

69.Навести і описати паралельні методи розв'язання диференціальних рівнянь у частинних похідних.
Завдання Пуассона, тобто рішення диференціальних рівнянь в приватних похідних, виражається наступними рівняннями:
![]() -
усередині області
(8.1)
-
усередині області
(8.1)
![]() -
на межі
(8.2)
-
на межі
(8.2)
Вважатимемо, що область рішення є квадратною. Щоб знайти наближене рішення, визначимо квадратну сітку, включає точки (хі. уі), що задаються як
![]()
Таким чином, уздовж кожного краю сітки є п+2 точки. Слід знайти апроксимацію и(х,у) в точках (хі,, уі) вибраної сітки. Позначимо через иij значення і u (xi, yj), через h відстань мiж точками, рівне 1/(n+1). Тоді формула 8.1. для кожної з точок виглядатиме таким чином:
![]()
Обчислюємо значення uij в кожній точці сітки, які заміщують попередні значення, використовуючи вираз
![]()
Цей процес називається ітераціями Якобі і повторюється до отримання результату. Фрагмент програми для цього випадку такий:
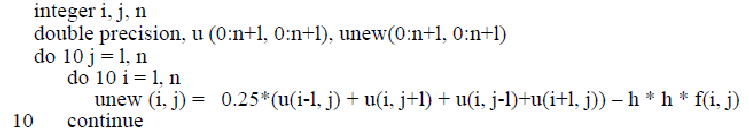
70.---
71. У вихідному коді програми на мові с вставити пропущені виклики процедур підключення мрі, визначення кількості процесів і рангу процесів.
#include "mpi.h"
#include <stdio.h>
int main (int argc, char *argv[])
{
int myid, numproc;
MPI_Status status;
MPI_Init ( &agrc &argv );
MPI_Comm_size (MPI_COMM_WORLD &numproc);
MPI_Comm_rank (MPI_COMM_WORLD &myid);
fprintf(stdout,”Process%d of %d\n”,myid,numproces);
MPI_Finalesize();
return 0;
}
72. Програма, яка виводить «Hello Word from process I for n».
#include "mpi.h"
#include <stdio.h>
int main (int argc, char *argv[])
{
int myid, numproc;
MPI_Status status;
MPI_Init ( &agrc &argv );
MPI_Comm_size (MPI_COMM_WORLD &numproc);
MPI_Comm_rank (MPI_COMM_WORLD &myid);
fprintf(stdout,”Hello World from process%d for %d\n”,myid,numproces);
MPI_Finalesize();
return 0;
}
73. Програма генерації чисел в одному процесі і сумування їх у іншому процесі і надсилення результату в перший процес.
74.---
75.---
76.---
77.---
78. Навести приклад найпростішої програми на мові С з використанням технології OpenMP, яка виводить прізвище студента.
int main ()
{ #pragma omp parallel
{ printf (“…………”);
} return 0;
}
79.---
80. Написати програму з використанням бібліотеки OpenMP на мові С/С++ для вимірювання часу cумування квадратів чисел від 0 до 10000000. Для усереднення накладних витрат повторити достатню кількість операцій обчислення з метою отримання значень часу в межах доль секунди, повторити тестування декілька разів (наприклад, 10) і усереднити результати. А також написати аналогічну програму без бібліотеки OpenMP на мові C/C++ та виконати аналогічні дії по визначенню часу роботи програми. Порівняти отримані значення часу.
Пример 2 иллюстрирует применение функций omp_get_wtime() и
omp_get_wtick() для работы с таймерами в OpenMP. В данном примере
производится замер начального времени, затем сразу замер конечного време-
ни. Разность времён даёт время на замер времени. Кроме того, измеряется
точность системного таймера.
#include <stdio.h>
#include <omp.h>
int main(int argc, char *argv[])
{
double start_time, end_time, tick;
start_time = omp_get_wtime();
end_time = omp_get_wtime();
tick = omp_get_wtick();
printf("Время на замер времени %lf\n", end_time-start_time);
printf("Точность таймера %lf\n", tick);
}
Пример 2a. Работа с системными таймерами на языке Си.
program example2b
include "omp_lib.h"
double precision start_time, end_time, tick
start_time = omp_get_wtime()
end_time = omp_get_wtime()
tick = omp_get_wtick()
print *, "Время на замер времени ", end_time-start_time
print *, "Точность таймера ", tick
end
кажись ця канає… якшо нє то шось мутити тре з тою шо вище
#include <stdio.h>
#include <iostream>
#include <omp.h>
using namespace std;
int i,s;
double time,start;
//Тіло програми
main()
{
//Розпаралелення
start = clock();
omp_set_num_threads(50);
#pragma omp parallel
{
for( int i=0; i<=10000000; ++i)
{
s+=pow(i,2)
};
};
time = clock() - start;
printf( "%g\t\n", s, time );
return 0;
}
81.
Написати
програму з використанням бібліотеки
OpenMP на мові С/С++ обчислення числа
![]() методом чисельного інтегрування (метод
середніх прямокутників).
методом чисельного інтегрування (метод
середніх прямокутників).
#include <stdio.h>
#include <omp.h>
int main ()
{
int n =100000, i;
double pi, h, sum, x;
h = 1.0 / (double) n;
sum = 0.0;
#pragma omp parallel default (none) private (i,x) shared (n,h,sum)
{
int id = omp_get_thread_num();
int numt = omp_get_num_threads();
for (i = id + 1; i <= n; i=i+numt)
{
x = h * ((double)i - 0.5);
sum += (4.0 / (1.0 + x*x));
}
}
pi = h * sum;
printf("pi is approximately %.16f”, pi);
return 0;
}
![]()
![]()
82. Написати програму з використанням бібліотеки OpenMP на мові С/С++ додавання двох матриць. Матриця заповнюється значеннями з генератора псевдовипадкових чисел.
#include <stdio.h>
#include <iostream>
#include <omp.h>
using namespace std;
#define M 2
class vvid_N {
public:
double array[N][N];
void Str();
};
//Метод
void vvid_M::Str() {
for( int i=1; i<=N; ++i )
array
for( int j=1; j<=N; ++j )
{
for(int i=0; i<n; i++)
for(int j=0; j<m; j++)
array[i][j]=0+rand()%10;
};
}
//Тіло програми
main()
{
//Введення матриць
vvid_N arrayA, arrayB, arrayZ;
cout << "\t\tМатриця А\n";
arrayA.Str();
cout << "\t\tМатриця B\n";
arrayB.Str();
cout << "\t\tМатриця C\n";
arrayC.Str();
//Розпаралелення
omp_set_num_threads(4);
#pragma omp parallel
{
//Цикл обрахунку матриць
for( int a=0; a<N; ++a)
for( int b=0; b<<N; ++b)
{
arrayZ.array[a][b]=arrayA.array[a][b]+arrayB.array[a][b];
};
};
//Цикл виводу матриці
for( int a=1; a<=N; ++a){
for( int b=1; b<=N; ++b){
printf( "%g\t\n", arrayZ.array[a][b] );
}
};
return 0;
}
83---
84---
85---
86---
87---