

(по цифровому вещанию) Dvorkovich_V_Cifrovye_videoinformacionnye_sistemy
.pdfЛитература к части I
1.19.Приоров А.Л., Хрящев В.В., Апальков И.В. Цифровая обработка изображений: Учебное пособие. Ярославль: ЯрГУ им. П.Г. Демидова, 2007
1.20.Ho man G. CIE Color Space http:www.fho-emde/ hoffmann/ciexyz29082000.pdf
1.21.Гуревич М.М. Цвет и его измерение. М.: АН СССР, 1950
1.22.Кустарев А.К. Колориметрия цветного телевидения. М.: Связь, 1967
1.23.Кривошеев М.И., Кустарев А.К. Световые измерения в телевидении. М.: Связь, 1973
1.24.CIE 1931 Color Space
http://en. wikipedia.org/wiki/CIE 1931 color space
1.25.MacAdam D.L. Sources of Color Science. Cambridge, MA, MIT Press, 1970
1.26.Джадд Д., Вышецки Г. Цвет в науке и технике. М.: Мир, 1978
1.27.Юстова Е.Н. Таблицы основных колориметрических величин. М.: Изд-во Комитета стандартов, 1967
1.28.Photometry/Colorimetry-light perception http://www/paladix/cz///www.wikipedia.org
1.29.Chromaticity Diagrams Lab Report http:www.efg2.com/Lab/Graphics/Colors/Cromaticity.html
1.30.Lab Color Spase
http://en. wicipedia.org/wiki/Lab_color_cpace
1.31.CIPR Still Images http://www.cipr.rpi.edu/resource/stills/index.html
1.32.CIPR Sequences http://www.cipr.rpi.edu/resource/sequences/index.html
1.33.The University of South California free database http://sipi.usc.edu/database/index/html
1.34.Wikipedia materials plas
http://en/ wikipedia.org/wiki/Standard test image#cite note-1
1.35.МККР. Характеристики монохромных систем телевидения. Отчет 308
1.36.МККР. Параметры кодированных сигналов цифрового телевидения для студий. Рекомендация 601
1.37.Netravali A.N., Haskell B.G. Digital pictures: Representation and Compression.: Plenum Press, N.Y., 1991
1.38.Цифровое телевидение / Под ред. М.И.Кривошеева. М.: Связь, 1980
1.39.Цифровое кодирование телевизионных изображений / Под ред. И.И. Цукермана. М.: Связь, 1981
1.40.МККР. Характеристики телевизионных систем. Отчет 624
1.41.Темников Ф.Е., Афонин В.А., Дмитриев В.И. Теоретические основы информационной техники. М.: Энергия, 1971
1.42.Певзнер Б.М. Системы цветного телевидения. Л.: Энергия, 1969
1.43.МККР. Характеристики систем цветного телевидения. Отчет 407
Литература к части I
1.44.Новаковский С.В. Стандартные системы цветного телевидения. М.: Связь, 1976
1.45.Певзнер Б.М. Качество цветных телевизионных изображений. М.: Радио и связь, 1988
1.46.МККР. Номенклатура сигналов цветных полос. Рекомендация 471
1.47.Птачек М. Цифровое телевидение. Теория и техника. М.: Радио и связь, 1990
1.48.Дворкович В.П., Кривошеев М.И. Особенности измерения и контроля в цветном телевидении. М.: Издательство ГКТР, 1981
1.49.ГОСТ 7845. Система вещательного телевидения. Основные параметры. Методы измерений
1.50.Новаковский С.В., Котельников А.В. Новые системы телевидения. М.: Радио и связь, 1992
1.51.ITU-R Recommendation BT.1200-1 Target standard for digital video systems for the studio and for international programme exchange, 1998
1.52.ITU-R Recommendation BT.1201-1 Extremely high resolution imagery, 2004
1.53.МККР. Подходы к разработке общемирового стандарта студийного ТВЧ. Отчет AW/11
1.54.Дворкович В., Чобану М. Проблемы и перспективы развития систем кодирования динамических изображений // MediaVision. 2011. № 2, 3, 4, 5, 7, 8
1.55.Хлебородов В.А. На пути к единому мировому стандарту ТВЧ // Техника кино и телевидения, 1988, № 2
1.56.ISO/IEC 11172-2 — Information Technology — Coding of Moving Pictures and Associated Audio for Digital Storage Media at up to about 1,5 Mbit/s — Part 2: Video, 1993 (MPEG-1 Video)
1.57.ISO/IEC 14496-2 — Information Technology — Coding of Audio-Visual Objects — Part 2: Visual, 2004 (MPEG-4 Video)
1.58.ITU-T Recommendation H.261 — Video Codec for Audiovisual services at p x 64 kbit/s, 1993; ITU-T Recommendation H.263 — Video Coding for Low Bit Rate Communication, 2005
1.59.ITU-T Recommendation H.262 / ISO/IEC 13818-2 — Information Technology — Generic Coding of Moving Pictures and Associated Audio Information: Video, 2000 (MPEG-2 Video)
1.60.ITU-T Recommendation H.264 — Advanced Video Coding for Generic Audiovisual Services / ISO/IEC 14496-10 — Information Technology — Coding of Audio-Visual Objects — Part 10: Advanced Video Coding, 2005
