

(по цифровому вещанию) Dvorkovich_V_Cifrovye_videoinformacionnye_sistemy
.pdfГлава 4. Статистическая избыточность дискретизированных данных
f2 = 2; fi = fi−1 ). Поэтому можно построить код числа как последовательность битов, каждый из которых указывает на факт наличия в n определенного числа Фибоначчи.
Очевидно, если в разложении числа n присутствует fi, то в этом разложении не может быть числа fi+1. Поэтому логично для конца кода использовать дополнительную единицу. Тогда две идущие подряд единицы будут означать окончание кодирования текущего числа. Примеры кодов Фибоначчи приведены в табл. 4.4. В кодах Фибоначчи все биты, кроме двух последних, являются мантиссами.
Таблица 4.4. Коды Фибоначчи
n\fi |
1 |
2 |
3 |
5 |
8 |
13 |
21 |
34 |
55 |
1 |
1 |
(1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
0 |
1 |
(1) |
|
|
|
|
|
|
3 |
0 |
0 |
1 |
(1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4 |
1 |
0 |
1 |
(1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5 |
0 |
0 |
0 |
1 |
(1) |
|
|
|
|
6 |
1 |
0 |
0 |
1 |
(1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
7 |
0 |
1 |
0 |
1 |
(1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8 |
0 |
0 |
0 |
0 |
1 |
(1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
12 |
1 |
0 |
1 |
0 |
1 |
(1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
13 |
0 |
0 |
0 |
0 |
0 |
1 |
(1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
20 |
0 |
1 |
0 |
1 |
0 |
1 |
(1) |
|
|
|
|
|
|
|
|
|
|
|
|
21 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
(1) |
|
|
|
|
|
|
|
|
|
|
|
33 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
(1) |
|
|
|
|
|
|
|
|
|
|
|
34 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
(1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
54 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
(1) |
|
|
|
|
|
|
|
|
|
|
4.2.2. Алгоритм Шеннона–Фано
Первый известный метод эффективного кодирования символов известен как кодирование Шеннона–Фано [2.2, 2.12, 2.56]. Он основан на знании вероятности каждого символа, присутствующего в сообщении. Зная эти вероятности, строят таблицу кодов, обладающую следующими свойствами:
–различные коды имеют различное количество битов;
–коды символов, обладающих меньшей вероятностью, имеют больше битов, чем коды символов с большей вероятностью;
–хотя коды имеют различную битовую длину, они могут быть декодированы единственным образом.
Алгоритм основан на рекурсивной процедуре формирования системы префиксных кодов при известном распределении вероятностей появления символов на выходе источника информации.
Все символы информационного алфавита сортируются, например, по убыванию вероятностей их появления. После этого упорядоченный ряд символов разбивается на две части таким образом, чтобы суммы вероятностей появления символов, отнесенных к каждой части, были бы примерно равны. Очевидно, что
4.2. Виды статистического кодирования
при этом количество символов в первой части будет меньше, чем во второй части, поскольку вероятности появления каждого из символов первой части больше (или только части символов) равны вероятностям появления каждого из символов во второй части. Символам первой части присваивается начальный код «0», а символам второй части — «1».
Затем каждая из двух выделенных частей, если она содержит более одного символа, вновь разбивается на две части аналогичным образом. Разделенным на две составляющие первой части присваиваются коды соответственно «00» и «01», а второй части — «10» и «11». Такие операции производятся до тех пор, пока в рядах останется лишь по одному символу. Можно убедиться в том, что длина кода символа bi с вероятностью появления P (bi), полученного с применением алгоритма Шеннона–Фано, отличается от оптимального значения − log2 P (bi) менее чем на 1 бит.
Этот алгоритм незначительно уступает по эффективности оптимальному алгоритму Хаффмана префиксного кодирования.
4.2.3. Алгоритм Хаффмана
Алгоритм Хаффмана [2.4, 2.13, 2.56], основанный на элегантной и простой процедуре построения дерева вероятностей, является самым распространенным алгоритмом генерации кода переменной длины.
При реализации этого алгоритма средняя длина кодовых слов ˆ находится
L
в диапазоне:
ˆ |
ˆ |
H(B) L H(B) + 1 |
бит/отсчет и L 1 бит/отсчет, |
т. е. средняя длина слов не более чем на 1 бит/отсчет больше энтропии, но не менее 1 бит/отсчет (в предельном случае, когда энтропия равна нулю).
