

Тема 2. Попередній аналіз даних та вибір методу прогнозування
3.2.1. Методичні поради до вивчення теми 2
З даної теми передбачається вивчення таких питань:
інформаційне представлення динаміки розвитку соціально-економічних процесів;
різновиди моделей часових рядів;
вибір методу прогнозування часового ряду;
оцінка методів прогнозування;
ідентифікація часового ряду.
Для самостійного вивчення цієї теми рекомендується література: [1,2].
Вивчення теми надасть студентам можливість ознайомитися з характеристиками часових рядів, утворених за даними спостережень соціально-економічних процесів; різновидами моделей часових рядів; навчитися розпізнати вид моделі заданого часового ряду та вміти вибрати відповідний метод для його прогнозування.
Інформаційне представлення динаміки розвитку соціально-економічних процесів. Одним із найбільш складних етапів прогнозування, що забирає багато часу й сил, є отримання обґрунтованої й вірогідної інформації. Точність будь-якого прогнозу обмежується вірогідністю тих даних, на яких він побудований.
Ряд даних правильно відображає об’єктивний закон зміни економічного показника, коли рівні цього ряду є порівнянними, точними, стійкими та мають достатню сукупність спостережень. Визначення сутності цих понять можна знайти у [1] (стор.149-154). Невиконання однієї з умов робить некоректним застосування математичного апарату для аналізу ряду.
Для розрахунку прогнозів можна використовувати два типи даних.
Кросс-секційні дані або спостереження зібрані у фіксований момент часу. Задача полягає у вивченні цих даних і розповсюдженні отриманих взаємовідносин на велику генеральну сукупність.
Часові ряди – це розташовані у хронологічному порядку значення того чи того показника. Складовими ряду спостережень є числові значення показника, які називаються рівнями ряду, та моменти або інтервали часу, до яких належать рівні. Часовий ряд (ЧР) можна записати у стислому вигляді:
 ,
,
 ,
де
,
де
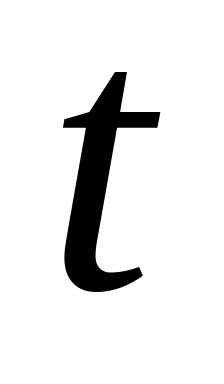 – рівновіддалені
моменти спостережень (година, доба,
місяць, квартал, рік тощо). Під довжиною
часового ряду розуміють час, що минув
від першого до останнього моменту
спостереження.
– рівновіддалені
моменти спостережень (година, доба,
місяць, квартал, рік тощо). Під довжиною
часового ряду розуміють час, що минув
від першого до останнього моменту
спостереження.
Принциповою відмінністю часового ряду від кросс-секційних даних є :
по-перше, рівні часового ряду не є незалежними;
по-друге, рівні часового ряду неоднаково розподілені. Закон розподілу ймовірностей цих випадкових величин і, зокрема, їхні математичні сподівання та дисперсії, можуть залежати від часу.
Залежно від характеру досліджуваних соціально-економічних показників часові ряди поділяють на моментальні, інтервальні та похідні [1] (див. Табл. 1.1.1-1.1.3). Для аналізу абсолютні рівні часових рядів часто доводиться перетворювати на відносні величини. Найпоширеніші характеристики динаміки розвитку економічних процесів та їхні розрахунки наведено в [1] (Табл. 1.1.4). Для вивчення просторових даних використовують технологію їх агрегування з побудовою інтервального ряду. Характеристиками інтервального ряду є: середнє значення, дисперсія, средньоквадратичне відхилення, коефіцієнти асиметрії й ексцесу, мода та медіана. Їх зміст і призначення збігаються із варіаційними характеристиками, а формули розрахунку (табл. 1.1.5, [1]) містять компоненту, яка враховує частоту попадання спостережень в інтервали.
Різновиди
моделей часових рядів.
В загальному випадку
часовий ряд економічного показника (
,
)
можна розкласти на чотири структурно
утворюючі елементи: тренд
(![]() ),
сезонну компоненту
(
),
сезонну компоненту
(![]() ),
циклічну компоненту
(
),
циклічну компоненту
(![]() ),
випадкову компоненту
(
),
випадкову компоненту
(![]() ).