1.61.Дорошенко И.В. Системы телетекста. Техника средств связи. Сер. Техника телевидения. 1981, вып. 3
1.62.Мартин Дж. Видеотекс и информационное обслуживание общества. Перевод с английского. М.: Радио и связь, 1987
Литература к части I
1.63.Jayant N.S., Noll P. Digital Coding of Waveforms, Chapter 4.: Prentice Hall, N.J., 1984
1.64.Прэтт У. Цифровая обработка изображений. Т. 1–2. М.: Мир, 1982
1.65.Залманзон Л.А. Преобразования Фурье, Уолша, Хаара и их применение в управлении, связи и других областях. М.: Наука, 1989
1.66.Ахмед Н., Рао К.Р. Ортогональные преобразования при обработке цифровых сигналов. М.: Связь, 1980
1.67.Гольдберг Л.М., Матюшкин Б.Д., Поляк М.Н. Цифровая обработка сигналов. Справочник. М.: Радио и связь, 1985
1.68.Ярославский Л.П. Введение в цифровую обработку изображений. М.: Сов. радио, 1979
1.69.Рабинер Л.Р. Гоулд Б. Теория и применение цифровой обработки сигналов. М., Мир, 1978
1.70.Левин Б.Р. Теоретические основы статистической радиотехники. т.1, т.2, т.3. М.: Сов. радио, 1974, 1975, 1976
1.71.Max J. Quantizing for minimum distortion. IEEE Trans., 1960, v. JT-6, № 3

Сокращение избыточности информации о статическом и динамическом изображении является способом обеспечения существенного уменьшения объема цифровой информации для реализации режимов ее хранения и передачи по каналам связи, использования в разнообразных приложениях, таких как видеотелефония, видеоконференцсвязь, широковещательное телевидение, дистанционное зондирование, телемедицина и др.
Избыточность информации является центральным понятием для ее цифрового сжатия. Термин «сжатие» означает уменьшение объема данных, используемых для описания определенного количества информации. Данные являются средством передачи информации. При этом для определения одного и того же количества информации может быть использовано различное количество данных.
Как оценить эффективность различных видов представления информации? Используется два вида оценки. Один из них, относительный, характеризуется коэффициентом сжатия [2.1–2.4]:
CR = N2 , N1
где N1 и N2 — данные, характеризующие объем информации до и после сокращения избыточности.
Абсолютная оценка эффективности представления информации определяется величиной, равной количеству информации данного представления, приходящемуся в среднем на один информационный символ. Так, если исходная информация об изображении характеризуется объемом 8 битов на пиксел, то при
Введение
эффективном кодировании на каждый пиксел в среднем может приходиться существенно меньше бита.
Поток данных об изображении имеет значительное количество излишней информации, которая может быть устранена практически без визуальной заметности его изменений.
Существует два типа избыточности:
–статистическая избыточность, связанная с корреляцией и предсказуемостью данных; эта избыточность может быть устранена без потери информации, исходные данные при этом могут быть полностью восстановлены;
–визуальная (субъективная) избыточность, которую можно устранить с частичной потерей данных, мало влияющих на качество воспроизводимых изображений; это — информация, которую можно изъять из изображения, не нарушая визуально воспринимаемое качество изображений.
Соседние пикселы динамических изображений как в пространственной, так
иво временной областях коррелированы. Устранение внутрикадровой статистической избыточности (т. е. пространственной корреляции пикселов) позволяет сократить объем информации об изображении в 1,5–4 раза.
Воснове методов устранения статистической избыточности лежит информационная теорема Клода Шеннона, которая характеризует зависимость эффективности представления информации от свойств самой информации. Для количественной оценки свойств информации вводятся две связанные между собой характеристики: энтропия и избыточность. Теорема Шеннона определяет предельные возможности статистического кодирования информации.
При создании метода статистического кодирования решаются три проблемы: построения информационной модели, генерации кода и хранения описания способа кодирования. Эффективность кодирования различных видов информации зависит от применяемых принципов решения этих проблем.
