

12.Як визначається час виконання паралельного алгоритму?
Б![]()
![]() езліч
операцій, виконувані в досліджуваному
алгоритмі рішення обчислювальної
задачі, і інформаційні залежності, що
існують між операціями, можуть бути
представлені у вигляді ациклічного
орієнтованого графа
езліч
операцій, виконувані в досліджуваному
алгоритмі рішення обчислювальної
задачі, і інформаційні залежності, що
існують між операціями, можуть бути
представлені у вигляді ациклічного
орієнтованого графа
- безліч вершин графа, що представляють виконувані операції алгоритму
R - безліч дуг графа; дуга r(i,j) належить графові тільки якщо операція j використовує результат виконання операції i
Вершини без вхідних дуг можуть використовуватися для завдання операцій введення, а вершини без вихідних дуг – для операцій висновку.
V – безліч вершин графа без вершин введення,
D(G) – діаметр графа (давжина максимального шляху)
М![]()
![]() одель
паралельного алгоритму:
одель
паралельного алгоритму:
Час виконання паралельного алгоритму з заданим порядком:
Час виконання параллельного алгоритму з оптимальним порядком:
![]()
Мінімально можливий час розвязку задачі при заданій кількості процесів:
![]()
![]()
О![]() цінка
найбільш швидкого виконання алгоритму:
цінка
найбільш швидкого виконання алгоритму:
ч![]() ас
виконання послідовного алгоритму для
заданої розрахункової схеми:
ас
виконання послідовного алгоритму для
заданої розрахункової схеми:
Час виконання послідовного алгоритму:
Ч![]() ас
послідовного розрахунку задачі:
ас
послідовного розрахунку задачі:
Рекомендації
–при виборі обчислювальної схеми алгоритму повинен використовуватися граф з мінімально можливим діаметром
–для паралельного виконання доцільна кількість процесорів визначається величиною p~T1/T∞
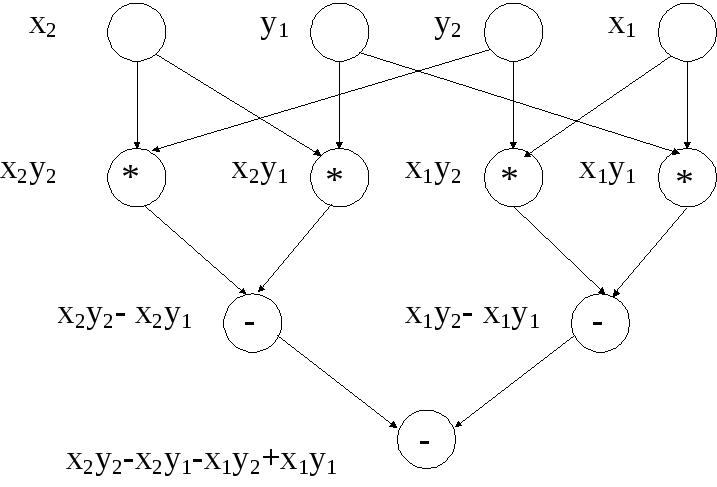
13. Мінімальний можливий час виконання паралельного алгоритму визначається довжиною максимального шляху обчислювальної схеми алгоритму:
При зменшенні числа використовуваних процесорів час виконання алгоритму збільшується пропорційно величині зменшення кількості процесорів, тобто :
![]()
при виборі обчислювальної схеми алгоритму повинен використовуватися граф з мінімально можливим діаметром
П риклад:
граф алгоритму обчислення площі
прямокутника, заданого координатами
двох кутів, що протилежать
риклад:
граф алгоритму обчислення площі
прямокутника, заданого координатами
двох кутів, що протилежать
14. Основною характеристикою алгоритму, визначальною ефективність його виконання на багатопроцесорній системі є його ступінь паралелізму.
Принциповий момент при розробці паралельних алгоритмів - аналіз ефективності використання паралелізму:
- Оцінка ефективності розпаралелювання конкретних вибраних методів виконання обчислень
- Оцінка максимально можливого прискорення процесу рішення даної задачі (аналіз всіх можливих способів виконання обчислень)
Ступенем паралелізму алгоритму називають число дій алгоритму, які можуть виконуватися одночасно, кожен на своєму процесорі.