Принцип построения дерева вероятностей можно достаточно просто пояснить на конкретном примере.
Пусть для передачи изображения используется 8 уровней квантования, распределение которых определяется гистограммой со следующими данными:
P (b0) = P (b5) = P (b6) = P (b7) = 0,06; P (b1) = 0,23;
P (b2) = 0,30; P (b3) = 0,15; P (b4) = 0,08.
Дерево строится справа налево следующим образом (рис. 4.2, верхняя диаграмма):
–в секции I уровни пикселов сортируются по вероятности от наибольшей к наименьшей сверху вниз; при равенстве P (bi) = P (bj ) выше ставится уровень bi < bj ;
–в секции II две самые нижние ветви объединяются в узел, их вероятности складываются, и узел образует новую ветвь; общее количество ветвей уменьшается на одну и они вновь сортируются по вероятности от наибольшей к наименьшей;
–в секциях III и IV и т. д. производятся операции, аналогичные проводимым в секции II, до тех пор пока не останется одна ветвь с вероятностью, равной 1.
Все это дерево можно перестроить (рис. 4.2, нижняя диаграмма), убрав пересечения.

Глава 4. Статистическая избыточность дискретизированных данных
Рис. 4.2. Принцип построения алгоритма хаффмановского кодирования |
Кодирование осуществляется движением слева направо по дереву к каждому кодируемому уровню bi. При этом на каждом узле коду приписывается, например, двоичный «0», если осуществляется шаг вверх и «1», если осуществляется шаг вниз.
Таким образом, для данного случая наиболее вероятные значения b1 и b2 кодируются двухбитовым кодом, величины b3 и b4 — трехбитовым кодом, а наименее вероятные значения b0, b5, b6 и b7 — четырехбитовым кодом (на рис. 4.2, нижняя диаграмма, коды указаны справа).
Нетрудно понять, что эти коды легко различимы:
–если второй бит кода является двоичным нулем, то код — двухбитовый,
впротивном случае количество битов в коде более двух;
–если третий бит кода является двоичным нулем, то код — трехбитовый,
впротивном случае количество битов в коде равно четырем.
Приемник декодирует информацию, используя то же самое дерево, двигаясь вверх при получении «0» и вниз при получении «1». Средняя битовая скорость
в данном случае ˆ бит/пиксел при энтропии бит/пиксел (т. е. ˆ
L = 2,71 H = 2,68 L
практически совпадает с H).
Используются неадаптивный и адаптивный варианты хаффмановского кодирования. В первом случае перед передачей сообщения передается таблица вероятностей, если она заранее неизвестна на приемной стороне. При адаптивном варианте кодирования таблица вероятностей вычисляется как на передающей, так и на приемной стороне по мере поступления данных. При этом до начала кодирования исходно предполагается, например, равновероятное распределение уровней пикселов. Рассмотренный выше пример показывает высокую эффективность хаффмановской процедуры при относительно равномерном распределении уровней пикселов.
4.2. Виды статистического кодирования
Однако когда энтропия сообщения становится существенно меньше единицы, эффективность хаффмановского кодирования резко снижается, поскольку дей-
ствует упомянутое выше ограничение снизу ˆ бит/отсчет.
L 1
По этой причине при использовании, например, восьмибитовой исходной информации об изображении, хаффмановское кодирование не позволит сжать информацию более восьми раз. В связи с этим применяются различные модификации неравномерного кодирования, позволяющие обеспечить более эффективное сокращение объема передаваемой информации.
Модификация алгоритма Хаффмана с фиксированной таблицей (CCITT, Group 3) [2.63] используется при сжатии черно-белых изображений (один бит на пиксел). Данный алгоритм был предложен третьей группой по стандартизации Международного консультационного комитета по телеграфии и телефонии (Consultative Committee International Telegraph and Telephone). Последовательности подряд идущих черных и белых точек в нем заменяются числом, равным их количеству. А этот ряд, в свою очередь, сжимается, по Хаффману, с фиксированной таблицей.
Ниже приведены два вида кодов соответственно:
–коды серий — от 0 до 63 с шагом 1 (табл. 4.5);
–дополнительные коды — от 64 до 2560 с шагом 64 (табл. 4.6).
