

(по цифровому вещанию) Dvorkovich_V_Cifrovye_videoinformacionnye_sistemy
.pdfГлава 7. Групповое кодирование изображений
Рис. 7.15. Влияние изменений коэффициента квантования на качество восстанавливаемых изображений
где |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
h(ω) = (0,31 + |
0,69ω) · exp(−0,29ω), |
|
|
|
|||||||||||||||
|
& |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
||
a(ω) = |
|
1 |
+ |
1 |
|
|
ln |
|
2πω |
+ |
|
1 + |
2πω 2 |
|
, |
|||||
|
|
π2 |
|
|
|
|
α |
|
|
|||||||||||
|
4 |
|
· |
|
α |
|
|
|
|
|
||||||||||
|
' |
|
|
|
|
|
|
- |
|
|
|
|
|
|||||||
|
' |
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
' |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
( |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
α = 11, |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
636 deg−1, ω = |
|
|
u2 + v2. |
|
|
|
|||||||||
Группой JPEG, занимающейся |
стандартизацией алгоритмов цифровой обра- |
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||||
ботки статических изображений, эмпирически получено несколько таблиц квантования и, в частности, данные, приведенные в табл. 7.4 для обработки сигналов яркости и цветности [3.68, 3.70]. На рис. 7.16 приведены варианты использования указанных таблиц при дискретном косинусном преобразовании изображений для двух значений коэффициента k.
Сравнивая изображения, приведенные на рис. 7.15 и рис. 7.16 при одинаковых коэффициентах сжатия, следует сказать, что использование таблиц квантования позволяет получить более высокое качество восстанавливаемых изображений при одной и той же степени сокращения избыточности информации.

7.3. Кодирование коэффициентов преобразования
Таблица 7.4. Таблицы квантования сигналов яркости и цветности
Таблица квантования сигнала яркости
16 |
11 |
10 |
16 |
24 |
|
|
40 |
51 |
|
|
61 |
|
12 |
12 |
14 |
19 |
26 |
|
|
58 |
60 |
|
|
55 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
14 |
13 |
16 |
24 |
40 |
|
|
57 |
69 |
|
|
56 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
14 |
17 |
22 |
29 |
51 |
|
|
87 |
80 |
|
|
62 |
|
18 |
22 |
37 |
56 |
68 |
|
|
109 |
103 |
|
|
77 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
24 |
35 |
55 |
64 |
81 |
|
|
104 |
113 |
|
|
92 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
49 |
64 |
78 |
87 |
103 |
|
|
121 |
120 |
|
|
101 |
|
72 |
92 |
95 |
98 |
112 |
|
|
100 |
103 |
|
|
99 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица квантования сигнала цветности |
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
17 |
18 |
24 |
47 |
99 |
|
|
99 |
99 |
|
|
99 |
|
18 |
21 |
26 |
66 |
99 |
|
|
99 |
99 |
|
|
99 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
24 |
26 |
56 |
99 |
99 |
|
|
99 |
99 |
|
|
99 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
47 |
66 |
99 |
99 |
99 |
|
|
99 |
99 |
|
|
99 |
|
99 |
99 |
99 |
99 |
99 |
|
|
99 |
99 |
|
|
99 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
99 |
99 |
99 |
99 |
99 |
|
|
99 |
99 |
|
|
99 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
99 |
99 |
99 |
99 |
99 |
|
|
99 |
99 |
|
|
99 |
|
99 |
99 |
99 |
99 |
99 |
|
|
99 |
99 |
|
|
99 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 7.16. Сжатие с применением неравномерной матрицы квантования компонентов дискретного косинусного преобразования
После квантования компоненты унитарных преобразований, в частности ДКП, блоков изображения группируются в определенной последовательности, а затем кодируются хаффмановским или арифметическим кодером.
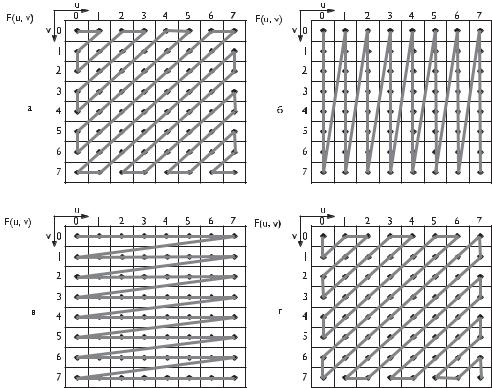
Глава 7. Групповое кодирование изображений
Рис. 7.17. Варианты упорядочивания коэффициентов дискретного косинусного преобра- |
зования |
Метод группировки коэффициентов преобразования имеет большое значение для уменьшения объема передаваемой информации.
