

18.Физическая организация данных в субд: индексирование. Организация индексов в виде б-деревьев и инвертированных списков.
Организация индексов в виде Б-деревьев.
Структура типа Б-дерево является частным случаем бинарного индекса древовидного типа, которая используется для построения наиболее важных и распространённых индексов.
Бинарные индексы обладают в большинстве случаев сравнительно высокой производительностью. Поэтому в настоящее время они используются почти во всех СУБД.
Высокая производительность бинарных индексов обеспечивается тем, что при их использовании удаётся избежать обязательного просмотра всего содержимого файла согласно его физической последовательности, которая требует больших затрат времени.
Построение Б-деревьев связано с простой идеей построения индексов над уже построенным индексом. Если уже построен плотный индекс для реальных данных, то сама индексная область может рассматриваться как основной файл, над которым надо снова построить неплотный индекс. Потом снова над новым индексом строится следующий неполный индекс и так до того момента пока не останется всего 1 индексный блок, при этом индекс на каждом из уровней будет неплотным по отношению к нижнему индексируемому уровню.
Т.о. на самом верхнем уровне другого индекса находится только 1 элемент структуры (страница, содержащая множество записей), который называется корневым.
Набор индексов обеспечивает быстрый и непосредственный доступ к набору последовательностей и, значит, итак.
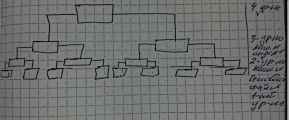
В результате такого построения получится некоторое дерево каждый родительский блок в котором связан с одинаковым количеством подчинённых блоков, число которых равно числу индексных записей, размещаемых в одном блоке. Количество обращений к диску при этом для поиска любой записи одинаково и равно количеству уровней построенных в дереве.
Структуры типа Б-дерево позволяют использовать специальные алгоритмы, осуществлять сбалансированную вставку и удаление значений.
Алгоритм вставки нового значения V в структуру типа Б-дерево:
на самом низком уровне набора индексов следует найти элемент N, c которым логически связано значение V. Если элемент N содержит свободно пространство, то значение V вставляется в него.
если свободного пространства нет, то элемент N разделяется на 2 элемента: N1 и N2. Допустим элемент N содержит 2n значений. Обозначим символом S множество значений S= 2n+1, где 2n – исходное количество значений, +1 – новый вставляемый элемент. Множество S упорядочено. Тогда n первых значений этой логической, уже упорядоченной последовательности необходимо поместить в элемент N1. n последних значений в элемент N2. А среднее между ними значение W в родительский элемент P на более высоком структурном уровне.
Далее этот процесс следует повторять для вставки среднего значения W в родительский элемент P на более высоком структурном уровне. В худшем случае процесс разделения элементов структуры может продлиться вплоть до корневого элемента с образованием нового иерархического уровня. Для удаления некоторого значения применяем аналогичный алгоритм, но в обратном порядке. Для изменения значения – удаляем его и вставляем в новое.
Инвертированные списки
БД должны предоставлять возможность проводить операции доступа к данным не только по первичным, но и по вторичным индексам
Для обеспечения ускорения доступа по вторичным индексам используются структуры называемые инвертированными списками.
При организации инвертированного списка можно выделить 3 уровня:
Самый нижний уровень представлен основным файлом. Над этим уровнем строится ещё 2 уровня которые, и представляют собой инвертированный список. На 1 уровне эта структура выводится в файл, в котором помещается значения вторичных индексов основного файла в упорядоченном состоянии. В этом файле предусмотрено поле, куда помещается ссылка на 2 уровень.
На 2 уровне для каждого значения вторичного индекса строится цепочка блоков, содержащих номера записей основного файла с этим значением вторичного индекса. Адрес первого блока этой цепочки помещается в поле ссылки 1 уровня. При этом блоки 2 уровня так же упорядочены по значениям вторичного индекса.
Механизм доступа к записям по вторичному индексу:
найти в области первого уровня заданное значение вторичного индекса
по ссылке считать блоки второго уровня, содержащие номера записей, с заданным значением вторичного индекса
прямым доступом загрузить в рабочую область пользователя содержимое всех записей, содержащих заданное значение вторичного индекса
Для одного основного файла может быть создано несколько инвертированных списков по разным вторичным индексам. Если БД постоянно изменяется, дополняется, модифицируется, то наличие большого количества инвертированных списков или индексных файлов по вторичным индексам может резко замедлить процесс обработки информации.
Модификация основного файла при такой ситуации требует:
изменить запись основного файла
исключить старую ссылку на предыдущее значение вторичного индекса.
добавить новую ссылку на новое значение вторичного индекса