

С/К «БАЗЫ ЗНАНИЙ И ЭКСПЕРТНЫЕ СИСТЕМЫ», 2008 г.
Введение
Настоящий курс посвящен одному из важных направлений современной информатики – искусственному интеллекту. Основой всех систем искусственного интеллекта является представление знаний, т.е. информации о свойствах и закономерностях тех или иных предметных областей. Предметная область – это некий фрагмент окружающего нас реального мира, процессов развития современного общества, научная теория и пр. Для представления знаний используются различные формальные модели, позволяющие не рассматривать бесконечное разнообразие предметной области, а сосредоточиться на наиболее существенных ее особенностях.
В литературе можно найти много различных определений самого понятия искусственного интеллекта (ИИ). Вот некоторые из них:
ИИ – это свойство автоматических или автоматизированных систем брать на себя отдельные функции интеллекта человека, т.е., например, выбирать и принимать оптимальные решения на основе ранее накопленного опыта и рационального анализа внешних воздействий.
ИИ – это программные системы, выполняющие функции, которые традиционно считаются прерогативой человека. Интеллектуальная система способна решать задачи, традиционно считающиеся творческими, принадлежащие конкретной предметной области, знания о которой хранятся в памяти такой системы. Структура интеллектуальной системы включает три основных блока — базу знаний, решатель и интеллектуальный интерфейс.
Одним из наиболее успешных направлений ИИ являются экспертные системы (ЭС). ЭС – это программная система, в которую включены знания специалистов (экспертов) о некоторой предметной области и которая в пределах этой области способна принимать экспертные решения. В рамках экспертных систем к настоящему моменту достигнуты успехи в таких областях, как медицинская диагностика, обнаружение неисправностей в электронном оборудовании финансовая сфера и пр. Обычно ЭС используется как электронный консультант, который с помощью советов и рекомендаций помогает пользователю находить правильные решения возникающих у него проблем. Хорошо разработанная ЭС действует как эксперт-профессионал в данной предметной области. В 1950-м году английский математик и логик Алан Тьюринг предложил тест (иногда называемый «английской гостиной»), с помощью которого можно оценить «интеллектуальные» способности компьютера. Вот его описание:
«Человек взаимодействует с одним компьютером и одним человеком. На основании ответов на вопросы он должен определить, с кем он разговаривает: с человеком или компьютерной программой. Задача компьютерной программы — ввести человека в заблуждение, заставив сделать неверный выбор».
Все участники теста не видят друг друга. Если судья не может сказать определенно, кто из собеседников является человеком, то считается, что машина прошла тест.
Отметим два принципиально различных подхода к разработке систем ИИ. Согласно первому при создании систем ИИ не ставится задача моделирования мыслительной деятельности человека. Согласно второму, наоборот, требуется, чтобы системы ИИ решали задачи так, как это делает человек. Большинство систем ИИ было разработано в соответствии с первым подходом. Однако в настоящее время значение второго подхода стало расти.
Процесс мышления, или, иначе говоря, работа головного мозга, до сих пор до конца не изучен и в настоящем курсе предлагается лишь самая простая его модель, позаимствованная из одного из литературных источников.
Одна ячейка человеческого глаза способна выполнить за 10 мсек обработку, эквивалентную решению 500 нелинейных дифференциальных уравнений со 100 переменными. Суперкомпьютеру для решения подобной системы потребуется несколько минут. В глазе 10 миллионов ячеек, которые работают параллельно. Суперкомпьютер потратит много лет, чтобы выполнить работу глаза за 1 секунду.
Простейшая схема областей головного мозга, участвующих в обработке информации, выглядит так:
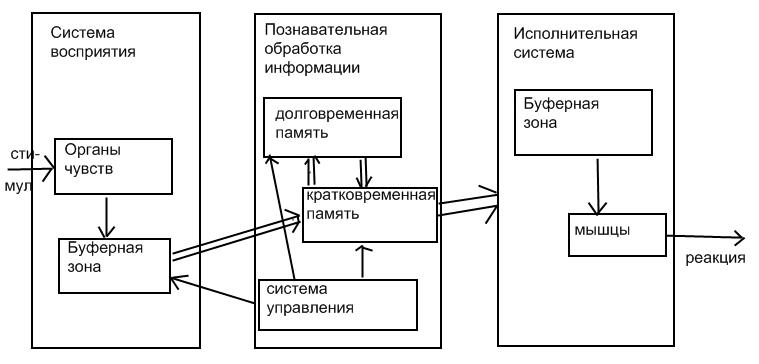
В долговременной памяти хранятся объекты и связи между ними. В кратковременную память все время поступает информация. Обработка ее быстрая (отдергиваем руку от горячего, играем в мяч и пр.). Перевод информации из кратковременной памяти в долговременную занимает 15 – 20 минут. Это проверено на травмированных людях.
В мозгу хранятся символьные образы. Они объединяются в так называемые чанки – наборы фактов и связей между ними. Чанки воспринимаются как единое целое. В каждый момент времени человек может обработать от 4 до 7 чанков.
Успехи человека в деятельности в предметной области во многом зависят от его способности образовывать чанки. Эксперт соединяет в чанки большие объемы данных, устанавливает иерархические связи. Таким образом, объем знаний эксперта зависит от величины чанков.
Средний специалист в предметной области помнит 50 – 100 тысяч чанков. Это требует 10 – 20 лет обучения.
Представление знаний.
Данные – это отдельные факты, характеризующие объекты, процессы и явления предметной области, а также их свойства.
В компьютере данные трансформируются, условно проходя следующие этапы:
1) D1 – данные как результат измерений и наблюдений.
2) D2 – данные на материальных носителях информации (таблицы, протоколы, справочники).
3) D3 – модели (структуры) данных в виде диаграмм, графиков, функций.
4) D4 – данные в компьютере на языке описания данных.
5) D5 – база данных на машинных носителях информации.
Знания основаны на данных, полученных, в основном, эмпирическим путем. Они представляют собой результат мыслительной деятельности человека, направленной на обобщение его опыта, полученного в результате практической деятельности.
Знания – это закономерности предметной области (принципы, связи, законы), полученные в результате теоретических исследований, практической деятельности и профессионального опыта, позволяющие специалистам ставить и решать задачи в этой области.
При обработке в компьютере знания трансформируются аналогично данным:
1) K1 – знания в памяти человека как результат мышления.
2) K2 – знания на материальных носителях (учебники, методические пособия).
3) K3 – поле знаний, т.е. условное описание основных объектов предметной области, их атрибутов и связывающих их закономерностей.
4) K4 – знания, описанные на языках представления знаний (языки логического программирования, продукционные языки и др.).
5) K5 – база знаний на машинных носителях информации.
Часто используются следующие определения знаний через данные:
Знания– это хорошо структурированные данные.
Знания – это метаданные (данные о данных).
Способы определения понятий:
-
С помощью интенсионала, т.е. определение через соотнесение с понятием более высокого уровня абстракции с указанием специфических свойств. Например: Персональный компьютер – это небольшая относительно дешевая ЭВМ, которую можно поставить на стол.
-
С помощью экстенсионала, т.е. через соотнесение с понятием более низкого уровня абстракции или через перечисление фактов, относящихся к определяемому объекту. Например: Персональный компьютер – это IBM PC, Mac, Sincler и т.д.
Для хранения знаний используются базы знаний. Это относительно небольшие, но дорогие информационные массивы.
Знания могут классифицироваться следующим образом:
-
Поверхностные, т.е. знания о видимых взаимосвязях между отдельными объектами предметной области (ПО).
