

Лекция 2 субд. Основные функции. Классификация. Файл-серверные системы и компоненты. Клиент-серверные системы. Intranet-приложения. И т.Д.
Основные функции СУБД
управление данными во внешней памяти (на дисках);
управление данными в оперативной памяти:
журнализация изменений и восстановление базы данных после сбоев;
поддержка языков БД (язык определения данных, язык манипулирования данными).
Обычно современная СУБД содержит следующие компоненты:
ядро, которое отвечает за управление данными во внешней и оперативной памяти и журнализацию,
процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных, и создание, как правило, машинно-независимого исполняемого внутреннего кода,
подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД
а также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
СУБД включает:
1. Язык моделирования для определения схемы каждой базы данных в субд, согласно модели данных субд.
а) Четыре наиболее распространенные типы организации это иерархическая, сетевая, реляционная и объектная модели, перевернутый список и другие методы. Базе данных системы управления может предусматривать применение одного или несколько из четырех моделей. Оптимальная структура зависит от способа организации применения данных, а также от требований применению (включающие скорость обработки транзакций, надежности, эксплуатационной надежности, масштабируемости и экономичности).
б) Доминирующая модель, применяемая в настоящее время, специально встроена в SQL. несмотря на возражения пуристов, которые считают, что эта модель искажение реляционной модели, поскольку она нарушает ряд ее основополагающих принципов ради практичности и эффективности. Множество СУБД также поддерживает Open Database Connectivity (ODBC) API, который поддерживает стандартный способ для программистов доступ к СУБД.
Структуры данных (поля, записи, файлы и объекты), оптимизированных чтобы иметь дело с очень большим объемов данных, хранящихся на постоянном устройстве хранения данных.
Язык запросов базы данных и отчетов позволяют пользователям интерактивно опросить базы данных, провести анализ их данные и обновить их, в соответствии с привилегиями пользователей.
Он также контролирует обеспечение безопасности баз данных.
Защита данных от неавторизованного доступа оберегает от просмотра или обновления базы данных несанкционированными пользователями. Используя пароли, пользователи имеют доступ ко всей базе данных или подмножеству называемая подсхема БД. Например, базы данных работника может содержать все данные о личности работника, но одной группе пользователей может быть разрешено, просматривать только данные о заработной плате, а другие имеют доступ только к истории и медицинских данных.
Если СУБД дает возможность интерактивно войти и обновить базу данных, также хорошо как опросить ее, этот возможность позволит управлять персональными базами данных. Однако, не может разрешить проводить контрольные записи действий или обеспечить вилы контроля, необходимых при много-пользовательской организации. Эти контроли имеются только когда набор программных приложений являются индивидуальными для каждых вводимых данных и функций обновления.
4. Механизм транзакций, который в идеале должен гарантировать свойства автоматической классификации и интерпретации данных (ACID), в целях обеспечения целостности данных, несмотря на доступ со-пользователей (контроль параллелизма), и отказы (отказоустойчивости).
Это также поддерживает целостность данных в базе данных.
СУБД может поддерживать целостность базы данных, не позволяя более чем одному пользователю обновлять одну запись в одно и то же время. СУБД может помочь исключить дублирование записей через уникальный индекс ограничений; например, два клиента под одним и тем же номером клиента (ключевые поля) не могут быть введены в базу данных.
СУБД принимает запросы данных от прикладной программы и лает инструкции операционной системе для передачи соответствующих данных.

Рисунок 2: Структура баз данных [Основы реляционных баз данных]
Когда используется СУБД, информационная система может быть изменена намного проще, как
изменение информационных требований организации. Новые категории данных могут быть добавлены в базу
данных без нарушения существующей системы.
Организации могут использовать один тип СУБД для ежедневной обработки операций, а затем
переместить детали на другой компьютер, который использует другую СУБД лучше подходящую для
случайных запросов и анализа. Общие решения по дизайну системы выполняются администраторами данных и системными аналитиками. Подробная структура базы данных выполняется администратором баз данных.
Сервера баз данных это специально разработанные компьютеры, которые содержат фактические базы данных и исполняют только СУБД и связанное программное обеспечение. Как правило многопроцессорные компьютеры с RAID массивами используемых для стабильного хранения. Подключен к одному или нескольким серверам через высокоскоростной канал, аппаратные ускорители баз данных также применяются при условии обработки больших транзакций.
Иногда СУБД строятся с многозадачным ядром со встроенной поддержкой сетей, хотя в настоящее время эти функции оставили операционной системе.
Классификация СУБД
По типу управляемой базы данных СУБД разделяются на:
Сетевые
Иерархические
Реляционные
Объектно-реляционные
Объектно-ориентированные
По архитектуре организации хранения данных:
локальные СУБД (все части локальной СУБД размещаются на одном компьютере)
распределенные СУБД (части СУБД могут размещаться на двух и более компьютерах)
По способу доступа к БД СУБД разделяются на:
Файл-серверные
Клиент-серверные
Файл-серверные приложения
Организация информационных систем на основе использования выделенных файл-серверов все еще является наиболее распространенной в связи с наличием большого количества персональных компьютеров разного уровня развитости и сравнительной дешевизны связывания PC в локальные сети. Хотя на данный момент файл-серверные СУБД считаются устаревшими.
При опоре на файл-серверные архитектуры сохраняется автономность прикладного (и большей части системного) программного обеспечения, работающего на каждой PC сети. Фактически, компоненты информационной системы, выполняемые на разных PC, взаимодействуют только за счет наличия общего хранилища файлов, которое хранится на файл-сервере.
В классическом случае в каждой PC дублируются не только прикладные программы, но и средства управления базами данных. Файл-сервер представляет собой разделяемое всеми PC комплекса расширение дисковой памяти.
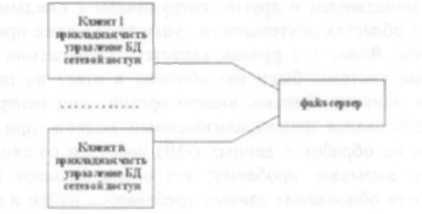
Рисунок 3: Классическое представление информационной системы в архитектуре "файл-сервер"
Достоинством является простота организации. Проектировщики и разработчики информационной системы находятся в привычных и комфортных условиях. Имеются удобные и развитые средства разработки графического пользовательского интерфейса, простые в использовании средства разработки систем баз данных и/или СУБД.
Недостатками являются следующие существенные моменты:
часто разработчики файл-серверных приложений считают, что по причине простоты средств управления базами данных проблемой проектирования базы данных можно пренебречь.
сложность поддержания целостного состояния базы данных информационной системы и гарантирования надежности хранения информации, сложность реализации
транзакционного управления.
хранения избыточных данных (например, с применением методов журнализации),
возможности формулировать ограничения целостности и проверять их соблюдение.
• В файл-серверной организации клиент работает с удаленными файлами, что вызывает существенную перегрузку трафика (поскольку СУБД-ФС работает на стороне клиента, то для выборки полезных данных в общем случае необходимо просмотреть на стороне клиента весь соответствующий файл целиком)
В файл-серверной архитектуре мы имеем "толстого" клиента и очень "тонкий" сервер в том смысле, что почти вся работа выполняется на стороне клиента, а от сервера требуется только достаточная емкость дисковой памяти