

Модели, содержащие только качественные объясняющие переменные
Регрессионные модели, содержащие лишь качественные объясняющие переменные, называются моделями дисперсионного анализа (ANOVA-моделями).
Например, пусть y - начальная заработная плата.
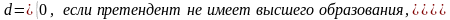
Тогда зависимость можно выразить моделью парной регрессии
y = α + βd + ε, (4.39)
Очевидно, что Mу (d = 0) = α + β·0 = 0,
Mу (d = 1) = α + β·1 = α + β.
При этом коэффициент α определяет среднюю начальную заработную плату при отсутствии высшего образования. Коэффициент β указывает, на какую величину отличаются средние начальные заработные платы при наличии или отсутствии высшего образования у претендента. Проверяя статистическую значимость коэффициента β с помощью t-статистики либо значимость коэффициента детерминации R2 с помощью F-статистики, можно определить, влияет или нет наличие высшего образования на начальную заработную плату.
Нетрудно заметить, что ANOVA-модели представляют собой кусочно-постоянные функции. Однако такие модели в экономике крайне редки. Гораздо чаще встречаются модели, содержащие как качественные, так и количественные переменные.
Модели, в которых объясняющие переменные носят как количественный, так и качественный характер
Называются моделями ковариационного анализа (ANCOVA- моделями).
Рассмотрим простейшую ANCOVA - модель с одной количественной и одной качественной переменной, имеющей два альтернативных состояния:
y = α + β1x + β2d + ε. (4.40)
Пусть, например, y – заработная плата сотрудника фирмы, x – стаж сотрудника, d – пол сотрудника, т. е.
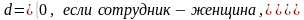
Тогда ожидаемое значение заработной платы сотрудников при х годах трудового стажа будет:
Mу (x, d = 0) = α + β1x + β2·0 = α + β1x – для женщины. (4.41)
Mу (x, d = 1) = α + β1x + β2·1 = (α + β2)+ β1x – для мужчины. (4.42)
Заработная плата в данном случае является линейной функцией от стажа работы. Причем и для мужчин и для женщин заработная плата меняется с одним и тем же коэффициентом пропорциональности β1. А вот свободные члены в моделях (4.41), (4.42) отличаются на величину β2. Проверив с помощью t-статистики статистические значимости коэффициентов α и (α + β2), можно определить, имеет ли место в фирме дискриминация по половому признаку. Если эти коэффициенты окажутся статистически значимыми, то, очевидно, дискриминация есть. Более того, при β2 > 0 – она будет в пользу мужчин, при β2 < 0 – в пользу женщин.
В данном случае пол сотрудников имеет два альтернативных значения, и в модели это отражается одной фиктивной переменной. Возникает вопрос, нельзя ли с помощью большего числа фиктивных переменных обрисовать более сложные комбинации? Например, пусть
y = α + β1x + β2d1 + β3d2 + ε. (4.43)
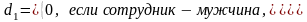

Но в этой ситуации между переменными d1 и d2 существует строгая линейная зависимость: d2 = 1 – d1. Мы попадаем в ситуацию совершенной мулътиколлинеарности, при которой коэффициенты β2 и β3 однозначно определены быть не могут. Простейшим способом преодоления данной проблемы является отбрасывание одной из фиктивных переменных и использование для рассматриваемой задачи модели (4.40). Применяя аналогичные выкладки, можно получить следующее общее правило:
Если качественная переменная имеет к альтернативных значении, то при моделировании используются только (к - 1) фиктивных переменных.
Если не следовать данному правилу, то при моделировании исследователь попадает в ситуацию совершенной мультиколлинеарности или так называемую ловушку фиктивной переменной.
Значения фиктивной переменной можно изменять на противоположные. Суть модели от этого не изменится. Например, в модели (4.40) можно положить, что:
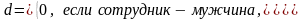
Однако при этом знак коэффициента β1 изменится на противоположный.
Значение качественной переменной, для которого принимается d = 0, называется базовым или сравнительным. Выбор базового значения обычно диктуется целями исследования, но может быть и произвольным.
Коэффициент β1 в модели (4.40) иногда называется дифференциальным коэффициентом свободного члена, т. к. он показывает, на какую величину отличается свободный член модели при значении фиктивной переменной, равном единице, от свободного члена модели при базовом значении фиктивной переменной.
Пусть рассматривается модель с двумя объясняющими переменными, одна из которых количественная, а другая – качественная. Причем качественная переменная имеет три альтернативы, Например, ситуация, связанная с расходами на содержание ребенка, может быть связана с доходами домохозяйств и возрастом ребенка: дошкольный, младший школьный и старший школьный. Так как качественная переменная связана с тремя альтернативами, то по общему правилу моделирования необходимо использовать две качественные переменные. Таким образом, модель может быть представлена в виде:
y = α + β1x + β2d1 + β3d2 + ε. (4.44)
где y - расходы. x - доходы домохозяйств.
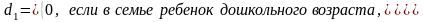
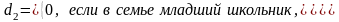
Таким образом, получаются следующие зависимости.
Средний расход на дошкольника:
Mу (x, d1 = 0, d2 = 0) = α + β1x. (4.45)
Средний расход на младшего школьника:
Mу (x, d1 = 1, d2 = 0) = α + β1x + β2·1 + β3·0 = (α + β2)+ β1x . (4.46)
Средний расход на старшего школьника:
Mу (x, d1 = 1, d2 = 1) = α + β1x + β2·1 + β3·1 = (α + β2+ β3)+ β1x . (4.47)
Здесь β2, β3 – дифференциальные свободные члены. Базовым значением качественной переменной является значение «дошкольник». После определения коэффициентов регрессии (4.44) определяется статистическая значимость коэффициентов β2, β3 на основе t-статистики. Если коэффициенты оказываются статистически незначимыми, то можно сделать вывод, что возраст ребенка не оказывает существенного влияния на его содержание.