-
Глубинные, т.е. абстракции, аналогии, схемы, отображающие структуру и природу процессов, протекающих в ПО. Эти знания объясняют явления и могут использоваться для прогнозирования поведения объектов ПО.
Современные ЭС в основном работают с поверхностными знаниями.
Процедурные и декларативные знания. Понятие декларативного языка (представления знаний).
Модели представления знаний.
-
формальные логические модели;
-
продукционные модели;
-
семантические сети;
-
фреймы
-
нейронные сети.
-
Формальная логическая модель.
Основана на логике предикатов первого порядка. Знания представляются в виде фактов и правил. Факты – это предикаты, представляющие свойства объектов предметной области и отношения между ними. Правила позволяют выводить новые факты, т.е. указывать, при каких условиях некоторые предикаты могут считаться новыми фактами.
-
Продукционная модель.
Позволяет представить знания в виде предложений типа:
Если <условие> то <действие>.
Условие называется антецедентом. Под ним понимается некоторое предложение-образец, по которому выполняется поиск в БЗ.
Действие называется консеквентом. Оно выполняется при успешном исходе поиска и может само выступать далее как условие, либо быть терминальным, т.е. завершающим работу системы.
-
Семантические сети.
Семантическая сеть – это ориентированный граф, вершины которого являются понятиями, а дуги – отношениями между ними. Так как типов отношений может быть много, отношения указываются при дугах, которые в этом случае называются нагруженными.
Типы отношений: класс – элемент класса (цветок – роза), свойство – значение (цвет – желтый), пример элемента класса (роза – чайная).
Типы сетей:
– однородные (с одним типом отношений), используются редко);
– неоднородные (с различными типами отношений)
Наиболее частые типы отношений:
– часть – целое;
– функциональные (с глаголами «производит», «влияет» и т.д.);
– количественные (больше, меньше и пр.);
– пространственные (далеко, близко, под, над и т.д.);
– временные (раньше позже, в течение);
– атрибутивные (иметь свойство, иметь значение);
– логические (И, ИЛИ, НЕ);
– лингвистические и пр.
Приведем пример семантической сети, представляющей следующий фрагмент знаний: «Автомобиль – это вид транспорта, имеющий двигатель. Гражданин Иванов любит автомобили и ему принадлежит машина Жигули красного цвета»:
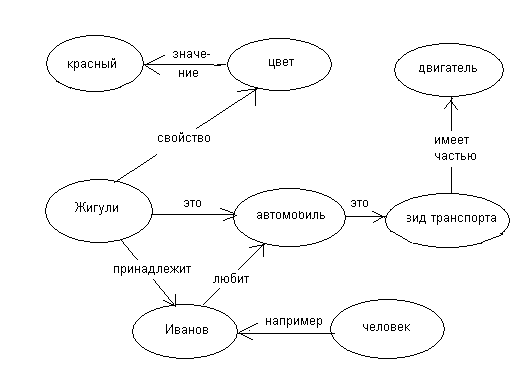
Проблема поиска решений в базе знаний в виде семантической сети сводится к задаче поиска фрагмента сети, соответствующего некоторой подсети, отражающей поставленной к БЗ вопрос.
-
Фреймы
Термин предложен одним из первых исследователей ИИ Марвином Минским в 70-е годы. Известны несколько определений фрейма:
Фрейм – это абстрактный образ для представления некоего стереотипа восприятия.
Фрейм – это структура данных для представления некоторого концептуального объекта. Она охватывает все стороны этого объекта. Характеристики объекта называются слотами. Значения характеристик – наполнители (значения) слотов.
Понятие фрейма тесно связано с абстрактными образами. Например, абстрактным образом является объект «комната». Ее характеристики: жилое помещение, имеет 4 стены, пол, потолок, окна и двери, характеризуется площадью, высотой потолка, покрытием пола и т.д. Здесь нет никаких конкретных значений. Но если мы укажем, что данная комната имеет одно окно, одну дверь, ее площадь 15 кв.м, высота потолка 3 м, пол паркетный и пр. , то получим «пример» комнаты.
Таким образом, нужно различать фреймы-прототипы (для моделирования абстрактных образов) и фреймы-экземпляры (для конкретных примеров абстрактных образов).
Типы фреймов:
фреймы-структуры (используются для обозначения объектов и понятий, таких как дом, комната, вексель, заем);
фреймы-роли (используются для обозначения, например, профессии или должности служащих: кассир, клиент, преподаватель, студент);
фреймы-сценарии (используются для обозначения действий, протекающих во времени: собрание акционеров, экзамен, сессия);
фреймы-ситуации (используются для обозначения событий: тревога, авария, банкротство).
Структуру фрейма можно представить следующей таблицей:
-
Имя фрейма
Имя слота
Значение слота
Способ получения значения
Присоединенная процедура
Способы получения значений слотов:
– по умолчанию от фрейма-образца;
– через наследование свойств от фрейма, указанного в слоте АКО (a kind of, по-русски – это);
– с помощью вычисления значения формулы, указанной в столбце «Способ получения значения»;
– путем выполнения присоединенной процедуры;
– в процессе диалога с пользователем;
– из базы данных.
Так же, как и в семантических сетях, важнейшее свойство фреймов – это наследование свойств. Оно происходит по АКО-связям. Слот АКО указывает на фрейм более высокого уровня иерархии. Наследование свойств может быть частичным, так как фреймы более низкого уровня могут иметь собственные значения.
Пример.
В курсе подробно рассматриваются формальная логическая и продукционная модели.
Понятие логического вывода.
Логический вывод – это решение проблемы дедукции с помощью резолюционных методов (прямая дедукция) или метода Маслова (обратная дедукция).
Проблема дедукции (в ИВ и ИП).
Пусть имеется множество формул S = {H1, H2, … , Hn }, а также еще одна формула С. Говорят, что С является логическим следствием множества S (S╞ C), если при любой интерпретации, при которой все Нi истинны, С также истинна. При этом формулы Hi называются гипотезами. Проблема дедукции – это исследование того, является ли произвольно заданная формула С логическим следствием заданного множества гипотез S.
Утверждение. Для того, чтобы S╞ C, н. и д., чтобы формула F = H1 H2 … Hn C была общезначимой.
Воспользуемся эквивалентным преобразованием для исключения импликации:
F1 (H1 H2 … Hn) C H1 H2 … Hn C = F2.
Решение проблемы дедукции методом обратной дедукции – это доказательство (или опровержение) того, что F2 – общезначима.
Рассмотрим F3 = F2. Для того, чтобы S╞ C, н. и д., чтобы F3 была невыполнимой.
F3 (H1 H2 … Hn C) H1 H2 … Hn C = F4.
Решение проблемы дедукции методом обратной дедукции – это доказательство (или опровержение) того, что F4 – невыполнима.
Определение 1.1. Пусть два дизъюнкта C1 и C2 имеют следующий вид: C1=AX, C2=B Y, где A и B — некоторые дизъюнкты, а X и Y — атомарные формулы такие, что X=Y.
Тогда дизъюнкт (C1\X) (C2\ Y) является резольвентой дизъюнктов C1 и C2.
Определение 1.2. Логическим выводом дизъюнкта C из множества дизъюнктов S назовем такую последовательность дизъюнктов C1,C2,...,Cn, что CiS или Ci является резольвентой некоторых Cj и Ck, j<i, k<i, 1< i n, и Cn=C.
В системах искусственного интеллекта понятие логического вывода и выводимости тесно связаны с принципом дедукции и резолюционным выводом пустого дизъюнкта .