).
Тренд,
сезонна і циклічна компоненти не є
випадковими і називаються систематичними
компонентами часового
ряду. Складова частина часового ряду,
що залишається після вилучення з
нього систематичних компонент, являє
собою випадкову компоненту (залишки,
помилки) εt.
Можна говорити про існування чотирьох
типів моделей даних:
горизонтальної,
тренду,
сезонної
та
циклічної.
Реальні дані цілковито
не відповідають лише одній із наведених
моделей, тож часовий ряд
,
![]() можна уявити у вигляді розкладення:
можна уявити у вигляді розкладення:
![]() ,
,
або різноманітних поєднань окремих
функцій. Однак завжди припускають
обов’язкову наявність випадкової
складової. Моделі тренду й сезонності
(тренд-сезонні) можуть відображати як
відносно постійну сезонну хвилю (цикл),
так і динамічно змінювану залежно від
тренду. Перша форма − належить до
адитивних,
друга −
,
,
або різноманітних поєднань окремих
функцій. Однак завжди припускають
обов’язкову наявність випадкової
складової. Моделі тренду й сезонності
(тренд-сезонні) можуть відображати як
відносно постійну сезонну хвилю (цикл),
так і динамічно змінювану залежно від
тренду. Перша форма − належить до
адитивних,
друга −
![]() ,
- до мультиплікативних
моделей.
,
- до мультиплікативних
моделей.
Процес окремого
обчислення функцій
![]() і
і
![]() називають фільтрацією
компонент
часового ряду
.
Процедура оцінювання детермінованої
частини разом з усіма невипадковими
компонентами має назву згладжування
часового ряду.
називають фільтрацією
компонент
часового ряду
.
Процедура оцінювання детермінованої
частини разом з усіма невипадковими
компонентами має назву згладжування
часового ряду.
Випадкова компонента є обов’язковою складовою часового ряду і визначає стохастичний характер його елементів уt. Стохастичне моделювання відбувається, як правило, на підставі стаціонарних випадкових процесів. Прикладами стаціонарних часових рядів є: білий шум, автокореляційний процес першого порядку (марківський процес), автокореляційний процес другого порядку (процес Юла) тощо.
За видом нестаціонарності вирізняють такі часові ряди, як: TS (trend stationary) – процес із детермінованим поліноміальним трендом, DS (differencing stationary) – процес зі сталою середньою та наявністю тренду в дисперсії, тренд-сезонні – окрім тренду містять чітко виражені сезонні коливання, нелінійні динамічні процеси – часові ряди зі складною структурою. Визначення сутності означених вище понять можна знайти у розділі 1.3 [1].
Вибір методу прогнозування часового ряду. Правильна стратегія для оцінки методу прогнозування складається із наступних етапів.
Метод прогнозування вибирається, виходячи із природи досліджуваних даних. Якщо в них вдається розпізнати тренд, циклічну або сезонну модель, це суттєво полегшує пошук ефективного методу екстраполяції.
2. Усі наявні дані
діляться на дві групи – дані підгонки
(ініціалізації) та дані перевірки або
прогнозу (рис. 3.2.1). На часовій шкалі
наочно представлені різні періоди.
Точка
відповідає моменту поділу даних. Усі
точки до неї відповідають минулим
спостереженням змінної
![]() ,
а точки після неї – майбутнім, які
прогнозуються.
,
а точки після неї – майбутнім, які
прогнозуються.
Поточний момент Дані минулого періоду Прогнозний період |
|
Рис. 3.2.1. Процедура розподілу даних під час прогнозування.
Вибрана методика прогнозування визначає спосіб добору значень для частини даних, які використовуються під час ініціалізації.
4. Коли методика
прогнозування обрана, можна скористатися
відомими даними і розрахувати прогнозовані
значення
![]() .
Після того як прогнозні значення будуть
отримані, слід порівняти їх із
спостереженнями і розрахувати помилки
прогнозу
.
