
![]() - количество слов w
в документах из категории C.
- количество слов w
в документах из категории C.
Как показано в [14], для улучшения качества рубрикации можно произвести нормализацию по числу книг, чтобы не потерять категории с небольшим количеством документов и с большой частотой встречаемости слова на фоне категорий с большим количеством обучающих документов:
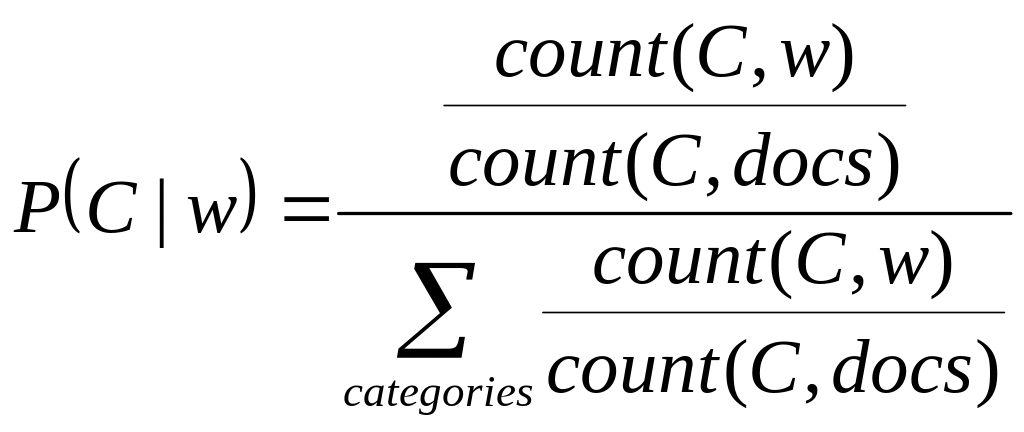 , (2.2.4)
, (2.2.4)
где
- количество слов w
в документах из категории C;
![]() -
количество обучающих документов в
категории C.
-
количество обучающих документов в
категории C.
В работе [4] говорится о том, что результат классификации становится лучше, если не учитывать априорную вероятность встречаемости категории при расчете результирующей вероятности. В данной работе будет проверено два способа: с учетом априорной вероятности выбора рубрики и без учета.
Во время расчета вероятности возможна следующая ситуация: какое-либо слово может ни разу не встретиться в рубрике, то есть = 0 и, следовательно, = 0. В работе [2] при расчете рекомендуется прибавлять единицу в числителе. В работе [14] рекомендуется присваивать вероятности маленькое число. В данной работе будут опробованы оба варианта.
Предположение о независимости вероятности появления слова является слишком сильным и практически никогда не выполняется. Тем не менее, как показано в работах [7, 9, 10], данный подход показывает очень хорошие результаты. Кроме того, этот метод обладает высокой скоростью работы и простотой математической модели [2].
Векторный подход.
Данный подход заключается в преобразовании документов в вектора. Координатами векторов являются веса термов. Согласно [2], вес терма вычисляется по следующей формуле:
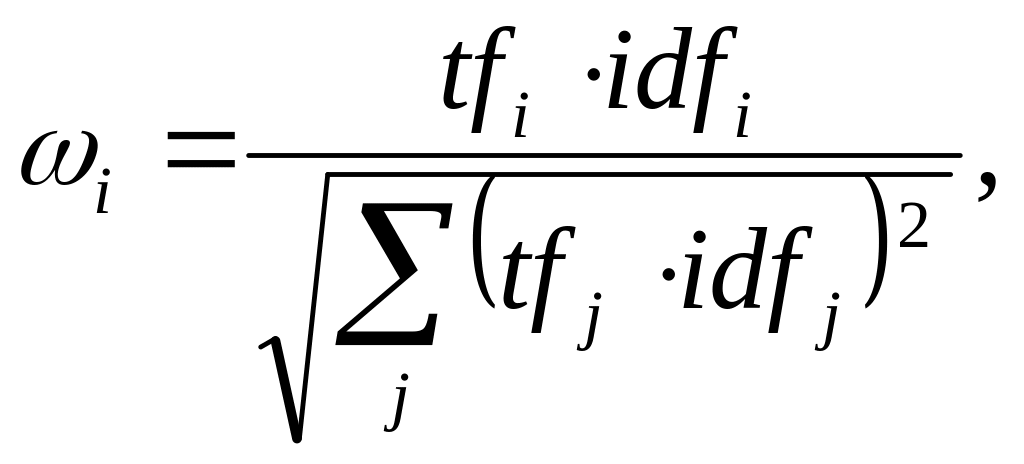 (2.2.5)
(2.2.5)
где
![]() - вес i-го
слова,
- вес i-го
слова,
![]() - частота встречаемости i-го
слова в данном документе (term
frequency),
- частота встречаемости i-го
слова в данном документе (term
frequency),
![]() - логарифм отношения количества всех
документов в коллекции к количеству
документов, в которых встречается i-ое
слово (inverse
document
frequency).
