

12.7 Блок «Констрастер»
Назначение контрастера - сводить число связей сети до минимально необходимого, но обеспечивающего заданную точность или оценку. При этом также уменьшается и число нейронов сети.
Упрощение НС строится как последовательный процесс исключения из сети наименее значимого элемента и последующего ее дообучения. При контрастировании решаются следующие задачи:
- упрощение архитектуры НС
- уменьшение числа входных сигналов
- получение явных знаний из данных
- получение логически прозрачных НС
4.3.9. Контрастер нейронной сети
Рассмотрим следующий важный блок нейрокомпьютера - контрастер нейронной сети [ 110]. Его назначение - сводить число связей сети до минимально необходимого или до «разумного» минимума (степень разумности минимума определяется пользователем). Наиболее важным следствием применения процедуры контрастирования является получение логически прозрачных сетей - сетей, работу которых легко описать и понять на языке логики [37,42,43].
Упрощение (контрастирование) нейронной сети строится как последовательный процесс исключения из сети наименее значимого элемента и дальнейшего подучивания сети. Если после шага упрощения невозможно доучивание сети до требуемой точности, то возвращаемся к сети, полученной на предыдущем шаге, и завершаем процесс упрощения. Из анализа литературы [41,42,110] можно сформулировать следующие задачи, решаемые с помощью контрастирования нейронных сетей.
Упрощение архитектуры нейронной сети.
Уменьшение числа входных сигналов.
Сведение параметров нейронной сети к небольшому набору выделенных значений.
Получение явных знаний из данных.
Процессы контрастирования работают как при проектировании информационных систем, так к при эксплуатации в процессе доучивания интеллектуальных блоков. При работающих информационных системах данную функцию желательно выполнять при периодическом запуске процедур обучения сетей в автоматическом режиме.
При контрастировании необходимо определить нужное число нейронов как минимально необходимое. Основной трудностью является то, что это минимально необходимое число заранее неизвестно, а процедура его определения путем постепенного наращивания числа нейронов весьма трудоемка. Однако из опыта применения нейросистем в различных областях деятельности, в том числе в экономике, можно отметить, что во многих задачах требуется не более нескольких десятков нейронов. Поэтому алгоритм контрастирования "снизу", т.е. от минимума числа нейронов до максимума, имеет право на жизнь, так как число итераций явно будет ограниченным. При этом можно использовать известные методы вычислительной математики (итерации). В данном случае данный блок будем называть конструктором.
Рассмотрим одну из задач контрастирования нейронных сетей -уменьшение числа входных сигналов. При постановке задачи для нейронной сети не всегда удается точно определить, сколько и каких входных данных нужно подавать на вход. В случае недостатка данных сеть не сможет обучиться решению задачи. Однако гораздо чаще на вход сети подается избыточный набор входных параметров. Например, в задачах диагностики состояния хозяйствующего субъекта часто исследуется на первых этапах значительно большее число показателей, чем это необходимо. Затем при помощи методов факторного анализа выбираются наиболее существенные. Однако следует отметить, что использование данных методов требует от менеджера достаточной математической подготовки. При использовании нейронных сетей этот процесс можно в максимальной степени автоматизировать и сделать незаметным для конечного пользователя. Поэтому методы определения значимости входных параметров имеют важное значение в экономических информационных системах. Алгоритмы определения значимости входных сигналов приведены в [37,41).
12.8 Задачник нейросетевого блока - это некоторая совокупность примеров векторов, на основе которых осуществляется обучение по НС. Та часть задачника, которая может использоваться для проверки правильности обучения называется тестовой выборкой. Для оценки эффективности обучения НС используется понятие ошибки.
Для информационных систем важным является вопрос формирования задачника. Это связано с тем, что для любого интеллектуального блока, которых в информационных системах довольно много, на входе формируется обучающая выборка, которая находится в постоянном динамическом изменении. Как правило, обучение производится не по всему задачнику, а по некоторой его части. Ту часть задачника, по которой в данный момент производится обучение, будем называть обучающей выборкой. Важность этого компонента определяется тем, что при обучении сетей всех видов с использованием любых алгоритмов обучения необходимо предъявлять примеры, на которых она обучается решению задачи. Кроме того, задачник содержит правильные ответы для сетей, обучаемых с учителем.
