

(по цифровому вещанию) Dvorkovich_V_Cifrovye_videoinformacionnye_sistemy
.pdfГлава 4. Статистическая избыточность дискретизированных данных
ксимволу «е» контекст сократился до «в». Контекст «в» встречался два раза. Вероятность символа «esc» без учета правила исключений равна 1/3, а с учетом этого факта — 1/2 . Пустой контекст встречался 22 раза. Значит, вероятность pˆ(a|¯c) = 1/23, а с учетом двух исключений (символы «а» и «о») — 1/21 .
Используя значения pˆ(¯c) и pˆ(a|¯c), можно подсчитать количество битов, тре-
буемых для передачи данной информации:
" #
I = − |
log2pˆi(esc|¯c) − |
log2pˆi(a|¯c) . |
(4.15) |
|
i |
i |
|
Вданном случае I = 34,47 + 149,83 = 185 битов (операция · — округление вверх).
Втакже широко применяемомалгоритме PPMD [2.41] используются следующие принципы оценки условных вероятностей появления символов алфавита источника и esc-символов:
pˆ(a ¯c) = |
Nn(¯c, a) − 1/2 |
, N |
(¯c, a) > 0, |
|||
| |
|
Nn(¯c) |
|
n |
(4.16) |
|
|
|
Mn(¯c) |
|
|
||
pˆ(esc|¯c) = |
|
|
|
|||
|
, |
Nn(¯c, a) = 0, |
||||
2Nn(¯c) |
||||||
где Mn(¯c) — число различных символов, появившихся в последовательности длины n вслед за контекстом ¯c.
Здесь также используется правило исключений (4.14), причем число различных символов Mn(¯c) также должно быть пересчитано с учетом правила исключений. Результаты работы алгоритма PPMD с параметром D = 8 по шагам приведены в табл. 4.11.
Таблица 4.11. Пример работы алгоритма PPMD
|
Интервал |
|
Контекст |
Число |
Число |
PPMD |
||
Шаг |
Символ |
¯c |
Nn(¯c) |
Mn(¯c) |
||||
|
|
|||||||
|
D = 8 |
|
|
|
|
|
|
|
|
|
|
|
|
pˆ(esc|¯c) |
pˆ(a|¯c) |
||
|
|
|
|
|
|
|||
1 |
|
н |
# |
0 |
0 |
1 |
1/256 |
|
2 |
н |
а |
# |
1 |
1 |
1/2 |
1/255 |
|
3 |
на |
_ |
# |
2 |
2 |
2/4 |
1/254 |
|
4 |
на_ |
д |
# |
3 |
3 |
3/6 |
1/253 |
|
5 |
на_д |
в |
# |
4 |
4 |
4/8 |
1/252 |
|
6 |
на_дв |
о |
# |
5 |
5 |
5/10 |
1/251 |
|
7 |
на_дво |
р |
# |
6 |
6 |
6/12 |
1/250 |
|
8 |
на_двор |
е |
# |
7 |
7 |
7/14 |
1/249 |
|
9 |
на_дворе |
_ |
# |
8 |
8 |
|
1/16 |
|
10 |
ф_дворе_ |
т |
_ |
1, 9 |
1, 8 |
1/2*7/16 |
1/248 |
|
11 |
_дворе_т |
р |
# |
10 |
9 |
|
1/20 |
|
12 |
дворе_тр |
а |
р |
1, 11 |
1, 9 |
1/2 |
1/20 |
|
13 |
воре_тра |
в |
а |
1, 12 |
1, 9 |
1/2 |
1/22 |
|
14 |
оре_трав |
а |
и |
1, 13 |
1, 9 |
1/2 |
3/24 |
|
15 |
ре_трава |
_ |
а |
2 |
2 |
|
1/4 |
|
16 |
е_трава_ |
н |
а_ |
1, 2, 15 |
1, 2 |
1/2*1/2 |
1/26 |
|
17 |
_трава_н |
а |
н |
1 |
1 |
|
1/2 |
|
18 |
трава_на |
_ |
на |
1 |
1 |
|
1/2 |
|
