

Введение
Изложенный здесь материал на протяжении ряда лет читался профессором Вернером Куихом в курсе «Теоретическая информатика» для студентов Венского технического университета. Данное пособие может рассматриваться лишь как краткий конспект лекций, читаемых авторами для студентов математического факультета Калининградского госуниверситета, и не является заменой последних.
В пособии изложены основы теории формальных языков и грамматик, включая регулярные, контекстно-свободные грамматики и грамматики Ван Вайнгаардена, а также теория автоматов применительно к анализу формальных языков, включая конечные автоматы, магазинные автоматы и машины Тьюринга. Далее даны основы теории алгоритмов и рекурсивных функций, где особое внимание уделено вопросам вычислимости. В последней главе рассмотрены проблемы весьма актуальной сейчас теории сложности.
В конце пособия приведены упражнения по изложенным темам вместе с их краткими решениями, что необходимо для практического закрепления материала.
1. Грамматики, автоматы и контекстно-свободные языки
Алфавит есть непустое конечное множество. Элементы алфавита называются символами. Пусть – алфавит. Множество всех слов над , а именно
= {x1x2…xn | xi, 1in, n0}
вместе с операцией конкатенации образуют свободный моноид, порожденный , с единичным элементом (для n = 0). Через |w| обозначим длину слова w: |x1…xn| = n, n1, || = 0. Очевидно, выполняется |w1w2| = |w1| + |w2|. Отображение | |: , где – неотрицательные целые числа {0, 1, 2,...} есть гомоморфизм моноида <, , > на моноид <, +, 0>.
Каждое подмножество L множества , т.е. L , называется формальным языком над . Пусть L1 и L2 формальные языки над , т.е. L1, L2 . Тогда определим произведение L1 и L2 как L1L2 = w1w2 | w1L1, w2L2} .
Естественно <P(), , {}> снова моноид. (Через P обозначим степень множества.) Он называется моноидом формальных языков.
Для L мы можем с помощью произведения определить степени:
L0 = {}, Ln+1 = LLn = LnL, n0.
L
определяется как L
=
![]() n.
Нам потребуется также L+
=
n.
Нам потребуется также L+
=
![]() n.
Очевидно, выполняется L
= {}
L+ и L+
= LL
= LL.
n.
Очевидно, выполняется L
= {}
L+ и L+
= LL
= LL.
В случае, если множество М содержит в точности один элемент, М = {а}, то мы также будем писать, если не возникнет путаницы, просто а. Справедливо: an = a … a (n раз) и a = {an | n0}.
Пусть S – множество. Каждое подмножество R множества SS, т.е. R SS, называется (двухместным) отношением над S. Если (s1,s2)R, то мы пишем s1Rs2.
Пусть R – отношение над S. Транзитивное замыкание R+ определяется следующим образом: t1R+t2 в точности тогда, если существуют s1, s2, …, snS, n>1, такие что t1 = s1, t2 = sn и sjRsj+1, 1jn-1. Рефлексивное и транзитивное замыкание R определяется следующим образом: t1Rt2 в точности тогда, если t1 = t2 или t1R+t2.
Грамматики есть математические системы, служащие для порождения формальных языков. Для определения синтаксиса языка программирования они чрезвычайно важны. Множество синтаксически правильных программ (причем содержание программ не принимается во внимание) может пониматься как формальный язык. Этот формальный язык определяется в общем случае через контекстно-свободную грамматику в нормальной форме Бэкуса.
Контекстно-свободная грамматика есть четверка G = (Ф, , P, S). Причем
-
Ф – алфавит, называемый алфавитом переменных, или нетерминальных символов;
-
– алфавит, называемый алфавитом базовых, или терминальных, символов, где Ф , V = Ф ;
-
P Ф(Ф ) – конечное множество, называемое множеством продукций;
-
SФ – начальная переменная.
Пусть G = (Ф, , P, S) – контекстно-свободная грамматика. Тогда G (или просто ) – отношение на V, которое определено следующим образом: тогда и только тогда, когда A, = и (A,)P.
Говорят, что прямо выводит , или может быть непосредственно выведено из .
Пусть отношение ![]() (или просто )
рефлексивное и транзитивное замыкание
отношения G.
Говорят, что выводит
, или
может быть выведено из .
(или просто )
рефлексивное и транзитивное замыкание
отношения G.
Говорят, что выводит
, или
может быть выведено из .
Пусть G = (Ф, , Р, S) – контекстно-свободная грамматика. Тогда обозначим L(G) – язык, порожденный G, причем выполняется:
L(G)
= {w | w
и S ![]() w}.
w}.
Если (А,)Р, то пишем также АG , или АP.
Пример 1.1. Пусть G = ({S}, {(,)}, P, S) с P = {S(S)S, S}. Тогда L(G) – есть множество всех корректных скобочных выражений над скобками ( и ). Например: (())() L(G), так как это выражение может быть выведено из S:
S (S)S ((S)S)S (()S)S (())S (())(S)S (())()S (())().
Таким образом, выполняется S * (())(), и тем самым (())() лежит в L(G).
