

2. Грамматики, машины тьюринга и перечислимые языки
Контекстно-свободные грамматики
недостаточно «сильны» в смысле порождающей
способности, чтобы учесть все синтаксические
правила языка программирования (так,
все встречающиеся переменные должны
быть объявлены) или чтобы вычислить
относительно простые функции (например,
{![]() | n
}).
Поэтому как обобщение контекстно-свободных
грамматик введем грамматику
Ван-Вайнгаардена.
| n
}).
Поэтому как обобщение контекстно-свободных
грамматик введем грамматику
Ван-Вайнгаардена.
Грамматика Ван-Вайнгаардена есть шестерка G = (VZ, VM, , R, P, S), причем
-
VZ – алфавит, называемый алфавитом синтаксических знаков, который не содержит <, >;
-
VM – конечное множество (которое может быть и пустым), называемое множеством метапонятий, где VM (VZ {<, >}) = и V = VM VZ;
-
алфавит, называемый алфавитом базовых или терминальных символов, такой что VM = ;
-
R VM V конечное множество метапродукций;
-
P <V> (<V> ) конечное множество схем продукций;
-
S <
 >
стартовая
переменная.
>
стартовая
переменная.
Пусть G = (VZ, VM, , R, P, S)
грамматика Ван-Вайнгаардена. Тогда
назовем GA = (VM, VZ, R, A)
грамматикой, ассоциированной с
метапонятием A
VM.
Грамматика GA
контекстно-свободная
и порождает контекстно-свободный
язык L(GA)
![]() .
Из схем продукций получают с помощью
контекстно-свободного языка L(GA),
A
VM,
продукции, которые потом применимы
в выводах. Чтобы из некоторой схемы
продукции получить продукцию, следует
все встречающиеся метапонятия согласованно
заменить словами из языка L(GA).
Это значит, что если некоторое метапонятие
A встречается
многократно, то все встречаемые A
должны быть заменены одним и тем же
словом из L(GA).
.
Из схем продукций получают с помощью
контекстно-свободного языка L(GA),
A
VM,
продукции, которые потом применимы
в выводах. Чтобы из некоторой схемы
продукции получить продукцию, следует
все встречающиеся метапонятия согласованно
заменить словами из языка L(GA).
Это значит, что если некоторое метапонятие
A встречается
многократно, то все встречаемые A
должны быть заменены одним и тем же
словом из L(GA).
Как ранее, будем писать для (<>, 1), …,(<>, n) P также <>::= 1 | … | n и для (A, 1), …,(A, n) R также A::= 1 | … | n.
Гомоморфизм h: (V {<, >}) (VZ {<, >}) называется допустимым (в отношении грамматики G) тогда и только тогда, когда h(a) = a, a VZ {<, >}, h(А) L(GA), A VM.
Множество продукций
![]() определяется
следующим образом:
определяется
следующим образом:
![]() = {<h()> h() | <>::= P, V, (<V> ),
h
– допустимый гомоморфизм}.
= {<h()> h() | <>::= P, V, (<V> ),
h
– допустимый гомоморфизм}.
(Для различения метапродукций от схем
продукций будем записывать продукции
в виде: <![]() >
> ![]() .)
.)
С помощью множеств продукций
![]() определяется
прямое отношение вывода G
(или просто )
над (<
определяется
прямое отношение вывода G
(или просто )
над (<![]() > ):
> ):
G = <![]() >, =
>, = ![]() , <
, <![]() >
> ![]()
![]() , , (<
, , (<![]() > ).
> ).
С помощью L(G) снова обозначим язык, порожденный грамматикой G:
L(G) = {w | S w}.
При этом есть рефлексивное и транзитивное замыкание отношения и называется отношением вывода.
Формальный язык L называется перечислимым, если существует грамматика Ван-Вайнгаардена, такая что L = L(G).
Предложение 2.1. Любой контекстно-свободный язык перечислим.
Доказательство.
Пусть <wi>::= i1 | … | ![]() , 1 i n,
– продукции
контекстно-свободной грамматики G,
записанные в нормальной форме Бэкуса,
<w1>
начальная переменная G,
VZ
алфавит с wi
, 1 i n,
– продукции
контекстно-свободной грамматики G,
записанные в нормальной форме Бэкуса,
<w1>
начальная переменная G,
VZ
алфавит с wi ![]() ,
1 i n
и
терминальный алфавит. Тогда
грамматика Ван-Вайнгаардена
G = (VZ, , , , P, <w1>),
причем P точно
содержит продукции в нормальной
форме Бэкуса в G,
порождает тот же самый язык. □
,
1 i n
и
терминальный алфавит. Тогда
грамматика Ван-Вайнгаардена
G = (VZ, , , , P, <w1>),
причем P точно
содержит продукции в нормальной
форме Бэкуса в G,
порождает тот же самый язык. □
Чтобы избежать повторов в примерах, условимся о следующем.