Визуальная избыточность связана с психофизическими свойствами зрения. При восприятии изображения зритель не оценивает количественные параметры отдельных пикселов, а отыскивает определенные особенности, такие как контуры или текстурные области, подсознательно объединяет их в узнаваемые детали
иизображения в целом.
Визуальная избыточность принципиально отличается от статистической избыточности, она связана с реальной и количественно измеримой зрительной информацией. Поскольку она не воспринимается при визуальном восприятии, постольку она может быть устранена при цифровой обработке изображений.
Устранение визуальной избыточности позволяет очень существенно сократить объем информации за счет необратимого удаления той части информации, которая не воспринимается или плохо различается человеческим глазом. При использовании соответствующих методов объем информации об отдельном изображении может быть снижен в 8–12 раз без видимых искажений, а при обработке последовательности изображений объем информации может быть сокращен в несколько десятков и даже сотни раз.

Пусть имеется дискретизированное на IM ×N пикселов и квантованное с точностью K битов монохромное изображение. Следовательно, при импульсно-кодовой модуляции необходимо передать M × N × K битов информации.
Если предположить, что квантованные значения яркости неравновероятны, то уменьшение информации возможно путем изменения количества битов информации для кодирования пикселов: более вероятные значения яркости кодируются словами с меньшим количеством битов, а менее вероятные — с большим. Этот метод называется кодированием словами переменной длины, или энтропийным кодированием.
Пусть квантованный уровень яркости bi имеет вероятность P (bi), и ему присваивается слово — код длины L(bi) битов. Тогда средняя длина кода для всего изображения составит:
I |
|
i |
|
ˆ |
(4.1) |
L(B) = L(bi) · P (bi) бит/отсчет, |
|
=1 |
|
B — последовательность отсчетов (источник данных), которые могут принимать одно из значений bi с вероятностями P (bi).
Нижняя граница величины ˆ определяется информационной теоремой и на-
L
зывается энтропией случайной величины [2.1–2.6]. Если энтропия H(S) измеряется в битах, то
|
I |
|
|
i |
ˆ |
H(B) = − |
P (bi) · log2 P (bi) бит/отсчет |
L. |
|
=1 |
|
Таким образом, энтропия — это мера количества информации, которую несет случайная величина. H(B) 0, поскольку P (bi) [0, 1]. Из формулы H(B) вытекает, что чем более неравномерно распределение P (bi), тем меньше энтропия
итем эффективнее энтропийное кодирование.
Вслучае, когда уровни яркости появляются равновероятно, энтропия максимальна и равна
H(B)max = log2 I.
По аналогии с определением энтропии вводится понятие избыточности как меры определенности (неслучайности) информации. Ее относительная величина определяется формулой:
H(B) |
|
R(B) = 1 − H(B)max . |
(4.2) |
Глава 4. Статистическая избыточность дискретизированных данных
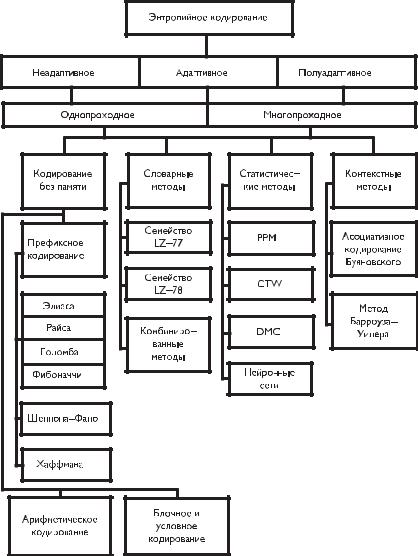
Эффективность методов устранения статистической избыточности, называемых энтропийным или экономным кодированием, зависит от выбранной расчетной модели источника информации. На рис. 4.1 приведена классификация методов энтропийного кодирования.
Рис. 4.1. Классификация методов устранения статистической избыточности |
Методы энтропийного кодирования делят на адаптивные и неадаптивные. |
В неадаптивных методах способ кодирования не меняется в процессе обработки |
4.2. Виды статистического кодирования
данных, а в адаптивных методах кодирование подстраивается под изменяющиеся статистические характеристики потока входных данных.
При использовании неадаптивного варианта алгоритма необходимо передать на декодирующую сторону таблицу распределения вероятностей. При адаптивном варианте кодирования таблица распределения вероятностей пересчитывается как на передающей, так и на приемной стороне по мере поступления данных. Существуют также полуадаптивные алгоритмы, при которых применяют некоторые подобранные способы кодирования и хранят их описание вместе с закодированной информацией.