Одним из вариантов группировки коэффициентов ДКП является Z-упорядо- чивание в соответствии со схемой рис. 7.17, вверху слева [3.69].
В этом случае коэффициенты выстраиваются в последовательности возрастания пространственных частот, причем если пространственные частоты одинаковы, то предпочтение отдается коэффициентам с меньшими вертикальными частотами.
Возможны и другие варианты группирования коэффициентов:
–если в блоке изображения в основном имеется горизонтальная структура изменения значений пикселов, то более эффективно вертикальное упорядочивание (рис. 7.17, вверху справа);
–при вертикальной структуре изменения значений пикселов более удобно горизонтальное упорядочивание (рис. 7.17, внизу слева);
–иногда используется структура (рис. 7.17, внизу справа), подобная Z-упо- рядочиванию, но с предпочтением к коэффициентам с меньшими горизонтальными частотами.
Часто для повышения эффективности кодирования коэффициенты Fkl(0, 0) разных блоков (k, l — соответственно номера блоков по горизонтали и вертикали)
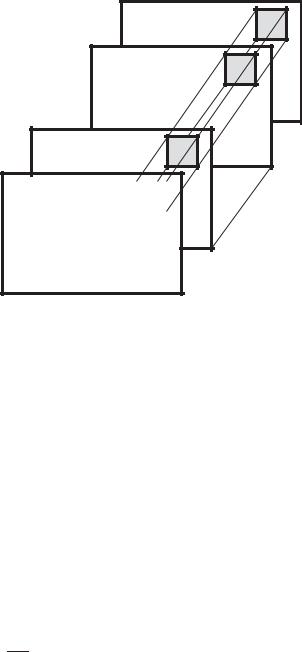
7.4. Межкадровое или трехмерное кодирование
Êàäð 1
Êàäð 2
Êàäð N-1
Êàäð N |
Áëîê |
|
|
|
|
||
|
пикселов |
|
|
|
N*N |
|
|
|
|
|
|
|
|
|
|
Рис. 7.18. К использованию трехмерного группового кодирования
изображения, характеризующие средние их яркости, группируют и передают отдельно, предварительно осуществляя их обработку с использованием алгоритмов предсказания.
Исследования статистики временных изменений яркости соответствующих элементов телевизионных изображений дают результаты, в целом аналогичные тем, что получаются при изучении пространственных свойств в неподвижных изображениях, причем коэффициенты корреляции получаются зачастую даже большими, чем для соседних пикселов или соседних строк в одном кадре.
Учитывая, что все рассмотренные в данной главе способы обработки массивов данных об изображениях легко обобщаются на трехмерные объекты (рис. 7.18), можно с уверенностью предположить, что результаты применения таких трехмерных преобразований подобны соответствующим результатам для плоского случая [3.17, 3.71, 3.72].
Например, дискретное прямое и обратное косинусное преобразование для трехмерного случая может быть записано в виде:
+
F (u, v, w) = |
8 |
C(u)C(v)C(w) × |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||||
N 3 |
|
πv(2j + 1) |
|
πw(2k + 1) |
|||||||
N −1 N −1 N −1 |
|
πu(2i + 1) |
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
||
× |
|
|
X(i, j, k) cos |
2N |
|
cos |
2N |
|
cos |
2N |
, (7.31) |
i=0 j=0 k=0 |
|
|
|
|
|
|
|
|
|
||

Глава 7. Групповое кодирование изображений
+
X(i, j, k) =
8
N 3
1 ,
√
2
N −1 N −1 N −1
C(u)C(v)C(w)F (u, v, w) ×
u=0 v=0 w=0 |
|
|
|
|
|
|
|
|
× cos |
πu(2i + 1) |
cos |
πv(2j + 1) |
cos |
πw(2k + 1) |
, (7.32) |
||
|
|
|
|
|
||||
2N |
2N |
2N |
||||||
n = 0,
1, n = 0.
Одним из важных аргументов использования трехмерных унитарных преобразований является возможность применения быстрых алгоритмов вычислений. Однако серьезным препятствием при этом является происходящая время от времени резкая смена сюжета, разрушающая межкадровые корреляционные связи.