Определение 1.3. Будем говорить, что целевой дизъюнкт (цель) C выводим (доказуем) в множестве гипотез S={H1,...,Hm}, если в S существует опровержение С, то есть логический вывод пустого дизъюнкта из расширенного множества дизъюнктов S C={H1,...,Hm, C}: C1,C2,...,Cn, C1= C, Cn= .
Для того, чтобы различать вывод цели в смысле определения 1.3 и вывод как последовательность резольвент в смысле определения 1.2, последний будем называть резолюционным выводом непустого дизъюнкта.
Рассмотрим подробнее понятие хорновских дизъюнктов и взаимосвязь последних с базами знаний.
Определение 1.4. Хорновским называется такой дизъюнкт, который содержит не более одной позитивной литеры. Хорновский дизъюнкт называется точным, если он содержит позитивную литеру. В противном случае он называется негативным.
Частным случаем точного дизъюнкта является унитарный позитивный дизъюнкт, сводящийся к одиночной позитивной литере. Если дизъюнкт представлен одиночной позитивной литерой, не содержащий переменных, то такой дизъюнкт называется элементарным.
В системах искусственного интеллекта точный дизъюнкт выражает некоторое правило: негативные литеры соответствуют посылкам (которые представлены соответствующими высказываниями), а позитивная литера представляет заключение. Унитарный позитивный дизъюнкт представляет некоторый факт, то есть заключение, не зависящее ни от каких посылок. Задача состоит в том, чтобы проверить, является ли некая формула, называемая целью, логически выводимой из множества фактов и правил. В этом случае используется метод резолюций, являющийся методом доказательства от противного. Исходя из фактов, правил и отрицания цели, представленного негативным хорновским дизъюнктом, метод резолюций пытается прийти к противоречию — пустому дизъюнкту .
Без ограничения общности можно рассматривать лишь такие хорновские дизъюнкты, все литеры которых различны. Таким образом, каждый дизъюнкт множества гипотез, расширенного отрицанием цели (расширенного множества), будет иметь один из трех следующих видов:
-
p, положительная литера; либо
-
p q1 q2... qn, где n≥1 и q1, q2, ..., qn — различные литеры, p —литера; либо
-
q1 q2...qm, где m≥1 и q1, q2, ..., qm — различные литеры.
Из рассмотрения можно исключить также тавтологии, то есть для дизъюнктов вида pq1q2...qn дополнительно потребовать, чтобы литера p не совпадала ни с одной из литер q1, q2, ..., qn.
Классическим механизмом логического вывода является метод резолюций, предложенный Дж.Робинсоном в 1965 году и опирающийся на принцип дедукции. Общая идея метода состоит в следующем: чтобы получить некоторое заключение С, исходя из гипотез H1,H2,...,Hn, то есть проверить, является ли C логическим следствием гипотез H1,H2,...,Hn, достаточно проверить, является ли противоречивой формула H1H2...HnC, в которой отрицание заключения добавлено к исходным гипотезам. При этом рассматриваются лишь формулы стандартного вида — КНФ. Тогда полученная формула может быть интерпретирована как множество дизъюнктов S={H1,H2, ...,Hn,C}, доказательство невыполнимости которого эквивалентно построению в нем логического вывода пустого дизъюнкта .
Таким образом, невыполнимость множества S можно проверить, порождая логические следствия из него до тех пор, пока не будет получен пустой дизъюнкт L. Для порождения логических следствий используется правило резолюции:
{AX,B X} ╞ AB, где A, B, X —формулы.
В силу неразрешимости логики предикатов первого порядка для выполнимого множества дизъюнктов S процедура, основанная на принципе резолюций, может работать бесконечно долго.
Метод резолюций полон в том смысле, что если существует доказательство некоторой формулы, то метод резолюций всегда его находит. Однако если предполагаемое заключение не выводимо из заданного множества гипотез, резолюция может привести к бесконечному перебору.
Метод резолюции является недетерминированным, и в общем случае неэффективен. Его наиболее существенный недостаток заключается в формировании всевозможных резольвент, большинство из которых оказывается ненужными. Существуют различные модификации метода резолюций, направленные на уменьшение длины вывода и, в конечном итоге, на сокращение числа лишних порожденных резольвент, не влияющих на выводимость пустого дизъюнкта. Эти модификации известны в литературе как стратегии метода резолюций или суживающие стратегии. Общим правилом является исключение из рассмотрения порождаемых дизъюнктов типа тавтологий и поглощенных дизъюнктов, которое не меняет выполнимости множества дизъюнктов.
Наиболее известными суживающими стратегиями являются семантическая, лок-резолюция и линейная, а также различные их модификации.
В семантической резолюции используется интерпретация для разделения множества дизъюнктов S на два класса: S1 — непустое множество дизъюнктов, которое выполняется (т.е. принимает значение «истина») некоторой интерпретацией, S2 — непустое множество дизъюнктов, которое не выполняется (т.е. принимает значение «ложь») этой интерпретацией; S1S2=S. Разрешается резольвирование дизъюнктов, принадлежащих только разным множествам, и запрещается образование резольвент от дизъюнктов, входящих в одно и то же множество. Тем самым сокращается образование ненужных дизъюнктов, так как только резольвированием из разных множеств можно получить пустой дизъюнкт.
Другим способом ограничения количества порождаемых дизъюнктов является упорядочение предикатных букв. Если имеется упорядочение предикатных букв типа P1>P2>...>Pk, то разрешается резольвирование литеры, обладающей наибольшим порядком, то есть P1.
В семантической резолюции допускается любая интерпретация и любое упорядочение предикатных букв. Семантическая резолюция полна.
Идея лок-резолюции состоит в использовании индексов для упорядочения литер в дизъюнктах из множества дизъюнктов S. Иными словами, она включает индексацию произвольным образом каждого вхождения литеры в S некоторым целым числом; разные вхождения одной и той же литеры в S могут быть индексированы по-разному. После этого резольвировать разрешается только литеры с наименьшим индексом в каждом из дизъюнктов. Литеры в резольвентах наследуют свои индексы из посылок. Если литера в резольвенте может унаследовать более одного индекса, то ей ставится в соответствие наименьший из этих индексов.
Лок-резолюция полна и является весьма эффективным методом логического вывода. Основным недостатком лок-резолюции является то, что она несовместима с большинством других стратегий, даже таких естественных, как, например, со стратегией избегания противоречивых дизъюнктов. Кроме того, совершенно неясно, как по данному множеству дизъюнктов a priori установить, какая из начальных индексаций литер дает более эффективную лок-резолюцию.
Линейная резолюция. Линейным выводом из множества дизъюнктов S называется последовательность дизъюнктов C1,C2,...,Cn, в которой верхний дизъюнкт С1S, а каждый член Ci+1, i=1,2,...,n-1, является резольвентой дизъюнкта Ci, называемого центральным, и дизъюнкта Bi, называемого боковым. При этом Bi должен удовлетворять одному из следующих двух условий:
-
либо BiS, i=1,2,...,n-1,
2) либо Bi является некоторым дизъюнктом Cj, предшествующим в выводе дизъюнкту Ci, то есть j<i. Таким образом, линейный вывод начинается с некоторого дизъюнкта, применяет к нему правило резолюции для получения резольвенты, затем применяет резолюцию к этой резольвенте и некоторому дизъюнкту, и так далее, пока не будет получен пустой дизъюнкт.
Линейная резолюция может быть дополнительно усилена введением понятия упорядоченного дизъюнкта и использованием информации о резольвированных литерах. В таком виде она называется OL-выводом и является разновидностью линейной резолюции с функцией выбора (SL-вывод)
Линейная резолюция и OL-вывод полны. Линейная резолюция является одной из наиболее эффективных стратегий. Особую привлекательность линейному выводу придает его простая структура. Кроме того, линейная резолюция совместима со стратегией множества поддержки, вместе с ней удобно применять эвристические методы.