Пусть G = (VZ, VM, , R, P, S) грамматика Ван-Вайнгаардена. Все встречающиеся большие буквы есть метапонятия в VM, все встречающиеся маленькие буквы и специальные знаки есть синтаксические знаки в VZ или терминальные символы в , S обозначается как <начало>. Тем самым должны быть только заданы множества R и P. Теперь с помощью примеров покажем, как определенные синтаксические конструкции языков (языков программирования) могут быть представлены с помощью грамматики Ван-Вайнгаардена, соответственно как с помощью этой грамматики могут быть вычислены функции. Контекстно-свободные грамматики для этого слишком слабы.
Пример 2.1. Пусть L
= {![]() b
…
b
…
![]() b
b![]() d
…
d
…
![]() d
| ik
il,
ik
1 для 1 k,
l
n, k
l, js
{ik
| 1
k
n}, 1
s
m, m,
n
1}. Слова ai
могут пониматься как обозначения
переменных в блоке объявления переменных,
слова b
как разделительные знаки и d
как правые части
присваиваний. Таким образом, L
содержит в точности те «куски» программы,
в которых все объявленные переменные
различно обозначены и в которых объявлены
все переменные, встречающиеся в левой
части присваивания.
d
| ik
il,
ik
1 для 1 k,
l
n, k
l, js
{ik
| 1
k
n}, 1
s
m, m,
n
1}. Слова ai
могут пониматься как обозначения
переменных в блоке объявления переменных,
слова b
как разделительные знаки и d
как правые части
присваиваний. Таким образом, L
содержит в точности те «куски» программы,
в которых все объявленные переменные
различно обозначены и в которых объявлены
все переменные, встречающиеся в левой
части присваивания.
Метапродукции в R заданы посредством:
K::= aK | a, K1::= K | , K2::= K | , L::= KbL | Kb, L1::= L | , L2::= L | .
Схемы продукций в P заданы посредством:
<начало>::= <L> <проверить L> <применить L>,
<KbL>::= <K> b <L>, <Kb>::= <K> b, <aK>::= a<K>,
<a>::= a,
<проверить KbL>::= <K не лежит в L> <проверить L>,
<проверить Kb>::= ,
<K1 не лежит в K2bL>::= <K1 не равно K2> <K1 не лежит в L>,
<K1 не лежит в K2b>::= <K1 не равно K2>,
<K1K не равно K1>::= ,
<K1 не равно K1K>::= ,
<применить L1KbL2>::= <K> d <применить L1KbL2> | <K> d.
Получим:
L(Gk) = {ai | i 1},
L(GL) = {![]() b
…
b
…
![]() b | ik 1, 1
k n, n 1}.
b | ik 1, 1
k n, n 1}.
Зададим некоторые
продукции в
![]() :
:
<начало> <a2bab> <проверить a2bab> <применить a2bab> поэтому L a2bab (в GL);
<проверить a2bab> <a2 не лежит в ab> <проверить ab>, поэтому K a2, L ab (в GK, GL);
<a2 не лежит в ab> <a2 не равно a>, поэтому K1 a2, K2 a;
<a2 не равно a> , поэтому K1 a, K a;
<применить a2bab> <a2> d <применить a2bab>, поэтому L1 , K a2, L2 ab;
<применить a2bab> <a2> d, поэтому L1 , K a2, L2 ab.
Слово a2baba2dada2d выводится следующим образом (в G):
<начало> <aabab> <проверить aabab> <применить aabab>
aabab <проверить aabab> <применить aabab> aаbab <aa не лежит в ab> <проверить ab> <применить aabab>
aabab <проверить ab> <применить aabab> aabab <применить aabab>
aababaad <применить aabab> aababaad <a> d <применить aabab>
aababaadad <применить aabab> aababaadadaad. □
Каждому выводу в
грамматике Ван-Вайнгаардена G
= (VZ,
VM,
,
R,
P,
S)
можно сопоставить направленное дерево,
узлы которого маркированы с помощью
элементов из множества <![]() >
.
>
.
-
Выводу S A1…An, Ai <
 >
соответствует дерево вывода (1) на
странице 7.
>
соответствует дерево вывода (1) на
странице 7. -
Пусть выводу S 1A2, 1, 2 (<
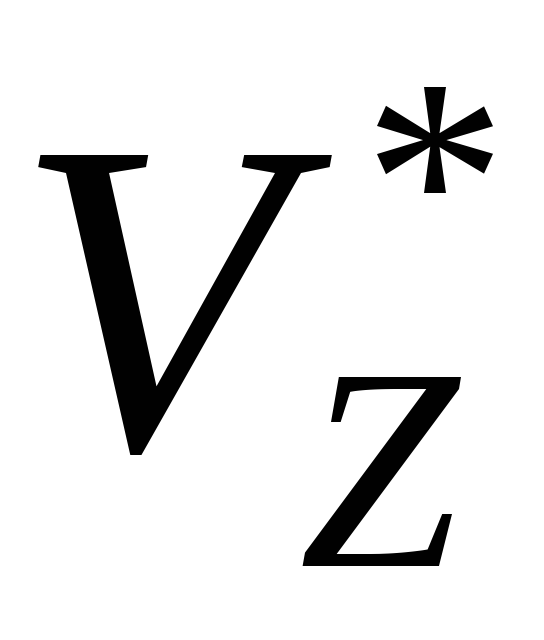 > ), A <
> ), A < >
соответствует первое дерево вывода
(2) на странице 7. Тогда выводу
S 1A2 1A1 … An2, Ai <
>
соответствует первое дерево вывода
(2) на странице 7. Тогда выводу
S 1A2 1A1 … An2, Ai < >
соответствует второе дерево вывода
(2) на странице 8.
>
соответствует второе дерево вывода
(2) на странице 8.
Как и ранее, получают результат дерева вывода.
Пример 2.2. Выводу в примере 2.1 соответствует дерево вывода:
<начало>


<a2bab> <проверить
a2bab> <применить
a2bab>








<a2> b <ab> <a2
не лежит в
ab> <проверить
ab> <a2
>
d
<применить
a2bab>











a <a>
d
<применить
a2bab> <a> <a> b <a2
не
равно
a> a <a>







a a a a
<a2> d


a <a>

a
□
Пример 2.3. Функция Аккерманна f: определяется следующим образом:

Справедливо следующее:
f(1, 1) = f(0, f(1, 0)) = f(0, f(0, 1)) = f(0, 2) = 3.
Мы хотим «вычислить» функцию Аккерманна посредством некоторой грамматики Ван-Вайнгаардена G, то есть должно выполняться:
L(G)
= {1m![]() 1n
1n![]() 1f(m,
n) | n,
m
0}.
1f(m,
n) | n,
m
0}.
(Число n представляется в виде 1n.)
Метапродукции в R заданы посредством:
M::= M1 | , N::= M, S::= Sf (N, | , T::=) T | .
Схемы продукции в P заданы посредством:
<начало>::= <M><N><f(M, N)>,
<Sf(, N)T>::= <SN1T>, <Sf(M1,)T>::= <Sf(M, 1)T>,
<Sf(M1, N1)T>::= <Sf(M, f(M1, N))T>,
<N1>::= <N>1, <>::= .
Слово 11111 выводится следующим образом:
<начало> <1><1><f(1, 1)> 11<f(1, 1)>
11<f(, f(1,))> 11<f(, f(, 1))>
11<f(, 11)> 11<111> 11111. □
Введем теперь грамматики, которые будут рассматриваться как обобщение контекстно-свободных грамматик. Грамматика G задана посредством G = (Ф, , P, S), причем:
-
Ф – алфавит, называемый алфавитом переменных (англ. nonterminals).
-
– алфавит, называемый алфавитом терминальных символов (англ. terminals), причем Ф = (пустое множество). Посредством V = Ф обозначается совокупный алфавит.
-
Р – конечное множество продукций или правил замещения (англ. productions) вида , причем V+ и V. Таким образом, Р есть конечное отношение над V.
-
S Ф переменная, называемая стартовой переменной (англ. start symbol).
Для отличия от остальных грамматик грамматику G называют также грамматикой Хомского типа 0.
Теперь мы хотим определить, какой формальный язык порождает грамматика. Для этого нам понадобится определение отношения вывода , которое вводится через отношение .
G есть отношение над V, определяемое следующим образом:
G тогда и только тогда, когда = , = и P.
Как и раньше, говорят: непосредственно выводит или: может быть непосредственно выведено из .
Отношение ![]() есть снова рефлексивная и транзитивная
оболочка отношения G.
Говорят также:
выводит , или
может быть выведено из .
В случае, если ясно какая грамматика
имеется в виду, вместо G
и
есть снова рефлексивная и транзитивная
оболочка отношения G.
Говорят также:
выводит , или
может быть выведено из .
В случае, если ясно какая грамматика
имеется в виду, вместо G
и ![]() можно также писать
и .
можно также писать
и .
Слово V называется сентенциальной формой, если S . Обозначим через L(G) формальный язык, который порождается грамматикой G. L(G) есть множество слов
L(G) = {w | w и S w}.
Это означает то, что L(G) содержит в точности все те сентенциальные формы, которые являются словами над терминальным алфавитом.
Путем введения ограничений на разрешаемые продукции получают так называемую иерархию грамматик по Хомскому.
Пусть G = (Ф, , P, S) грамматика. Она называется контекстно-зависимой, или грамматикой Хомского типа 1 тогда и только тогда, когда каждая продукция P:
-
имеет вид = 1A2, в случае = 12, A Ф, 12 V, V+;
-
имеет вид S , в случае если S не встречается в правой части продукции.
Контекстно-свободные и регулярные грамматики, получаемые из грамматик типа 0 введением ограничений, называются в этой связи грамматиками типа 2 и типа 3.
Грамматика G называется ограниченной тогда и только тогда, когда для каждого правила продукции P выполняется: || ||, или, если S не встречается в правой части продукции, когда выполняется = S и = .
Можно легко показать, что справедливо следующее предложение.
Предложение 2.2. Формальный язык может порождаться контекстно-зависимой грамматикой тогда и только тогда, когда он может порождаться ограниченной грамматикой. □
Формальный язык называется контекстно-зависимым, если найдется контекстно-зависимая грамматика, которая порождает этот язык.