Настройка параметров функции (4.2) производится на основе обучающей выборки, которая содержит примеры, описывающие состояние объекта исследования, и значения целевого параметра, соответствующие каждому состоянию. Например, для экономических задач оценки деятельности конкретного предприятия наиболее характерно применение временных отсчетов в качестве базового параметра измерения, т.е. примеры значений параметров объекта отличаются тем, что измерены в различные моменты времени. Соответствующая обучающая выборка представляется в виде матрицы М:

где tнач и tкон - границы временного интервала, определяемые экспертным путем.
Важным вопросом является разделение всех доступных данных на обучающую и тестовую выборки таким образом, чтобы обеспечить их независимость и представительность. Эта проблема решается для каждой конкретной задачи отдельно. Задачник формируется в результате функционирования информационной системы в ритме процессов производства и управления. Формирование происходит непосредственно в базах данных, причем даже для одного АРМа их может быть несколько.
Для рассматриваемых информационных систем основной структурой задачника является база данных реляционного типа. Каждому примеру соответствует одна запись базы данных. Каждому данному -одно поле. Поля базы данных могут быть числовыми и текстовыми. В зависимости от решаемой задачи содержимое задачника может меняться. Так, например, для решения задачи классификации без учителя используют нейросети, основанные на методе динамических ядер [207] (наиболее известным частным случаем таких сетей являются сети Кохонена [233,234]). Задачник для такой сети должен содержать только векторы входных данных. При использовании обучаемых сетей, основанных на принципе двойственности, к задачнику необходимо добавить вектор ответов сети. Кроме того, некоторые исследователи хотят иметь возможность просмотреть ответы, выданные сетью, вектор оценок примера, показатели значимости входных сигналов и, возможно, некоторые другие величины. Поэтому стандартный задачник должен иметь возможность предоставить пользователю всю необходимую информацию. При формировании задачника должны активно использоваться возможности графики и цвета [ 148].
Задачники формируются в результате функционирования информационной системы в базах данных в ритме процессов производства и управления в соответствии с разработанными технологиями. При этом выполняются процедуры погружения данных, описанные выше. Например, для задач прогнозирования возможны следующие варианты погружения информации: без пересечения, с пересечением, с дообучением, без дообучения, по совокупности временных рядов, в том числе возможны варианты с учетом сезонных колебаний, с учетом других качественных признаков (рисунок 4.14). При организации задачников важными являются вопросы создания и обновления архивов, технологии формирования обучающих выборок по этапам технологического процесса обработки информации в автоматизированной системе.
На рисунке 4.14 представлены методы формирования выходных (целевых) параметров У задачника нейросети. Наиболее качественные данные задачника получаются на основе фактической выборочной, экспериментальной информации, в том числе по данным происшедших событий, выполненных опытов и экспериментов. При решении неформализованных задач, таких, например, как оценка состояния объекта управления, получение значения целевого параметра экспериментальным путем бывает невозможно. В этом случае используется экспертная информация, формируемая опытным специалистом в соответствующей области знаний или группой экспертов при помощи методов экспертной оценки [54].
При функционировании информационной системы, при постоянно изменяющемся состоянии предметной области, существенном обновлении данных задачника часто не представляется возможным своевременно привлечь опытных специалистов для выработки значений целевых параметров и последующего дообучения нейронной сети. Для этого разработаны методы автоматического самообучения нейросетевых компонентов (рисунок 4.14). Они реализуются при помощи специально разработанных экспертных систем, содержащих знания опытных специалистов, по аналитическим методикам и зависимостям, с использованием фиксированных констант и множеств, определяющих значения целевых параметров "по умолчанию".
На рисунке 4.15 представлен процесс функционирования нейросетевого решателя в режиме автоматического обучения.
В данной схеме показано подключение экспертной системы для формирования значений целевого параметра У перед дообучением нейронной сети. Однако следует отметить, что данный режим не должен быть основным. В реально работающих информационных системах режим самообучения не должен иметь регулярного характера, так как при этом качество обучения нейросетевых элементов ухудшается. При эксплуатации информационных систем периодически должны подключаться группы экспертов для обновления целевых параметров обучающих выборок и последующего дообучения нейросетевых компонентов.