Після того як прогнозні значення будуть
отримані, слід порівняти їх із
спостереженнями і розрахувати помилки
прогнозу
![]() та виміряти його точність. Помилкою
прогнозу є різниця між справжнім
значенням та його прогнозом.
та виміряти його точність. Помилкою
прогнозу є різниця між справжнім
значенням та його прогнозом.
![]() .
.
Результати готові. На їх основі можна приймати рішення про те, чи придатна методика для використання у такому вигляді або потрібна її модифікація. Можливо, необхідно буде скористатися іншою методикою прогнозу з метою порівняння отриманих результатів.
Методи прогнозування для стаціонарних даних. Стаціонарний ряд має середнє значення яке із часом не змінюється. Така ситуація трапляється у наступних випадках:
чинники, які породжують ряд, стабілізувались, і зовнішні впливи на значення ряду є відносно сталими;
через недостатню кількість даних або для спрощення пояснення чи для реалізації прогнозу необхідно використати дуже просту модель;
стабільності можна досягти за рахунок простого коригування таких чинників, як зростання населення або інфляція;
ряд можна перетворити в стабільний (за допомогою логарифмів, квадратних коренів або різниць);
ряд являє собою множину помилок прогнозу, одержаних в результаті застосування методу прогнозування, що може вважатися неадекватним.
Методи прогнозування стаціонарних рядів включають у себе наївні методи, методи простого усереднення, ковзної середньої, простого експоненціального згладжування, методи авторегресійної ковзної середньої (Бокса-Дженкінса).
Методи прогнозування для даних, що мають тренд. Ряд із трендом містить довгострокову компоненту, яка відображує стале зростання або спад значень ряду на протязі тривалого часу. Випадками використання є наступні:
підвищення продуктивності праці і застосування нових технологій призводять до зміни стилю життя;
зростання населення спричиняє збільшення потреб у товарах та послугах;
купівельна спроможність долара за рахунок інфляції спричиняє вплив на загальні економічні показники;
зростання визнання продукції на ринку (період зростання у життєвому циклі нового продукту).
Апарат прогнозування для рядів із трендом - це метод ковзних середніх, метод Хольта (лінійного експоненціального згладжування), проста регресія, криві зростання, експоненціальні моделі, методи авторегресійних інтегрованих ковзних середніх (ARIMA).
Методи прогнозування для даних із сезонною компонентою. Сезонний ряд описує зміни, що відбуваються із року в рік. Методи прогнозування для сезонних даних використовуються у наступних випадках:
на досліджуваний показник впливає погода;
досліджувана величина визначається річним циклом.
Методи, які слід використовувати для прогнозування сезонних рядів включають мультиплікативне або адитивне розкладення часового ряду на трендову та сезонну складові, метод експоненціального згладжування Вінтера, множинну регресію, метод Бокса-Дженкінса.
Апарат прогнозування для циклічних рядів. Циклічні моделі мають тенденцію до повторення поведінки даних кожні два, три або більше років. Випадки використання наступні:
на досліджувану величину впливає бізнес-цикл;
зміни суспільних уподобань;
зміни народонаселення;
зрушення у циклі виробництва продуктів споживання.
Циклічні компоненти важко моделювати через їхню нестійкість. Для аналізу циклічної складової можна використовувати методи розкладення. Однак, через нерегулярну поведінку циклів цей аналіз часто потребує визначення головних економічних показників (індикаторів). Використовують економетричні моделі, метод Бокса-Дженкінса.
До інших чинників, які треба враховувати під час вибору методу прогнозування, можна віднести: встановлений для прогнозу часовий горизонт, простота розуміння й тлумачення результатів. Рекомендації щодо вибору методу прогнозування наведені в таблиці 3.2.2.
Таблиця 3.2.2.