Все рассмотренные выше стратегии эффективнее общего метода резолюций, однако, остаются переборными.
Дальнейшее повышение эффективности общих суживающих методов достигается за счет ограничения класса рассматриваемых формул. Важнейшим из частных случаев, для которых метод резолюций дает хорошую оценку по времени, является случай хорновских дизъюнктов, то есть таких дизъюнктов, которые содержат не более одной позитивной литеры.
Имеются уточнения линейной резолюции, которые эффективны (для ИВ), но не полны в общем случае. Речь идет о единичной и входной линейной резолюциях. Несмотря на свою неполноту, эти стратегии гораздо легче реализовать на ЭВМ, чем общий случай линейной резолюции, они эффективнее линейной резолюции и достаточно мощны для того, чтобы доказать большой класс теорем. Можно показать, что единичная и входная резолюции эквивалентны, они полны для случая хорновских дизъюнктов.
Входная линейная резолюция (SLD-резолюция) — линейная резолюция, в которой одна из двух посылок — входной дизъюнкт, то есть член заданного исходного множества S дизъюнктов. При реализации входной линейной резолюции, как правило, в качестве верхнего берется дизъюнкт цели, а в качестве боковых дизъюнктов —гипотезы (факты и правила базы знаний). Входная линейная резолюция легла в основу языка логического программирования Пролог. Пролог обладает универсальными средствами управления поиском логического вывода — механизмами рекурсивного вызова процедур, обобщенного сопоставления с образцом (унификацией), поиска с возвратами (бэктрекингом). Эти механизмы обеспечивают недетерминированный вывод и позволяют находить все возможные решения описанной логической программой задачи.
Единичная резолюция — это линейная резолюция, в которой по крайней мере одна из посылок — единичный дизъюнкт. Использование единичной резолюции приводит к тому, что на каждом этапе некая литера удаляется из одного дизъюнкта. Поэтому алгоритм проверки невыполнимости конечных множеств хорновских дизъюнктов ИВ с помощью линейной единичной резолюции имеет сложность N2 , где N — число литер, первоначально присутствующих в S с учетом повторений. Поскольку единичная и входная линейная резолюции эквивалентны, для последней справедлива та же оценка. Сейчас существует линейный по времени алгоритм проверки невыполнимости множеств хорновских дизъюнктов ИВ.
Для ИП оценка эффективности этих резолюционных стратегий будет существенно хуже (в общем случае NP-сложный алгоритм), так как дизъюнкт ИП может допускать бесконечно много конкретизаций. Кроме того, в логике предикатов затруднено нахождение контрарных пар, то есть литер, играющих роль X и X в правиле резолюций. Это приводит к необходимости предварительного этапа согласования формул таким образом, чтобы аргументы отсекаемых контрарных литер совпадали. Согласующая процедура называется унификацией.
Для получения полиномиальной оценки по времени необходимо введение дополнительных ограничений на КНФ и хорновские формулы ИП. Так, для ИП предложен полиномиальный (квадратичный по времени) алгоритм для баз знаний, описываемых хорновскими формулами с одноместными предикатами. Существенные ограничения накладываются также на использование функций. Предлагался частный случай семантической резолюции, эффективный для сингулярных баз знаний, т.е. описываемых одноместными предикатами и функциями. Однако накладываемые в этих случаях ограничения на базы знаний на практике неприемлемы, поскольку, в то время как любой m‑арный предикат может быть представлен в виде произведения бинарных, требование одноместности предикатов базы знаний существенно снижает выразительную способность логической модели.
Методом, альтернативным резолюции, является обратный дедуктивный метод Маслова. Он сформулирован для аксиоматических систем, но может быть также применен и для логических исчислений. В этом методе поиск вывода идет от целевой формулы к аксиомам или постулатам, истинность которых априорно известна. Чтобы определить выводимость формулы C из посылок H1,H2,...,Hn, необходимо найти формулы-предшественники, из которых C может быть выведена одним применением правила вывода. Затем по каждой из полученных формул-предшественников, не являющейся аксиомой исчисления, в свою очередь определяется множество непосредственных формул-предшественников и так далее, вплоть до построения окончательного вывода.
На основе обратного метода вывода были разработаны и реализованы машинный алгоритм вывода и алгоритм машинного поиска логического вывода в ИВ, носившие экспериментальный характер, было показано что метод может быть также распространен на весьма широкие классы дедуктивных систем.
Для стандартизированных формул метода резолюций оба метода примерно эквивалентны. Кроме того, идеи стратегий и доказательств их полноты обычно равноприемлемы для метода резолюций и обратного метода.
Поскольку задача разрешимости логического выражения, приведенного к КНФ, для ИП является NP-полной, общая оценка этих методов совпадает с оценкой для метода резолюций. Однако для некоторых частных случаев их применение может приводить к существенному ускорению вывода.
Резолюционные и связанные с ними методы весьма интересны, так как являются систематическими и могут быть реализованы на ЭВМ. Однако ввиду алгоритмической неразрешимости ИП невозможно определить эффективную стратегию решения для всех областей приложения. Кроме того, эффективность логических программ резко падает с увеличением числа предложений. Поэтому на практике добиваются устранения причин «комбинаторного взрыва» числа резолюций, имеющего место при доказательстве теорем практической степени сложности, за счет использования семантики и встраивания в правила вывода и алгоритмы унификации специфики конкретной области применения.
Учет контекста применения унификаций обеспечивается, как правило, внелогическими средствами. К ним относятся так называемые средства управления ходом вычислений, такие, как операторы отсечения и замораживания, имеющиеся практически во всех реализациях языка Пролог, специальные мета-конструкции. В одной из версий языка Пролог (IC-Пролог) к правилам могут добавляться специальные аннотации, влияющие на порядок вычислений.
Таким образом, основной проблемой логического программирования и, тем самым, логической модели БЗ, является его относительная малоэффективность по времени. Поэтому основной задачей для систем логического программирования, использующих механизмы автоматического доказательства теорем, является ускорение логического вывода. Существует два направления решения этой задачи:
-
Использование естественного параллелизма методов логического вывода, подразумевающее разработку параллельных реализаций Пролога и соответствующих аппаратных средств. Эта идея легла в основу проекта создания ЭВМ пятого поколения с принципиально новой, параллельной архитектурой;
-
Разработка новых эффективных универсальных методов решения логических задач, поиск методов и средств ускорения логического вывода.
Рассмотрим пример логического вывода.
S =
{ 1) P(a,b); 2) P(b,c); 3) (P(x,y), P(a,z), P((b,u)); 4) (P(x,y), P(b,y))}
C = P(a,c).
Присоединим отрицание цели к множеству гипотез:
-
P(a,b); 4) (P(x,y), P(b,y));
-
P(b,c); 5) P(a,c).
-
) (P(x,y), P(a,z), P((b,u));
Необходимо помнить, что резолюционные методы в ИП содержат две основные процедуры: унификацию и резолюцию.
Рассмотрим логические выводы, построенные двумя методами: единичной резолюцией и входной линейной резолюцией.
МЕТОДЫ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ ЛОГИЧЕСКОГО ВЫВОДА.
Применение метода абстракций
Для повышение эффективности резолюционных методов часто используются различные сокращающие перебор (суживающие) стратегии. Большинство суживающих стратегий реализуется путем включения в инструментальные средства создания систем ИИ специфических конструкций, управляющих перебором. Как правило, такие стратегии требуют ручной разработки высококвалифицированными специалистами. Поэтому важной представляется задача создания суживающих стратегий, которые могли бы использоваться в автоматическом режиме.