Таблица 4.5. Таблица кодов серий длиной от 0 до 63 (CCITT, Group 3)
Длина |
Код белой |
Код черной |
|
Длина |
Код белой |
Код черной |
серии |
серии |
серии |
|
серии |
серии |
серии |
|
|
|
|
|
|
|
0 |
00110101 |
0000110111 |
|
32 |
00011011 |
000001101010 |
|
|
|
|
|
|
|
1 |
00111 |
010 |
|
33 |
00010010 |
000001101011 |
|
|
|
|
|
|
|
2 |
0111 |
11 |
|
34 |
00010011 |
000011010010 |
3 |
1000 |
10 |
|
35 |
00010100 |
000011010011 |
|
|
|
|
|
|
|
4 |
1011 |
011 |
|
36 |
00010101 |
000011010100 |
|
|
|
|
|
|
|
5 |
1100 |
0011 |
|
37 |
00010110 |
000011010101 |
6 |
1110 |
0010 |
|
38 |
00010111 |
000011010110 |
|
|
|
|
|
|
|
7 |
1111 |
00011 |
|
39 |
00101000 |
000011010111 |
|
|
|
|
|
|
|
8 |
10011 |
000101 |
|
40 |
00101001 |
000001101100 |
9 |
10100 |
000100 |
|
41 |
00101010 |
000001101101 |
|
|
|
|
|
|
|
10 |
00111 |
0000100 |
|
42 |
00101011 |
000011011010 |
|
|
|
|
|
|
|
11 |
01000 |
0000101 |
|
43 |
00101100 |
000011011011 |
12 |
001000 |
0000111 |
|
44 |
00101101 |
000001010100 |
|
|
|
|
|
|
|
13 |
000011 |
00000100 |
|
45 |
00000100 |
000001010101 |
|
|
|
|
|
|
|
14 |
110100 |
00000111 |
|
46 |
00000101 |
000001010110 |
15 |
110101 |
000011000 |
|
47 |
00001010 |
000001010111 |
|
|
|
|
|
|
|
16 |
101010 |
0000010111 |
|
48 |
00001011 |
000001100100 |
|
|
|
|
|
|
|
17 |
101011 |
0000011000 |
|
49 |
01010010 |
000001100101 |
18 |
0100111 |
0000001000 |
|
50 |
01010011 |
000001010010 |
|
|
|
|
|
|
|
19 |
0001100 |
00001100111 |
|
51 |
01010100 |
000001010011 |
|
|
|
|
|
|
|
20 |
0001000 |
00001101000 |
|
52 |
01010101 |
000000100100 |
21 |
0010111 |
00001101100 |
|
53 |
00100100 |
000000110111 |
|
|
|
|
|
|
|
22 |
0000011 |
00000110111 |
|
54 |
00100101 |
000000111000 |
|
|
|
|
|
|
|
Глава 4. Статистическая избыточность дискретизированных данных
Таблица 4.5 (окончание)
|
Длина |
Код белой |
|
Код черной |
|
|
Длина |
Код белой |
|
Код черной |
|
||||
|
серии |
серии |
|
серии |
|
|
серии |
серии |
|
серии |
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
23 |
|
0000100 |
|
|
00000101000 |
|
|
|
55 |
|
01011000 |
000000100111 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
24 |
|
0101000 |
|
|
00000010111 |
|
|
|
56 |
|
01011001 |
000000101000 |
|
|
|
25 |
|
0101011 |
|
|
00000011000 |
|
|
|
57 |
|
01011010 |
000001011000 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
26 |
|
0010011 |
|
|
000011001010 |
|
|
|
58 |
|
01011011 |
000001011001 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
27 |
|
0100100 |
|
|
000011001011 |
|
|
|
59 |
|
01001010 |
000000101011 |
|
|
|
28 |
|
0011000 |
|
|
000011001100 |
|
|
|
60 |
|
01001011 |
000000101100 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
29 |
|
00000010 |
|
|
000011001101 |
|
|
|
61 |
|
00110010 |
000001011010 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
30 |
|
00000011 |
|
|
000001101000 |
|
|
|
62 |
|
00110011 |
000001100110 |
|
|
|
31 |
|
00011010 |
|
|
000001101001 |
|
|
|
63 |
|
00110100 |
000001100111 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 4.6. Таблица кодов серий длиной от 0 до 63 (CCITT, Group 3) |
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Длина |
|
Код белой |
|
|
Код черной |
|
|
|
Длина |
|
Код белой |
|
Код черной |
|
|
серии |
|
серии |
|
|
серии |
|
|
|
серии |
|
серии |
|
серии |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
64 |
|
11011 |
|
0000001111 |
|
|
1344 |
|
011011010 |
|
0000001010011 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
128 |
|
10010 |
|
000011001000 |
|
|
1408 |
|
011011011 |
|
0000001010100 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
192 |
|
01011 |
