

(по цифровому вещанию) Dvorkovich_V_Cifrovye_videoinformacionnye_sistemy
.pdfГлава 4. Статистическая избыточность дискретизированных данных
Величину «С» можно выбрать, например, как среднее значение длины совпадений, в данном случае сумма длин совпадений равна 34, а C = 34/17 = 2. Если совпадений постистории (правосторонних контекстов) нет, то записывается код номера строки «0».
Бит различия — первый бит пакуемой строки, отличающий ее от строки, максимально с ней совпадающей. В данном случае — 1 (отмечен подчеркиванием):
–в пакуемой строке — 010001011,
–в максимально близкой к ней 4-й строке — 010001010100101110.
Этим битом определяется положение максимально близкой строки: если бит 0, то эта строка выше, если 1 — то ниже. В данном случае пакуемая строка ниже.
Длина «вытяжки» (в терминологии автора алгоритма) — количество нулей или единиц в той части пакуемой строки (ниже отмечено подчеркиванием значений 0101), которая находится между битом различия максимально совпадающей строки (бит отмечен подчеркиванием в нижней строке) и битом различия второй строки (бит отмечен подчеркиванием в верхней строке). Если пакуемая строка лексикографически старше строки, максимально совпадающей с ней, то передается количество нулей, а если младше — то количество единиц. В данном случае подсчитывается количество нулей, которое равно 2.
01010010001010100101110
0100010111. . .
010001010100101110
Длина «вытяжки» также кодируется адаптивным статистическим кодером. Таким образом, упакована строка 010001011 (до бита различия включитель-
но). Операция восстановления строки осуществляется следующим образом: Декодируется номер строки максимального совпадения (в данном случае 4). По биту различия определяется положение запакованной строки (и соседней
строки) — если бит «0», то она выше (лексикографически младше, длина «вытяжки» — количество единиц), в противном случае — ниже (лексикографически старше, длина «вытяжки» — количество нулей) (в данном случае номер соседней строки — 13, она лексикографически старше).
Копируется в искомую строку совпадающая часть строки максимального совпадения (4,010001010100..) и соседней (13,010100100010. . . ), а также следующий бит из строки максимального совпадения (в данном случае — совпадающая часть — 010, а следующий бит — 0). Декодируется длина «вытяжки» (2).
Восстанавливается следующая часть искомой строки по «вытяжке» — копируются из строки максимального совпадения следующие биты, включающие соответствующее длине вытяжки количество нулей или единиц (в данном случае два нуля, так как искомая строка лексикографически старше; строка максимального совпадения — 010001010100. . . , из нее уже скопировано 4 бита, 0100, значит, копируется 010). Далее копируются из строки максимального совпадения все биты до следующего нуля или единицы (в данном случае — до следующего нуля, т. е. 1). Таким образом, восстановленная по «вытяжке» часть строки — 0101.
Дописывается в искомую строку бит различия (в данном случае — 1, а в строке максимального совпадения следующий бит, естественно, 0). Таким образом,
4.2. Виды статистического кодирования
восстановлена строка 010001011, что и требовалось. Кодирование и восстановление последующих битов информации осуществляется аналогичным образом.
Метод Барроуза–Уиллера (BWT — Burrows–Wheeler Transform)
Этот метод основан на использовании преобразования Барроуза–Уиллера, BWT, обеспечивающего преобразование всей исходной информации в более удобный для сжатия вид. Поскольку для реализации BWT требуется знать все элементы информационного потока, метод не может быть применен для сжатия при последовательном поступлении данных символ за символом.
Принцип преобразования BWT поясняется в табл. 4.13 на примере использования фразы: «на_дворе_трава_на_траве_дрова». Эта фраза обозначена в столбце 2 «Циклические перестановки» под номером «0». Последующие строки в этом столбце представляют собой циклические последовательные сдвиги фразы, каждый раз на один символ влево. Полученный набор матриц фраз пронумерован числами от 0 до 28.