Учитывая инерционные свойства зрения, влияние этого дефекта практически может быть существенно уменьшено путем замены некоррелированных кадров созданными с использованием экстраполяции или интерполяции. Важной проблемой при этом является разработка алгоритмов оценки резких изменений структуры кадра.
Хотя групповое кодирование практически обеспечивает декорреляцию информации в преобразуемых блоках изображения, однако и после преобразований сохраняется избыточность информации в связи с тем, что имеется корреляция между блоками.
Указанные выше недостатки, как уже было рассмотрено выше, уменьшаются при использовании гибридных преобразований [3.17, 3.73–3.76].
Например, при внутрикадровом гибридном преобразовании изображение разбивается на вертикальные полосы, по N пикселов вдоль строк внутри каждой полосы. Отрезки из N горизонтально расположенных пикселов подвергаются линейному дискретному косинусному преобразованию, после чего коэффициенты преобразования кодируются с предсказанием по вертикали.
Эта процедура дает выигрыш при кодировании коэффициентов низких пространственных частот, но более высокочастотные коэффициенты плохо коррелируют между собой, и их лучше передавать независимо.
Оценки таких преобразований показывают, что гибридное преобразование дает приблизительно такие же среднеквадратичные ошибки, что и двумерное дискретное косинусное преобразование.
Гибридное преобразование широко применяется при кодировании движущихся изображений, когда используется двумерное косинусное преобразование в кадре и предсказание между кадрами.
Вквазистационарных изображениях вектора движения малы независимо от числа пространственных деталей. Однако часто шум камеры и ее нестабильность вносят различия между кадрами даже в отсутствие движения.
Взависимости от используемого алгоритма и детальности изображения адаптивное гибридное кодирование позволяет уменьшить требуемую скорость передачи в 2–10 раз.
Дополнительно она может быть уменьшена при использовании компенсации движения.
Глава 8. Другие методы кодирования изображений
Одним из методов блочного кодирования является векторное кодирование, при котором весь набор блоков (векторов) изображения (как одного кадра, так и последовательности кадров) приводится к некоторому конечному набору [3.17, 3.76–3.81].
При этом вместо непосредственной передачи кодовых последовательностей, характеризующих значения пикселов в каждом блоке, передается лишь номер блока. Количество возможных векторов (блоков изображения) определяется при этом пропускной способностью канала.
Основным преимуществом векторного квантования является простая структура приемника, который имеет лишь кодовую таблицу векторов, а воспроизведение изображения осуществляется путем последовательной расстановки этих векторов согласно поступающей из канала связи информации.
При адаптивном векторном квантовании, кроме того, передается также информация об эталонных векторах.
Существенными недостатками векторного кодирования является, с одной стороны, сложность кодера, а с другой — плохая аппроксимация изображений, отличающихся от тех эталонных, по которым составлялась кодовая таблица.
Следует отметить, что существуют специальные алгоритмы формирования кодовых таблиц с использованием эталонных изображений. Иногда для ускорения процесса векторного кодирования и увеличения скорости передачи блоки изображения разбиваются на классы, для каждого из которых составляется своя кодовая таблица.
Алгоритмы векторного кодирования обеспечивают формирование специального набора блоков изображения (кодовой книги), составленного по принципу наилучшего приближения к блокам исходного изображения (например, минимизацией среднеквадратичного отклонения).
Содержание кодовой книги и номера (кодовые слова) ее элементов, на которые были заменены блоки исходного изображения, упорядоченные в порядке сканирования этих блоков (например, слева направо, сверху вниз), передаются декодеру, при этом количество элементов этой книги должно быть меньше количества блоков исходного изображения.
Если рассматривать различные блоки размера n × m пикселов как точкивектора в (n × m)-мерном пространстве изображений, то процесс замены их на элементы кодовой книги выглядит как квантование (вообще говоря, неравномерное) такого пространства на области сложной формы, окружающие точки, соответствующие изображениям — элементам кодовой книги (отчего и происходит название метода).
Пусть исходное изображение имеет размерность N ×M пикселов. При прямоугольном разбиении получается Nn · Mm блоков размерности n × m. Если кодовая книга будет содержать k элементов, то на ее передачу потребуется k×n×m×l битов, а последовательность кодовых слов займет еще Nn · Mm · log2 k битов, где l — разрядность оцифровки пикселов исходного изображения, в большинстве случаев равная 8.