В настоящем разделе рассматривается метод абстракций, впервые предложенный и теоретически обоснованный американским исследователем Плейстедом. Коротко этот метод можно сформулировать следующим образом. По исходной задаче А строится более простая задача В таким образом, чтобы для каждого решения задачи А имелось решение задачи В, структура которого подобна решению задачи А. Таким образом, найденные решения простой задачи В могут использоваться как некие схемы для поиска возможных решений первоначальной задачи А (хотя некоторые решения задачи B могут не привести к цели). Задача В строится с помощью так называемых абстракционных отображений и называется абстракционной задачей или абстракцией задачи А. Очевидно, для успешного применения данного метода необходимо, чтобы, во-первых, абстракционная задача решалась существенно проще исходной и, во-вторых, чтобы решения абстракционной задачи позволяли сократить перебор, необходимый для поиска решений исходной задачи. Ниже мы покажем, что предлагаемая суживающая стратегия удовлетворяет обоим требованиям.
Как уже было сказано, теоретической основой ИИ является проблема дедукции. Проблема дедукции формулируется как для исчисления предикатов (ИП), так и для исчисления высказываний (ИВ). В последнем случае под литерами понимаются высказывания или их отрицания. Применяя метод абстракций, мы можем заменить все предикаты БЗ и цели независимо от значений их аргументов высказываниями. Такая абстракция носит название пропозициональной. Ее определение таково.
Пусть D - дизъюнкт вида:
(L1, L2, … , Lk).
Тогда пропозициональная абстракция определяется абстракционным отображением
f(D) = D¢, где D¢ - дизъюнкт вида
(L¢1, L¢2, … , L¢k), L¢i = P, если Li = P( l1, … , ln ) и L¢i = ùP, если Li = ù (l1, … , ln), 1 £ i £ k.
В построенной таким образом простой модели проблема дедукции решается значительно проще. В ИП задача поиска логического вывода в общем случае является NP-полной, а для получения полиномиальной оценки по времени необходимы существенные ограничения на хорновские дизъюнкты (например, использование лишь одноместных предикатов). В то же время в ИВ большинство резолюционных методов имеют оценку трудоемкости Cn2, где n - число литер, присутствующих в S, а предложенный ниже метод имеет оценку Cn.
Таким образом, суживающая стратегия, которую мы будем рассматривать, построена на основе пропозициональной абстракции. В противоположность большинству известных суживающих стратегий она предусматривает настройку алгоритма поиска логических выводов на работу с конкретной БЗ. Ее целесообразно применять при работе со стационарными БЗ, т.е. такими, которые в процессе эксплуатации изменяются относительно редко. На практике стационарные и даже статические (не модифицируемые) БЗ встречаются достаточно часто. Так, например, такие БЗ используются в обучающих системах с элементами ИИ, часто называемых экспертно-обучающими системами.
Метод поиска логического вывода с использованием пропозициональной абстракции состоит из двух основных частей. Во-первых, в него включен эффективный алгоритм решения абстракционной задачи, полученной применением пропозициональной абстракции. Это алгоритм решения проблемы дедукции в ИВ. Он позволяет построить выводы дизъюнкта C, если последний является логическим следствием (ниже будут указаны некоторые особенности таких выводов, связанные с понятием мультидизюнкта). Алгоритм использует формально-грамматическую интерпретацию проблемы дедукции и предусматривает предварительную настройку на работу с конкретным множеством гипотез. Следует подчеркнуть, что предварительная настройка выполняется до задания целей, т.е. один раз для БЗ. Во-вторых, в предлагаемый метод включен алгоритм построения выводов в ИП по выводам в ИВ, полученным при решении абстракционной задачи. Рассмотрим сначала первый алгоритм, остановившись прежде всего на необходимой для него предварительной настройке.
Пусть имеется БЗ E в ИВ, состоящая из дизъюнктов
{D1, ... , Dm},
в которой используются высказывания Р1, ... , Рn. Построим по Е КС-грамматику G(E), без терминальных символов и начального нетерминала: G(E) = {Vn, Q},
где Vn - множество нетерминальных символов, а Q - множество правил вывода. Множество нетерминальных символов образуем из высказываний в Е:
VN = {Р1, ... , Рn}.
Правила вывода грамматики построим по входящим в Е дизъюнктам. Пусть Di = ( Рj , ùРl1, ... , ùРlk ).
Построим по нему правило вывода
Рj à Рl1 ... Рlk.
Если Di = ( Рj ), то получим укорачивающее правило Рj à e. По цели, представленной в виде
С = (ùРi1 , ... , ùРiq),
образуем цепочку соответствующих нетерминальных символов
w = Рi1 ... Рiq.
Теперь логический вывод во множестве S можно интерпретировать как вывод пустой цепочки из w: w Þ+ e. Формально-грамматическая интерпретация позволит нам использовать методы теории формальных грамматик для настройки на конкретные БЗ, что, свою очередь, значительно повысит эффективность алгоритма поиска логических выводов.
Введем понятие укорачивающего символа грамматики. Нетерминальный символ A называется укорачивающим, если в данной грамматике из него возможен вывод пустой цепочки: A Þ+ e. Очевидно, вывод пустой цепочки из некоторой w возможен лишь в том случае, если все входящие в w символы являются укорачивающими. Это утверждение дает возможность выполнить предварительную настройку алгоритма на работу с заданной БЗ. Настройка включает в себя выделение подмножества укорачивающих символов, которое удобно представить в виде двоичной шкалы. Разряды шкалы соответствуют нетерминалам грамматики и принимают разные значения, в зависимости от того, является ли данный нетерминал укорачивающим или нет. После построения шкалы укорачивающих символов алгоритм, распознающий свойство выводимости целей совершенно элементарен.
Нашей задачей является не только распознавание выводимости целей, но и построение выводов (по возможности всех) в случае выводимости. Поэтому предварительная настройка на работу с конкретной БЗ осуществляется алгоритмом, не только выделяющим укорачивающие символы, но и формирующим для каждого укорачивающего символа списки правил, с которых могут начинаться выводы пустой цепочки. Рассмотрим этот алгоритм.
Пусть имеется некоторая грамматика G(E). Обозначим через W формируемое подмножество укорачивающих символов грамматики, через S(А) - формируемые для каждого символа из W списки правил вывода, с которых могут начинаться выводы пустой цепочки из А. Алгоритм выделения укорачивающих символов и соответствующих им правил вывода представим в виде следующего итеративного процесса:
W0 = { А | А à e Î Q }; S0(А) = { R | R = A à e, R Î Q },
т.е. включаем в W0 те символы грамматики, для которых в ней имеются укорачивающие правила вывода, а в соответствующие S0 - сами укорачивающие правила. Пусть уже получены Wi и Si(A) для всех А Î Wi.
Выполним очередной шаг итеративного процесса следующим образом:
Wi+1 = Wi È { А | А à А1А2 ... Аn Î Q; Ai Î Wi, i = 1, ... , n };
Si+1(A) = Si(A) È { R | R = А à А1А2 ... Аn ; Ai Î Wi , i = 1, ... , n; R Î Q\ Si(A)},
т.е. включаем в Wi+1 все символы из Wi и те символы грамматики, для которых найдутся правила вывода, все символы правых частей которых включены в Wi. В соответствующие Si+1 включим правила из Si, а также правила, обладающие указанным выше свойством и не входящие в Si. Отметим, что Si+1 - это упорядоченные множества (списки) и вновь включаемые в них правила вывода попадают в концы списков.
Алгоритм закончит работу, когда на некотором шаге j+1 окажется, что имеют место равенства Sj+1(A) = Sj(A) для всех А Î VN. Примем W = Wj и S(A) = Sj(A) для каждого А Î W. Для оценки числа шагов алгоритма докажем следующие две леммы.
Лемма 1. Пусть на j-ом шаге алгоритма получено Wj = Wj-1. Тогда Sj+1(A) = Sj(A) для любого А Î Wj .
Доказательство. Доказывая утверждение от противного, предположим, что для некоторого А найдется правило R = А à h такое, что R Ï Sj(A) и R Î Sj+1(A). Так как правило R не попало в Sj(A), найдется символ Ai, который входит в цепочку h и Ai Ï W j-1. Но R включено в Sj+1(A) и, следовательно, Ai Î Wj. Поэтому Wj ¹ Wj-1. Получили противоречие, доказывающее наше утверждение.
Лемма 2. Число шагов алгоритма настройки не превышает числа нетерминальных символов грамматики.
Доказательство. Так как для продолжения работы алгоритма необходимо, чтобы на каждом его шаге число выделенных укорачивающих символов увеличивалось, число шагов не может превышать числа нетерминальных символов грамматики.
Важное свойство формируемых алгоритмом настройки подмножеств S сформулировано в следующей теореме.
Теорема 1. На всех шагах любого вывода А Þ+ e могут применяться лишь правила из подмножеств S.
Доказательство. Докажем это утверждение от противного. Не умаляя общности, мы можем рассматривать левосторонние выводы. Пусть на некотором шаге вывода к цепочке wj = Bx, B Î VN, x Î VN*, было применено правило R = B à h такое, что R Ï S(B). Так как мы исследуем вывод пустой цепочки, в нем должна найтись цепочка wk = x, k > j. Поэтому существует вывод h Þ+ e, и все символы цепочки h укорачивающие, а тогда найдется такое i, что в Wi, входят все символы цепочки h и R Î Si(B). Так как Si(B) Í S(B), R Î S(B). Получили противоречие, доказывающее наше утверждение.
Подмножество W позволяет сформировать двоичную шкалу нетерминальных символов, которая вместе со списками S является результатом работы алгоритма предварительной настройки.
Теперь можно описать алгоритм решения абстракционной задачи. Выводимость цели C проверяется построением соответствующей цепочки нетерминальных символов грамматики и просмотром значений шкалы для символов этой цепочки. C выводима в том и только том случае, если шкала покажет, что все символы цепочки являются укорачивающими. Для перебора всех вариантов ее вывода нужно в построенной по данной БЗ КС-грамматике перебрать выводы пустой цепочки из цепочки, соответствующей С. Такой перебор легко осуществить, пользуясь списками S. Отметим, что при этом не будут перебираться тупиковые варианты. Это выгодно отличает предлагаемый метод от других алгоритмов, построенных на основе метода резолюций.
Проиллюстрируем описанный алгоритм, включая предварительную настройку, следующим примером.
Пример 1. Пусть задана следующая БЗ в ИВ: E = {
(1) (p, ùr, ùt, ), (5) ( q, ùu ),
(2) (p, ùq, ùr, ), (6) ( r ),
(3) (p, ùq, ùs, ), (7) ( t, ùq, ùu ),
(4) ( q, ùs, ùt, ùu ), (8) ( u ) }.
Соответствующая этой БЗ грамматика выглядит так:
VN = { p, q, r, s, t, u }.
В Q войдут следующие правила вывода:
1) p à rt; 2) p à qr; 3) p à qs; 4) q à stu;
5) q à u; 6) r à e; 7) t à qu; 8) u à e.
Применим итерационный алгоритм настройки. Правила вывода будем представлять своими номерами.
|
Wi |
Символы |
|
Si |
P |
Q |
r |
s |
t |
u |
|
W0 |
r, u |
|
S0 |
|
|
6 |
|
|
8 |
|
W1 |
q, r, u |
|
S1 |
|
5 |
6 |
|
|
8 |
|
W2 |
p, q, r, t, u |
|
S2 |
2 |
5 |
6 |
|
7 |
8 |
|
W3 |
p, q, r, t, u |
|
S3 |
2,1 |
5 |
6 |
|
7 |
8 |
Так как W2 = W3, работа алгоритма закончена. Настройка на заданную БЗ произведена: W = W2, S(a) = S3(a), a ÎW. Имеем шкалу (1 - символ укорачивающий, 0 - символ неукорачивающий):
|
p |
q |
r |
s |
t |
u |
|
1 |
1 |
1 |
0 |
1 |
1 |
Пусть цель C = p&q&s. Ее отрицание ùС = (ùp, ùq, ùs). Этому дизъюнкту соответствует цепочка w = pqs. Находим в шкале значения символов w: 110. Так как s - неукорачивающий, C невыводим.
Пусть C = p&q. Его отрицание ùС = (ùp, ùq). Этому дизъюнкту соответствует цепочка w = pq. Значения символов w в шкале 11. Следовательно, C выводим. Найдем все его выводы, перебирая варианты вывода из w пустой цепочки с учетом подмножеств S:
-
pq, qrq, urq, rq, q, u, e (при использовании на первом шаге правила 2).
-
pq, rtq, tq, quq, uuq, uq, q, u, e (при использовании на первом шаге правила 1).
Мы видим, что наш алгоритм не применял в процессе перебора правило 3, так как оно не входит в S(р). По полученным выводам в грамматике легко построить выводы C в исходной БЗ (предоставим это читателю). Отметим лишь, что в каждой цепочке выводов можно оставить лишь по одному вхождению каждого символа и сократить совпадающие цепочки. Такое преобразование следует выполнять, если нас интересуют выводы в ИВ. Если же поиск выводов в ИВ рассматривается как метод решения абстракционной задачи, то выводы нужно оставить в их первоначальном виде.
Перейдем к описанию второго алгоритма предлагаемого метода – алгоритма построения выводов в ИП по выводам в ИВ, полученным применением пропозициональной абстракции. Этот алгоритм должен учитывать особенность, связанную с тем, что в дизъюнктах ИП литерами могут оказаться одни и те же предикаты с различными значениями аргументов. При применении пропозициональной абстракции таким предикатам соответствуют одни и те же высказывания. Сокращение повторяющихся литер в дизъюнктах ИВ недопустимо, так как приводит к несоответствию между выводами в ИП и ИВ. Во избежание подобного обстоятельства в рамках пропозициональной абстракции используется понятие мультидизъюнкта - это дизъюнкт ИВ, который может содержать несколько экземпляров одного и того же высказывания (в том числе и литеры вида p и ùp, хотя дизъюнкты, содержащие подобные литеры, являются тавтологиями и обычно исключаются из рассмотрения). Мультидизъюнкты являются объектами и результатами действия m-абстракции и m-резолюции, которые определяются аналогично понятиям абстракции и резолюции. Выводы в множестве мультидизъюнктов ИВ строятся с помощью m-резолюции и поэтому будут соответствовать по своей структуре выводам в исходном множестве дизъюнктов ИП.
Описываемый алгоритм для построения выводов целей в ИП использует выводы в ИВ, полученные в результате решения абстракционной задачи, как схемы выводов в ИП. Построение выводов в ИП производится последовательным просмотром всех схем с одновременным восстановлением аргументов предикатов и выполнением унификации. Если на каком-либо этапе просмотра очередной схемы унификация окажется невозможной, то данная схема является непродуктивной, т.е. выводы в ИП, соответствующие этой схеме отсутствуют. Если все схемы окажутся непродуктивными, то выводы в ИП отсутствуют и соответствующая цель невыводима.