4.2. Виды статистического кодирования
Таблица 4.11 (окончание)
|
Интервал |
|
Контекст |
Число |
Число |
PPMD |
||
Шаг |
Символ |
¯c |
Nn(¯c) |
Mn(¯c) |
||||
|
|
|||||||
|
D = 8 |
|
|
|
|
|
|
|
|
|
|
|
|
pˆ(esc|¯c) |
pˆ(a|¯c) |
||
|
|
|
|
|
|
|||
19 |
рава_на_ |
т |
на_ |
1, 2, 3 |
1, 2, 3 |
1/2*1/2 |
1/2 |
|
20 |
ава_на_т |
р |
_т |
1 |
1 |
|
1/2 |
|
21 |
ва_на_тр |
а |
_тр |
1 |
1 |
|
1/2 |
|
22 |
а_на_тра |
в |
_тра |
1 |
1 |
|
1/2 |
|
23 |
_на_трав |
е |
_трав |
1, 1, 1, |
1, 1, 1, |
1/2*1 * |
1/40 |
|
1, 2, 22 |
1, 2, 9 |
*1 *1 * |
||||||
|
|
|
|
*1/2 |
|
|||
|
|
|
|
|
|
|
||
24 |
на_траве |
_ |
е |
1 |
1 |
|
1/2 |
|
25 |
а_траве_ |
д |
е_ |
1, 4 |
1, 3 |
1/2 |
1/6 |
|
26 |
_траве_д |
р |
_д |
1, 1, 25 |
1, 1, 9 |
1/2*1 |
5/48 |
|
27 |
_тра- |
о |
р |
3, 26 |
2, 9 |
2/6 |
1/48 |
|
ве_др |
||||||||
|
|
|
|
|
|
|
||
28 |
раве_дро |
в |
о |
1, 27 |
1, 9 |
1/2 |
5/52 |
|
29 |
аве_дров |
а |
в |
3 |
3 |
|
1/6 |
|
30 |
ве_дрова |
_ |
ва |
1 |
1 |
|
1/2 |
|
31 |
е_дрова_ |
н |
ва_ |
1 |
1 |
|
1/2 |
|
32 |
_дрова_н |
а |
ва_н |
1 |
1 |
|
1/2 |
|
33 |
дрова_на |
_ |
ва_на |
1 |
1 |
|
1/2 |
|
34 |
рова_на_ |
д |
ва_на_ |
1, 1, 1, |
1, 1, 1, |
1/2*1 *1 |
1/2 |
|
|
|
|
|
2 |
2 |
|
|
|
35 |
ова_на_д |
в |
на_д |
1 |
1 |
|
1/2 |
|
36 |
ва_на_дв |
о |
на_дв |
1 |
1 |
|
1/2 |
|
37 |
а_на_дво |
р |
на_дво |
1 |
1 |
|
1/2 |
|
38 |
_на_двор |
е |
на_двор |
1 |
1 |
|
1/2 |
|
39 |
на_дворе |
_ |
на_дворе |
1 |
1 |
|
1/2 |
|
40 |
а_дворе_ |
т |
а_дворе_ |
1 |
1 |
|
1/2 |
|
41 |
_дворе_т |
р |
_дворе_т |
1 |
1 |
|
1/2 |
|
42 |
дворе_тр |
а |
дворе_тр |
1 |
1 |
|
1/2 |
|
43 |
воре_тра |
в |
воре_тра |
1 |
1 |
|
1/2 |
|
44 |
оре_трав |
а |
оре_трав |
1 |
1 |
|
1/2 |
|
45 |
ре_трава |
_ |
ре_трава |
1 |
1 |
|
1/2 |
|
46 |
е_трава_ |
н |
е_трава_ |
1 |
1 |
|
1/2 |
|
47 |
_трава_н |
а |
_трава_н |
1 |
1 |
|
1/2 |
|
48 |
трава_на |
_ |
трава_на |
1 |
1 |
|
1/2 |
|
49 |
рава_на_ |
т |
рава_на_ |
1 |
1 |
|
1/2 |
|
50 |
ава_на_т |
р |
ава_на_т |
1 |
1 |
|
1/2 |
|
51 |
ва_на_тр |
а |
ва_на_тр |
1 |
1 |
|
1/2 |
|
52 |
а_на_тра |
в |
а_на_тра |
1 |
1 |
|
1/2 |
|
53 |
_на_трав |
е |
_на_трав |
1 |
1 |
|
1/2 |
|
54 |
на_траве |
_ |
на_траве |
1 |
1 |
|
1/2 |
|
55 |
а_траве_ |
д |
а_траве_ |
1 |
1 |
|
1/2 |
|
56 |
_траве_д |
р |
_траве_д |
1 |
1 |
|
1/2 |
|
57 |
траве_др |
о |
траве_др |
1 |
1 |
|
1/2 |
|
58 |
раве_дро |
в |
раве_дро |
1 |
1 |
|
1/2 |
|
59 |
аве_дров |
а |
аве_дров |
1 |
1 |
|
1/2 |
|