Пример 2.4. Ограниченная грамматика G = ({S, A, B}, {a, b}, P, S), где
P = {S abc, S aAbc, Ab bA, Ac Bbcc, bB Bb, aB aaA, aB aa}
порождает язык L(G) = {anbncn | n 1}. (Для доказательства следует рассмотреть сентенциальные формы aiAbici i 1и выводимые из них формы.) Этот язык является также контекстно-зависимым. Можно показать, что L(G) не является контекстно-свободным. □
Справедливо следующее предложение.
Предложение 2.3. Формальный язык порождается грамматикой Ван-Вайнгаардена тогда и только тогда, когда он порождается грамматикой Хомского типа 0. □
Теперь мы хотим определить автоматы, которые принимают перечислимые языки. По историческим причинам эти автоматы называются машинами Тьюринга. Машину Тьюринга можно рассматривать как прибор, который имеет конечное число состояний и в обе стороны потенциально бесконечную ленту с головкой чтения-записи. Лента разделена на ячейки, в каждой ячейке находится один символ ленты. Почти все ячейки содержат специальный символ ленты, символ пробела е. Головка чтения-записи может читать и изменять содержимое ячейки. Машина Тьюринга стартует в заданном начальном состоянии, причем головка чтения-записи находится над первым (крайним слева) символом входного слова. Один такт машины Тьюринга (в зависимости от состояния и читаемого символа) состоит из следующих действий:
-
прочитанный символ стирается и на его месте записывается новый символ;
-
головка чтения-записи перемещается на одну ячейку влево или вправо;
-
машина Тьюринга переходит в новое состояние.
Машина Тьюринга может применяться для представления некоторой (в общем случае частичной) функции или для акцептирования некоторого формального языка следующим образом:
-
Машина Тьюринга заканчивает свои вычисления с входным словом w. Содержимое ленты по окончании вычисления означает тогда значение функции от аргумента w, в случае, если представляется функция. Если должен акцептироваться язык, то слово w тогда и только тогда содержится в языке, когда машина Тьюринга находится по окончании вычисления в конечном состоянии.
-
Процесс вычислений на машине Тьюринга не прерывается. Тогда функция для аргумента w не определена. Соответственно, слово w не содержится в языке.
Двусторонняя детерминированная машина Тьюринга T = (Q, , Г, , q0, F) определяется через:
-
конечное множество состояний Q;
-
входной алфавит ;
-
алфавит символов ленты Г. При этом Г содержит символ пробела е и выполняется: Г {e};
-
функция перехода в общем случае лишь частично определенная:
: (Q F) Г Q Г {L, R};
-
начальное состояние q0 Q;
-
множество конечных состояний F Q.
Вычисление на машине Тьюринга представляется через конфигурации, причем конфигурация (или ситуация) есть элемент из ГQГ. (При этом Q, Q Г = используется как алфавит). Конфигурация q интуитивно означает, что машина Тьюринга находится в состоянии q, что есть содержимое ленты и что головка чтения-записи читает первый символ слова .
Условимся, что конфигурация q означает то же самое, что и конфигурация enqem, n, m 0.
Один шаг вычислений машины Тьюринга T представляется отношением над конфигурациями. Это отношение определяется следующим образом через :
-
qA Bp, если (q, A) = (p, B, R),
-
CqA pCB, если (q, A) = (p, B, L),
A, B, C , , , q Q F, p Q.
(На основе нашего соглашения выполняется:
q peB, если (q, e) = (p, B, L), q Bp, если (q, e) = (p, B, R).)
Говорят также, что отношение
прямо переводит одну конфигурацию
в другую. Отношение ![]() переводит некоторую конфигурацию
в другую.
переводит некоторую конфигурацию
в другую.
Конечная конфигурация есть конфигурация qA, такая, что (q, A) не определена. (В случае, если q F, то qA автоматически конечная конфигурация.)
Машина Тьюринга Т останавливается при вводе слова (w1, …, wn), wi , 1 i n в конечной конфигурации q, когда
q0w1ew2e
… ewn ![]() q.
q.
Пусть h: ( {e}) гомоморфизм, который определен через h(A) = A, A {e}, h(e) = . Пусть T некоторая машина Тьюринга и n 0. n-местная частичная функция fT,n: ()n , которая представляется (или вычисляется) машиной T, задается как:

n-местная частичная функция f: ()n называется частично вычислимой по Тьюрингу, если существует такая машина Тьюринга, что
fT,n(w1, …,wn) = f(w1, …,wn),
для всех (w1, …, wn) ()n.
Частично вычислимая по Тьюрингу функция называется полностью вычислимой по Тьюрингу, если T останавливается для всех входных слов (w1, …, wn) ()n.
Формальный язык L , принимаемый машиной Тьюринга T, определяется через:
L = {w | q0w ![]() q, w , q F, , }.
q, w , q F, , }.
Формальный язык над называется перечислимым по Тьюрингу, если он принимается некоторой машиной Тьюринга. Он называется разрешимым по Тьюрингу, если он принимается некоторой машиной Тьюринга, которая останавливается для всех входных слов w .
Пример 2.6. Мы хотим построить машину Тьюринга T, которая принимает формальный язык {anbncn | n 1}:
T = (Q, , Г, , q0, F), где
Q = (q0, q1, q2, q3, q4, q5, q6, q7, qf), = {a, b, c}, = (a, b, c, X, e}, F = {qf};
Функция перехода определена следующим образом:
-
(q0, a) = (q1, a, R)
(q1, a) = (q1, a, R)
(q1, b) = (q2, b, R)
(q2, b) = (q2, b, R)
(q2, c) = (q3, c, R)
(q3, c) = (q3, c, R)
(q3, e) = (q4, e, L)
Проверка, выполнено ли w a+b+c+. Если да, то T переходит в состояние q4. В противном случае T останавливается в одном из состояний q0, q1, q2 или q3, не акцептируя слово.
(q4, X) = (q4, X, L)
(q4, c) = (q5, X, L)
Головка передвигается налево до
символа c. Он заменяется на X.
(q4, e) = (qf, e, R)
При пробеге влево в состоянии q4 на ленте находятся только символы X. T акцептирует слово.
(q5, c) = (q5, c, L)
(q5, X) = (q5, X, L)
(q5, b) = (q6, X, L)
Головка передвигается дальше
налево до символа b, который
заменяется на X.
(q6, b) = (q6, b, L)
(q6, X) = (q6, X, L)
(q6, a) = (q7, X, R)
Головка передвигается дальше до символа a, который заменяется на X.
(q7, X) = (q7, X, R)
(q7, b) = (q7, b, R)
(q7, c) = (q7, c, R)
(q7, e) = (q4, e, L)
Головка возвращается на самый крайний справа символ X, и T снова попадает в состояние q4.
Если в состоянии q4 будет найден один из символов a или b, то T останавливается, не акцептируя слово. Потому что тогда число символов a или b во входном слове больше, чем число символов c. Если в состоянии q5 или q6 не будет найдено b или a, то аналогично T останавливается, не акцептируя слово, так как тогда число символов c во входном слове больше, чем количество b или a.
Слово w = a3b3c3 принимается следующим образом:
q0aaabbbccc * aaabbbсссq3 aaabbbccq4c
aaabbbcq5cX * aaabbq5bccX aaabq6bXccX *
* aaq6abbXccX aaXq7bbXccX * aaXbbXccq4X
aaXbbXcq4cX aaXbbXq5cXX * aaXbq5bХcXX
aaXq6bXXcXX * aq6aXbXXcXX aXq7XbXXcXX *
* aXXbXXcXq4X * aXXbXXq4cXX aXXbXq5XXXX *
* aXXq5bXXXXX aXq6XXXXXXX * q6aXXXXXXXX
* Xq7XXXXXXXX * XXXXXXXXq4X * q4eXXXXXXXXX
qfXXXXXXXXX.
Акцептирование anbncn требует O(n2) шагов. □
Пример 2.7. Построим теперь машину Тьюринга, которая при вводе an, n 0 вычисляет двоичное представление числа n как слово над {0, 1}:
T = (Q, , Г, , q0, F),
где Q = (q0, q1, q2, q3), = {a}, = (a, 0, 1, e}, F = ;
Функция перехода определена следующим образом:
-
(q0, e) = (q2, 0, L)
При вводе = а0 возвращается 0.
(q0, a) = (q1, a, R)
(q1, a) = (q1, a, R)
(q1, 0) = (q1, 0, R)
(q1, 1) = (q1, 1, R)
(q1, e) = (q2, e, L)
Головка передвигается на крайний справа, отличный от е символ. Если этот символ 0 или 1, то вычисление закончено.
(q2, a) = (q3, e, L)
(q3, a) = (q3, a, L)
Если это символ а, то он замещается на е, и головка передвигается влево до двоичного числа, стоящего перед группой символов а.
(q3, 0) = (q1, 1, R)
(q3, 1) = (q3, 0, L)
(q3, e) = (q1, 1, R)
К этому двоичному числу добавляется 1.
Двоичное представление числа 6 вычисляется следующим образом:
q0aaaaaa * aaaaaq2a aaaaq3a * q3eaaaaa
1q1aaaaa * 1aaaaq2a 1aaaq3a * q31aaaa
q3e0aaaa 1q10aaaa * 1q30aaa 11q1aaa *
* 1q31aa q310aa q3e00aa 1q100aa *
* 10q30a 101q1a * 10q31 1q300
11q10 110q1 11q20.
Вычисление двоичного представления числа n требует O(n2) шагов. Существует «более сложная» машина Тьюринга, которая вычисляет двоичное представление за O(n log n) шагов. □
Как модификацию двусторонней детерминированной машины Тьюринга рассмотрим одностороннюю детерминированную машину Тьюринга. Она имеет ленту, которая потенциально бесконечна только в одну сторону. Конец ленты маркируется некоторым специальным символом, например Z0, который не должен меняться.