Грамматика G’ = ({S}, {(,)}, P’,S) с P’ = {SSS, S(S), S} порождает тот же самый язык. Однако правила вывода имеют другую структуру:
S SS (S)S ((S))S (())S (())(S) (())().
Тем самым показано, что (())()L(G’). □
Если синтаксис языка программирования определяют через контекстно-свободную грамматику, то продукции часто представляют в нормальной форме Бэкуса. При этом переменные пишутся в форме <w>, где w – непустое слово над алфавитом VZ. Если <w> 1, …, <w> n – все продукции с левой частью <w>, то пишут
<w>::= 1|2|…|n.
Алфавиты Ф, VZ, не всегда указаны. Кроме того, разрешена следующая конструкция: j может иметь вид 1{2}3. Это означает, что возможны прямые выводы:
<w> 12n3, n0.
Пример 1.2. В языке PASCAL константы определяются в разделе описания констант. Синтаксис раздела описания констант задается следующими правилами (в нормальной форме Бэкуса):
<раздел описания констант>::= <пустой>|const<определение константы> {;<определение константы>};
<определение константы>::=<идентификатор константы> = <константа>
<идентификатор константы>::= <идентификатор>
<идентификатор>::= <буква>{<буква или цифра>}
<буква или цифра>::= <буква>|<цифра>
<буква>::= A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z
<цифра>::= 0|1|2|3|4|5|6|7|8|9
<константа>::= <число без знака>|<знак><число без знака>|
<идентификатор константы>|<знак><идентификатор константы>
<число без знака>::= <целое без знака>|<вещественное без знака>
<целое без знака>::= <цифра>{<цифра>}
<вещественное без знака>::= <целое без знака>.<цифра>{<цифра>}|
<целое без знака>.<цифра>{<цифра>}Е
<характеристика>|<целое без знака>Е
<характеристика>
<характеристика>::= <целое без знака>|<знак><целое без знака>
<знак>::= +|-
<пустой>::=
Определение константы
const PI = 3.14; E = 2.73;
синтаксически правильно, так как существует вывод:
<раздел описания констант>
const <определение константы>;<определение константы>;
const <идентификатор константы>=<константа>;<определение константы>;
const<идентификатор>=<константа>;<определение константы>;
const <буква><буква или цифра>=<константа>;<определение константы>;
const <буква><буква>=<константа>;<определение константы>;
const Р <буква> = <константа>;<определение константы>;
const РI = <константа>;<определение константы>;
const РI = <число без знака>;<определение константы>;
const РI = <вещественное без знака>;<определение константы>;
const РI = <целое без знака><цифра><цифра>;<определение константы>;
const РI = <цифра><цифра><цифра>;<определение константы>;
* const РI = 3.14;<определение константы>;
* const PI = 3.14; E = 2.73; □
Формальный язык L * называется контекстно-свободным тогда и только тогда, когда имеется контекстно-свободная грамматика G, такая что L(G) = L. Множество всех выражений, правильно заключенных в скобки, и множество всех синтаксически правильных определений констант есть, таким образом, контекстно-свободные языки.
Каждому выводу в контекстно-свободной грамматике G = (Ф, , Р, S) можно поставить в соответствие направленное дерево, так называемое дерево вывода, узлы которого обозначаются символами из V:
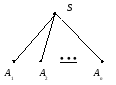
-
Выводу S A1A2…An, AjV, 1jn, соответствует дерево вывода:

(2) Пусть выводу S 1A2, 1,2 V, AФ, соответствует дерево вывода:
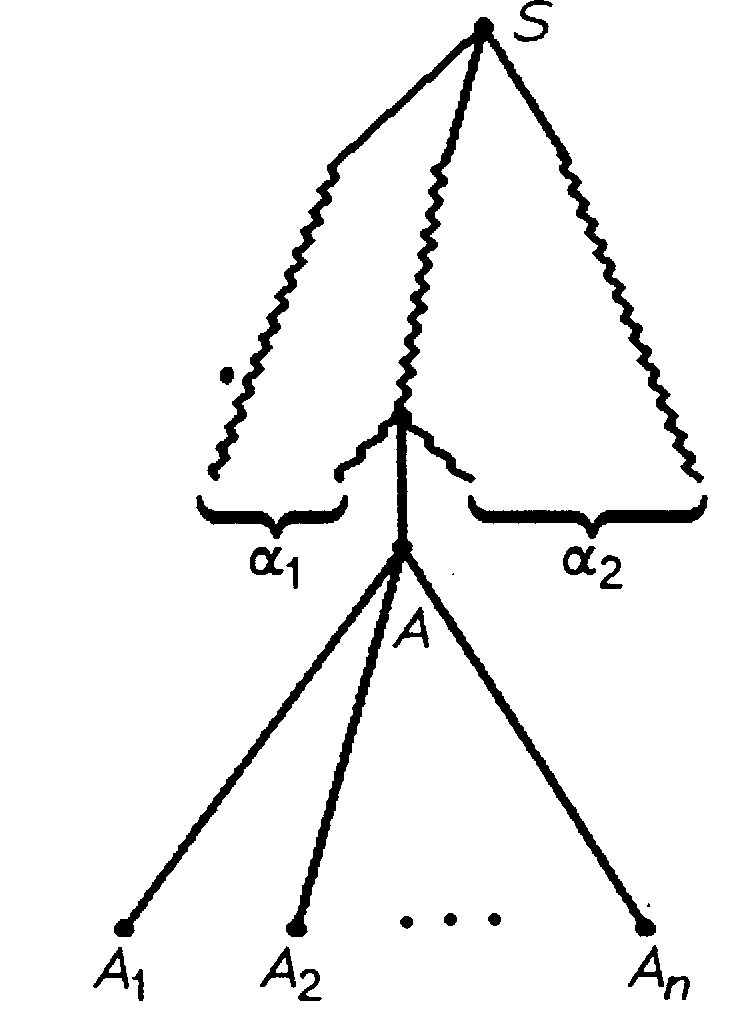
Тогда выводу S 1A2 1A1…An2, AjV соответствует дерево вывода:
Метки конечных узлов, если они при прохождении по дереву вывода в положительном направлении связываются воедино, дают в результате слово 1A1…An2. Это слово называется результатом дерева вывода.