Наиболее эффективная стратегия построения выводов в ИП – это параллельное построение выводов в грамматике, схем в ИВ и выводов в ИП. Алгоритм, реализующий эту стратегию, назовем параллельным. Каждый шаг его работы заключается в применении некоторого правила вывода для построения вывода в грамматике, использовании соответствующего правилу мультидизъюнкта в абстракционной задаче для резолюции и в попытке использования соответствующего дизъюнкта для резолюции в исходной задаче. Эта попытка будет успешной, если найдется соответствующий унификатор. Параллельный алгоритм оперативно выявляет непродуктивные схемы еще в процессе их построения - если на некотором шаге унификация окажется невозможной. Предусматривается также удаление алгоритмом "лишних" литер. Если одинаковым литерам в мультидизъюнктах схемы соответствуют одинаковые литеры в дизъюнктах вывода в ИП, то повторяющиеся литеры исключаются в схеме, и в выводе, а из цепочки вывода удаляются соответствующие им символы. Формальное описание параллельного алгоритма достаточно громоздко. Поэтому проиллюстрируем этот алгоритм следующими двумя примерами.
Пример 2. Пусть в ИП задана следующая БЗ:
E = { (1) (q(c), ùp(a), ùp(b)), (2) (p(a)), (3) (p(b)), (4) r(d)) }.
Пропозициональные m-абстракции, построенные по множеству E:
f(E) = { (1) (q, ùp, ùp), (2) (p), (3) (p), (4) (r) }.
Грамматика, построенная по множеству f(E):
G(f(E)) = { VN, Q }; VN = { q, p, r }; Q = { (1) q ® pp, (2) p ® e, (3) p ® e, (4) r ® e }.
Двоичная шкала символов:
|
q |
p |
r |
|
1 |
1 |
1 |
Списки правил, выделенных для укорачивающих символов грамматики:
S(q) = (1), S(p) = (2, 3), S(r) = (4).
Пусть задана цель:
C = q(c)&r(d).
Ее отрицание:
ùC = (ùq(c), ùr(d)).
M-абстракция:
f(ùC) = (ùq, ùr).
Соответствующая цепочка w = qr. Имеем из шкалы значения 11. Следовательно, m-абстракция цели выводима. Используя параллельный алгоритм, построим вывод исходной цели, формируя вывод в грамматике с указанием применяемых правил и соответствующие им схемы.
|
Вывод в G(f(E)) и номера правил |
Вывод в f(E) |
Вывод в E |
Унификатор |
|
qr (1) |
(ùq, ùr) |
(ùq(c), ùr(d)) |
L |
|
ppr (2) |
(ùp, ùp, ùr) |
(ùp(a), ùp(b), ùr(d)) |
L |
|
pr (2) |
(ùp, ùr) |
( ùp(b), ùr(d)) |
Унификатор отсутствует |
Так как провести унификацию для продолжения вывода в E оказалось невозможным, возник тупик, означающий, что текущая схема непродуктивна. Алгоритм прекращает работу с ней и, осуществляя перебор, переходит к работе со следующей схемой. Эта схема строится применением на последнем шаге вместо правила 2 в G(f(E)) правила 3:
|
Вывод в G(f(E)) и номера правил |
Вывод в f(E) |
Вывод в E |
Унификатор |
|
pr (3) |
(ùp, ùr) |
( ùp(b), ùr(d)) |
L |
|
r (4) |
(ùr) |
( ùr(d) |
L |
|
e |
L |
L |
|
Один вывод найден, но работа алгоритма не закончена, так как имеется еще одна схема, которая строится применением на втором шаге вместо правила 2 правила 3:
|
Вывод в G(f(E)) и номера правил |
Вывод в f(E) |
Вывод в E |
Унификатор |
|
ppr (3) |
(ùp, ùp, ùr) |
(ùp(a), ùp(b), ùr(d)) |
Унификатор отсутствует |
Возник тупик, означающий, что текущая схема непродуктивна. Так как перебор схем исчерпан, параллельный алгоритм заканчивает работу, построив единственный вывод цели. Данный пример иллюстрирует необходимость использования m-абстракции. Если бы в мультидизъюнкте (ùp, ùp, ùr) вывода в f(E) была удалена одна из литер ùp, выводы в грамматике, и в f(E) оказались бы неадекватными выводам в E.
Пример 3 [1]. Пусть задана следующая БЗ в ИП (a и b - константы, x - переменная):
E = { (1) (p(a), ùq(x), ùr(b)), (2) (p(x), ùt(x)), (3) (q(b), ùp(a), ùt(a)), (4) (t(b)), (5) (t(a)) }.
Пропозициональные m-абстракции, построенные по множеству E:
f(E) = { (1) (p, ùq, ùr), (2) (p, ùt), (3) (q, ùp, ùt), (4) (t), (5) (t) }.
Грамматика, построенная по множеству f(E):
G(f(E)) = { VN, Q }; VN = { p, q, r, t }; Q = { (1) p ® qr, (2) p ® t, (3) q ® pt, (4) t ® e, (5) t ® e }.
Двоичная шкала символов:
|
p |
q |
r |
t |
|
1 |
1 |
0 |
1 |
Списки правил, выделенных для укорачивающих символов грамматики:
S(p) = (2), S(q) = (3), S(t) = (4, 5).
Пусть задана цель:
C = q(x)&p(x).
Ее отрицание:
ùC = (ùq(x), ùp(x)).
M-абстракция:
f(ùC) = (ùq, ùp).
Соответствующая цепочка w = qp. Имеем из шкалы значения 11. Следовательно, m-абстракция цели выводима. Используя параллельный алгоритм, построим вывод исходной цели, формируя вывод в грамматике с указанием применяемых правил и соответствующие им схемы.
|
Вывод в G(f(E)) и номера правил |
Вывод в f(E) |
Вывод в E |
Унификатор |
|
pq (3) |
(ùq, ùp) |
(ùq(x), ùp(x)) |
(x = b) |
|
ptp (2) |
(ùp, ùt, ùp) |
(ùp(a), ùt(a), ùp(b)) |
(x = a) |
|
ttp |
(ùt, ùt, ùp) |
(ùt(a), ùt(a), ùp(b)) |
|
В дизъюнкте вывода в E литера ùt(a) оказалась представленной двумя копиями. Поэтому параллельный алгоритм удаляет одну из них, а также соответствующие копию в мультидизъюнкте вывода в f(E) и символ в цепочке вывода в G(f(E)):
|
Вывод в G(f(E)) и номера правил |
Вывод в f(E) |
Вывод в E |
Унификатор |
|
tp (4) |
(ùt, ùp) |
(ùt(a), ùp(b)) |
Унификатор отсутствует |
Возник тупик, означающий, что текущая схема непродуктивна. Алгоритм прекращает работу с ней и, осуществляя перебор, переходит к работе со следующей схемой. Эта схема строится применением на последнем шаге вместо правила 4 в G(f(E)) правила 5:
|
Вывод в G(f(E)) и номера правил |
Вывод в f(E) |
Вывод в E |
Унификатор |
|
tp (5) |
(ùt, ùp) |
(ùt(a), ùp(b)) |
L |
|
p (2) |
(ùp) |
(ùp(b)) |
(x = b) |
|
t (4) |
(ùt) |
(ùt(b)) |
L |
|
L |
L |
L |
|
Один вывод найден, но работа алгоритма еще не закончена, так как имеется еще одна схема:
|
Вывод в G(f(E)) и номера правил |
Вывод в f(E) |
Вывод в E |
Унификатор |
|
t (5) |
(ùt) |
(ùt(b)) |
Унификатор отсутствует |
Здесь вновь возник тупик, и так как перебор схем исчерпан, алгоритм заканчивает работу, построив единственный вывод цели. Отметим, что параллельный алгоритм не пытался строить вывод путем резольвирования литеры ùp(a) с дизъюнктом 1: (p(a), ùq(x), ùr(b)). Это вызвано тем, что правило 1 грамматики p ® qr не попало в S(p). Из обоих примеров также хорошо видно, что непродуктивные схемы удаляются из рассмотрения уже в процессе их построения. Если бы алгоритм строил схемы и выводы последовательно, непродуктивные схемы формировались бы полностью.