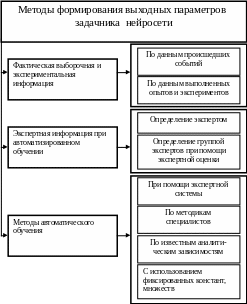
Рисунок 7 - Методы
формирования выходных параметров
![]() задачника
задачника
![]() нейросети
нейросети
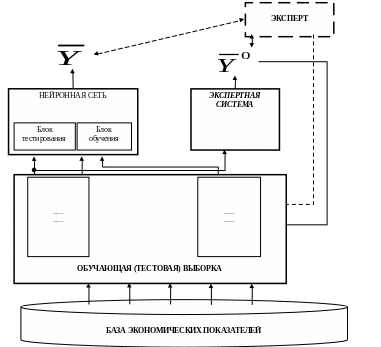
Рисунок 8 – Функционирование нейросетевого решателя в режиме
автоматического обучения
12.9 Предобработчик нейросетевого блока.
Сигналы могут поступать на нейроим-р в любой форме => необходима программа преобразования инф-и в единую форму, необх-ю для мат-ой обработки сигналов.
К этапам предобработки при НС-ом моделировании относятся след.функциипредобработчика:
- функции предобработки
1) проверка однородных данных – весь исх-й статист-й материал разбивается на ряд групп, объедин-х к-л общим признаком. В спец. теории распознавания образов сущ-ет гипотеза о компактности:
реализация одного и того же образа данных обычно отображается в признаковом пространстве геом-ки близкими точками, образуя компактные сгустки. Для опред-я однородности выборки используют различные меры компактности. В частности среднее расстояние от центра тяжести до всех точек образа.
2) исключение аномальных наблюдений
3) заполнение пропусков данных – статистич-й анализ данных с пропусками.
4) фильтрация данных прим-ся, когда есть резкие всплески/падения знач-й Д Методы: простые скользящие средние, взвешенные скользящие средние, экспоненциальные скользящие средние, вейвлет анализ, ряды Фурье.
5) нормирование данных осуществляется преобраз-е вх-ых сигналов т.о., чтобы обеспечить эфф-ю работу сети: bmin=-1, bmax=1 xmin, xmax
x’=((x-xmin)(bmax-bmin))/(xmax-xmin)
6) эвристический анализ данных – технический анализ данных.
- функции погружения данных
1) погр-е данных для задач оценки и анализа
2) погр-е данных для задач прогноза (без пересечения, с пересечением, по одному ряду, по совок-ти временных рядов, с настройкой глубины погружения, режим без дообучения, режим с дообучением).
Предварительная обработка информации на этапе формирования нейросетевых компонентов
Необходимо отметить, что в информационных системах нейросетевому моделированию любого экономического процесса или явления должен предшествовать априорный анализ объекта исследования. Если этот этап будет исключен, то, как и при статистическом моделировании, возможно получение неадекватных действительности результатов на этапе эксплуатации модели при функционировании информационной системы. Априорный анализ при нейросетевом моделировании частично отличается от технологии статистического анализа и состоит из следующих этапов: постановка задачи исследования; обобщение профессиональных знаний об объекте исследования на основании опыта, интуиции, изучения литературных источников, консультаций со специалистами и т.п.; формализация полученной априорной информации об объекте исследования; уточнение и конкретизация постановки задачи, сбор исходных данных. Этапы априорного анализа статистических данных подробно рассмотрены в литературе [17,31, 100,102].
На этапе предобработки важную роль играет компонент предобработчик. Он занимает место между обучающей выборкой и нейросетью. Из литературных источников следует, что разработка эффективных предобработчиков для нейрокомпьютеров является новой, почти совсем не исследованной областью [НО]. Поэтому данный раздел при использовании нейросетевого подхода в информационных системах подлежит существенной доработке. К этапам предобработки данных при нейросетевом моделировании в информационных системах будем относить: исключение аномальных наблюдений, проверку однородности данных, заполнение пропусков в данных, фильтрацию, нормировку данных, погружение данных (рисунок 9). На этапе погружения данных происходит формирование обучающей выборки в базе данных в соответствии с определенными правилами, заданными процедурой решения конкретной прикладной задачи. В частности, различаются функции погружения при решении задач анализа и прогноза. При решении задач прогнозирования выделяются варианты погружения данных в режимах "без пересечения", "с пересечением", "по одному-ряду", "по совокупности временных рядов".