Рассчитанное с использованием соотношения (4.15) количество битов, требуемых для передачи данной информации, равно:
I = 23,78 + 158,32 = 183 бита.
Как следует из рассмотренных вариантов реализации метода РРМ, при их прак-
Глава 4. Статистическая избыточность дискретизированных данных
тической эффективности основным требованием является обеспечение хранения большого массива статистической информации, что вызывает необходимость использования значительного объема оперативной памяти.
Метод CTW (Context-Tree Weighting — взвешивание с использованием контекстных деревьев) [2.44–2.49] представляет собой одну из возможных альтернатив методу PPM, в этом методе оценка вероятности появления символа осуществляется с учетом весов контекстов, организованных в бинарное дерево.
Рассматриваются информационные источники, генерирующие двоичные последовательности длины N . Последовательность xN1 = x1x2 . . . xN генерируется с вероятностью pˆa(xN1 ). Для источника без памяти:
$N
pˆa(x1N ) = |
pˆa(xn), pˆa(1) = 1 − pˆa(0) = θ. |
(4.17) |
|
n=1 |
|
Параметр θ (вероятность генерации 1), лежит в диапазоне от 0 до 1. Если последовательность содержит a нулей и b единиц, то pˆa(xN1 ) = (1 − θ)a · θb.
Кумулятивная вероятность Qa(xN1 ), используемая для арифметического кодирования, определяется следующим образом:
N |
|
Qa(x1N ) = |
pˆa(x1x2...xn−10). |
x |
=1 |
n=1, n |
|
Рассмотрим оценку распределения вероятностей pˆe(xN1 ), сформулированную Кричевским и Трофимовым [2.60]. Распределение Кричевского–Трофимова (КТ-
распределение) определяется следующей условной вероятностью: |
|||||
pˆe(xn = 1|x1n−1) = |
b + 1/2 |
; pˆe(xn = 0|x1n−1) = 1 |
− pˆe(xn = 1|x1n−1) = |
a + 1/2 |
|
|
|
. |
|||
a + b + 1 |
a + b + 1 |
||||
|
|
|
(4.18) |
||
При этом оценка вероятности двоичной последовательности xN1 = x1x2 · · · xN связана условными вероятностями так:
pˆ |
(xN ) = pˆ (x ) |
· |
pˆ (x |
2| |
x ) |
· |
pˆ (x |
3| |
x2) |
· · · |
pˆ (x |
xN −1). |
(4.19) |
||
e |
1 |
e |
1 |
e |
1 |
e |
1 |
e N | |
1 |
|
|||||
Из этих соотношений нетрудно вывести выражения для оценочной вероятности последовательности из a нулей и b единиц:
pˆe(a, b) = |
[ 21 · 23 · · ·(a − 21 )] · [ 21 · 23 · · · (b − 21 )] |
. |
|
(4.20) |
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
При этом |
|
|
|
|
|
|
|
|
|
|
1 · 2 · · ·(a + b) |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
pˆe(a + 1, b) = |
a + 1/2 |
|
|
pˆe |
(a, b) и pˆe(a, b + 1) = |
|
b + 1/2 |
|
pˆe(a, b). |
(4.21) |
||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||
a + b + 1 |
a + b + 1 |
|||||||||||||||||||||||||||||||||||||||
Пример оценок вероятности и кумулятивной вероятности: |
|
|
|
|
|
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
1 |
|
|
1 |
|
|
3 |
|
5 |
|
|
|
3 |
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
||||
|
pˆe(01110) = |
|
|
|
· |
|
|
|
· |
|
|
|
· |
|
· |
|
|
|
|
= |
|
|
|
|
|
|
|
|
|
|
||||||||||
|
2 |
|
4 |
|
6 |
|
8 |
10 |
|
256 |
|
|
|
|
|
|
||||||||||||||||||||||||
(см. рис. 4.4а); |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
3 |
|
1 |
|
1 |
|
3 |
|
|
1 |
|
1 |
|
|
3 |
3 |
|
59 |
|
|
|||||||||||||||||
Qe(01110) = |
|
|
· |
|
|
+ |
|
|
· |
|
|
· |
|
|
+ |
|
|
|
· |
|
· |
|
· |
|
= |
|
|
. |
|
|||||||||||
2 |
4 |
2 |
4 |
6 |
2 |
|
4 |
6 |
8 |
128 |
|
|||||||||||||||||||||||||||||
4.2. Виды статистического кодирования
Построение контекстного дерева
Контекстное дерево состоит из узлов, соответствующих контекстам s вплоть до заданной глубины D (память источника не более D). Корень контекстного дерева соответствует пустому контексту. Каждый узел s в контекстном дереве связывается с подпоследовательностью символов источника, которые появляются после контекста s.
Требуется оценить взвешенную вероятность символов pˆsw в каждом узле контекстного дерева. Статистика источника неизвестна. Если источник не обладает памятью, то хорошей оценкой вероятности будет оценка по КТ-распределению. В противном случае необходимо расщепление последовательности на две подпоследовательности нулей — 0s и единиц — 1s, и хорошей оценкой вероятности будет служить произведение взвешенных вероятностей pˆ0ws и pˆ1ws. Вероятность в каждом узле контекстного дерева подсчитывается как взвешенная сумма этих двух вариантов:
pˆsw = [pˆe(as, bs) + pˆ0ws · pˆ1ws]/2,
где as, bs — количество нулей и единиц в контексте s.
Полученные таким образом вероятности используются для арифметического кодирования данных источника.
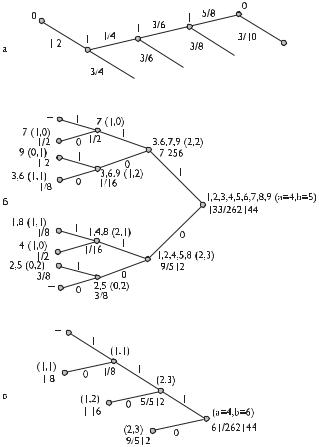
Например, предположим, что глубина контекста D = 3 и пусть источник данных породил последовательность 010011011 после последовательности . . . 110:
Источник данных |
. . . 110|010011011 |
Последовательность данных |
123456789 |
Пустому контексту соответствуют все символы от первого до девятого; символы 3, 6, 7, 9 имеют контекст «1»; контексту «0» соответствуют символы с номерами 1, 2, 4, 5, 8; контекст «11» имеет символ номер 7 и т. д. (см. табл. 4.12). На рис. 4.4б приведено соответствующее контекстное дерево.
Таблица 4.12. Пример расчета вероятностей для контекстного дерева в методе CTW
Контекст |
Номера символов |
Количество нулей и единиц (a, b) |
pˆ (a, b) |
pˆs |
|
|
|
e |
w |
Пустой |
1,2,3,4,5,6,7,8,9 |
(4,5) |
35/65536 |
133/262144 |
1 |
3,6,7,9 |
(2,2) |
3/128 |
7/256 |
|
|
|
|
|
0 |
1,2,4,5,8 |
(2,3) |
3/256 |
9/512 |
|
|
|
|
|
11 |
7 |
(1,0) |
1/2 |
|
01 |
3,6,9 |
(1,2) |
1/16 |
1/16 |
|
|
|
|
|
10 |
1,4,8 |
(2,1) |
1/16 |
1/16 |
|
|
|
|
|
00 |
2,5 |
(0,2) |
3/8 |
|
111 |
– |
– |
– |
|
|
|
|
|
|
011 |
7 |
(1,0) |
1/2 |
|
|
|
|
|
|
101 |
9 |
(0,1) |
1/2 |
|
001 |
3,6 |
(1,1) |
1/8 |
|
|
|
|
|
|
110 |
1,8 |
(1,1) |
1/8 |
|
|
|
|
|
|
010 |
4 |
(1,0) |
1/2 |
|
100 |
2,5 |
(0,2) |
3/8 |
|
|
|
|
|
|
000 |
– |
– |
– |
|
|
|
|
|
|
Глава 4. Статистическая избыточность дискретизированных данных
Рис. 4.4. К построению деревьев последовательностей при кодировании методом CTW: а) структура дерева при расчете оценки pˆe(01110); б) структура контекстного дерева для последовательности . . . 110|010011011; в) принцип обновления контекстного дерева при появлении следующего символа источника, равного «1»
Для каждого узла контекстного дерева подсчитывается количество нулей (a) и единиц (b), им соответствующих. Например, узлу с контекстом «1» соответствуют символы с номерами 3, 6, 7, 9, среди которых два нуля и две единицы.
Далее для каждого узла контекстного дерева рекурсивно рассчитываются вероятности. Расчет начинается с конечных веток и идет по направлению к корню. Вероятность в конечных ветках рассчитывается как pˆe(a, b), а для остальных узлов используется формула взвешенной вероятности pˆsw. В табл. 4.12 приведены соответствия символов (по номерам от 1 до 9) возможным контекстам.
Алгоритм обновления контекстного дерева при появлении следующего символа рассмотрим на том же примере (110|010011011). Пусть следующий, десятый, символ источника — «1». Тогда нужно:
–увеличить bs;
–обновить значение pˆe(as, bs);
4.2. Виды статистического кодирования
–обновить pˆsw для всех контекстов вплоть до глубины D = 3: {011, 11, 1, пустой}.
Структура обновления контекстного дерева приведена на рис. 4.4в.
Метод DMC (Dynamic Markov Compression — динамическая марковская компрессия) значительно отличается от двух предыдущих методов. Он связан с теорией конечных автоматов и использует моделирование с конечным числом состояний [2.50, 2.51]. Благодаря простоте этот метод обладает высокой производительностью, но невысокой эффективностью при обработке последовательности достаточно сложных символов, используемых для описания большинства реальных информационных источников.
По этой причине чаще всего метод DMC используется при побитовом вводе информации, поскольку при этом нет проблем следующего состояния и существуют только два перехода от одного состояния в другое.
Марковская модель является таким источником информации, при котором
вкаждом состоянии она помнит только об одном предыдущем своем состоянии.
Вкачестве примера представим марковскую модель, при которой источник информации порождает последовательность двоичных чисел [2.61, 2.62]:
–за 0 следует 0 с вероятностью 3/4;
–за 0 следует 1 с вероятностью 1/4;
–за 1 следует 0 с вероятностью 1/3;
–за 1 следует 1 с вероятностью 2/3.
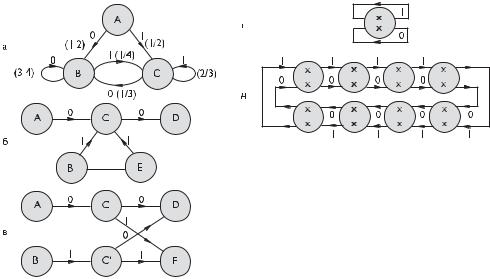
При этом первая цифра может быть «0» или «1» равновероятно (1/2). Эта модель может быть описана с помощью ориентированного графа, каждой дуге которого приписываются соответствующие вероятности перехода (см. рис. 4.5а).