Можно доказать полноту рассмотренного метода поиска логического вывода с предварительной настройкой, а также идентичность выводов, полученных данным методом, с выводами, полученными входной линейной резолюцией. В то же время, очевидно, что метод с предварительной настройкой во многих случаях эффективнее входной линейной резолюции. Было произведено сравнение этих двух методов и получены статистически значимые результаты, показывающие предпочтительность метода с предварительной настройкой.
ОСНОВЫ ЯЗЫКА ПРОЛОГ (СТАНДАРТ)
1. Особенности языка
Пролог имеет два главных отличия от процедурных языков:
-
Программирование на Прологе по-преимуществу является символьным. Данные в этом языке – это символы, которые никак не интерпретируются, и числа. (исключение – числа).
-
Так как Пролог относится к парадигме декларативного программирования, алгоритмы решения задач не задаются. Формулируется лишь условие задачи, после чего она решается с помощью встроенного (в интерпретатор) универсального алгоритма логического вывода, основанного, как уже упоминалось, на входной линейной резолюции.
Программа на Прологе состоит из описания предметной области и вопроса. Предметная область задается описанием объектов и отношений между ними с помощью фактов и правил. Факты и правила представляются хорновскими дизъюнктами: факты – унитарными позитивными дизъюнктами, правила – точными дизъюнктами. При этом с помощью фактов указываются тождественно истинные утверждения – представленные предикатами со значениями аргументов (термов), при которых они являются истинными. С помощью правил задаются средства установления новых фактов. Каждое правило интерпретируется так: если истинными являются все предикаты, представленные негативными литерами, то истинным считается и предикат, представленный позитивной литерой.
Вопросы указывают на необходимость установить наличие в БЗ указанных в них фактов или попытаться вывести эти факты в качестве новых. Вопросы представляются негативными дизъюнктами.
Характерными чертами языка Пролог считаются:
-
наличие алгоритма вывода с поиском и возвратом, который осуществляется с помощью стековой памяти и используется для перебора всех возможных вариантов вывода; возврат часто называется откатом, а перебор вариантов с откатом выполняется процедурой, называемой бэктрекингом.
-
наличие встроенного механизма сравнения с образцом (для реализации процедуры унификации);
-
простые синтаксис и структура данных.
2.1. Синтаксис языка.
Синтаксическими элементами языка являются:
Термы: константы, переменные, сложные термы.
Константы: целые и вещественные числа, атомы (любые цепочки символов, не начинающиеся с заглавных букв или любые цепочки символов в кавычках).
Целые числа представляются последовательностями цифр с возможным знаком «+» или «-».
Вещественные числа представляются в двух форматах:
-
В виде десятичной дроби, например: 10.12, -0.25, +35.1234. В некоторых случаях целые числа могут интерпретироваться как десятичные дроби – это зависит от контекста, в котором находится число.
-
В виде мантиссы и десятичного порядка: <десятичная дробь>Е<целое>, например: 1.012E1, -0.95Е+3, 125Е-2.
Как видно из примеров, перед вещественными числами могут находиться знаки «+» или «-»
Переменные: цепочки букв, цифр и знака подчеркивания («_»), начинающиеся с заглавной буквы или знака подчеркивания. Особая переменная – анонимная. Она представляется знаком подчеркивания.
Сложный терм это:
1) структура, состоящая из атома-предиката (или функтора) и компонент, т.е. термов в скобках через запятую; при этом компоненты сами могут являться сложными термами; например информация о книгах библиотеки может состоять из следующих данных: автор, название, издательство, год выпуска – книга(“Л.Н. Толстой”, “Война и мир”, “Художественная литература”, “2002”).
2) список, т.е. упорядоченный набор связанных между собой термов; имеется возможность работать как целиком со списком, так и с отдельными входящими в него термами.
Константы и структуры представляют объекты предметной области, а списки – упорядоченные наборы объектов. Роль структур заключается в группировке некоторых объектов, представляющих составной объект.
База знаний, описывающая предметную область, задается фактами и правилами.
Факты – это отдельные предикаты, состоящие из имени предиката и, возможно, термов, представляющих его аргументы.
Правила имеют вид:
p1( … ) : – p2( … ), … , pn( … ), n ≥ 2,
где pi – предикаты.
Приведем примеры простых баз знаний, пояснив кроме синтаксиса также их семантику.
Фрагмент словаря синонимов и антонимов может быть представлен следующей базой знаний:
synonym("храбрый","отважный").
synonym("храбрый","бесстрашный").
synonym("современный","новый").
synonym("редкий","неупотребительный").
antonym("храбрый","трусливый").
antonym("честный","бесчестный").
antonym("современный","старый").
antonym("редкий","частый").
Фрагмент описания предметной области «Дифференцирование», который представляет правило дифференцирования суммы, может быть представлен следующими фактом и правилом:
diff( Х,Х,1).
diff ( U+V, X, A+B) : – diff ( U, X, A), diff (V, X, B).
Отметим, что в первом из этих примеров мы использовали только факты. Все они представляют два предиката, для имен которых использованы функторы synonym и antonym. Вы можете без труда заметить, что их компоненты подобраны так, что они действительно являются, соответственно, синонимами и антонимами друг друга в общепринятом понимании этих терминов. Во втором примере имеется факт diff( Х,Х,1). Он отражает простейшее правило дифференцирования, согласно которому производная по X функции F(X) = X равна 1. Правило второго примера интерпретируется так: если производная по X функции U равна A, а производная по X функции V равна B, то производная по X суммы U+V равна A+B.
Вопросы представляются в виде одного или нескольких предикатов, называемых целями:
?- p1( … ), p2( … ), … , pn( … ), n ≥ 1.
Список целей, заданный этим вопросом, таков:
p1( … ), p2( … ), … , pn( … ).
Если вопрос состоит из одного предиката, то он называется простым, в противном случае – составным. Активная цель – это первая цель списка (в нашем примере p1). После осуществления логического вывода активной цели, она исключается из списка, который в случае нашего примера примет вид:
p2( … ), … , pn( … ).
В этом случае говорят, что цель доказана или достигнута и активной становится цель p2. Работа заканчивается либо после достижения последней цели списка pn (в случае наличия решений), либо при возникновении тупиковой ситуации, когда вывод какой-нибудь активной цели оказывается невозможным.
Программы на Прологе состоят из двух частей – описания предметной области и вопроса:
-
Факты и правила, описывающие предметную область.
-
Вопрос.
Например, приписав вопрос
?- synonym("храбрый",X), antonym("храбрый", Y)
к базе знаний первого примера, получим программу.
Ответы на вопросы пользователей формируются в процессе выполнения программ и в разных версиях языка представляются по-разному. Мы примем следующий вариант. Если ответ должен быть положительным или отрицательным, то он представляется в форме Yes и No соответственно. Если же требуется указать выполненные в процессе логического вывода подстановки, вместо переменных, входящих в цели, то они перечисляются в ответе, после чего указывается число найденных решений.
Например, ответ на приведенный выше вопрос выглядит так:
X = "отважный", Y = "трусливый"
X = "бесстрашный", Y = "трусливый"
2 Solutions