- логарифм отношения количества всех
документов в коллекции к количеству
документов, в которых встречается i-ое
слово (inverse
document
frequency).
Кроме того, в [2] обоснован такой выбор формулы следующим образом:
множитель учитывает следующий факт: что чем чаще встречается слово в документе, тем оно важнее;
множитель
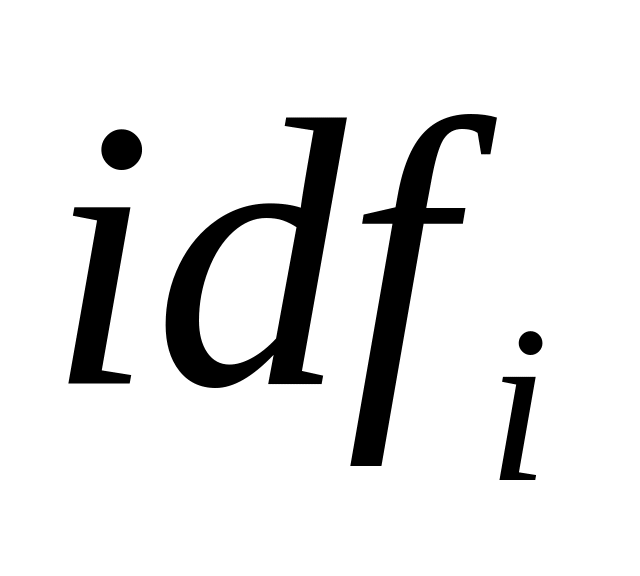 учитывает следующий факт: если слово
встречается в большей части документов,
то оно не является существенным критерием
принадлежности документа рубрике и
его вес следует понизить;
учитывает следующий факт: если слово
встречается в большей части документов,
то оно не является существенным критерием
принадлежности документа рубрике и
его вес следует понизить;для учета различной длины текстов в документах, веса слов нормализуются.
В данном подходе можно выделить два метода автоматической классификации:
метод k-ближайших соседей (k-nearest neighbors, k-NN);
классификатор Роше (Rocchio classifier).
При использовании метода k-ближайших соседей, каждый документ d сравнивается со всеми документами из обучающей выборки. Согласно [2], для каждого документа e из обучающей выборки находится расстояние до документа d как косинус угла между векторами признаков:
![]() (2.2.6)
(2.2.6)
После вычисления расстояний, из обучающей выборки выбираются k документов, ближайших к документу d. В [2] значение параметра k предлагается выбирать в интервале от 1 до 100. В работе же [5] значение параметра k предлагается выбирать в интервале от 20 до 50.
Далее для каждой рубрики вычисляется количество документов из k документов, отобранных на предыдущем шаге [2]:
![]() (2.2.7)
(2.2.7)
Рубрика, у которой величина s больше, чем у других, будет приписана документу d.
В работах [8] и [10] приводятся хорошие показатели данного метода. Однако в работе [9] приводятся результаты, которые хуже, чем у статистических методов и деревьев решений.
В [2] говорится о
том, что данный метод требует больших
вычислительных затрат на этапе рубрикации.
Классификатор Роше – еще один из способов
автоматической классификации текстов,
основанный на векторном представлении
документа. В нем используется профайл
для каждой из категорий. Согласно [5],
профайл – это список термов, наличие
или отсутствие которых наиболее хорошо
отличают категорию
![]() от других категорий. Таким образом,
новый документ сравнивается не с каждым
документом из обучающей выборки, а с
профайлом каждой категории. Профайл
от других категорий. Таким образом,
новый документ сравнивается не с каждым
документом из обучающей выборки, а с
профайлом каждой категории. Профайл
![]() для категории
рассчитывается по следующей формуле
[5]:
для категории
рассчитывается по следующей формуле
[5]:
![]() (2.2.8)
(2.2.8)
где
![]() - вес терма
- вес терма
![]() в документе
в документе
![]() ,
,
![]() - множество документов, в которых
присутствует терм
,
- множество документов, в которых
присутствует терм
,
![]() - список документов, в которых отсутствует
терм
,
- список документов, в которых отсутствует
терм
,
![]() и
и
![]() - контрольные параметры, которые
характеризуют значимость положительных
и отрицательных документов.
- контрольные параметры, которые
характеризуют значимость положительных
и отрицательных документов.
Преимущество данного метода состоит в том, что, при необходимости, можно быстро пересчитать профайлы для категорий. В [10] показано, что качество классификации данного метода немного хуже, чем у k-ближайших соседей.
В ходе консультации со старшим научным сотрудником НИВЦ МГУ Агеевым М.С. было установлено, что для рубрикации текстов небольшой длины (например, текст объявления) может не хватить стандартного векторного представления по словам и придется учитывать какую-либо специфику: расширение по синонимам или учет контекст появления текста. Это может существенно усложнить реализацию поставленной задачи.
Деревья решений.
Деревья решений – это способ представления правил в иерархической структуре. Под правилом понимается логическая конструкция, представленная в виде «если-то» [12].