Предварительная очистка и первичная статистическая обработка исходных данных при нейросетевом моделировании включает также этап исключения аномальных наблюдений. Для этих целей можно применить алгоритмы «ремонта» данных.

Рисунок 9– Функции предобработчика нейросети
Следующим этапом предобработки данных следует считать проверку однородности данных [17]. Исследования показывают, что часто весь исходный статистический материал разбивается на ряд групп, объединенных каким - либо общим признаком. Применение нейросетевой аппроксимации по таким данным часто бывает затруднено, сеть учится с перебоями, так как алгоритмы оптимизации работают неустойчиво. В связи с этим встает вопрос о сравнении различных групп исходных данных для определения их однородности и установления принадлежности различных выборок единой генеральной совокупности.
Часто при эксплуатации реальных информационных систем не известна связь обучающей выборки с генеральной совокупностью. Неизвестна связь выборки с теми или иными законами распределения, корреляционными и регрессионными зависимостями. Поэтому для проверки однородности выборки необходимо, прежде всего, обратиться к известной из литературы по распознаванию образов гипотезе компактности [62]. Она утверждает, что реализации одного и того же образа обычно отображаются в признаковом пространстве в геометрически близкие точки, образуя «компактные сгустки». При исследовании компактности (в том числе определения однородности выборки) можно в качестве предобработки использовать различные меры компактности:
- среднее расстояние от центра тяжести до всех точек образа,
- средняя длина ребра полного графа или ребра кратчайшего незамкнутого пути, соединяющего точки одного образа,
- максимальным расстоянием между двумя точками образа и т.д.
Кроме того, эффективными являются следующие меры близости объектов:
- квадрат эвклидова расстояния между векторами значений и признаков,
- квадрат расстояния Махаланобиса,
- квадрат коэффициента корреляции.
Для проверки однородности данных можно применять методы классификации данных «без учителя» [41]. Наиболее эффективными являются методы динамических ядер и нейросетевой метод адаптивной кластеризации данных, основанный на картах Кохонена [41,44,207,233,234].
Важным этапом предобработки является также процедура заполнения пропусков в данных. Распространенными приемами анализа данных с пропусками являются исключение некомплектных наблюдений (содержащих пропуски хотя бы одной из переменных) и традиционные методы заполнения пропусков - средневыборочными по присутствующим значениям с помощью регрессии и главных компонентов [102]. Эти методы в общем случае имеют малую эффективность, ведут, как правило, к несмещенности и несостоятельности, к нарушению уровней значимости критериев и другим искажениям статистических выводов, не обладают устойчивостью к распределению пропусков. Наиболее популярен в настоящее время за рубежом ЕМ -алгоритм [98]. В нашей стране известны работы в области заполнения пропусков в данных, в том числе, наиболее эффективными являются алгоритмы ZЕТ, адаптивный генетический алгоритм LGАР [60].
Для проводимых исследований за основу взята [184]. Авторами этой работы создан программный комплекс «Линейный и нелинейный факторный анализ». Он предназначен для восстановления пропущенных (ремонт известных) данных в таблицах путем моделирования исходных данных многообразиями малой размерности и последующего замещения пропущенных данных значениями из модели. Метод интерпретируется как построение конвейера нейронов для обработки данных с пробелами. Другая возможная интерпретация - итерационный метод главных компонент и нелинейный факторный анализ для данных с пробелами.
Следующим элементом предобработчика является оценка выборки и при необходимости фильтрация данных. В зависимости от характера обучающей выборки возможно использование различных методов фильтрации данных. Для выбора методов необходимо произвести предварительную оценку данных. Для этого можно использовать оценку дисперсии, корреляции, эвристические методы. В зависимости от результатов анализа при помощи экспертной системы (продукционной, основанной на теории прецедентов и др.) определяется тот или иной метод фильтрации данных: простые скользящие средние, взвешенные скользящие средние, экспоненциальное скользящее среднее, фурье, вейвлет - анализ и т.д.