Таблица 4.13. Пример преобразования Барроуза–Уиллера
№ |
Циклические |
Сортированные |
№ |
КС |
|
|
перестановки |
перестановки |
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
0 |
на_дворе_трава_ |
ава_на_траве_ |
11 |
р |
|
|
на_траве_дрова |
дрована_дворе_тр |
|
|
|
1 |
а_дворе_трава_ |
аве_дрована_дворе_ |
20 |
р |
|
|
на_траве_дрован |
трава_на_тр |
|
|
|
2 |
_дворе_трава_на_ |
ана_дворе_трава_ |
28 |
в |
|
|
траве_дрована |
на_траве_дров |
|
|
|
3 |
дворе_трава_на_ |
а_дворе_трава_на_ |
1 |
н |
|
|
траве_дрована_ |
траве_дрован |
|
|
|
4 |
воре_трава_на_ |
а_на_траве_дрова |
13 |
в |
|
|
траве_дрована_д |
на_дворе_трав |
|
|
|
5 |
оре_трава_на_тра |
а_траве_дрована_ |
16 |
н |
|
|
ве_дрована_дв |
дворе_трава_н |
|
|
|
6 |
ре_трава_на_ |
вана_дворе_трава_ |
27 |
о |
|
|
траве_дрована_дво |
на_траве_дро |
|
|
|
7 |
е_трава_на_тра |
ва_на_траве_дрова |
12 |
а |
|
|
ве_дрована_двор |
на_дворе_тра |
|
|
|
8 |
_трава_на_траве_ |
ве_дрована_дворе_ |
21 |
а |
|
|
дрована_дворе |
трава_на_тра |
|
|
|
9 |
трава_на_траве_ |
воре_трава_на_тра |
4 |
д |
|
|
дрована_дворе_ |
ве_дрована_д |
|
|
|
10 |
рава_на_траве_ |
дворе_трава_на_ |
3 |
_ |
|
|
дрована_дворе_т |
траве_дрована_ |
|
|
|
11 |
ава_на_траве_дро |
дрована_дворе_тра |
24 |
_ |
|
|
вана_дворе_тр |
ва_на_траве_ |
|
|
|
12 |
ва_на_траве_дрова |
е_дрована_дворе_ |
22 |
в |
|
|
на_дворе_тра |
трава_на_трав |
|
|
|
13 |
а_на_траве_дрова |
е_трава_на_траве_ |
7 |
р |
|
|
на_дворе_трав |
дрована_двор |
|
|
|
14 |
_на_траве_дрова |
на_дворе_тра |
0 |
а |
14 |
|
на_дворе_трава |
ва_на_траве_дрова |
|
|
|
15 |
на_траве_дрована_ |
на_траве_дрова |
15 |
_ |
|
|
дворе_трава_ |
на_дворе_трава_ |
|
|
|
Глава 4. Статистическая избыточность дискретизированных данных
Таблица 4.13 (окончание)
1 |
2 |
3 |
4 |
5 |
6 |
16 |
а_траве_дрована_ |
ована_дворе_ |
26 |
р |
|
|
дворе_ трава_н |
трава_на_траве_др |
|
|
|
17 |
_траве_дрована_ |
оре_трава_на_ |
5 |
в |
|
|
дворе_трава_на |
траве_дрована_дв |
|
|
|
18 |
траве_дрована_ |
рава_на_траве_ |
10 |
т |
|
|
дворе_трава_на_ |
дрована_дворе_т |
|
|
|
19 |
раве_дрована_ |
раве_дрована_ |
19 |
т |
|
|
дворе_трава_на_т |
дворе_трава_на_т |
|
|
|
20 |
аве_дрована_ |
ре_трава_на_ |
6 |
о |
|
|
дворе_трава_на_тр |
траве_дрована_дво |
|
|
|
21 |
ве_дрована_дворе_ |
рована_дворе_ |
25 |
д |
|
|
трава_на_тра |
трава_на_траве_д |
|
|
|
22 |
е_дрована_дворе_ |
трава_на_траве_ |
9 |
_ |
|
|
трава_на_трав |
дрована_дворе_ |
|
|
|
23 |
_дрована_дворе_ |
траве_дрована_ |
18 |
_ |
|
|
трава_на_траве |
дворе_трава_на_ |
|
|
|
24 |
дрована_дворе_ |
_дворе_трава_на_ |
2 |
а |
|
|
трава_на_траве_ |
траве_дрована |
|
|
|
25 |
рована_дворе_ |
_дрована_дворе_ |
23 |
е |
|
|
трава_на_траве_д |
трава_на_траве |
|
|
|
26 |
ована_дворе_ |
_на_траве_ |
14 |
а |
|
|
трава_на_траве_др |
дрована_дворе_ |
|
|
|
|
|
трава |
|
|
|
27 |
вана_дворе_трава_ |
_трава_на_траве_ |
8 |
е |
|
|
на_траве_дро |
дрована_дворе |
|
|
|
28 |
ана_дворе_трава_ |
_траве_дрована_ |
17 |
а |
|
|
на_траве_дров |
дворе_трава_на |
|
|
|
Встолбце 3 «Сортированные перестановки» фразы столбца 2 отсортированы
всоответствии с лексикографическим порядком символов, в данном случае —
впорядке «а», «в», «д», «е», «н», «о», «р», «т», «_». При этом сначала следует сортировать строки по первому символу, затем строки, у которых первые симво-
лы одинаковы, — по второму символу и т. д. Номера исходных строк приведены в столбце 4.