Рекомендації щодо вибору методу прогнозування
|
Мінімальні вимоги до даних |
||||
Метод |
Модель даних |
Випередження прогнозу |
Тип моделі |
Несезонні |
Сезонні |
Наївний Прості середні Ковзні середні Експоненціальне згладжування Лінійне експоненц. згладжування Квадратичне. експоненц. згладжув. Сезонне експоненц. згладжування Адаптивна фільтрація Проста регресія Множинна регресія Класичне розкладення Криві зростання „Перепис ІІ” Моделі Бокса-Дженкінса Провідні індикатори Економетричні моделі Багатомірна регресія ЧР |
СТ, Т, С СТ СТ СТ
Т
Т
С
С Т Ц, С С
Т С СТ,Т,Ц,С
Ц Ц
Т, С |
К К К К
К
К
К
К С С К
С, Д К К
К К
С, Д |
ЧР ЧР ЧР ЧР
ЧР
ЧР
ЧР
ЧР К К ЧР
ЧР ЧР ЧР
К К
К |
1 30 4-20 2
3
4
10 10хk
10
24
24 30 |
2хс
5хс
5хс
6хс 3хс
6хс |
Моделі даних: СТ – стаціонарні; Т – трендові; С – сезонні; Ц – циклічні.
Час випередження прогнозу: К – короткостроковий; С – середньостроковий; L – довгостроковий.
Тип моделі: ЧР – часовий ряд; К – каузальна.
Величини: k – період випередження прогнозу; с – тривалість сезонності.
Оцінка методів прогнозування. Після завершення дослідження необхідно перевірити, наскільки кожний метод надійний і може бути використаний до прогнозування даної проблеми. Окрім того необхідно оцінити його вартісну перевагу і точність у порівнянні із конкуруючими методами, а також розглянути можливість його застосування менеджерами.
Способами вимірювання помилки прогнозу є розрахунок наступних характеристик точності :
- середнього абсолютного відхилення
 ,
,
- середньої квадратичної похибки:
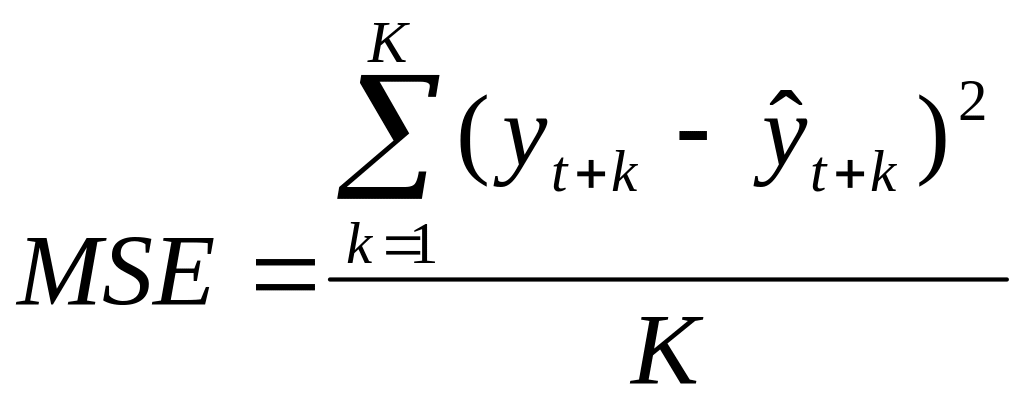 ,
,
- середньої абсолютної похибки у відсотках (МАРЕ):
МАРЕ=![]() .
.
На основі критерію МАРЕ можна робити висновок про деякий загальний рівень точності прогнозу:
MAPE |
Точність прогнозу |
Менше 10% |
Висока |
10% - 20% |
Добра |
20% - 40% |
Задовільна |
40% - 50% |
Погана |
Більше 50% |
Незадовільна |
Часто необхідно визначити, чи дає метод прогнозування систематичні відхилення (дає занижені або завищені результати). Для цього використовується середня відсоткова похибка
МРЕ=![]() .
.
Ознакою не зсунення результатів застосування методу є близьке до нуля значення МРЕ. Якщо відсоткове значення виходить суттєво від’ємним, то метод є послідовно переоцінюючим. Велике додатне відсоткове значення говорить про послідовно недооцінюючий метод.