По мере поступления информации марковская модель переходит из одного своего состояния в другое в соответствии с ранее прочитанными символами. Если завести счетчики переходов по каждой дуге, то можно получить оценки вероятностей переходов. Если переход из состояния A по дуге для символа «0» проходил N0 раз, а по дуге для «1» — N1, то оценки условных вероятностей переходов таковы:
pˆ(0|из состояния A) = |
N0 |
|
pˆ(1|из состояния A) = |
|
N1 |
|
||
|
; |
|
|
. |
|
|||
N0 + N1 |
N0 |
+ N1 |
|
|||||
При адаптивном кодировании заранее определить значения N0 и N1 невозможно, |
||||||||
и эти оценки могут быть определены так: |
|
|
|
|
||||
pˆ(0|из состояния A) = |
N0 + c |
; |
pˆ(1|из состояния A) = |
|
N1 + c |
, |
||
N0 + N1 + 2c |
N0 |
+ N1 + 2c |
||||||
где c — положительная константа.
Для файлов большого размера (намного больше значения c) выбор конкретного значения c существенной роли не играет. Для файлов малого размера при малом значении c модель быстрее оценит характеристики источника, однако при этом увеличивается вероятность неправильного прогноза, что является типичной проблемой адаптивных алгоритмов. Алгоритм динамической реализации диаграммы состояний поясняется на примере уже построенной модели, содержащей состояния A, B, С, D и E (рис. 4.5б).
Глава 4. Статистическая избыточность дискретизированных данных
Рис. 4.5. Марковская модель источника информации: а) ориентированный граф источника заданной модели последовательности; б) исходная модель динамической реализации диаграммы состояний; в) измененная модель с разделением состояния С на две части; г) начальная модель с одним состоянием; д) начальная модель, представляющая 8-битовые последовательности
Из диаграммы следует, что в состояние C ведут две дуги из A и B; из состояния С также выходят две дуги — в D и E.
Всякий раз, когда модель переходит в состояние C, теряется информация о контексте, т. е. неясно откуда пришли в это состояние — из A или B. Однако вполне может быть, что выбор следующего состояния (D или E) зависит от предыдущего состояния (A или B). Чтобы учесть эту зависимость, например в случае, когда переход из состояния А в С имеет большую частоту, чем переход из В в С, состояние C обычно разделяют на две части (С и С’).
Измененная модель приведена на рис. 4.5в. Значения счетчиков переходов из C в D или E делится между счетчиками C и C в новой модели пропорционально числу переходов из A в C и из B в C для старой модели. Следовательно, новая модель отражает степень зависимости между состояниями A, B и D, E. При этом выбор следующего состояния (D или E) не зависит от предыдущего состояния (A или B), но зависит от непосредственного предшественника A или B. В этом случае производится дополнительное деление состояний A, C и B, C. Следовательно, модель теперь будет учитывать эти зависимости. Процесс деления необходимо производить только в том случае, когда существует уверенность в наличии соответствующих зависимостей, иначе информация о контексте будет потеряна.
Поэтому желательно, чтобы деление состояния C проходило тогда, когда оба счетчика переходов A–C и B–C достаточно велики. Чем больше применяется делений состояний, тем больше увеличиваются зависимости, используемые моделью для прогноза.
4.2. Виды статистического кодирования
Для полного определения метода динамического сжатия Маркова необходимо определить начальную модель, которая затем будет изменяться в соответствии со спецификой поступающей информации. Простейшим случаем является модель с одним состоянием, приведенная на рис. 4.5г.