|
|
|
8.2. Другие методы блочного и интерполяционного кодирования |
|
|||||||||
При этом достигается степень сжатия, равная |
|
|
|
|
|||||||||
comp = |
|
N · M · l |
= |
|
1 |
|
|
|
|
, |
(8.1) |
||
|
1 |
1 |
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|||
|
1 |
— степень |
|
|
log2 k |
|
|
|
|
|
|||
|
|
|
k · n |
· m · l c1 + Nn · Mm · log2 k |
|
k |
Nn · Mm · c1 + |
|
· |
1 |
|
|
|
где c |
|
|
|
l |
n·m |
|
|||||||
|
|
|
сжатия кодовой книги, которая может быть упакована с помо- |
||||||||||
щью каких-либо методов компрессии без потерь информации, причем реально достижимое c1 составляет около 2.
Очевидно, что сжатие с помощью векторного квантования предполагает обязательную потерю части информации, т. е. внесение искажений в исходное изображение. В процессе оптимизации процесса векторного квантования эти искажения минимизируются (при заданной степени сжатия, или, наоборот, достигается максимальное сжатие при заданном уровне допустимых искажений) путем:
–выбора оптимального размера блока n × m;
–выбора оптимального размера кодовой книги k;
–составления оптимального набора изображений — элементов кодовой книги.
Вообще говоря, существует и может быть найден глобальный оптимум одновременно по всем трем перечисленным параметрам. Положение этого оптимума определяется распределением Nn · Mm точек-блоков из исходного изображения в (n × m)-мерных пространствах изображения при различных n × m. При равномерном распределении, что соответствует некоррелированному шуму в исходном изображении, оптимальным оказывается равномерное квантование каждого пиксела исходного изображения, т. е.
n · m = 1; k = 2l/(2d); Ki = 2 · i · d;
где d — максимальная ошибка квантования; 2l — количество дискретных уровней в исходном изображении, Ki — i-й уровень воспроизводимых дискретных значений яркости пикселов.
В изображении с коррелированными значениями яркости пикселов точкиблоки распределены в пространстве изображений неравномерно, и центром «сгустков» таких точек, т. е. точек, в которых плотность вероятности нахождения блока из исходного изображения имеет локальный максимум, могут составить набор элементов кодовой книги, так что усредненная по исходному изображению ошибка, вносимая векторным квантованием, окажется меньшей, чем, например, при равномерном квантовании пространства изображений.
Следует заметить, что использованная выше в целях изложения сути метода векторного квантования модель представления блоков изображения в виде точек в многомерном пространстве изображений с вычислительной точки зрения слишком сложна, т. к. при этом придется работать с массивами данных объемом в (2l)n·m битов, что составляет, например, для блоков 4 × 4 пиксела и l = 8: 28·4·4 = 2128 — неприемлемую величину.
В описываемых в литературе реальных исследовательских схемах [3.76, 3.82, 3.83], как правило, объем кодовой книги и размерность блоков выбирают, исходя из ожидаемой степени сжатия (для comp=10 обычно выбирают n ×m=16 (блоки 4 × 4); для comp = 30 — n × m = 64 (блоки 8 × 8); количество элементов кодовой книги k обычно достигает нескольких тысяч). Основными задачами оптимизации кодирования при этом оказываются:
Глава 8. Другие методы кодирования изображений
–составление оптимального набора изображений элементов кодовой книги;
–поиск элемента кодовой книги, наилучшим образом соответствующего очередному кодируемому блоку из исходного изображения.
Алгоритм LBG
В 1980 году Linde, Buzo и Gray предложили алгоритм составления кодовой книги, дающий наилучшие до сего дня результаты [3.17, 3.78]. Этот алгоритм, именуемый LBG, состоит из двух процедур, последовательно-итерационно применяемых к системе — исходное изображение плюс кодовая книга, полученная в результате применения какого-либо иного предварительного алгоритма или составленная наугад из случайных изображений (от качества этой предварительной кодовой книги зависит лишь число итераций, которые необходимо будет произвести, прежде чем кодовая книга перестанет изменяться при каждой следующей итерации).
Алгоритм предусматривает реализацию последовательности итерационных процедур.
1.Процедура присваивания блокам исходного изображения соответствия тому или иному элементу текущей кодовой книги. При этом множество блоков, составляющих исходное изображение, разбивается на непересекающиеся подмножества, состоящие из блоков исходного изображения (необязательно в одном
итом же количестве), близких друг к другу и к некоторому элементу кодовой книги, в соответствии с некоторой мерой (например, среднеквадратичным или максимальным отклонением яркости по блоку). При этом число непересекающихся подмножеств должно быть равно количеству элементов текущей кодовой книги (оно может быть меньше конечной величины k).