Пример 1.3. Выводам слова (())() в G и G’ соответствуют деревья вывода:
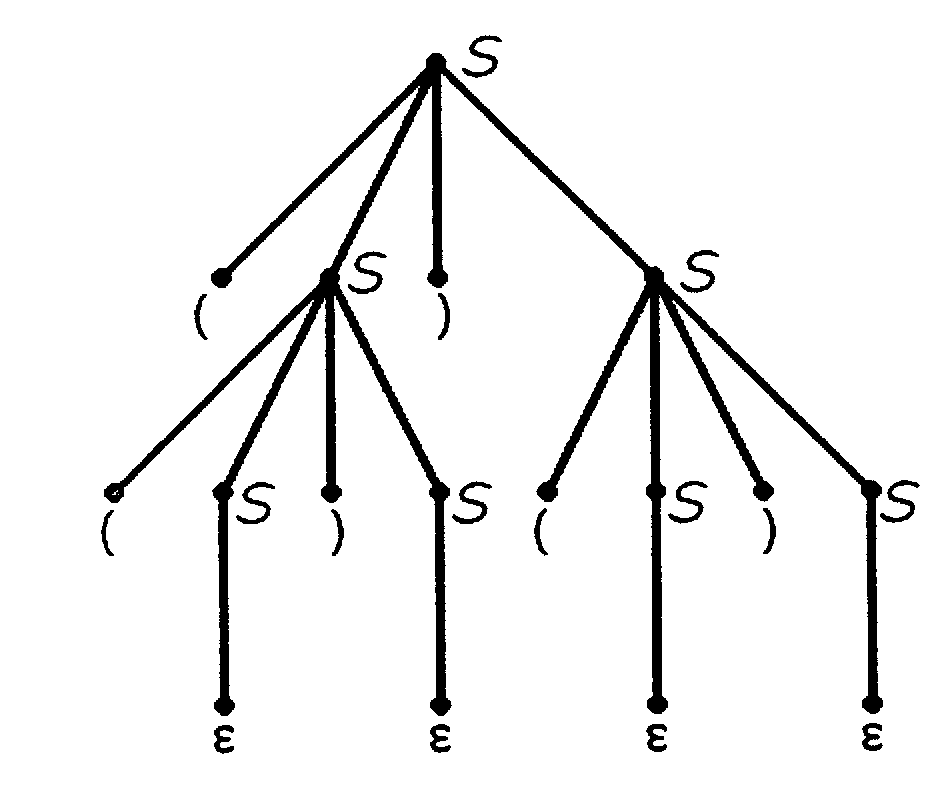

Пунктирные линии не принадлежат дереву вывода, которое соответствует правилу вывода в примере. Тем не менее дерево, состоящее из сплошных и пунктирных линий, также является деревом вывода с результатом (())(). Таким образом, имеется два различных дерева вывода с результатом (())(). Это приводит к определению однозначной контекстно-свободной грамматики. Контекстно-свободная грамматика G называется однозначной тогда и только тогда, когда для каждого wL(G) найдется единственное дерево вывода. В противном случае она называется многозначной.
Пример 1.4. Пусть G = (Ф, , P, S),
где Ф = {![]() оператор
if
оператор
if![]() ,
,![]() оператор
оператор![]() };
};
= {if, then, else, выражение, другой_оператор};
P = {![]() оператор
if
оператор
if![]() ::=
if выражение then
::=
if выражение then
![]() оператор
оператор![]()
if выражение then
![]() оператор
оператор![]() else
else
![]() оператор
оператор![]() ;
;
![]() оператор
оператор![]() ::=
::=![]() оператор
if
оператор
if![]() другой_оператор};
другой_оператор};
S =
![]() оператор
if
оператор
if![]() .
.
L(G) описывает оператор if в PASCAL. Грамматика G – неоднозначна, так как «программа»: