

Вказівки до лаб_2010
.pdfРис. 57. Діалогове вікно Regression.
∙Іnput Y Range — діапазон значень змінної Y ;
∙Іnput X Range — діапазон значень змінної X ;
∙Labels — відмітити цю опцію лише в тому випадку, коли значення змінних
X та Y в полях Іnput Y Range та Іnput X Range вводяться разом із заголовками X та Y ;
∙Constant is Zero — відмітити цю опцію лише в тому випадку, коли припуска-
ється, що вільний член рівняння регресії β0 = 0 ;
∙Confidence Level — цю опцію виставити тільки в тому випадку, коли потрібно знайти не тільки 95%-ні довірчі інтервали для коефіцієнтів регресії, а й
90%-ні, 98%-ні, 99%-ні тощо;
∙Output Range — адреса результуючої клітинки.
Зауважимо, що для більш повного аналізу регресійної моделі можна розглядати в діалоговому вікні Regression елементи Residuals (для аналізу залишків) та Normal Probability (для порівняння з нормальним розподілом).
71
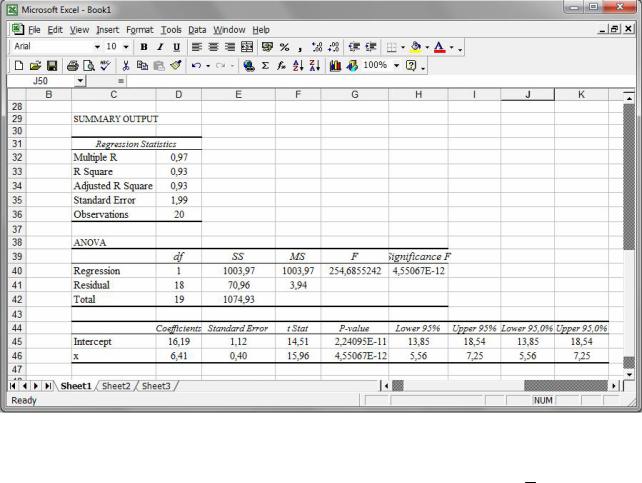
Крок 8. Натиснути ОК та проаналізувати отримані результати (рис. 58).
Рис. 58. Моделювання лінійної регресії.
Оскільки p -значення 4,55×10−12 для коефіцієнта регресії β1 та критерію Фішера не перевищує заданого в умові рівня значущості α = 0,05 , то знайдене рівняння регресії yˆx = 16,19 + 6,41x вважається адекватним до результатів спо-
стережень.
Крок 9. Оскільки побудована регресійна модель виявилась адекватною на рівні α = 0,05 , знайдемо прогнозне значення прибутку при заданих в умові ре-
кламних витратах x0 = 5,0 . Для цього достатньо в знайдене рівняння регресії замість x підставити значення x0 = 5,0 :
y€0 = y€x (x0 ) = y€x (5,0) =16,19 + 6,41×5,0 » 48,3.
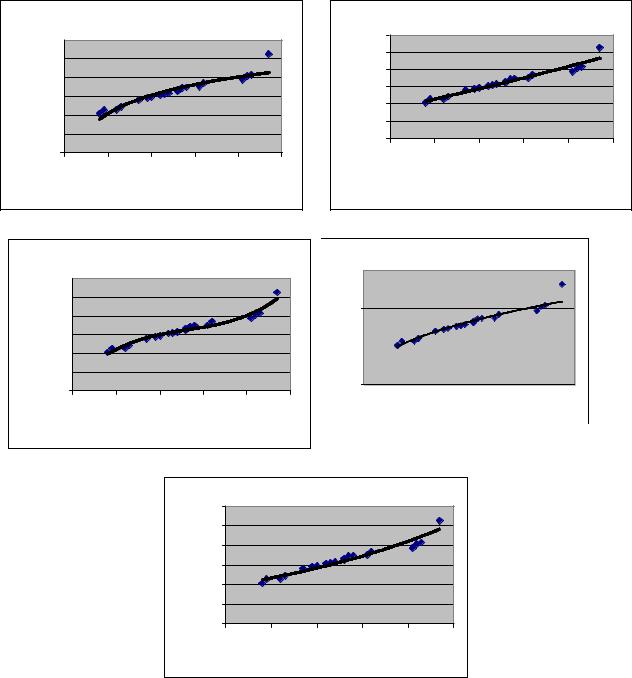
Крок 10. Побудувати на діаграмі розсіювання лінії логарифмічного, квадратичного, кубічного, степеневого та показникового тренду. Для кожного з них записати ві дповідне рівняння регресії та коефіцієнт детермінації
(рис. 59 а-д).
72
|
|
Логарифмічний тренд |
|
|
||
|
60,0 |
y = 13,97Ln(x) + 20,968 |
|
|||
|
50,0 |
|
||||
Прибутки |
|
R2 = 0,8691 |
|
|
||
40,0 |
|
|
|
|||
|
|
|
|
|
||
30,0 |
|
|
|
|
|
|
20,0 |
|
|
|
|
|
|
10,0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,0 |
|
|
|
|
|
|
0,0 |
1,0 |
2,0 |
3,0 |
4,0 |
5,0 |
|
|
|
Рекламні витрати |
|
|
|
|
|
Квадратичний тренд |
|
|||
|
60,0 |
y = 0,1582x2 |
+ 5,5453x + 17,172 |
|
||
|
50,0 |
|
||||
Прибутки |
|
R2 |
= 0,9348 |
|
|
|
40,0 |
|
|
|
|||
|
|
|
|
|
||
30,0 |
|
|
|
|
|
|
20,0 |
|
|
|
|
|
|
10,0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,0 |
|
|
|
|
|
|
0,0 |
1,0 |
2,0 |
3,0 |
4,0 |
5,0 |
|
|
|
Рекламні витрати |
|
|
|
|
|
|
а |
|
|
|
|
|
|
|
б |
|
|
|
|
|
Кубічний тренд |
|
|
|
|
Степеневий тренд |
|
|
|||
|
60,0 |
|
|
|
|
|
|
60,0 |
|
|
|
|
|
|
|
3 |
2 |
+ 24,88x + 4,5617 |
|
50,0 |
y = 22,005x0,4424 |
|
|
|
|||
|
50,0 |
|
|
R2 |
= 0,9463 |
|
|
|
|||||
|
y = 1,0321x |
- 8,1139x |
|
|
|
|
|
||||||
Прибутки |
40,0 |
|
|
R2 = 0,9604 |
|
Прибутки |
40,0 |
|
|
|
|
|
|
|
|
|
|
|
30,0 |
|
|
|
|
|
|||
30,0 |
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
20,0 |
|
|
|
|
|
|||
20,0 |
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
10,0 |
|
|
|
|
|
|||
10,0 |
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
0,0 |
|
|
|
|
|
|
|
0,0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,0 |
1,0 |
2,0 |
3,0 |
4,0 |
5,0 |
|
|
0,0 |
1,0 |
2,0 |
3,0 |
4,0 |
5,0 |
|
||||||
|
|
|
|
Рекламні витрати |
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
||
Рекламні витрати
в |
г |
|
60,0 |
Показниковий тренд |
|
|
||
|
y = 19,278e0,1955x |
|
|
|
||
|
50,0 |
|
|
|
||
|
R2 = 0,9442 |
|
|
|
||
Прибутки |
40,0 |
|
|
|
||
|
|
|
|
|
||
30,0 |
|
|
|
|
|
|
20,0 |
|
|
|
|
|
|
|
10,0 |
|
|
|
|
|
|
0,0 |
|
|
|
|
|
|
0,0 |
1,0 |
2,0 |
3,0 |
4,0 |
5,0 |
|
|
|
Рекламні витрати |
|
|
|
д
Рис. 59. Нелінійні регресійні моделі.
Висновок. У цьому завданні ми досліджували двовимірну вибірку об’єму n = 20, причому увага акцентувалася на виявленні лінійного кореляційного зв’язку між ознаками генеральної сукупності „Прибутки” (значення yi ) та „Ре-
кламні витрати” (значення xi ). Оскільки рекламні витрати впливають на се-
реднє значення прибутку компанії, то вважаємо, що змінна X відповідає фак-
73

торній ознаці генеральної сукупності, а змінна Y — результативній. Іншими словами, в нашому випадку X — незалежна змінна, Y — залежна.
Побудова діаграма розсіювання вибіркових значень дозволяє висловити припущення, що між ознаками генеральної сукупності таки існує лінійний кореляційний зв’язок, причому коефіцієнт кореляції буде додатним. Побудова лінії тренду дозволяє знайти аналітичну форму залежності між досліджуванми
ознаками: вибіркове лінійне рівняння регресії |
приблизно матиме вигляд |
yˆx = 6,408x +16,195 , а коефіцієнт детермінації R2 |
» 0,934. Дослідження цієї ре- |
гресійної моделі на адекватність можна провести за допомогою процедури Regression надбудови Data Analysis.
Знайдений за функцією CORREL вибірковий коефіцієнт кореляції ρ ≈ 0,97 досить близький за значенням до 1, що вказує на щільний лінійний кореляційний зв’язок, і, крім того, він додатний, а це означає, що із збільшенням витрат на рекламу прибутки компанії в середньому зростають.
Знайдені за допомогою надбудови Data Analysis вибіркові коваріаційна
та кореляційна матриці є симетричними: |
|
|
|
|
|
|
|
|
||||
|
|
æ |
1,22 |
7,83 |
ö |
, |
|
|
æ |
1 |
0,97 |
ö |
S = ç |
7,83 |
53,75 |
÷ |
R = ç |
0,97 |
1 |
÷. |
|||||
è |
ø |
|
è |
ø |
||||||||
Можна зробити висновок, що змінна Y характеризується значно більшою варіацією порівняно зі змінною X (дисперсія змінної Y перевищує дисперсію
X більш, ніж у 44 рази: 53,75 1,22 = 44,1). Вибіркова коваріація cov ≈ 7,83 між змінними X та Y є абсолютною мірою щільності лінійного кореляційного зв’язку між ознаками генеральної сукупності. Діагональні елементи кореляційної матриці дорівнюють одиниці, а вибірковий коефіцієнт кореляції ρ ≈ 0,97 — додатний і досить близький до 1, що вказує на прямий (додатний)
1,22 = 44,1). Вибіркова коваріація cov ≈ 7,83 між змінними X та Y є абсолютною мірою щільності лінійного кореляційного зв’язку між ознаками генеральної сукупності. Діагональні елементи кореляційної матриці дорівнюють одиниці, а вибірковий коефіцієнт кореляції ρ ≈ 0,97 — додатний і досить близький до 1, що вказує на прямий (додатний)
зв’язок між досліджуваними ознаками, причому щільність цього зв’язку дуже велика. Навіть неозброєним оком можна помітити, що із збільшенням рекламних витрат середні прибутки компаній також збільшуються. Зауважимо, що
74

значення вибіркового коефіцієнта кореляції із кореляційної матриці та того, що знайдений за допомогою функції CORREL, збігаються.
За допомогою процедури Regression знайдено вибіркове лінійне рівняння регресії
yˆx = 16,19 + 6,41x .
Коефіцієнти цього рівняння β0 =16,19 та β1 = 6,41 є точковими оцінками коефіцієнтів β0 , β1 теоретичного рівняння регресії в генеральній сукупності.