Несколько лучшее сжатие может быть достигнуто при побайтовом вводе информации при использовании начальной модели, представляющей 8-битовые последовательности в виде цепи, приведенной на рис. 4.5д. Впрочем, начальная модель не является особо решающей, поскольку DMC быстро приспосабливается к требованиям кодируемой информации.
Для оценки вероятностей появления символов на выходе информационного источника применяется искусственная нейронная сеть [2.52, 2.53].
Чаще всего используется многослойная нейронная сеть, обладающая одним нейроном выходного слоя на каждый символ информационного алфавита. На выходах этих нейронов формируются сигналы, определяющие вероятности появления различных символов в текущем контексте.
Преимуществом данного решения энтропийного кодирования является возможность адаптации системы к обрабатываемой информации с применением фиксированного объема памяти. Этот метод обладает высокой эффективностью, но очень низкой производительностью.
4.2.8. Контекстные методы энтропийного кодирования
Эта группа контекстных методов включает два алгоритма, которые рассматривают зависимости между последовательностью символов, предшествующих кодируемому (левосторонний контекст) и последовательность символов, следующих за кодируемым (правосторонний контекст). Первый из этих двух методов называется ассоциативным кодированием Буяновского (ACB) [2.54] и относится к поточным методам, т. е. он может применяться для кодирования данных, непрерывно порождаемых источником. Второй метод [2.55] основан на использовании преобразования Барроуза–Уиллера, он может применяться, если доступен весь объем кодируемой информации. Это самые современные методы, которые пока не получили заметного распространения из-за значительной сложности реализации, но имеют большие перспективы.
Ассоциативное кодирование Буяновского (ACB)
Алгоритм кодирования Буяновского поясняется на примере обработки битовой последовательности.
Предположим, что уже закодирована последовательность
.. . 111101011100001010010001010100101110
ипредстоит закодировать строку 0100010111. . . , обозначенную далее как «пакуемая строка». Закодированная последовательность представляет предысторию, пакуемая строка — постисторию:
. . . 111101011100001010010001010100101110|0100010111.. . (4.22)
Выпишем все подпоследовательности из предыстории, которые совпадают с первым и более начальными битами предыстории (отсчет битов ведется справа
Глава 4. Статистическая избыточность дискретизированных данных
налево, в данном случае первый бит равен «0»):
. . . 11110|1011100001010010001010100101110
. . . 1111010|11100001010010001010100101110
. . . 11110101110|0001010010001010100101110
. . . 111101011100|001010010001010100101110
. . . 1111010111000|01010010001010100101110
. . . 11110101110000|1010010001010100101110
. . . 1111010111000010|10010001010100101110
. . . 111101011100001010|010001010100101110
. . . 1111010111000010100|10001010100101110
. . . 111101011100001010010|001010100101110
. . . 1111010111000010100100|01010100101110
. . . 11110101110000101001000|1010100101110
. . . 1111010111000010100100010|10100101110
. . . 111101011100001010010001010|100101110
. . . 11110101110000101001000101010|0101110
. . . 111101011100001010010001010100|101110
. . . 11110101110000101001000101010010|1110
. . . 111101011100001010010001010100101110|0100010111.. .
Последней выделена строка (4.22), содержащая предысторию и постисторию, которую необходимо закодировать. Заметим, что все строки в этом списке, кроме последней доступны на декодировании, а у последней строки известна предыстория.