После этой сортировки необходимо выписать из каждой фразы последние символы, приведенные в столбце 5, и запомнить номер строки, в которой записана исходная фраза (указан в столбце 6).
Приведенное преобразование Барроуза–Уиллера позволяет восстановить исходную информацию по данным столбцов 5 и 6. Последовательность операций восстановления информации приведена в табл. 4.14. Исходной информацией являются символы, приведенные в правой части столбца 2 этой таблицы и обозначенные жирным шрифтом.
Символ «а» первым встречается 6 раз; символы «в» и «р» — по 4 раза; символы «д», «е», «н», «о» и «т» — по 2 раза; символ «_» — 5 раз. Ввиду того что сортировка фраз осуществлялась в соответствии с лексикографическим порядком первых символов, их последовательность соответствует правой части столбца 2, обозначенного как «1-е символы».
Символы, идущие вслед за первыми символами, приведены в столбце 3. Принцип их формирования поясним на примерах символов, следующих за первыми шестью символами «а» в столбце 2. Поскольку каждая из строк матрицы бы-
4.2. Виды статистического кодирования
ла получена путем циклического сдвига предыдущей строки, символы первого и последнего столбцов образуют пары.
Таблица 4.14. Восстановление данных после преобразования Барроуза–Уиллера
№ |
1-е символы |
2-е символы |
3-и символы |
|
28-е символы |
1 |
2 |
3 |
4 |
|
29 |
0 |
а. . . . . . . . . |
ав . . . . . . |
ава . . . . . . |
|
ава_на_траве_ |
р |
р |
р |
|
дрована_дворе_тр |
|
|
|
||||
1 |
а. . . . . . . . . |
ав. . . . . . |
аве . . . . . . |
|
аве_дрована_ |
р |
р |
р |
|
дворе_трава_на_тр |
|
|
|
||||
2 |
а. . . . . . . . . |
ан . . . . . . |
ана |
|
ана_дворе_трава_ |
в |
в |
в |
|
на_траве_дров |
|
|
|
||||
3 |
а. . . . . . . . . |
а_ . . . . . . . . . |
а_д . . . . . . |
|
а_дворе_трава_ |
н |
. . . н |
н |
|
на_траве_дрован |
|
|
|
||||
4 |
а. . . . . . . . . |
а_ . . . . . . . . . |
а_н . . . . . . |
|
а_на_траве_ |
в |
. . . в |
в |
|
дрована_дворе_трав |
|
|
|
||||
5 |
а. . . . . . . . . |
а_ . . . . . . . . . |
а_р |
|
а_траве_дрована_ |
н |
. . . н |
н |
|
дворе_трава_н |
|
|
|
||||
6 |
в. . . . . . . . . |
ва . . . . . . |
ван . . . . . . |
|
вана_дворе_трава_ |
о |
о |
о |
|
на_траве_дро |
|
|
|
||||
7 |
в. . . . . . . . . |
ва . . . . . . |
ва_ . . . . . . |
|
ва_на_траве_ |
а |
а |
а |
|
дрована_дворе_тра |
|
|
|
||||
8 |
в. . . . . . |
ве . . . . . . |
ве_ . . . . . . |
|
ве_дрована_дворе_ |
а |
а |
а |
|
трава_на_тра |
|
|
|
||||
9 |
в. . . . . . |
во . . . . . . |
вор . . . . . . |
|
воре_трава_на_ |
д |
д |
д |
|
траве_дрована_д |
|
|
|
||||
10 |
д. . . . . . . . . |
дв . . . . . . |
дво |
|
дворе_трава_на_ |
_ |
_ |
_ |
|
траве_дрована_ |
|
|
|
||||
11 |
д. . . . . . . . . |
др . . . . . . |
дро . . . . . . |
|
дрована_дворе_ |
_ |
_ |
_ |
|
трава_на_траве_ |
|
|
|
||||
12 |
е. . . . . . |
е_ . . . . . . |
е_д . . . . . . |
|
е_дрована_дворе_ |
в |
в |
в |
|
трава_на_трав |
|
|
|
||||
13 |
е. . . . . . |
е_ . . . . . . |
е_н . . . . . . |
|
е_трава_на_траве_ |
р |
р |
р |
|
дрована_двор |
|
|
|
||||
|
н |
на |
на_ |
|
на_дворе_ |
14 |
|
трава_на_траве_ |
|||
а |
а |
а |
|
||
|
|
дрова |
|||
|
|
|
|
|
|
15 |
н. . . . . . |
на . . . . . . |
на_ . . . . . . |
|
на_траве_дрована_ |
_ |
_ |
_ |
|
дворе_трава_ |
|
|
|
||||
16 |
о. . . . . . |
ов . . . . . . |
ова . . . |
|
ована_дворе_ |
р |
р |
р |
|
трава_на_траве_др |
|
|
|
||||
17 |
о. . . . . . |
ор . . . . . . |
оре . . . . . . |
|
оре_трава_на_ |
в |
в |
в |
|
траве_дрована_дв |
|
|
|
||||
18 |
р. . . . . . |
ра . . . . . . |
рав . . . . . . |
|
рава_на_траве_ |
т |
т |
т |
|
дрована_дворе_т |
|
|
|
||||
19 |
р. . . . . . |
ра . . . . . . |
рав . . . |
|
раве_дрована_ |
т |
т |
т |
|
дворе_трава_на_т |
|
|
|
||||
20 |
р. . . . . . |
ре . . . . . . |
ре_ . . . . . . |
|
ре_трава_на_ |
о |
о |
о |
|
траве_дрована_дво |
|
|
|
||||
21 |
р. . . . . . |
ро . . . . . . |
ров . . . . . . |
|
рована_дворе_ |
д |
д |
д |
|
трава_на_траве_д |
|
|
|
||||
22 |
т. . . . . . |
тр . . . . . . |
тра |
|
трава_на_траве_ |
_ |
_ |
_ |
|
дрована_дворе_ |
|
|
|
Глава 4. Статистическая избыточность дискретизированных данных
Таблица 4.14 (окончание)
1 |
2 |
3 |
4 |
|
29 |
23 |
т. . . . . . |
тр . . . . . . |
тра . . . . . . |
|
траве_дрована_ |
_ |
_ |
_ |
|
дворе_трава_на_ |
|
|
|
||||
24 |
_. . . . . . |
_д . . . . . . |
_дв . . . . . . |
|
_дворе_трава_на_ |
а |
а |
а |
|
траве_дрована |
|
|
|
||||
25 |
_. . . . . . |
_д . . . . . . |
_др . . . . . . |
|
_дрована_дворе_ |
е |
е |
е |
|
трава_на_траве |
|
|
|
||||
|
_ |
_н |
_на |
|
_на_траве_ |
26 |
|
дрована_дворе_ |
|||
а |
а |
а |
|
||
|
|
трава |
|||
|
|
|
|
|
|
27 |
_. . . . . . |
_т . . . . . . |
_тр . . . . . . |
|
_трава_на_траве_ |
е |
е |
е |
|
дрована_дворе |
|
|
|
||||
28 |
_. . . . . . |
_т . . . . . . |
_тр . . . . . . |
|
_траве_дрована_ |
а |
а |
а |
|
дворе_трава_на |
|
|
|
Строки, в которых последними символами являются символы «а» справа можно дополнить так:
Строка 7 — в . . . . . . . . . . . . . . . а|в;
Строка 6 — в . . . . . . . . . . . . . . . а|в;
Строка 14 — н . . . . . . . . . . . . . . . а|н;
Строка 24 — _ . . . . . . . . . . . . . . . а|_;
Строка 26 — _ . . . . . . . . . . . . . . . а|_;
Строка 28 — _ . . . . . . . . . . . . . . . а|_.
Это означает, что первые два символа в 6 строках столбца 3 (2-е символы) будут соответственно «ав», «ав», «ан», «а_», «а_» и «а_».
Подобным же образом, используя столбец 3, формируются третьи символы, как приведено в столбце 4, поскольку строки, в которых последними символами являются символы «а» справа, можно дополнить так:
Строка 7 — ва . . . . . . . . . . . . а|ва;
Строка 8 — ве . . . . . . . . . . . . а|ве;
Строка 14 — на . . . . . . . . . . . . а|на;
Строка 24 — _д . . . . . . . . . . . . а|_д;
Строка 26 — _н . . . . . . . . . . . . а|_н;
Строка 28 — _т . . . . . . . . . . . . а|_т.
Это означает, что первые три символа в 6 первых строках столбца 3 (2-е символы) будут соответственно «ава», «аве», «ана», «а_д», «а_н» и «а_т».
Таким образом, последовательно шаг за шагом определяются символы в каждой из строк табл. 4.14, в 14-й строке которой формируется искомая последовательность.
Описанный метод восстановления исходной информации весьма сложен и требует значительного объема оперативной памяти.
На самом деле получение исходной информации значительно упрощается при применении вектора обратного преобразования, принцип нахождения которого поясняется с использованием табл. 4.15.

4.2. Виды статистического кодирования
Таблица 4.15. Получение Т-вектора обратного преобразования Барроуза–Уиллера
|
|
Первые |
№ |
№ |
|
и последние |
новых |
|
|
символы |
строк |
|
|
|
|
1 |
|
2 |
3 |
0 |
а. |
. . . . . . . . . . . . . . р |
18 |
1 |
а. |
. . . . . . . . . . . . . . р |
19 |
2 |
а. |
. . . . . . . . . . . . . . в |
6 |
3 |
а. |
. . . . . . . . . . . . . . н |
14 |
4 |
а. |
. . . . . . . . . . . . . . в |
7 |
5 |
а. |
. . . . . . . . . . . . . . н |
15 |
6 |
в. |
. . . . . . . . . . . . . . о |
16 |
7 |
в. |
. . . . . . . . . . . . . . а |
0 |
8 |
в. |
. . . . . . . . . . . . . . а |
1 |
9 |
в. |
. . . . . . . . . . . . . . д |
10 |
10 |
д. |
. . . . . . . . . . . . . . _ |
24 |
11 |
д. |
. . . . . . . . . . . . . . _ |
25 |
12 |
е. |
. . . . . . . . . . . . . . в |
8 |
13 |
е. |
. . . . . . . . . . . . . . р |
20 |
14 |
н. |
. . . . . . . . . . . . . . а |
2 |
15 |
н. |
. . . . . . . . . . . . . . _ |
26 |
16 |
о. |
. . . . . . . . . . . . . . р |
21 |
17 |
о. |
. . . . . . . . . . . . . . в |
9 |
18 |
р. |
. . . . . . . . . . . . . . т |
22 |
19 |
р. |
. . . . . . . . . . . . . . т |
23 |
20 |
р. |
. . . . . . . . . . . . . . о |
17 |
21 |
р. |
. . . . . . . . . . . . . . д |
11 |
22 |
т. |
. . . . . . . . . . . . . . _ |
27 |
23 |
т. |
. . . . . . . . . . . . . . _ |
28 |
24 |
_. |
. . . . . . . . . . . . . . а |
3 |
25 |
_. |
. . . . . . . . . . . . . . е |
12 |
26 |
_. |
. . . . . . . . . . . . . . а |
4 |
27 |
_. |
. . . . . . . . . . . . . . е |
13 |
28 |
_. |
. . . . . . . . . . . . . . а |
5 |
|
|
|
|
|
|
№ |
|
|
|
Новые строки |
старых |
Дан- |
№ |
||
строк — |
ные |
п/п |
|||
|
|
||||
|
|
Т-вектор |
|
|
|
|
4 |
5 |
6 |
7 |
|
в. . . . . |
. . . . . . . а |
7 |
р |
0 |
|
в. . . . . . |
. . . . . . а |
8 |
р |
1 |
|
н. . . . . . |
. . . . . . а |
14 |
в |
2 |
|
_.. . . . . . |
. . . . . . а |
24 |
н |
3 |
|
_. . . . . . |
. . . . . . а |
26 |
в |
4 |
|
_. . . . . . |
. . . . . . а |
28 |
н |
5 |
|
а. . . . . . |
. . . . . . в |
2 |
о |
6 |
|
а. . . . . . |
. . . . . . в |
4 |
а |
7 |
|
е. . . . . . |
. . . . . . в |
12 |
а |
8 |
|
о. . . . . . |
. . . . . . в |
17 |
д |
9 |
|
в. . . . . . |
. . . . . . д |
9 |
_ |
10 |
|
р. . . . . . |
. . . . . . д |
21 |
_ |
11 |
|
_. . . . . . |
. . . . . . е |
25 |
в |
12 |
|
_. . . . . . |
. . . . . . е |
27 |
р |
13 |
|
а. . . . . . |
. . . . . . н |
3 |
а |
14 |
|
а. . . . . . |
. . . . . . н |
5 |
_ |
15 |
|
в. . . . . . |
. . . . . . о |
6 |
р |
16 |
|
р. . . . . . |
. . . . . . о |
20 |
в |
17 |
|
а. . . . . . |
. . . . . . р |
0 |
т |
18 |
|
а. . . . . . |
. . . . . . р |
1 |
т |
19 |
|
е. . . . . . |
. . . . . . р |
13 |
о |
20 |
|
о. . . . . . |
. . . . . . р |
16 |
д |
21 |
|
р. . . . . . |
. . . . . . т |
18 |
_ |
22 |
|
р. . . . . . |
. . . . . . т |
19 |
_ |
23 |
|
д. . . . . . |
. . . . . . _ |
10 |
а |
24 |
|
д. . . . . . |
. . . . . . _ |
11 |
е |
25 |
|
н. . . . . . |
. . . . . . _ |
15 |
а |
26 |
|
т. . . . . . . |
. . . . . _ |
22 |
е |
27 |
|
т. . . . . . . |
. . . . . _ |
23 |
а |
28 |
|
|
|
|
|
|
|
Исследуя алгоритм проведения операций восстановления информации, можно сделать вывод о том, что при формировании строк путем объединения переданных последних символов (отмеченных во всех столбцах табл. 4.14 жирным шрифтом) с выявленными столбцами 1-го, 2-го и т. д. символов формируются новые строки, расположенные на других позициях матрицы. Например, из строки с номером «0», содержащей два первых и последний символы (см. табл. 4.14, столбец 3):
ав. . . . . . . . . . . . р, формируется новая строка, первые три символа которой таковы (см. табл. 4.14, столбец 4):
рав. . . . . . . . . . . .
В данном случае эта новая строка располагается под номером 18.
Глава 4. Статистическая избыточность дискретизированных данных
Исследуя столбец 4 табл. 4.15, можно увидеть, что строки, перемещенные в соответствии с номерами столбца 3, имеют последние символы, отсортированные в соответствии с лексикографическим порядком. Первые же символы в этом столбце определяют вторые символы строк, приведенных в столбце 2.
Полученная строка номеров строк (см. столбец 5) — T = {7, 8, 14, 24, 26, 28, 2, 4, 12, 17, 9, 21, 25, 27, 3, 5, 6, 20, 0, 1, 13, 16, 18, 19, 10, 11, 15, 22, 23} и является искомым вектором, содержащим номера позиций символов в строке, которую необходимо декодировать (см. столбцы 5 и 6 данной таблицы).
При использовании имеющегося номера искомой строки (в данном случае равный 14) вся строка определяется весьма просто.
T [14] = 3, и первым символом декодируемой строки является символ «н» (см. последний символ в строке 3 столбца 2). Затем определяется номер строки в векторе Т под номером 3.
T [3] = 24, и вторым символом декодируемой строки является символ «а» (см. последний символ в строке 24 столбца 2). Сумма двух символов — «на».
Далее по аналогии:
T [24] = 10 — «_»; T [10] = 9 — «д»; T[9]=17 — «в»; T [17] = 20 — «о»;
T [20] = 13 — «р»; T [13] = 27 — «е»; T [27] = 22 — «_»; T [22] = 18 — «т»; T [18] = 0 - «р»; T [0] = 7 — «а»; T [7] = 4 — «в»; T [4] = 26 — «а»;
T [26] = 15 — «_»; T [15] = 5 — «н»; T [5] = 28 — «а»; T [28] = 23 — «_»; T [23] = 19 — «т»; T [19] = 1 — «р»; T [1] = 8 — «а»; T [8] = 12 — «в»;
T [12] = 25 — «е»; T [25] = 11 — «_»; T [11] = 21 — «д»; T [21] = 16 — «р»; T [16] = 6 — «о»;T [6] = 2 — «в»; T [2] = 14 — «а».
Весьма часто перед кодированием изображения подвергаются дискретным преобразованиям. Обобщенно можно считать, что используется два вида преобразований:
–непосредственная обработка дискретных отсчетов, к которой относится кодирование с предсказанием;
–предварительное алгоритмическое преобразование с формированием различного вида спектров сигналов.
4.3.1. Кодирование с предсказанием
Широкое применение имеют методы кодирования с предсказанием (так называемая дифференциальная импульсно-кодовая модуляция ДИКМ).
ДИКМ очень близко связана с условным кодированием. Однако в данном случае вместо кодирования и передачи значения N -го пиксела bN , передается
ˆ |
ˆ |
— величина, являющаяся фиксированной функцией |
величина bN − bN , где |
bN |
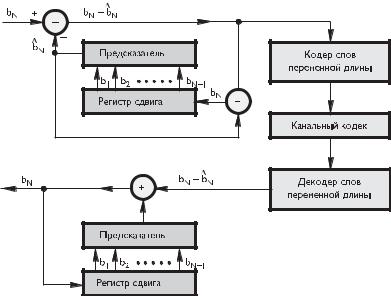
ранее переданных пикселов b1, b2, ..., bN −1 (рис. 4.6).
Это означает, что предсказываемое значение N -го пиксела вычисляется на передаче с использованием формулы, включающей линейную комбинацию значений нескольких предыдущих пикселов [2.4, 2.56, 2.65–2.70].
4.3. Кодирование с преобразованием
Рис. 4.6. Структура системы кодирования с предсказанием
Результатом вычисления является некая оценка («предсказание») значения N -го пиксела, которое, естественно, отличается от его истинного значения.
Таким образом, на передаче известно и истинное значение пиксела, и рассчитанное по формуле предсказание его значения. Остается вычесть одно из другого и передать по каналу связи.
На приемной стороне известно, по какой формуле рассчитывалось на передаче предсказание значения N -го пиксела. Поэтому приемник также рассчитывает
предсказанное значение -го пиксела ˆN , используя значения нескольких преды-
N b
дущих пикселов. Когда предсказание получено, приемнику остается лишь прибавить к нему значение разности между предсказанным и истинным значением
-го пиксела N −ˆN , полученное им из канала от передатчика, и сформировать
N b b
таким образом истинное значение N -го пиксела.
Понятно, что такая система в принципе может работать при абсолютно любой формуле предсказания, даже при такой, которая дает результаты очень далекие от истинного значения предсказываемого пиксела, т. е. не обеспечивает вообще никакой точности — важно лишь, чтобы формула предсказания была одинаковой на передаче и на приеме. Однако чем точнее предсказание, тем меньше объем информационного потока, передаваемого по каналу, и таким образом, главная задача кодирования с предсказанием — получение дифференциального сигнала, который в среднем обладает малыми значениями и только изредка имеет большую величину.
Энтропия такого дифференциального сигнала мала, и, следовательно, мал битовый поток, необходимый для кодирования информации.