Заключительным этапом предобработки является нормировка данных. При этом осуществляется преобразование входных сигналов таким образом, чтобы обеспечить эффективную работу нейронной сети. Для количественных признаков стандартными процедурами предобработки являются нормировка и центрирование, которые обеспечивают универсальность нейронной сети при работе с произвольными данными и позволяют сохранять параметры сети в оптимальном для функционирования диапазоне. Существует несколько стандартных методов нормировки [41], использующих оценки математического ожидания и дисперсии, основанные на текущей выборке, но оценки статистических параметров могут меняться от выборки к выборке, что создаст трудности при обработке новых данных, которые могут менять статистические параметры выборки. Более удобной в нашем случае является формула [41, 110]:
![]() (4.3)
(4.3)
где [bmin,bmax] - Диапазон приемлемых значений входных переменных, в нашем случае [-1,1];
[xmin,xmax] - интервал допустимых значений признака х, полученный на этапе структурирования;
![]() -
преобразованный сигнал, который будет
подан на вход сети.
-
преобразованный сигнал, который будет
подан на вход сети.
При использовании (4.3) параметры нормировки остаются неизменными при обработке различных выборок.
Значения переменных, измеренных в номинальной шкале, обычно представлены в обучающей выборке в виде натуральных чисел 1... S, где S - число возможных состояний. Преобразование номинальных переменных по формуле (4.3) некорректно, так как явным образом вводит расстояние между отдельными значениями переменной. Применяется следующий метод предобработки. Пусть Pє{1..S} - номинальная переменная, S - число возможных состояний. С=(С{C1 .. Сs), Ciє{-1,1} — кортеж бинарных переменных. Тогда каждой Рk ставится в соответствие Сk. При этом
![]() (4.4)
(4.4)
где i,j - номера состояний Рk.
В итоге каждой номинальной переменной соответствует несколько бинарных полей в обучающей выборке.
Преобразования (4.3), (4.4) проводятся как для входных, так и для выходных параметров обучающей выборки.
В [41, 110] предлагается включить в предобработку данных вычисление оценки константы Липшица для выборки для определения «минимального порога разрешения», которым должна обладать нейросеть, чтобы иметь возможность разделить два близких сигнала:
![]() (4.5)
(4.5)
где Ls - выборочная константа Липшица;
x1,x2 - примеры из выборки X;
f(.) - значение целевой переменной;
||.|| - евклидова норма.
Если x1= x2 при f(x1)≠f(x2), то примеры x1,x2 являются конфликтными и оценка обучения сети на данной выборке будет не меньше, чем e=0.5∙(|f(x1)f(x2)|)2.
Конфликтные примеры свидетельствуют либо об ошибках измерения различной природы, либо о недостаточности набора параметров для описания объекта. В первом случае один из примеров исключают из рассмотрения или при малом значении е продолжают обучение, используя оценку МНК «с допуском» [110]. Во втором случае необходим дополнительный анализ предметной области для выявления новых параметров описания, позволяющих разделить конфликтные примеры.
Если в значениях выходной переменной присутствует аддитивный шум є, формула (4.5) может дать завышенную оценку константы Липшица аппроксимируемой функции. В этом случае предлагается использовать оценку:
![]() (4.6)
(4.6)
где
![]() ,
т.е. требования к нейросетевой модели
станут менее жесткими, что позволит
построить более гладкую нейросетевую
зависимость.
,
т.е. требования к нейросетевой модели
станут менее жесткими, что позволит
построить более гладкую нейросетевую
зависимость.
Заметим, что использование того или иного вида выборочной константы Липшица зависит от вида функционала оценки работы ней-росети. Классическому МНК соответствует (4.5), при оценке типа МНК с допуском предлагается использовать (4.6).
Выборка может содержать как количественные, так и номинальные переменные. В случае векторов со смешанным типом компонент расстояние определяется в соответствии с функцией НЕОМ (Неtеrоgепеоus Еисlidean-Оvеr1ар Меtric function) [279]: для количественных параметров, после их нормирования в интервал [-1,1], за расстояние принимается модуль разности значений. Для дискретных переменных расстояние между двумя значениями Р1 и Р2 переменной Р определяется по правилу:
![]() (4.7)
(4.7)
где С1, С2 получены по формуле (4.4).
Тогда расстояние между векторами вычисляется по формуле
![]() (4.8)
(4.8)
где i - номер компоненты вектора.
12.10 Интерфейс ввода нейросетевого блока.
Структурно-функциональная модель построения интерфейсов в программной системе ввода документов
Рассмотрим подход к организации интеллектуальных интерфейсов пользователя для ввода информации на примере программной системы ввода бухгалтерских проводок. Данная программа входит в комплекс анализа финансово-хозяйственной деятельности предприятия. Система реализует следующие функции:
- обучение пользователя,
- оценка его работы,
- выбор обучающих тестов,
контроль степени усвоения материала.