Пусть Т2 двусторонняя машина Тьюринга. Тогда односторонняя машина Тьюринга Т1 моделирует двустороннюю машину Тьюринга Т2 следующим образом. Начальный участок ленты машины Т1 при необходимости разделяется на две дорожки (т. е. алфавит ленты машины Т1 содержит Г Г, где Г – алфавит ленты Т2). Вторая дорожка служит для того, чтобы представлять содержание ячеек машины Т2, которые лежат левее той ячейки, над которой находится головка чтения-записи в начале вычислений. В своем множестве состояний Т1 «отмечает», находится она на верхней или на нижней дорожке (т. е. множество состояний машины Т1 содержит Q {вверху, внизу}, где Q – множество состояний машины Т2). Если, например, машина Т2, исходя из начальной конфигурации, q0a1a2a3a4a5 делает три шага влево, при которых последовательно записываются символы А1, А2, А3, то достигаемая тем самым конфигурация qeA3A2A1a2a3a4a5 машины Т2 представляется с помощью машины Т1 следующим образом:

Если машина Т2 выполняет передвижение вправо, то и машина Т1, если она находится в состоянии (q, вверху), тоже выполняет движение вправо. Если же машина Т1, как в предыдущем примере, находится в состоянии (q, внизу), то она выполняет движение влево. Подобное справедливо при передвижении машины Т2 влево. Если Т1 достигает символа Z0, то она должна перейти из состояния (q, внизу) в (q, вверху), или наоборот.
В конце вычислений,
если должна представляться функция,
все символы должны быть сдвинуты на
верхнюю дорожку и пары
![]() заменяются на А.
заменяются на А.
В следующем предложении мы сформулируем, что языки, принимаемые машинами Тьюринга, есть в точности перечислимые языки.
Предложение 2.4. Пусть L формальный язык. Тогда следующие высказывания эквивалентны:
-
Существует грамматика Ван-Вайнгаардена, которая порождает L.
-
Существует грамматика Хомского типа 0, которая порождает L.
-
Существует двусторонняя детерминированная машина Тьюринга, которая принимает L.
-
Существует односторонняя детерминированная машина Тьюринга, которая принимает L.
Доказательство. Мы покажем только моделирование действий односторонней машины Тьюринга T = (Q, , Г, , q0, F) грамматикой типа 0 G = ({S, T, $} Q ( ), , P, S). При этом следующие продукции лежат в Р:
-
S TZ0q0, T $, T aTa, a .
Эти продукции осуществляют вывод S w$wRZ0q0, где w .
-
aq pb для (q, a) = (p, b, R),
aqcbcp для (q, a) = (p, b, L),
$ $e.
Применяя эти продукции, мы можем
моделировать действия машины Тьюринга
Т: S w$![]() q
q![]() тогда и только тогда, когда
q0Z0w * 1q2.
тогда и только тогда, когда
q0Z0w * 1q2.
-
qz q, zq q, $q , q F, z .
Если Т достигает конечной конфигурации
1q2,
q F,
то с помощью продукций (i),
(ii) возможен вывод:
S w$![]() q
q![]() .
С помощью продукций (iii)
возможен следующий вывод: w$
.
С помощью продукций (iii)
возможен следующий вывод: w$![]() q
q![]() w.
□
w.
□
Рассмотрим другую модификацию машины Тьюринга – многоленточную машину. Детерминированная k-ленточная машина Тьюринга имеет k лент, потенциально бесконечных в обе стороны. Над каждой лентой находится головка чтения-записи. Функция перехода имеет в качестве аргументов соответствующее состояние и символы, читаемые на каждой из лент. Ее значения задают новое состояние, новые символы, которые записываются на месте старых, и независимые друг от друга перемещения головок чтения-записи, которые на каждом шаге передвигаются влево (L), вправо (R) или не передвигаются (S):
(q, A1, …, Ak) = (p, B1, …, Bk, S1, …, Sk),
где q, p Q, Ai, Bi , Si {L, S, R}.
(Также и в рассматривающихся до сих пор моделях машин Тьюринга возможно допустить отсутствие передвижения головки чтения-записи при прямом переходе. Тем самым вычислительная «сила» машины Тьюринга не повышается – только что «программирование» становится удобней.)
Конфигурация k-ленточной машины Тьюринга есть элементы из (Q ()k. При этом специальный символ обозначает положение головки чтения-записи на соответствующей ленте. Таким образом, конфигурации имеют вид:
(q, 11, 22, …, kk).
Входное слово (w1, …, wn) представляется конфигурацией (q0, w1e … ewn, , …, ). Переход от одной конфигурации к другой осуществляется детерминированным образом с помощью функций перехода. Остальные определения, которые относятся к машинам Тьюринга, переносятся аналогично.
Предложение 2.5. k-ленточная машина Тьюринга (k 1) может быть смоделирована двухсторонней машиной Тьюринга.