|
000011001001 |
|
|
1472 |
|
010011000 |
|
0000001010101 |
|||
|
256 |
|
0110111 |
|
000001011011 |
|
|
1536 |
|
010011001 |
|
0000001011010 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
320 |
|
00110110 |
|
000000110011 |
|
|
1600 |
|
010011010 |
|
0000001011011 |
|||
|
384 |
|
00110111 |
|
000000110100 |
|
|
1664 |
|
011000 |
|
0000001100100 |
|||
|
448 |
|
01100100 |
|
000000110101 |
|
|
1728 |
|
010011011 |
|
0000001100101 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
512 |
|
01100101 |
|
0000001101100 |
|
|
1792 |
|
00000001000 |
|
совп. с белой |
|||
|
576 |
|
01101000 |
|
0000001101101 |
|
|
1856 |
|
00000001100 |
|
— // — |
|||
|
640 |
|
01100111 |
|
0000001001010 |
|
|
1920 |
|
00000001101 |
|
— // — |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
704 |
|
011001100 |
|
0000001001011 |
|
|
1984 |
|
000000010010 |
|
— // — |
|||
|
768 |
|
011001101 |
|
0000001001100 |
|
|
2048 |
|
000000010011 |
|
— // — |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
832 |
|
011010010 |
|
0000001001101 |
|
|
2112 |
|
000000010100 |
|
— // — |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
896 |
|
011010011 |
|
0000001110010 |
|
|
2176 |
|
000000010101 |
|
— // — |
|||
|
960 |
|
011010100 |
|
0000001110011 |
|
|
2240 |
|
000000010110 |
|
— // — |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
1024 |
|
011010101 |
|
0000001110100 |
|
|
2304 |
|
000000010111 |
|
— // — |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
1088 |
|
011010110 |
|
0000001110101 |
|
|
2368 |
|
000000011100 |
|
— // — |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
1152 |
|
011010111 |
|
0000001110110 |
|
|
2432 |
|
000000011101 |
|
— // — |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
1216 |
|
011011000 |
|
0000001110111 |
|
|
2496 |
|
000000011110 |
|
— // — |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
1280 |
|
011011001 |
|
0000001010010 |
|
|
2560 |
|
000000011111 |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Каждая строка изображения сжимается независимо. Считается, что в изображениях существенно преобладает белый цвет, и все строки изображения начинаются с белой точки. Если строка начинается с черной точки, то считается, что строка начинается белой серией с длиной 0. На практике в тех случаях, когда в изображении преобладает черный цвет, изображение инвертируется перед компрессией и записывается эта информация в заголовке файла.
Близким к Хаффмановскому является алгоритм JBIG, разработанный группой экспертов ISO (Joint Bi-level Experts Group) специально для сжатия однобитных черно-белых изображений, например, факсов или отсканированных

4.2. Виды статистического кодирования
документов [2.64]. В принципе он может применяться и к 2-, и к 4-битовым картинкам. При этом алгоритм разбивает их на отдельные битовые плоскости. JBIG позволяет управлять такими параметрами, как порядок разбиения изображения на битовые плоскости, ширина полос в изображении, уровни масштабирования. Последняя возможность позволяет легко ориентироваться в базе больших по размерам изображений, просматривая сначала их уменьшенные копии. Распаковываться изображение на экране будет постепенно, как бы медленно «проявляясь».
Как и алгоритм Хаффмана, JBIG использует для чаще появляющихся символов короткие цепочки, а для реже появляющихся — длинные.
4.2.4. Блочное и условное кодирование
Дальнейшее снижение битового потока возможно, если использовать блочное кодирование [2.4], т. е. если кодировать и передавать информацию блоками из N отсчетов, которые можно представить как компоненты вектора:
b = (b1, b2, . . . , bN ).