Например, эффективным является предсказатель, вычисляющий ˆN
b таким образом, чтобы предсказываемая величина была средневероятным значением
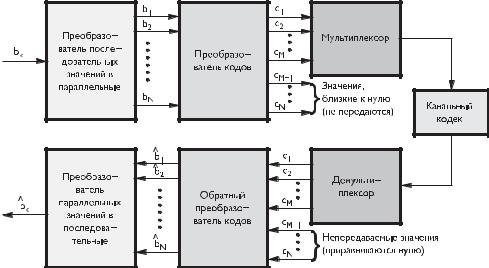
Глава 4. Статистическая избыточность дискретизированных данных
Рис. 4.7. Структурная схема кодирования с преобразованием
ˆ · |
bN = bN P (bN b1, ..., bN −1) , (4.23)
bN
минимизирующим среднеквадратичную ошибку предсказания. Обычно используют линейный предсказатель
N −1 |
|
ˆbN = αi · bi , |
(4.24) |
i=1
в котором коэффициенты αi часто выбирают путем минимизации среднего значения ошибки предсказания:
ˆ |
2 |
min . |
(4.25) |
E(bN − bN ) |
|
При этом коэффициенты αi могут быть получены путем решения системы урав-
нений:
N −1
αi · r ij = dj , |
(4.26) |
i=1
где dj = E(bN , bj ), rij = E(bi, bj ), j = 1, ..., N − 1; r ij — корреляционная матрица, определяющая статистическую взаимосвязь между пикселами bi и bj .
4.3.2. Кодирование с дискретным преобразованием
Наиболее эффективным является кодирование с дискретным преобразованием N -мерных блоков b ИКМ закодированных пикселов. Структурная схема такого кодирования приведена на рис. 4.7.

4.3. Кодирование с преобразованием
Обычно применяется линейное преобразование [4, 56, 65, 70–72]:
N
cj = |
tmj · bm , 1 j N, (4.27) |
(4.27) |
|
m=1 |
|
где bm — коды, характеризующие исходный блок пикселов изображения, cj — коды, характеризующие преобразованные величины, tmj = T — матрица преобразования.
В матричной форме это преобразование и обратное преобразование можно записать в виде:
c = Т × b, b = Т−1 × c.
Главная цель преобразования — сделать как можно больше преобразованных величин cj настолько малыми, чтобы они стали несущественными и не требовали бы кодирования и передачи.
Другой целью такого преобразования является минимизация статистических зависимостей между ci и cj (i = j), что обеспечивает само по себе устранение избыточности информации.
Если обратная матрица T−1 равна транспонированной T (T−1 = T ), то преобразование является ортонормированным, или унитарным.
Примером такого преобразования является дискретное преобразование Фурье
(ДПФ) [2.3, 2.4, 2.56, 2.65, 2.66, 2.73], при котором |
|
||||||||
1 |
|
2πi |
|
|
|
||||
tmk = |
√ |
|
· exp[− |
|
|
· (k − 1) · (m − 1)], k, m = 1, ..., N. |
(4.28) |
||
|
N |
||||||||
N |
|||||||||
|
|
|
|
|
|
|
|
||
Соотношение T−1 = T в данном случае эквивалентно |
|
||||||||
|
|
|
N |
|
|
|
|||
|
|
|
|
|
|
1, |
|
||
|
|
|
k=1 tmk · tlk |
= δml = 0, |
m = l. |
(4.29) |
|||
Унитарное преобразование сохраняет энергию сигнала, т. е.
N |
N |
|
l |
|
|
|bl|2 = |
|cm|2. |
(4.30) |
=1 |
m=1 |
|
Это соотношение известно как равенство Парсеваля [2.4].
Используется большое количество унитарных преобразований. Так как обратное преобразование полностью восстанавливает исходные коды блока пикселов bl, энтропия при преобразовании не меняется, т. е.
H(b) = H(c) бит/блок.
К тому же, если преобразование устраняет статистическую зависимость между преобразованными величинами {c1, . . . , cN }, то
N
H(c) = H(cm)бит/блок.
m=1
В этом случае оказывается весьма эффективным блочное кодирование (исключая, возможно, коэффициенты, энтропия которых H(cm) 1). До сих пор не найдено преобразование пиксельной информации, которое полностью устраняет статистическую зависимость между преобразованными величинами.