Доказательство. Пусть Т – k-ленточная машина Тьюринга. Тогда конфигурация машины Т может быть смоделирована двухсторонней машиной Тьюринга Т1, лента которой разделена на 2k дорожек:

Дорожка «лента i» содержит содержимое i-той ленты машины Т1, дорожка «головка i» маркирует позицию i-той дорожки, в которой находится головка чтения-записи машины Т. В состояниях машины Т1 хранится информация о том, находится символ Х на дорожке «головка i» слева или справа от головки чтения-записи машины Т1. Кроме того, соответствующие состояния машины Т хранятся в машине Т1. Для моделирования перехода машины Т машина Т1 должна найти символ Х на дорожке «головка i» и лежащий под ним символ на дорожке «лента i» занести как информацию в состояние. После просмотра всех k дорожек машина Т1 знает, как нужно изменить k символов и как нужно выверить позиции символа Х. Тогда необходимо снова найти символ Х на дорожке «головка i», лежащий под ним символ заменить согласно функции перехода машины Т и сдвинуть при необходимости символ Х. После того как это проделано для всех дорожек, Т1 находится в конфигурации, которая представляет последовательность конфигураций машины Т. Разумеется, на каждом шаге нужно следить за тем, чтобы информация о том, находится символ Х на дорожке «головка i» слева или справа от головки чтения-записи машины Т1, была занесена в новое состояние. □
Преимущество многоленточных машин Тьюринга состоит в том, что они в общем случае быстрее, чем одноленточные.
Пример 2.8. Мы хотим построить двухленточную машину Тьюринга, которая принимает формальный язык {anbncn | n 1}:
T = (Q, , Г, , q0, F),
где Q = (q0, q1, q2, qf), = {a, b, c}, = (a, b, c, e}, F = {qf}.
Функция перехода определена следующим образом:
-
(q0, a, e) = (q0, a, a, R, R)
Ведущая а-группа входного слова копируется на вторую ленту.
(q0, b, e) = (q1, b, e, S, L)
Как только на первой ленте появляется b, то головка на второй ленте устанавливается на последний скопированный символ а.
(q1, b, a) = (q1, b, a, R, L)
Теперь количество символов b на первой ленте сравнивается с количеством символов а на второй ленте.
(q1, с, е) = (q2, с, е, S, R)
Если эти числа совпадают и на первой ленте появляется символ с, то головка на второй ленте устанавливается на первом копируемом символе а.
(q2, с, а) = (q2, с, а, R, R)
Теперь количество символов с на первой ленте сравнивается с количеством символов а на второй ленте.
(q2, е, е) = (qf, e, e, S, S)
Если эти числа совпадают, то входное слово принимается.
Слово a3b3c3 принимается следующим образом:
(q0, aaabbbccc, ) * (q0, aaabbbccc, aaa)
(q1, aaabbbccc, aaa) * (q1, aaabbbccc, eaaa)
(q2, aaabbbccc, aaa) * (q2, aaabbbccc, aaa)
(qf, aaabbbccc, aaa).
Принятие слова anbncn требует О(n) шагов. □
Дальнейшей модификацией машины Тьюринга является недетерминированная машина Тьюринга. При этом функция перехода производит отображение в конечные подмножества состояний символов и изменений направления. Лента в обоих направлениях является потенциально бесконечной. Здесь нельзя больше говорить о функции, определенной недетерминированной машиной Тьюринга, так как она была бы определена неоднозначно. Мы получили бы здесь отношение. Однако недетерминированная машина Тьюринга принимает слово тогда, когда она для какой-либо последовательности прямых переходов останавливается в конечном состоянии. Множество принятых слов есть тогда формальный язык, принимаемый недетерминированной машиной Тьюринга.
Предложение 2.6. Недетерминированная машина Тьюринга может быть смоделирована трехленточной машиной Тьюринга (и тем самым обычной машиной Тьюринга).
Доказательство. Пусть Т недетерминированная машина Тьюринга. Для каждого состояния и каждого символа ленты существует не более чем конечное число возможностей для прямого перехода. Пусть r максимальное число таких возможностей. Следующая трехленточная машина Тьюринга Т1 моделирует Т.
Первая лента машины Т1 содержит входное слово. На второй ленте представляются числа в системе счисления по базису r, упорядоченные по величине. Каждому такому числу может, но не обязательно, соответствовать одна из возможностей прямых переходов.
Для каждого числа на второй ленте входное слово копируется с первой ленты на третью и машина Т моделируется машиной Т1 на третьей ленте, в соответствии с числом, записанным на второй ленте. Если Т останавливается в конечном состоянии, то останавливается и Т1. □
Пример 2.9. Построим недетерминированную машину Тьюринга для проблемы рюкзака (англ. knapsackproblem):
Даны натуральные числа x1,
…, xm,
m
1. Существует ли подмножество J
{1, …, m1},
такое, что
![]() ?
?
(Эту проблему можно наглядно сформулировать так: даны какие-либо предметы размером x1, …, xm-1. Можно ли рюкзак вместимостью xm наполнить полностью путем некоторого выбора этих предметов?)
Представим эту проблему как формальный язык
RUCKSACK = {w1a
… awm
| wi,
где 1
i
m и m
1, есть двоичное представление натурального
числа xi,
и существует подмножество J
{1, …, m1},
такое, что
![]() }
}
и построим
недетерминированную машину Тьюринга
Т, которая принимает этот язык.