При квантовании этих компонент K уровнями имеем 2N K возможных значений случайного вектора B, чьи возможные значения b имеют распределение вероят-
ностей {P (b)}. Энтропия N -го порядка (блочная энтропия) определяется как
H(B) = − P (b) · log2 P (b), |
(4.3) |
b
где сумма берется по всем 2N K возможным значениям.
Очевидно, что энтропия вектора H(B) связана с энтропией каждой его компоненты H(B) соотношением
N1 H(B) H(B),
причем равенство достигается лишь в том случае, когда все компоненты вектора (пикселы) статистически независимы.
|
хаффмановские коды для |
{ |
b в соответствии с распределением ве- |
||||||||||||||||
Построим |
|
|
|
(всего 2 |
N K |
|
|
} |
|
|
|
|
|
|
|
||||
роятностей {P (b)} |
|
кодовых слов). При этом если среднюю длину |
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ˆ |
|
|
|
кодового слова, определяющего вектор B, обозначить LN , то средняя длина ко- |
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
ˆ |
|
1 |
ˆ |
|
|
|
|
дового слова, определяющего его компоненту, L = |
N |
LN , может быть ограничена |
|||||||||||||||||
следующим соотношением: |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
1 |
|
|
1 |
ˆ |
ˆ |
1 |
|
|
1 |
|
|
1 |
|
(4.4) |
||||
|
|
N |
H(B) |
N |
LN |
= L |
N |
H(B) + |
N |
H(B) + |
N |
. |
|||||||
Таким образом, при достаточно больших N возможно (хотя и не всегда практично из-за большого объема вычислений) кодировать поблочно и получать битовый поток, максимально отличающийся от энтропии первого порядка H(B) на малую величину N1 .
Существенным недостатком блочного кодирования является необходимость создания таблицы кодирования (или дерева), содержащей 2N K кодовых слов. При этом часто получаются весьма длинные коды.
Эта проблема частично преодолевается при так называемом условном кодировании [2.4], когда кодируется компонента bN при условии, что компоненты b1, b2, . . . , bN −1 уже переданы и известны приемнику. В этом случае коды Хаффмана для bN можно построить на основе условной вероятности {P (bN | b1, b2, . . . , bN −1)}.

Глава 4. Статистическая избыточность дискретизированных данных
Очевидно, что такой код будет иметь 2N слов, и средняя длина слов в битах
будет не более чем на 1 бит отличаться от условной энтропии:
H(BN |b1, . . . , bN −1 ) = − P (bN |b1,. . . ,bN −1 ) · log2 P (bN |b1,. . . ,bN −1 ). (4.5)
bN
Если такой код построен для всех возможных (N − 1)-мерных значений, то получается 2(N −1)K кодов, каждый из которых имеет 2K кодовых слов.
Результирующая условная энтропия может быть получена усреднением по всем (N − 1)-мерным векторам:
H(BN |B1, . . . , BN −1 ) = − |
P (bN |b1, . . . , bN −1 ) · H(BN |b1, . . . ,bN −1 ) = |
||
|
b1...bN −1 |
b |
|
|
= − |
P (b) · log2 P (bN |b1, . . . ,bN −1 ). (4.6) |
|
ˆ |
|
|
При этом средняя длина потока битов Lc оценивается с точностью 1 бит/отсчет: |
||
ˆ |
, . . . , BN −1 ) + 1 |
ˆ |
H(BN |B1, . . . , BN −1 ) Lc H(BN |B1 |
бит, но Lc 1. (4.7) |
|
Эффективность условного кодирования связана с тем, что при значительной зависимости между отсчетами условная энтропия всегда меньше отнесенной на отсчет блоковой энтропии, т. е.
1 |
|
H(BN |B1, . . . , BN −1 ) N H(B). |
(4.8) |
Однако в связи с тем, что ˆc оценена снизу битом на отсчет, условное кодирование
L
неэффективно при значениях условной энтропии, меньшей единицы.
Поэтому более эффективным является так называемое условное блочное кодирование, сочетающее преимущества двух модификаций кодирования.
К методам блочного кодирования можно отнести алгоритм группового кодирования RLE (Run Length Encoding) [2.6, 2.9], который позволяет сжимать данные любых типов независимо от содержащейся в них информации. Сама информация влияет лишь на коэффициент сжатия. Он является самым быстрым и простым алгоритмом компрессии и при этом иногда оказывается весьма эффективным.