Алгоритмы кодирования могут быть однопроходными и многопроходными, т. е. требующими сбора предварительной информации об обрабатываемых данных до начала непосредственного процесса кодирования. В связи с этим процесс обработки информации зачастую состоит из двух этапов — моделирования, используемого для оценки дерева вероятностей информационного поля, и собственно кодирования источников данных без памяти.
Методы кодирования источников данных без памяти включают префиксное кодирование и арифметическое кодирование. Повышение эффективности этих методов связано с применением блочного и условного кодирования.
Наиболее известные методы префиксного кодирования — хорошо исследованные схемы кодирования целых чисел Элиаса, Райса, Голомба, Фибоначчи [2.7–2.11], алгоритмы Шеннона–Фано [2.2, 2.12], Хаффмана [2.13].
Основой арифметического кодирования послужил алгоритм П. Элайеса. Существенный вклад в его развитие в разное время внесли Р. Паско [2.14], Д. Риссанен, Г. Лэнгдон и В. Пеннебакер [2.15–2.18], Ф. Рубин [2.19], М. Гуаззо [2.20], Г. Мартин [2.21], Д. Клири, И. Уиттен, Э. Моффат и Р. Нил [2.22, 2.23], П. Говард [2.24].
Снижение битового потока возможно при применении блочного и условного кодирования [2.4], т. е. кодирование и передача информации блоками из значительного количества отсчетов.
Специфическими особенностями обладают словарные, статистические и контекстные методы кодирования информации.
Идея словарных методов кодирования, к которым относятся классические схемы Зива–Лемпела и их многочисленные модификации [2.6, 2.25–2.39], заключается в том, что входные символы и группы символов преобразуются в индексы некоторого словаря, формируемого по заданному алгоритмом закону.
В основе статистических методов моделирования (PPM, CTW, DMC, нейронные сети) лежит принцип оценки и использования условных вероятностей появления символов в сообщении, рассчитываемых путем статистического анализа информационной выборки [2.40-2.53].
Очень интересны контекстные методы ассоциативного кодирования Буяновского [2.54] и Барроуза–Уиллера [2.55], являющиеся оптимальными при кодировании информации, обладающей значительной избыточностью.
4.2.1.Методы представления целых чисел
Вбольшинстве случаев модель источника информации неизвестна, и поэтому выбор и эффективность использования тех или иных методов кодирования входной последовательности элементов алфавита зависит от вероятности их появления.
Глава 4. Статистическая избыточность дискретизированных данных
Основная идея методов представления целых чисел состоит в том, чтобы отдельно хранить порядок значения элементов Xi («экспоненту» Ei) и отдельно — значащие цифры значения («мантиссу» Mi).
Эти методы чаще всего применяются в случаях, когда объем и свойства входных данных заранее неизвестны. Экспонента значений элементов при этом обычно представляется в виде унарного кода a(n), представляющего число n в виде подряд идущих n единиц, заканчивающихся контрольным нулем, либо в виде набора n нулей, за которыми следует контрольная единица (табл. 4.1).
Таблица 4.1. Унарные коды
Код числа |
Унарные коды |
|
0 |
0 |
1 |
|
|
|
1 |
10 |
01 |
|
|
|
2 |
110 |
001 |
3 |
1110 |
0001 |
|
|
|
4 |
11110 |
00001 |
|
|
|
5 |
111110 |
000001 |
. . . |
. . . |
. . . |
|
|
|
Гамма- и дельта-коды Элиаса (Elias γ and δ codes) генерируются по правилам, приведенным в табл. 4.2.
Для диапазона значений [2k, 2k+1 −1] числа n коды формируются следующим образом:
–гамма-код: унарное представление числа k (k нулей и единица), за которым следует двоичное представление (бинарный код) числа (n − 2k) (в таблице обозначено «x»); длина кода — 2k + 1 бита;
–дельта-код: гамма-код Элиаса для числа (k + 1) (т. е. количества битов дво-
ичного представления чисел заданного диапазона значений), за которым следует двоичное представление числа (n − 2k) (в таблице обозначено «x»);
длина кода — 2L + k + 1 бита, где L = [log2(k + 1)] — целая часть значения логарифма числа (k + 1) по основанию 2.