При использовании деревьев решений для автоматической классификации документов на обучающей выборке строится дерево решений. Каждый новый документ «проходит» по этому дереву. В итоге выбирается какая-либо рубрика.
Дерево решений можно построить следующим образом [12]: пусть задано обучающее множество T, которое содержит уже отрубрицированные по категориям документы, каждый из которых характеризуется m атрибутами из множества наборов атрибутов M. Один из атрибутов обязательно указывает на принадлежность объекта к определенной категории.
Пусть
![]() - множество категорий. Тогда при построении
дерева решений возможны три ситуации:
- множество категорий. Тогда при построении
дерева решений возможны три ситуации:
обучающее множество T содержит один и более документов, которые относятся к одной категории
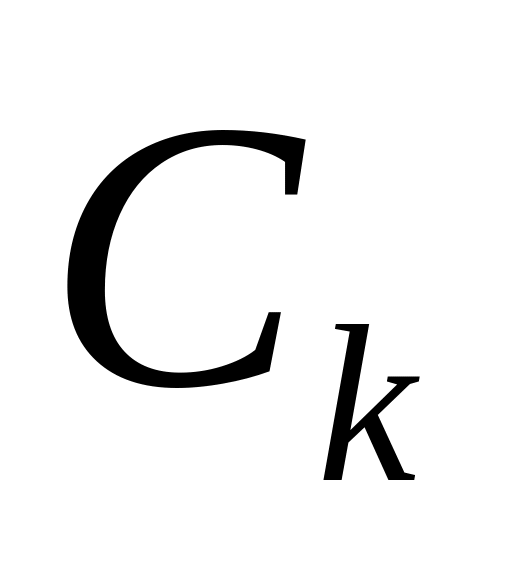 .
Тогда дерево решений для T
– это лист, который определяет категорию
;
.
Тогда дерево решений для T
– это лист, который определяет категорию
;обучающее множество T не содержит ни одного примера из категории , то есть пустое множество. В данном случае также получается лист (решение). Категория для листа определяется из множества, которое ассоциировано с родителями;
обучающее множество T содержит примеры, которые относятся к различным категориям. В этом случае множество T разбивается на подмножества
 .
Для этого выбирается один из наборов
атрибутов из множества M.
Данная процедура продолжается до тех
пор, пока в подмножествах не останутся
документы из одной категории.
.
Для этого выбирается один из наборов
атрибутов из множества M.
Данная процедура продолжается до тех
пор, пока в подмножествах не останутся
документы из одной категории.
При построении дерева на каждом внутреннем узле необходимо найти такой атрибут, выбор которого обеспечил бы наилучшее разбиение на подмножества, то есть получаемые подмножества должны состоять из документов, принадлежащих к одной категории, а количество документов из других категорий должно быть минимальным. Чаще всего для выбора атрибута используется один из двух критериев:
теоретико-информационный критерий:
![]() , (2.2.9)
, (2.2.9)
где Info(T) – энтропия множества T, X – проверка (выбранный атрибут), а
![]() ,
(2.2.10)
,
(2.2.10)
где - множества, полученные при разбиении T по проверке X.
Для разбиения выбирается тот атрибут, который дает максимальное значение критерия. Один из самых часто применяемых алгоритмов для автоматической классификации текстов с использованием данного критерия является алгоритм С4.5;
статистический критерий:
При использовании данного критерия атрибут выбирается на основе индекса Гини (Gini), который оценивает расстояние между категориями:
![]() ,
(2.2.11)
,
(2.2.11)
где C
– текущий узел, а
![]() - вероятность категории j
в узле C.
- вероятность категории j
в узле C.
Для повышения
точности классификации можно
воспользоваться методом «Random
Forest».
Согласно этому методу строится комитет
решающих деревьев, то есть несколько
деревьев решений. Каждое из них строится
на основе сгенерированной случайной
подвыборки из множества M,
а также m
выбранных атрибутов (![]() ).
В данном случае классификация документа
проводится следующим образом: каждое
дерево комитета относит классифицируемый
документ к одной и категорий. В итоге
выбирается та категория, за которую
«проголосовали» наибольшее число
деревьев.
).
В данном случае классификация документа
проводится следующим образом: каждое
дерево комитета относит классифицируемый
документ к одной и категорий. В итоге
выбирается та категория, за которую
«проголосовали» наибольшее число
деревьев.
Из деревьев решений можно извлекать наборы правил, которые описывают категории. Для извлечения правил необходимо исследовать все пути от корня до каждого листа дерева. Каждый путь дает правило, где условиями будут являться проверки из узлов дерева [12].
В работах [9, 10] показано, что деревья решений показывают хорошие результаты, сравнимые с другими методами автоматической классификации. Но в работе [5] упоминается о том, что процесс обучения и переобучения занимает много времени. Это объясняется тем, что при выборе атрибута, по которому произойдет разбиение обучающего множества, необходимо провести большое количество вычислений. Кроме того, если обучающая выборка состоит из большого количества документов, то дерево сильно разрастается.