Технологии искусственного интеллекта применяются для организации интеллектуальных интерфейсов пользователя с программно- техническими комплексами (рисунок 10). Разрабатываются средства адаптации системы к конкретному специалисту. Для этого реализуются функции распознавания действий человека и текущего состояния информационной системы, определение класса пользователя и в зависимости от этого проведения непрерывного его обучения в соответствии со степенью образования. При работе интеллектуальных систем ввода данных применяются два уровня контроля входной информации. На первом уровне используется логический контроль данных и действий пользователя. Для этих целей возможно использование традиционных экспертных систем.
В результате работы этих блоков формируются контрольные сообщения и обобщающие параметры, показывающие класс работы пользователя (качество ввода, категория допущенной ошибки, характеристика недопустимого действия). Сформированные параметры используются во втором уровне логического контроля данных. Для этого применяется обученная нейронная сеть. Выходным параметром сети является класс пользователя. Он определяет квалификацию пользователя, критерий качества его работы. В зависимости от значения проиЗ' водится автоматический выбор обучающего теста и настройка программы ввода. Обучающие инструкции при необходимости выдаются на экран видеотерминала.
В системе реализованы следующие функции:
1. Обучение пользователя работе с системой:
- объяснение структуры информационных полей и их семантического смысла;
- обучение процедурам ввода информации;
- слежение за работой пользователя, логический контроль допущенных ошибок и частичное их автоматическое исправление;
- адаптация системы к конкретному пользователю.
2. Оценка квалификации пользователя, запуск обучающих тестов по мере необходимости.
3. Контроль прогресса пользователя в изучении системы в процессе работы.

Рисунок 10 - Схема построения интеллектуальных интерфейсов
Рассмотрим реализацию предлагаемого метода в основных этапах работы интеллектуальной системы ввода. Логическая схема системы приведена на рисунке 11. Пользователь вводит информацию в информационные поля, система в процессе ввода контролирует пользователя, Помогает исправить допущенные ошибки, ставит ему оценки по десятибалльной шкале. Система накапливает полученные оценки для пользователя, затем после ввода им "n" проводок подсчитывает среднеарифметическое каждой оценки и подает результаты на вход нейронной сети. Параметр "n" определяется методом экспертной оценки [54].
Кроме «полевых» оценок (оценки за каждое введенное поле) программа подает на вход нейросети две дополнительные оценки: оценку времени заполнения одного бланка бухгалтерской проводки (ПО1) и оценку количества обращения пользователя к справке по программе (ПО2). Нейронная сеть на выходе дает общую оценку пользователя по шестибальной шкале. В зависимости от поставленной оценки нейросетью возможен запуск обучающего теста, подстройка программы под пользователя.
Как видно ИЗ рисунка 11, в программе существует два уровня контроля:
Логический контроль. Выполнен на основе экспертной системы, которая реализует рассуждения на основе теории прецедентов (каждому действию пользователя сопоставлено решение этого действия и определенная оценка).
Анализ оценок нейронной сетью и вывод общей оценки пользователя, запуск обучающих тестов.
Остановимся более подробно на каждом уровне контроля. На первом уровне функционирует ЭС, основанная на теории прецедентов [5]. Выбор данного метода представления знаний основан на следующих обстоятельствах: при помощи данного метода представления знаний легко реализовать на СУБД базу знаний и подсистему рассуждения (индексация и поиск решения}; сложность описания проблемной области в интерактивных системах ввода информации не позволяет для этого использовать традиционные экспертные системы.
При функционировании экспертной системы за любое действие пользователю ставится оценка. Оценки ставятся от 0 до 10 баллов. Десятибальная шкала позволяет гибко определить действия пользователя. В таблице 4.1 приведены несколько примеров для заполнения БЗ экспертной системы.