Підкреслимо, що ступінь паралелізму не залежить від числа процесорів, на яких передбачається виконувати відповідну програму. Ступінь паралелізму є внутрішньою властивістю вибраного алгоритму. Від числа процесорів залежить тільки час виконання реальної програми при її запуску на цих процесорах.
Можна зробити вивід про те, що прискорити виконання програми більше чим в число разів, визначуване ступенем паралелізму її алгоритму, не можна.
15. Ефективність паралельних обчислень сильно залежить від об'єму обміну у виконуваному застосуванні і від свойст коммуникатора. Щоб оцінити цей вплив, постороїм деяку формульную модель виконання додатку на кластері.Як модель обчислень ухвалимо мережевий закон Амдала. Мережевий закон Амдала володіє великими можливостями розширення і дозволяє врахувати витрати часу на міжпроцесорний обмін даними. У окремому випадку він може виглядати так:
Т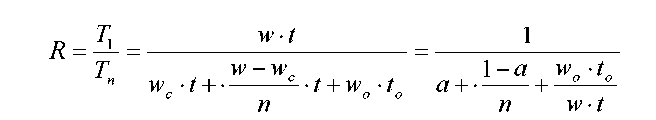 ут:T1
- час вирішення додатку на однопроцесорній
системі; Tn
- час
вирішення того ж застосування на n
-
процесорній системі; w
-число
обчислювальних операцій в додатку; wс
-число скалярних
операцій в пріложенійі; wо
- число
операцій обміну; t
- час
виконання однієї обчислювальної
операції; tо
-
время виконання однієї операції обміну;
а
- питома
вага операцій обміну.
ут:T1
- час вирішення додатку на однопроцесорній
системі; Tn
- час
вирішення того ж застосування на n
-
процесорній системі; w
-число
обчислювальних операцій в додатку; wс
-число скалярних
операцій в пріложенійі; wо
- число
операцій обміну; t
- час
виконання однієї обчислювальної
операції; tо
-
время виконання однієї операції обміну;
а
- питома
вага операцій обміну.
О![]() крім
прискорення для характеристики
ефективності обчислень часто використовують
коефіцієнт використання процесорного
часуh,
який
по суті є коефіцієнтом корисної дії
процесорів (ККД):
крім
прискорення для характеристики
ефективності обчислень часто використовують
коефіцієнт використання процесорного
часуh,
який
по суті є коефіцієнтом корисної дії
процесорів (ККД):
Цей параметр дозволяє оцінити масштабованість кластера. Під масштабованістю розуміють ступінь збереження ефективності при зміні розмірів системи (числа процесорів або розміру даних).
Для простоти покладемо а=0, тоді
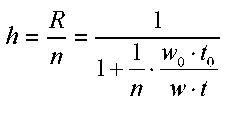
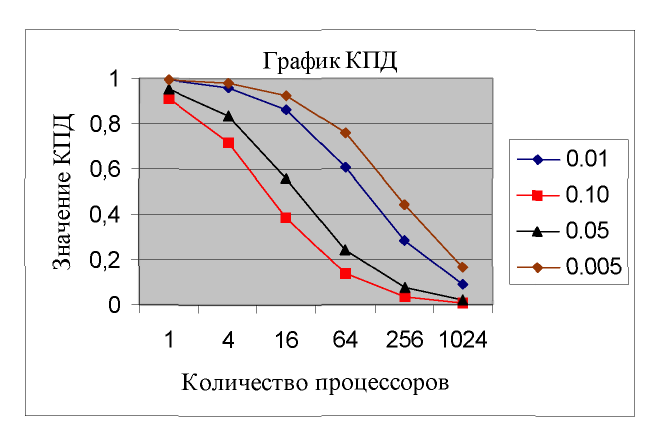
Досліджуємо на цьому спрощеному варіанті мережевого закону Амдала, як міняється ефективність обчислень при збільшенні числа процесорів. Для багатьох завдань відношення часу обміну до часу рахунку
![]()
Відповідний графік для цього діапазону зміни z приведений нижче. Зазвичай вважають, що ККД не має бути нижче 0.5. З графіка видно, що цій умові в кращому разі задовольняють 256 процесорів.
Значення z в сильному ступені визначається характеристиками коммуникатора, тобто величиною wo∙ to. Тому можна допустити, що крива для wo∙ to =0.10 відповідає комунікатору Fast Ethernet, а крива wo∙to = 0.005 - швидшому комунікатору, наприклад, SCI.