Таблица 4.2. Гамма- и дельта-коды Элиаса
Диапазон |
Гамма-коды Элиаса |
Длина кода, бит |
Дельта-коды Элиаса |
Длина кода, бит |
1 |
1 |
1 |
1 |
1 |
|
|
|
|
|
2. . . 3 |
01х |
3 |
010х |
4 |
|
|
|
|
|
4. . . 7 |
001хх |
5 |
011хх |
5 |
8. . . 15 |
0001ххх |
7 |
00100ххх |
8 |
|
|
|
|
|
16. . . 31 |
00001хххх |
9 |
00101хххх |
9 |
32. . . 63 |
000001ххххх |
11 |
00110ххххх |
10 |
64. . . 127 |
0000001хххххх |
13 |
00111хххххх |
11 |
|
|
|
|
|
128. . . 255 |
00000001ххххххх |
15 |
0001000ххххххх |
14 |
|
|
|
|
|
Коды Голомба (Golomb codes) — семейство двоичных префиксных кодов представления натуральных чисел (с нулем). Коды различаются одним параметром — величиной m.
Для кодирования символа с номером n необходимо представить этот номер в виде n = qm + r, где qи r — целые положительные числа, 0 r < m.
4.2. Виды статистического кодирования
Кодируемое число разбивается на две независимо кодируемые части: частное и остаток от деления на m: q = [n/m] и rn − mq.
Частное q кодируется унарным кодом, а остаток r, представляющий собой число в диапазоне [0, . . . , m −1], кодируется бинарным кодом длиной [log2 m]. Полученные двоичные последовательности объединяются в результирующее слово.
Например: положим, параметр кода m = 4 и кодируемое число n=13. Тогда частное от деления кодируемого числа на параметр кода q = [n/m] = [13/4] = 3 и унарный код a(q)a(3) = 1110. Поскольку остаток от деления кодируемого числа на m равен rn − m · q = 13 − 4 · 3 = 1 и представляет собой число в диапазоне [0, . . . , m − 1] = [0, . . . , 3], бинарный код b(r)b(1) = 01. Следовательно, результирующее кодовое слово равно a(q)|b(r)a(3)|b(1) = 1110|01.
Коды Райса (Rice codes) — частный случай кодов Голомба, когда m является степенью двойки.
Коды Райса различаются параметром k, связанным со значением m соотношением m = 2k. Следовательно, если k = 0, то m = 1, и коды Голомба и Райса соответствуют стандартному унарному коду a(n).
Омега-коды Элиаса и коды Ивен–Роде (Elias ω and Even–Rodeh codes) состоят из последовательности групп длинной L1, L2, L3, . . . , Lm битов, которые начинаются с бита 1, а в конце последовательности следует 0. Примеры генерации омега-кодов Элиаса и кодов Ивен–Роде приведены в табл. 4.3. Символы «ххх» обозначают двоичное представление числа.
Длина каждой следующей (n + 1)-й группы задается значением битов предыдущей n-й группы. Значение битов последней группы является итоговым значением всего кода, т. е. всей последовательности групп. В сущности, все первые m − 1 групп служат лишь для указания длины последней группы.
Таблица 4.3. Омега-коды Элиаса и коды Ивен–Роде
Диапазон |
Омега-коды Элиаса |
Длина кода, бит |
Коды Ивен–Роде |
Длина кода, бит |
0 |
– |
– |
000 |
3 |
|
|
|
|
|
1 |
0 |
1 |
001 |
3 |
|
|
|
|
|
2. . . 3 |
хх 0 |
3 |
0хх |
3 |
4. . . 7 |
10 ххх 0 |
6 |
ххх 0 |
4 |
|
|
|
|
|
8. . . 15 |
11 хххх 0 |
7 |
100 хххх 0 |
8 |
|
|
|
|
|
16. . . 31 |
10 100 ххххх 0 |
11 |
101 ххххх 0 |
9 |
32. . . 63 |
10 101 хххххх 0 |
12 |
110 хххххх 0 |
10 |
|
|
|
|
|
64. . . 127 |
10 110 ххххххх 0 |
13 |
111 ххххххх 0 |
11 |
|
|
|
|
|
128. . . 255 |
10 111 хххххххх 0 |
14 |
100 1000 хххххххх 0 |
16 |
256. . . 511 |
11 1000 ххххххххх 0 |
16 |
100 1001 ххххххххх 0 |
17 |
|
|
|
|
|
В омега-кодах Элиаса длина первой группы — 2 бита. Длина следующей группы на единицу больше значения предыдущей. Первое значение (1) задается отдельно. В кодах Ивен–Роде длина первой группы — 3 бита, а длина каждой последующей группы равна значению предыдущей. Первые четыре значения (0–3) заданы особым образом.
Из таблицы видно, что как двоичное представление числа Lm, так и коды длин L1, . . . , Lm−1 всегда начинаются с единицы, как было указано выше.
Коды Фибоначчи (Fibonacci codes) основаны на использовании представления любого натурального числа n в виде суммы чисел Фибоначчи fi (f1 = 1;