Рисунок 11-Логическая схема системы
Таблица 4.1 - Пример заполнения базы знаний экспертной системы
а) Поле - Счет
Наименование ошибки |
Действие системы |
Оценка |
Пользователь ввел счет, которого нет в БД |
Выдать сообщение об ошибке, проанализировать счет и найти наиболее подходящее, дать пользователю выбрать счет. Оценку ставить в зависимости от введенного неправильного счета и количества отобранных счетов |
0...10 |
Пользователь не заполнил счет |
Выдать сообщение об ошибке, вывести пользователю всю базу счетов |
2 |
Ввел одинаковый дебет и кредит
|
Выдать сообщение об ошибке, дать пользователю возможность исправиться |
0 |
б) Поле - Количество |
||
Наименование ошибки |
Действие системы |
Оценка |
Превысили остаток на складе |
Выдать сообщение об ошибке, дать пользователю возможность исправиться |
8 |
Ничего не ввел, хотя ввел товар |
Выдать сообщение об ошибке, дать пользователю возможность исправиться |
|
Ввел отрицательное число |
Выдать сообщение об ошибке, дать пользователю возможность исправится |
0 |
Ниже приведена формула вычисления балла на основе выборок:
На рисунке 12 дана общая схема работы экспертной системы в составе информационной системы.
кол-во записей в выборке
Балл = 10 – ((-------------------------------------)*10)
кол-во всех записей
База знаний упорядочена по номерам полей и убыванию приоритета.

Рисунок 12 - Схема работы экспертной системы в составе информационной системы
На рисунке 13 представлена схема индексации базы знаний для реализации рассуждений на основе теории прецедентов. База знаний легко корректируется и адаптируется для любой предметной области.
На рисунке 14 приведен механизм работы экспертной системы.
В большинстве информационных программ, используемых в настоящее время, существует только логический контроль действий пользователя и запуск соответствующей подсказки. В данной работе отличие от этого используется второй уровень контроля, который основе ошибок пользователя запускает обучающие тесты и настраивается на работу с пользователем. Для этого используется искусствен нейронная сеть (НС),
Выбор нейронной сети основан на следующих предположениях:
Из-за специфики оценивания пользователя (не все интервалы для оценок равны и изменяются в одних и тех же пределах).
Для традиционных систем представления знаний характерно резкое усложнение описания проблемы при увеличении ее масштабов.
Результат от среднеарифметических оценок поступает на вход НС только после ввода "n" проводок. В результате проведенных экспериментов установлено, что в процессе ввода n =7 - 10 проводок можно полностью оценить квалификацию действий пользователя. Десять проводок позволяют оценить ввод всех полей и проверить, повторяет пользователь одни и те же ошибки или нет. На вход НС поступает 12 оценок в последовательности, представленной в таблице 4.2.

Рисунок 13 - Индексы БЗ и дерево поиска решений

Рисунок 14 - Механизм работы экспертной системы
Таблица 4.2 - Входы нейронной сети
1 |
Дата |
2 |
Наименование дебитора дебитора |
3 |
Счет дебет |
4 |
Наименование кредитора |
5 |
Счет кредит |
6 |
Наименование материала |
7 |
Текшая единица измерения |
8 |
Цена |
9 |
Количество |
10 |
Сумма |
11 |
«Временная» оценка |
12 |
«Справочная» оценка |
На выходе у нейронной сети определяется класс пользователя. Количество классов - 6. Ниже, в таблице 4.3, приведены все в пользователя.
Таблица 4.3 - Классы пользователя
Класс |
Тип пользователя |
Действие системы |
1 |
Полностью некомпетентен |
Запуск теста, который объясняет «азы» работы с компьютером, информационными системами и т.д. |
2 |
Не знает назначение полей и как вводить информацию |
Запуск теста, который объясняет, какие поля существуют в программе и для чего и как в них нужно вводить информацию |
3 |
Не знает основ бухгалтерского учета |
Запуск теста для объяснения бухгалтерского учета |
4 |
Не владеет информацией |
Запуск теста, объясняющего, как правильно и быстро получать нужную информацию |
5 |
Пользователь разбирается (допускает небольшие недочеты, например, когда торопится при вводе информации) |
Контроль пользователя в процессе ввода и исправление допущенных ошибок |
6 |
Пользователь прекрасно разбирается в том, что он делает |
|
Для составления выборок для обучения нейронной сети составлена таблица граничных оценок разных пользователей (таблица 4) Для каждого класса существуют свои «главные оценки» (самые низкие показатели). Например, для 3-го класса (пользователь плохо разбирается в бухгалтерском учете) очень низкие показатели для бухгалтерских счетов, цен и сумм.
На основании вышеуказанной таблицы была составлена обучающая выборка. В выборке каждому классу пользователя представлены по три набора оценок (наивысший, средний и самый минимальный для данного класса).