(Для простоты будем допускать ведущие
нули в двоичных числах и разрешим число
0 изображать через .).
Машина Тьюринга обрабатывает
последовательность чисел w1a
… awm
слева направо. Для каждого символа а
она может (недетерминированным образом)
стоящее слева от а число xi
либо игнорировать (xi
не пакуется в рюкзак), либо вычитать из
xm
(xi
пакуется в рюкзак). Входное слово
принимается в точности тогда, когда
последнее число последовательности
сократится до нуля. Вычитание числа xi
из xm
происходит (как при ручных вычислениях)
цифра за цифрой. Вычтенные уже цифры
в xi
заменяются на символ Х; позиция в
xm,
в которой только что проводилось
вычитание, маркируется (т. е. вместо 0
или 1 пишется
![]() или
или
![]() ),
для того чтобы обеспечить правильность
соответствия позиций при вычитании.
Формально машина Т строится следующим
образом:
),
для того чтобы обеспечить правильность
соответствия позиций при вычитании.
Формально машина Т строится следующим
образом:
T = (Q, , Г, , q0, F),
где
Q = (q0, q1, q2, q3, q4, q5, r0, r1, s0, s1, t1, qf), = {0, 1, a},
= {0, 1, a, X, ![]() ,
, ![]() , e},
F ={qf};
, e},
F ={qf};
функция перехода определена следующим образом:
-
(q0, e) = {(qf, e, L)}
Последнее число 0 – входное слово принимается.
(q0, 0) = {(q0, e, R)}
Ведущие нули стираются.
(q0, а) = {(q0, e, R)}
xi состоит только из нулей, игнорировать.
(q0, 1) = {(q1, 1, R)}
(q1, 0) = {(q1, 0, R)}
(q1, 1) = {(q1, 1, R)}
xi содержит 1 – идти направо до следующего символа а.
(q1, а) = {(q0, е, R),
(q2, X, L)}
xi игнорировать или
вычитать. недетерминировано!
(q2, Х) = {(q2, Х, L)}
Искать следующую еще не вычтенную цифру.
(q2, 0) = {(r0, Х, R)}
(q2, 1) = {(r1, Х, R)}
Заметить вычитаемую цифру.
(q2, е) = {(q3, e, R)}
Завершить вычитание xi.
(q3, X) = {(q3, e, R)}
Все символы Х стереть.
(q3, 0) = {(q3, 0, R)}
(q3, 1) = {(q3, 1, R)}
(q3, а) = {(q3, а, R)}
Идти вправо до маркировки.
(q3,
 )
= {(q4,
0, R)}
)
= {(q4,
0, R)}(q3,
 )
= {(q4,
1, R)}
)
= {(q4,
1, R)}Удалить маркировку.
(q4, 0) = {(q4, 0, L)}
(q4, 1) = {(q4, 1, L)}
(q4, a) = {(q4, a, L)}
(q4, e) = {(q0, e, R)}
Идти влево к началу xi+1.
(r0, X) = {(r0, X, R)}
(r0, 0) = {(r0, 0, R)}
(r0, 1) = {(r0, 1, R)}
(r0, а) = {(r0, а, R)}
(r0, e) = {(s0, e, L)}
(r0,
 )
= {(s0,
0, L)}
)
= {(s0,
0, L)}(r0,
 )
= {(s0,
1, L)}
)
= {(s0,
1, L)}(r1, X) = {(r1, X, R)}
(r1, 0) = {(r1, 0, R)}
(r1, 1) = {(r1, 1, R)}
(r1, а) = {(r1, а, R)}
(r1, e) = {(s1, e, L)}
(r1,
 )
= {(s1,
0, L)}
)
= {(s1,
0, L)}(r1,
 )
= {(s1,
1, L)}
)
= {(s1,
1, L)}Идти вправо до последней немаркированной цифры, при необходимости удалить старую маркировку.
(s0, 0) = {(q5,
 ,
L)}
,
L)}(s0, 1) = {(q5,
 ,
L)}
,
L)}(s1, 0) = {(t1,
 ,
L)}
,
L)}(s1, 1) = {(q5,
 ,
L)}
,
L)}(t1, 0) = {(t1, 1, L)}
(t1, 1) = {(q5, 0, L)}
Произвести вычитание 0 (соотв. 1), при этом маркировать возникающие цифры. Учитывать возможный перенос (t1).
(q5, 0) = {(q5, 0, L)}
(q5, 1) = {(q5, 1, L)}
(q5, а) = {(q5, а, L)}
(q5, Х) = {(q2, Х, L)}
Идти налево до символа Х и снова в cостояние q2, для того чтобы искать следующую вычитаемую цифру.
Проблема рюкзака х1 = 2, х2 = 3, х3 = 1, х4 = 5 может быть решена с помощью машины Т (поскольку х1 + х2 = х4) следующим образом:
q0010a11a01a101 * 1q20X11a01a101 *
*
XXX11a01a1q50![]() *
XXX11a01q5a0
*
XXX11a01q5a0![]() 1
*
1
*
*
q011a01a011
*
XXX01q50![]() 0
*
0
*
* q001a000 * 1eeeqf. □