2.Процедура «улучшения» текущей кодовой книги — замена ее элементов путем построения для каждого из полученных в предыдущей процедуре подмножеств блоков такого элемента кодовой книги, который бы минимизировал некоторое среднее отклонение от него всех блоков подмножества в смысле выбранной меры. При этом блоков — новых элементов кодовой книги, соответствующих каждому подмножеству, может быть и больше одного. Тогда происходит «расщепление» элемента текущей кодовой книги, так что ее объем может быть постепенно доведен до заранее выбранного значения k.
Если «расщепления» не происходит, то новый блок — элемент кодовой книги находится, например, путем попиксельного арифметического усреднения яркостей всех блоков подмножеств при использовании в качестве меры среднеквадратичного отклонения или же путем определения медианы значений яркостей соответствующих пикселов по всему подмножеству блоков при использовании в качестве меры максимального отклонения.
Расщепление представляет собой задачу нахождения оптимальной кодовой книги малого объема, где в качестве исходного изображения выступает рассматриваемое подмножество блоков. Однако при таком решении этой задачи сложность общего алгоритма оказывается неприемлемо высокой.
Поэтому обычно нахождение оптимальной кодовой книги осуществляется упрощенными способами — от случайного разбиения подмножеств на ряд более мелких, до выбора в качестве новых элементов кодовой книги векторов собственной
8.2. Другие методы блочного и интерполяционного кодирования
системы ковариационной матрицы, рассчитанной для подмножества блоков, имеющих наибольшие соответствующие собственные значения (метод Кархунена– Лоева) и т. п. [3.38, 3.82, 3.83].
Решение вопроса о том, осуществлять ли «расщепление» в данном подмножестве или нет, может быть принято из различных соображений, например исходя из анализа величины дисперсии блоков в подмножестве.
Алгоритм LBG весьма гибок, и предполагает дальнейшую оптимизацию в конкретном применении.
Недостатком алгоритма LBG является то, что большой объем необходимых для его исполнения вычислительных операций не поддается ни сокращению, ни распараллеливанию: на каждой итерации в первой процедуре приходится перебирать все блоки исходного изображения, сравнивая каждый из них со всеми элементами текущей кодовой книги, что не позволяет непосредственно применять LBG в системах реального времени.
Данный недостаток в значительной мере компенсируется тем, что в качестве предварительной кодовой книги можно использовать результат применения иных алгоритмов (например, алгоритм Эквитца), используя LBG лишь для окончательной оптимизации кодовой книги на малом количестве итераций (возможно) без «расщеплений».
Алгоритм Эквитца
Данный алгоритм составления кодовой книги [3.79, 3.82] основан на последовательном сокращении (в противоположность LBG) числа элементов исходной кодовой книги.
При этом в качестве исходной кодовой книги используется само исходное изображение. Сокращение осуществляется путем поиска пары элементов текущей кодовой книги, менее всего отличающихся друг от друга в смысле некоторой меры, с последующей заменой такой пары блоком, полученным попиксельным арифметическим усреднением значений яркости в этой паре.
Эту операцию осуществляют до тех пор, пока размер кодовой книги не станет равен требуемому значению.
Алгоритм Эквитца более благоприятен с вычислительной точки зрения, чем LBG, но уступает ему по качеству получаемой кодовой книги.
Намного меньших объемов вычислительных операций требуют алгоритмы, основанные на принятии в качестве элемента кодовой книги собственных векторов ковариационных матриц, рассчитанных для последовательностей блоков исходного изображения. При этом получаются кодовые книги, как правило, нуждающиеся в уточнении методом LBG [3.83].
Среднеквадратичные ошибки в приводимых в литературе экспериментальных данных составляют −24 дБ при степенях сжатия порядка 10 [3.76, 3.81].
В связи с проблемой поиска элемента кодовой книги, наилучшим образом сходного с блоком исходного изображения, следует заметить, что в алгоритмах, использующих метод Кархунена–Лоева, параллельно с созданием самой кодовой книги происходит построение системы многомерных плоскостей (гиперплоскостей), делящих пространство изображений на ячейки, так что поиск соответствия блока исходного изображения элементу кодовой книги из полного перебора всей кодовой книги превращается в бинарный поиск соответствующей ячейки.