Эксперименты по обучению и тестированию нейросети проводились на нейроимитаторе. При этом были выбраны следующие параметры для нейронной сети: коэффициент характеристической функции - 0,1; надежность - 0,1.
В результате эксперимента изменялось число нейронов и плотность (на сколько нейронов будет подаваться каждый параметр, полученный с входного синапса). Для начала бралось минимальное число нейронов - 6 (равное количеству классов). Нейронная сеть полностью обучалась примерно за 4000 тактов. Затем увеличивалось число нейронов, и процесс обучения повторялся заново. Эксперименты проводились, начиная с максимального числа нейронов - 50. Было обнаружено, что при числе нейронов от 10 до 14 нейронная сеть обучалась наиболее быстро (примерно 1500 - 2500 тактов), а увеличение числа нейронов вело к снижению скорости обучения. Ниже представлен график зависимости скорости обучения НС от количества нейронов (рисунок 15).
Таблица 4 –Граничные оценки пользователя
|
|
Оценки |
|
_ |
|
|||||||||
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12
|
Классы |
||
10 |
10 |
10 |
10 |
10 |
10 |
10 |
10 |
10 |
10 |
8 ... 10 |
10 |
6 |
||
6 ... 10 |
7 ... 10 |
7 ... 10 |
7 ... 10 |
7 ... 10 |
7 ... 10 |
7 ... 10 |
0 ... 10 |
7 ... 10 |
7 ... 10 |
8 ... 10 |
9 ... 10 |
5
|
||
6 ... 10 |
3 ... 7 |
3 ... 7 |
3 ... 7 |
3 ... 7 |
3 ... 7 |
10 |
10 |
5.1 0 |
10 |
4 ... 8 |
0 ... 7 |
4 |
||
6 ... 10 |
3 ... 9 |
0 |
3 ... 9 |
0 |
3 ... 9 |
2 ... 10 |
1 |
5 ... 10 |
0 |
0 ... 6 |
0 ... 10 |
3 |
||
0 ... 5 |
0,1 |
0,2 |
0,1 |
0,2 |
0,1 |
0 |
0 ... 2 |
0 ... 2 |
0 ... 2 |
0 ... 7 |
0 ... 10 |
2 |
||
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
||

Рисунок 15-Зависимость времени обучения от числа нейронов
12.11 Менеджер (управляющий модуль нейросетевого блока).
Каждый компонент нейрокомпьютера представляет собой отдельный модуль. Для управления работой нейросетевой системы используется управляющая программа, которая выполняет функции загрузки модулей, организации обмена информацией между модулями базами данных и знаний. Данный компонент называется управляющим модулем (менеджером). Задача этого компонента - управление работой программного комплекса нейрокомпьютера, обеспечивающее аффективное взаимодействие всех его составных частей Рассмотреть всю схему НС блока. Менеджер осуществляет управление всеми этапами обработки информации.
Р ис –структура нейросетевого блока
№38 Особенности проектир-я нейросетевых интеллектуальных компонентов инфор-х систем
При проектир-ии интел. ИС нейросетевому моделир-ю любого эл. процесса д. предшествовать оприорный анализ объекта исследования или исх-х данных. При НС-ом моделировании он частично отл-ся от технологии статистич-го анализа и состит из след. этапов:
постан-ка задачи исслед-я
обобщ-е профес. з. об о. исслед-я на основе опыта, интуиции, изуч-я лит-ых ист-ков, консультации со спец-тами и тп.
формализация получен. оприорной информации об о. исслед-я.
уточнение и конкретизация постановки задачи
сбор исходных данных
формирование обучающей выборки.
№39 Функционирование нейросетевого решателя в режиме автоматического обучения

Y ’ – на тестовой выборке, Y0 – дообучение с учителем.
№40 Методы формирования значений выход-х параметров нейросети
1) фактич-я выборочная и эксперимент-я информация
- по данным происшедших событий
- по данным выполненных опытов и экспер-тов
2) экспертная информация
- определение параметра опытным экспертом
- определение группой экспетов с пом метода эксп-ой оценки
3) методы автом-го самообучения
- при помощи ЭС
- по методикам специалистов
- по известным аналитич-м зависимостям
- с исп-ем фикс-ых констант, мн-в, списков и т.д.