Чим менше значення цих величин, тим вища точність прогнозу. На практиці ці характеристики використовуються досить часто оскільки природно очікувати, що правильно підібраний метод буде давати невеликі помилки прогнозу.
Означені та інші [1] критерії точності прогнозу використовуються для наступних цілей.
Оцінка корисності й надійності методу.
Порівняння точності двох методів.
Пошук оптимального методу.
Оцінка адекватності обраного методу прогнозування. Перш ніж використовувати певний метод прогнозування, необхідно оцінити його відповідність поставленому завданню. Основна вимога полягає у тому, щоб множина помилок була випадковою. Для перевірки цього необхідно відповісти на такі питання.
Чи є коефіцієнти автокореляції часового ряду помилок значущими? Для випадкового ряду не повинно спостерігатися значущих коефіцієнтів автокореляції. Потрібно дослідити чи дорівнюють нулю коефіцієнти автокореляції для усіх періодів зрушення.
Чи є помилки приблизно нормально розподіленими? На це питання можна відповісти, проаналізувавши гістограму помилок або графік нормальної імовірності.
Чи усі оцінені параметри моделі значущі за t-критерієм?
Чи є метод простим у використанні та доступним для розуміння тими, хто буде приймати рішення?
Якщо побудована “якісна” модель прогнозування, то залишкова компонента εt є близькою до нуля, випадковою, незалежною, нормально розподіленою, інакше модель вважається неадекватною. Способи перевірки цих умов описані в підручнику [1] розділах 1.3 (перевірка гіпотез стосовно сталості середнього значення та дисперсії часового ряду, дослідження автокореляційної функції часового ряду) та 7.1 (перевірка гіпотез стосовно випадковості відхилень рівнів часового ряду від тренду та нормального закону їхнього розподілу).
Ідентифікація часового ряду. Для ідентифікації моделі часового ряду спочатку з’ясовують, із яким процесом доведеться працювати – стаціонарним чи нестаціонарним.
Стаціонарні часові ряди передбачають, що процес породження наявних даних є лінійним. Вони не мають тренду або періодичної зміни середнього та дисперсії. Перевірку гіпотез стосовно сталості середнього значення та дисперсії часового ряду можна здійснити такими способами:
метод перевірки різниць середніх рівнів (див. розділ 1.3 [1]);
метод Форстера-Стьюарта (див. розділ 1.3 [1]);
дослідження автокореляційної функцій часового ряду (АКФ). Для перевірки статистичної значущості коефіцієнтів автокореляції можна скористатися критерієм стандартної похибки, Q-критерієм Бокса-Пірса, критерієм Льюнга − Бокса (див. розділ 1.3 [1]). На практиці порядок
 АКФ
рекомендується обирати від п/4
до п/3.
Корисною
властивістю автокореляційної функцій
є те, що для стаціонарних рядів існує
деяке значення К
таке, що для
АКФ
рекомендується обирати від п/4
до п/3.
Корисною
властивістю автокореляційної функцій
є те, що для стаціонарних рядів існує
деяке значення К
таке, що для
 коефіцієнти автокореляції
коефіцієнти автокореляції
 приймають майже нульові значення. Отже,
якщо при збільшенні часового проміжку
АКФ ряду за абсолютним значенням
поступово згасає, ряд можна вважати
стаціонарним.
приймають майже нульові значення. Отже,
якщо при збільшенні часового проміжку
АКФ ряду за абсолютним значенням
поступово згасає, ряд можна вважати
стаціонарним.
Визначення типу нестаціонарності та ступеня інтеграції часового ряду. Для нестаціонарного ряду визначають ознаку його нестаціонарності: чи описується він детермінованим або стохастичним трендом, визначають наявність періодичної складової.
Порядком інтеграції
є число, що показує, скільки разів часовий
ряд потребує застосування оператора
перших різниць, щоб стати стаціонарним
рядом. Наприклад, стаціонарні ряди ще
називаються динамічно стабільними або
такими, що мають нульовий порядок
інтеграції
![]() .
.
