

33.Тест Гольдфельда-Квандта для виявлення гетероскедастичності залишків.
1.Упорядковується
значення незалежної змінної від меншого
до більшого і відкидається с
спостереження, які містяться всередині
впорядкованого ряду (залежна змінна
впорядковується по незалежній):
 У
результаті матимемо 2 сукупності:
У
результаті матимемо 2 сукупності:
2. Будується дві економетричні моделі на основі двох новостворених сукупностей спостережень
3. Визначаються залишки моделі за цими двома моделями

4.
Обчислюється
дисперсія залишків та знайдемо їх
співвідношення
5.
Порівняння
 з критичним значенням
з критичним значенням
 (ступень
свободи – (n-m-1),
і значущості α)
(ступень
свободи – (n-m-1),
і значущості α)
34. Алгоритм Глейсера для перевірки гетероскедастичності залишків.
Він
розглядає регресію залишків
 ,
що відповідають регресії найменших
квадратів, як певну функцію від
,
що відповідають регресії найменших
квадратів, як певну функцію від
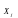 ,
де
‑ та незалежна змінна, яка відповідає
зміні дисперсії
,
де
‑ та незалежна змінна, яка відповідає
зміні дисперсії
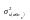 .
Для цього використовуються такі види
функцій.
.
Для цього використовуються такі види
функцій.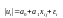 ;
; ;
; ;
; .У
цих рівняннях
.У
цих рівняннях
 ‑ стохастична складова. Рішення про
відсутність гетероскедастичності
залишків приймається на підставі
статистичної значущості коефіцієнтів
‑ стохастична складова. Рішення про
відсутність гетероскедастичності
залишків приймається на підставі
статистичної значущості коефіцієнтів
 .
Переваги цього тесту визначаються
можливістю розрізняти випадок чистої
і мішаної гетероскедастичності.
.
Переваги цього тесту визначаються
можливістю розрізняти випадок чистої
і мішаної гетероскедастичності.
Можливі 4 варіанти:
1)а0 і а1 ‑ статистично значущі ‑‑ існує чиста і мішана гетероскедастичність;
2)а0 ‑ статистично значуща, а1 ‑ ні ‑‑ існує мішана гетероскедастичність;
3)а1 ‑ статистично значуща, а0 – ні ‑‑ існує чиста гетероскедастичність;
4)а0, а1 ‑ статистично незначущі ‑‑ гетероскедастичність відсутня.
35.Перевірка наявності гетероскедастичності залишків на основі теста коефіцієнта рангової кореляції Спірмена.
1.
Побудова простих економетричних моделей
1МНК залежної змінної (Y)
з кожною з пояснювальних змінних (Xij).
2.
Визначення
вектора залишків для кожної з побудованих
моделей ( ).
3.
Ранжування вектора кожної пояснювальної
змінної (Xj)
і
кожного з векторів
).
3.
Ранжування вектора кожної пояснювальної
змінної (Xj)
і
кожного з векторів
 від меншого до більшого та заміна цих
векторів іншими рангами. 4.
Визначення коефіцієнта рангової
кореляції Спірмена:
від меншого до більшого та заміна цих
векторів іншими рангами. 4.
Визначення коефіцієнта рангової
кореляції Спірмена:
 де
де
 ‑ різниця між рангами
‑ різниця між рангами
 та
та

n – кількість спостережень; m-1 – кількість пояснювальних змінних.
5.
Розраховується t
–
статистика для визначення рівня
статистичної значущості кореляції
Спірмена:
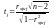
Доведено,
що ця характеристика має закон розподілу
Стьюдента з кількістю ступенів свободи
 .
Якщо розраховане значення t
–
статистики перевищує критичне значення
про ступені свободи
та вибраному рівні значущості α,
то гіпотезу про наявність гетероскедастичності
потрібно прийняти. У протилежному
випадку вона відхиляється.
.
Якщо розраховане значення t
–
статистики перевищує критичне значення
про ступені свободи
та вибраному рівні значущості α,
то гіпотезу про наявність гетероскедастичності
потрібно прийняти. У протилежному
випадку вона відхиляється.
39. Алгоритм Дарбіна-Уотсона для виявлення автокореляції залишків першого порядку
Тест Дарбіна-Уотсона
 Нехай
він може набувати значень з проміжку
[0, 4]:
Нехай
він може набувати значень з проміжку
[0, 4]:
 .Якщо
залишки
.Якщо
залишки
 є випадковими величинами, нормально
розподіленими, а не автокорельованими,
то значення DW
містяться поблизу 2. При додатній
автокореляції DW < 2,
при від’ємній — DW > 2.
Фактичні значення критерію порівнюються
з критичними (табличними) при різному
числі спостережень n
і числі незалежних змінних m
для вибраного рівня значущості a.
Табличні значення мають нижню межу DW1
і верхню — DW2.
Коли DWфакт
< DW1,
то залишки мають автокореляцію. Якщо
Dwфакт > DW2,
то приймається гіпотеза про відсутність
автокореляції. Коли DW1
<DW< DW2,
то конкретних висновків зробити не
можна: необхідно далі провадити
дослідження, беручи більшу сукупність
спостережень. Зауважимо, що цей критерій
призначений для малих вибіркових
сукупностей. Параметр r
для генеральної сукупності має тісний
зв’язок з критерієм DW.
Якщо r = 1,
то значення DW = 0,
при r = 0
DW = 2
і при r = –1
значення критерію DW = 4.
Наведені співвідношення показують, що
існують області, в яких застосування
критерію Дарбіна — Уотсона не може
дати певних результатів, про що вже
було сказано. Верхні та нижні межі
критерію DW
визначають межі цієї області для різних
розмірів вибірки, заданого числа
пояснювальних змінних та певного рівня
значущості.
є випадковими величинами, нормально
розподіленими, а не автокорельованими,
то значення DW
містяться поблизу 2. При додатній
автокореляції DW < 2,
при від’ємній — DW > 2.
Фактичні значення критерію порівнюються
з критичними (табличними) при різному
числі спостережень n
і числі незалежних змінних m
для вибраного рівня значущості a.
Табличні значення мають нижню межу DW1
і верхню — DW2.
Коли DWфакт
< DW1,
то залишки мають автокореляцію. Якщо
Dwфакт > DW2,
то приймається гіпотеза про відсутність
автокореляції. Коли DW1
<DW< DW2,
то конкретних висновків зробити не
можна: необхідно далі провадити
дослідження, беручи більшу сукупність
спостережень. Зауважимо, що цей критерій
призначений для малих вибіркових
сукупностей. Параметр r
для генеральної сукупності має тісний
зв’язок з критерієм DW.
Якщо r = 1,
то значення DW = 0,
при r = 0
DW = 2
і при r = –1
значення критерію DW = 4.
Наведені співвідношення показують, що
існують області, в яких застосування
критерію Дарбіна — Уотсона не може
дати певних результатів, про що вже
було сказано. Верхні та нижні межі
критерію DW
визначають межі цієї області для різних
розмірів вибірки, заданого числа
пояснювальних змінних та певного рівня
значущості.