В основу алгоритма RLE положен принцип выявления повторяющихся последовательностей данных и замены их простой структурой, в которой указывается код данных и коэффициент повтора. Он оперирует группами данных — последовательностями, в которых один и тот же символ встречается несколько раз подряд. Суть его заключается в том, что при кодировании строка повторяющихся символов, составляющих группу, заменяется строкой, которая содержит сам повторяющийся символ (значение группы) и количество его повторов (счетчик группы).
Программные реализации алгоритма RLE отличаются простотой, высокой скоростью работы, но в среднем обеспечивают недостаточное сжатие. Наилучшими объектами для данного алгоритма являются графические файлы, в которых большие одноцветные участки изображения кодируются длинными последовательностями одинаковых байтов. Этот метод также может давать заметный выигрыш на некоторых типах файлов баз данных, имеющих таблицы с фик-
4.2. Виды статистического кодирования
сированной длиной полей. Для текстовых данных методы RLE, как правило, неэффективны.
Из специфики работы алгоритма можно легко понять, для каких изображений коэффициент сжатия будет максимальным. Это изображения, содержащие минимальное количество цветов, без плавных переходов (с резкими границами) и с большими участками, заполненными одним цветом. Так как сканирование данных осуществляется построчно слева на право, высокий коэффициент сжатия будет достигаться на изображениях, строки которых содержат достаточно длинные цепочки одинаковых пикселов.
4.2.5. Арифметическое кодирование
Арифметическое кодирование во многих отношениях превосходит префиксные методы и теоретически обеспечивает среднюю битовую скорость передачи данных равной энтропии.
Арифметическое кодирование позволяет представить информацию более компактно, не требует ее разбиения на блоки для оптимизации сжатия, легко и эффективно использует адаптивную модель кодирования.
Основная концепция арифметического кодирования принадлежит П. Элайесу [2.56, 2.57] и относится к началу 60-х годов прошлого века. Дальнейшие исследования были направлены на практическую реализацию алгоритма [2.14–2.24].
Несмотря на объективную сложность нестандартного подхода, идея, лежащая в основе арифметического кодирования, весьма проста. Принцип этого метода можно пояснить следующим образом.
До начала кодирования сообщению ставится в соответствие интервал (0, 1]. Каждому символу из множества N символов, присутствующих в сообщении, на интервале (0, 1] отводится интервал, ширина которого равна вероятности появления символа. Если распределение уровней квантования пикселов изображения соответствует гистограмме, аналогичной той, что приведена в качестве примера при изучении хаффмановского кодирования, то указанный интервал (0, 1] разбивается так, как показано на рис. 4.3 слева.
При неадаптивной модели кодирования разбиение интервала (0, 1] на диапазоны, соответствующие различным символам, происходит до начала кодирования, и информация передается декодеру. При адаптивном кодировании после кодирования каждого символа уточняется таблица вероятности символов и корректируются соответствующие им интервалы как на передающей, так и на приемной стороне.
Пусть по мере сканирования изображения первым из N символом, поступающим на кодер, является символ b1. Тогда на первом этапе кодирования интервал (0, 1] преобразуется в новый интервал, границами которого являются границы интервала P (b1) на шкале (0, 1].
Диапазон новой шкалы равен r1P (b1), его минимальное значение равно l1P (b0), а максимальное h1P (b0) + P (b1).