Позначимо через
![]() порядок інтеграції. Часовий ряд має
одиничний корінь, або порядок інтеграції
одиниця (
порядок інтеграції. Часовий ряд має
одиничний корінь, або порядок інтеграції
одиниця (![]() ),
якщо
),
якщо
![]() є стаціонарним рядом, тобто ряд перших
різниць має нульовий порядок інтеграції
(
є стаціонарним рядом, тобто ряд перших
різниць має нульовий порядок інтеграції
(![]()
![]() ).
Часовий ряд має два одиничних корені,
або порядок інтеграції 2, якщо його другі
різниці є стаціонарним рядом:
).
Часовий ряд має два одиничних корені,
або порядок інтеграції 2, якщо його другі
різниці є стаціонарним рядом:
![]() ;
;
![]()
![]() .
У загальному випадку часовий ряд має
порядок інтеграції
:
.
У загальному випадку часовий ряд має
порядок інтеграції
:
![]() ,
якщо
,
якщо
![]() .
Зазначимо, що якщо ряд стаціонарний, то
будь-які його різниці залишаються
стаціонарним рядом:
.
Зазначимо, що якщо ряд стаціонарний, то
будь-які його різниці залишаються
стаціонарним рядом:
![]() тощо.
тощо.
Для того, щоб розрізняти часові ряди типу TS та DS, та визначити порядок інтеграції використовують тест Діккі–Фуллера (виділяють простий − DF-тест та розширений − АDF-тест) та коінтегративну регресійну статистику Дарбіна-Ватсона (КРДВ) (див. розділ 1.3 [1]).
Ідентифікація детермінованого тренду та сезонності. Визначити, які невипадкові чинники, окрім випадкових, беруть участь у формуванні значень часового ряду, можна за допомогою автокореляційного аналізу. Сутність методу полягає в застосуванні апарату перших різниць і аналізу автокореляцій:
1) ряд не має тренду, якщо коефіцієнти автокореляції між рівнями ряду не залежать від часового лагу (статистично незначущі) і не мають певної закономірності зміни;
2) ряд має лінійний адитивний тренд у разі, коли автокореляційний аналіз вказує на лінійну залежність зміни коефіцієнтів автокореляції від часового лагу, а перехід до перших різниць виключає цю залежність;
3) ряд містить сезонну складову, якщо не існує лінійної залежності зміни коефіцієнтів автокореляції від часового лагу, але корелограма містить велику кількість значущих максимальних і мінімальних значень коефіцієнтів автокореляцій, що свідчить про значну залежність між спостереженнями, зрушеними на однаковий часовий інтервал;
4) ряд має лінійний тренд і сезонну складову, якщо його корелограма вказує на лінійну залежність зміни коефіцієнтів автокореляції від часового лагу і містить велику кількість значущих максимальних і мінімальних значень коефіцієнтів автокореляцій, а перехід до перших різниць виключає лінійний тренд, але статистична значущість певних коефіцієнтів автокореляцій залишається.
3.2.2. Плани семінарських, практичних занять, лабораторних робіт та методичні вказівки до їх виконання
Завдання для практичного заняття №2 „Попередній аналіз часових рядів та ідентифікація їхніх моделей” (2 год.).
Підібрати для дослідження 2 часових ряди: один – стаціонарний, інший – повинен мати тренд та сезонність. Для обрання рядів використати графічний аналіз даних.
Перевірити ряди на стаціонарність, використовуючи:
перевірку значущої відмінності двох середніх значень та дисперсії для двох нормально розподілених підмножин вибірки (методом перевірки різниць середніх рівнів та методом Форстера-Стьюарта);
дослідження АКФ (визначення статистичної значущості коефіцієнтів автокореляції та критерій Бокса-Пірса або Льюнга-Бокса).
Для нестаціонарного ряду ідентифікувати вид детермінованого тренду та сезонності за допомогою перших різниць та АКФ.
Назвати можливі методи прогнозування заданих часових рядів.
Результати дослідження оформити письмово. Висновки робити на 5-% рівні значущості.