Максимальная длина предыстории ограничивается некоторым числом N . Полученные последовательности упорядочиваются по возрастанию лексикографического порядка предыстории. При этом анализируется последовательность символов справа налево начиная от символа «|». То есть последовательность . . . 110000| лексикографически меньше последовательности . . . 001000|. Слева проставлен номер строки. Пакуемой строке (с ее предысторией) присваивается номер 0, от нее номера вверх возрастают, а вниз убывают:
15 |
. . . 11110101110000| |
1010010001010100101110 |
14 |
. . . 11110101110000101001000| |
1010100101110 |
13 |
. . . 1111010111000| |
01010010001010100101110 |
12 |
. . . 1111010111000010100100| |
01010100101110 |
11 |
. . . 1111010111000010100| |
10001010100101110 |
10 |
11101011100001010010001010100| |
101110 |
9 |
. . . 111101011100| |
001010010001010100101110 |
8 |
. . . 1111010111000010| |
10010001010100101110 |
7 |
. . . 1111010111000010100100010| |
10100101110 |
6 |
. . . 111101011100001010010| |
001010100101110 |
5 |
. . . 11110101110000101001000101010010| |
1110 |
4 |
. . . 111101011100001010| |
010001010100101110 |
3 |
. . . 111101011100001010010001010| |
100101110 |
2 |
. . . 11110101110000101001000101010| |
0101110 |
1 |
. . . 1111010| |
11100001010010001010100101110 |
0 |
. . . 111101011100001010010001010100101110| |
0100010111. . . |
−1 |
. . . 11110101110| |
0001010010001010100101110 |
−2 |
. . . 11110| |
1011100001010010001010100101110 |
Этот список называют левосторонним ассоциативным списком, или «воронкой аналогий» в терминологии автора алгоритма.
4.2. Виды статистического кодирования
Затем этот список переупорядочивается в лексикографическом порядке постистории (в противоположном направлении — слева направо после «|», т. е. последовательность |110000. . . лексикографическибольшепоследовательности |001000. . . ):
−1 |
. . . 11110101110| |
0001010010001010100101110 |
9 |
. . . 111101011100| |
001010010001010100101110 |
6 |
. . . 111101011100001010010| |
001010100101110 |
4 |
. . . 111101011100001010| |
010001010100101110 |
0 |
..111101011100001010010001010100101110| |
0100010111.. |
13 |
. . . 1111010111000| |
01010010001010100101110 |
12 |
. . . 1111010111000010100100| |
01010100101110 |
2 |
. . . 11110101110000101001000101010| |
0101110 |
11 |
. . . 1111010111000010100| |
10001010100101110 |
8 |
. . . 1111010111000010| |
10010001010100101110 |
3 |
. . . 111101011100001010010001010| |
100101110 |
15 |
. . . 11110101110000| |
1010010001010100101110 |
7 |
. . . 1111010111000010100100010| |
10100101110 |
14 |
. . . 11110101110000101001000| |
1010100101110 |
10 |
11101011100001010010001010100| |
101110 |
−2 |
. . . 11110| |
1011100001010010001010100101110 |
1 |
. . . 1111010| |
11100001010010001010100101110 |
5 |
. . . 11110101110000101001000101010010| |
1110 |
В дальнейшем используются только две строки, примыкающие к пакуемой строке:
4 |
. . . 111101011100001010| |
010001010100101110 |
0 |
. . . 111101011100001010010001010100101110| |
0100010111. . . |
13 |
. . . 1111010111000| |
01010010001010100101110 |
Код пакуемой строки состоит из трех частей.
Номер строки, максимально совпадающей с пакуемой строкой. В данном случае — 4. Этот номер кодируется любым эффективным префиксным или арифметическим кодом. В качестве эквивалента вероятности автор алгоритма предложил использовать длину совпадения строки предыстории пакуемой строки со строками предысторий из рассмотренного списка с соответствующей нормировкой. В данном случае:
Номер строки |
Длина совпадения |
Эквивалент вероятности |
−2 |
4 |
4/(34+C) |
−1 |
7 |
7/(34+C) |
0 |
– |
C/(34+C) |
1 |
2 |
2/(34+C) |
2 |
2 |
2/(34+C) |
3 |
2 |
2/(34+C) |
4 |
2 |
2/(34+C) |
5 |
2 |
2/(34+C) |
6 |
2 |
2/(34+C) |
7 |
2 |
2/(34+C) |
8 |
2 |
2/(34+C) |
9 |
1 |
1/(34+C) |
10 |
1 |
1/(34+C) |
11 |
1 |
1/(34+C) |
12 |
1 |
1/(34+C) |
13 |
1 |
1/(34+C) |
14 |
1 |
1/(34+C) |
15 |
1 |
1/(34+C) |