

63.Навести основні етапи розробки паралельних алгоритмів.
Процес розробки паралельних алгоритмів можна розбити на такі складові:
декомпозиція (аналіз задачі, оцінка можливості її розпаралелювання, розбиття на підзадачі та фрагменти структур даних);
проектування обміну даними між задачами (визначення комунікацій необхідних для пересилання вихідних даних та результатів виконання підзадач);
об’єднання підзадач (згортка з метою виконування більш великих блоків, підвищення ефективності алгоритму його трансформація та оптимізація);
планування обчислень (розподіл задач між вузлами кластера з метою їх ефективного використання та мінімізації накладних витрат часу на обмін даними).
64.---
65.Навести і описати паралельні методи множення матриць.
Приклад реалізує найпростішу програму, що реалізовує перемножування двох квадратних матриць. В програмі заміряється час на основний обчислювальний блок, що не включає початкову ініціалізацію. В основному в обчислювальному блоці програми на мові Фортран змінений порядок циклів з параметрами i і j для кращої відповідності правилам розміщення елементів масивів.
#include <stdio.h>
#include <omp.h>
#define N 4096
double а[N][N], b[N][N], з[N][N];
int main()
{
int i, j, до;
double t1, t2;
// ініціалізація матриць
for (i=0; i<N; i++)
for (j=0; j<N; j++)
а[i][j]=b[i][j]=i*j;
t1=omp_get_wtime();
// основний обчислювальний блок
#pragma omp parallel for shared(а, b, з) private(i, j, до)
for(i=0; i<N; i++){
for(j=0; j<N; j++){
з[i][j]= 0.0;
for(k=0; k<N; k++) з[i][j]+=a[i][k]*b[k][j];
}
}
t2=omp_get_wtime();
printf("Time=%lf\n", t2-t1);
}
Приклад 31a. Перемножування матриць на мові С.
program matrmult
include "omp_lib.h"
integer N
parameter(N=4096)
common /arr/ а, b, з
double precision а(N, N), b(N, N), з(N, N)
integer i, j, до
double precision t1, t2
З ініціалізація матриць
do i=1, N
do j=1, N
а(i, j)=i*j
b(i, j)=i*j
end do
end do
t1=omp_get_wtime()
основний обчислювальний блок
!$omp parallel do shared(а, b, з) private(i, j, до)
do j=1, N
do i=1, N
з(i, j)= 0.0
do k=1, N
з(i, j)=c(i, j)+a(i, до)*b(до, j)
end do
end do
end do
t2=omp_get_wtime()
print *, "Time=", t2-t1
end
Приклад 31b. Перемножування матриць на мові Фортран
66. Навести і описати паралельні методи розв'язку систем лінійних рівнянь.
Лінійне рівняння з n невідомими
Безліч n лінійних рівнянь називається системою лінійних рівнянь або лінійною системою
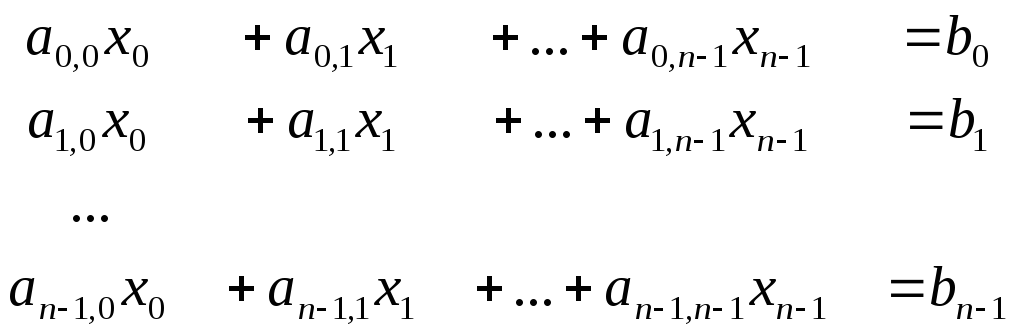
![]()
В матричной форме:
Під задачею рішення системи лінійних рівнянь для заданих матриці А і вектора b розуміється знаходження значення вектора невідомих x, при якому виконуються всі рівняння системи.
Метод Гауса - паралельний алгоритм
Масштабування і розподіл підзадач по процесорах
Основним видом інформаційної взаємодії підзадач є операція передачі даних від одного процесора всім процесорам обчислювальної системи
Як результат, для ефективної реалізації необхідних інформаційних взаємодій між базовими підзадачами, топологія мережі передачі даних повинні мати структуру гиперкуба або повного графа.
Метод зв'язаних градієнтів
Метод зв'язаних градієнтів може бути застосований для вирішення системи лінійних рівнянь з симетричною, позитивно визначеною матрицею
Матриця А є симетричною, якщо вона співпадає з своєю транспонованою матрицею
тобто А=АТ
Матриця А називається позитивно визначеною, якщо для будь-якого вектора x справедливе: xTAx>0.
Після виконання n ітерацій методу зв'язаних градієнтів (n є порядок вирішуваної системи лінійних рівнянь), чергове наближення xn співпадає з точним рішенням.