Эта шкала также разбивается на части, пропорциональные вероятностям сообщений P (bi). Значения шкалы в n-й точке
n−1 |
|
i |
|
g1(n) = l1 + r1 · P (bi), |
(4.9) |
=0 |
|
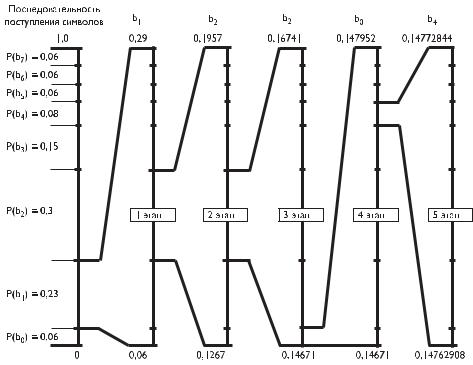
Глава 4. Статистическая избыточность дискретизированных данных
Рис. 4.3. Принцип обработки информации при арифметическом кодировании
причем g1(0) = l1, а g1(N )h1. Если на втором этапе на кодер поступает символ b2, то шкала вновь преобразуется, как показано на рис. 4.3. Диапазон новой шкалы равен r2r1 · P (b2), его минимальное значение равно
1 |
|
|
i |
|
|
l2 = l1 + r1 · |
P (bi), |
(4.10) |
=0 |
|
|
а максимальное значение — |
|
|
2 |
|
|
i |
|
|
h2 = l1 + r1 · |
P (bi). |
(4.11) |
=0 |
|
|
Значение шкалы в n-й точке |
|
|
n−1 |
|
|
i |
|
|
g2(n) = l2 + r2 · |
P (bi). |
(4.12) |
=0 |
|
|
Таким образом, последовательно шкала по мере поступления данных уменьшается. Поступающие символы сообщения уменьшают размер интервала в соответствии с моделью вероятности символов. Более часто встречающиеся символы меньше суживают интервал, чем редкие символы, и, следовательно, добавляют меньше битов в код интервала.
На k-м этапе при поступлении на кодер n-го символа шкала итеративно изменяется таким образом, что ее диапазон равен rk rk−1 · P (bn). Его минимальное
4.2. Виды статистического кодирования
|
|
|
= lk−1 + rk−1 · |
n−1 |
|
значение равно lk |
=0 P (bi), максимальное значение — hk = |
||||
По |
|
n |
|
i! |
p−1 |
|
! |
|
|
! |
|
= lk−1 |
+ rk−1 · |
i=0 P (bi), а значение шкалы p-й точки — gk(p) = lk + rk · |
i=0 P (bi). |
||
окончании цикла кодирования формируется такое число g, что выполняется неравенство lk < g hk. Это число g характеризует передаваемую последовательность символов, которая может быть однозначно восстановлена в приемнике.
Как показано на рис. 4.3, по окончании 5-го этапа число g должно быть
0,14762908 < g 0,14772844.
Если на приемной стороне сформирована исходная шкала вероятностей на интервале (0, 1], то это число g попадает на интервал, характеризующий символ b1, поступивший в кодер на первом этапе.
Зная, что на первом этапе на кодер поступил символ b1, можно рассчитать новую шкалу, соответствующую шкале кодера на 1-м этапе. В этой шкале число g попадает на интервал, характеризующий символ b2, поступивший в кодер на втором этапе. Таким образом, последовательно могут быть определены все символы, поступающие на кодер (в данном случае — последовательность b1, b2, b3, b0, b4).
Трудности в реализации приведенного алгоритма арифметического кодирования связаны с хранением чисел с большим количеством знаков после запятой
иоперациями над такими числами. Поэтому результатом дальнейших исследований стало использование более эффективных реализаций арифметического кодирования и специальных приемов повышения производительности вычислений, что позволило избежать сложных операций с плавающей точкой и существенно
упростить хранение данных. Алгоритм работает быстрее, если удается опери-
ровать двоичными дробями, задаваемыми последовательностью a1/21 + a2/22 + + a3/23 + a4/24 + · · · + ak/2k. При этом на каждом этапе вычислений необходимо дописывать дополнительные последовательности дробей, пока получившееся число не попадет в интервал, соответствующий закодированной цепочке. Чтобы избежать ограничений, связанных с используемой разрядностью переменных, реальный алгоритм работает с целыми числами и оперирует с дробями, числитель
изнаменатель которых являются целыми числами (например, знаменатель равен 216 = 65 536). При этом с потерей точности можно бороться, отслеживая сближе-
ние величин lk и hk и умножая числитель и знаменатель дроби на целое число, обычно на 2n.
4.2.6.Словарные методы кодирования дискретной информации
Словарные методы энтропийного кодирования вместо вероятностного используют так называемый комбинаторный подход, кодовые схемы которого используют коды только тех информационных последовательностей, которые реально порождаются информационным источником. Словарные модели опираются на информационную структуру, реализуемую словарем. Словарь включает в себя части уже обработанной информации, на основе которых осуществляется кодирование. Составляющие последовательности символов информационного источника кодируются посредством ссылок на идентичные им элементы словаря (совпадения).