Для побудованої лінійної регресійної моделі коефіцієнт детермінації
R2 ≈ 0,933, що свідчить про високу якість вибіркового рівняння регресії: при-
близно 93,3 % варіації (дисперсії) результативної ознаки пояснюється варіацією факторної ознаки. Решта 6,7 % варіації пояснюються впливом випадкових, не врахованих у моделі факторів. Значення виправленого коефіцієнта детермінації
%2 |
= 0,930 практично не відрізняється від R |
2 |
і точніше ха- |
(Adjusted R-square) R |
|
рактеризує частку варіації результативної ознаки, яка пояснюється регресією. Величина стандартної похибки рівняння регресії σε ≈ 1,99 може бути ви-
користана для вибору кращої регресійної моделі, побудованої на основі проведених спостережень.
Значущість теоретичних коефіцієнтів регресії β0 та β1 можна перевірити за критерієм Стьюдента: оскільки t -статистики для них (14,51 та 15,96) більші за критичне значення розподілу Стьюдента
tα ; n−2 = t0,05;18 = TINV(0,05;18) = 2,10 ,
то обидва коефіцієнти є значущими на рівні 0,05.
Довірчі інтервали для коефіцієнтів регресії β0 та β1 при заданому рівні довіри γ = 1−α = 0,95 мають вигляд
13,85 < β0 <18,54 ; 5,56 < β1 < 7,25.
Вони не „накривають” нуль, тому коефіцієнти β0 та β1 значущі на рівні
α = 0,05 .
75

Значущість коефіцієнта детермінації перевіряють за критерієм Фішера: оскільки спостережуване значення F -статистики 254,69 перевищує критичне Fα ;1; n−2 = F0,05;1;18 = 4,41, то це свідчить про значущість коефіцієнта детермінації.
Значущість коефіцієнтів регресії β0 та β1 можна перевірити також за до-
помогою p -значень: так як p -значення 2,24 ×10−11 та 4,55×10−12 не перевищу-
ють заданого в умові рівня значущості α = 0,05 , то обидва коефіцієнти є зна-
чущими на рівні 0,05. Аналогічно значущість коефіцієнта детермінації можна перевірити за допомогою p -значення для F -критерію:
Significance F = 4,55×10−12 < 0,05 ,
а це свідчить про значне відхилення коефіцієнта детермінації від нуля.
Для адекватності лінійної регресійної моделі достатньо, щоб був значу-
щим коефіцієнт регресії (нахилу) β1 або коефіцієнт детермінації R2 ( p -
значення для них є однаковими і дорівнюють 4,55×10−12 ). Отже, вибіркове лінійне рівняння регресії адекватне на рівні 0,05.
Адекватність побудованої регресійної моделі дає можливість проінтер-
претувати коефіцієнт регресії β1 та спрогнозувати значення залежної змінної при заданому x0 = 5,0 :
1)при збільшенні витрат на рекламу на 1 млн. дол. прибутки компаній зростають у середньому на 6,41 млн. дол., що свідчить про високу ефективність такого виділення коштів на рекламу;
2)при збереженні існуючої тенденції якщо витрати на рекламу компанії становитимуть 5,0 млн. дол., то за результатами лінійної регресії мож-
на сподіватися, що прибутки компанії складатимуть в середньому
48,3 млн. дол.
Діаграма розсіювання дозволяє також побудувати нелінійні регресійні моделі та знайти відповідні коефіцієнти детермінації:
·логарифмічне рівняння регресії yˆx = 20,97 +13,97 ×ln x ; R2 = 0,87;
·квадратичне рівняння регресії yˆx =17,17 + 5,54x + 0,16x2 ; R2 = 0,93;
76

∙кубічне рівняння регресії yˆx = 4,56 + 24,88x -8,11x2 +1,03x3 ; R2 = 0,96;
∙степеневе рівняння регресії yˆx = 22,01× x0,44 ; R2 = 0,95;
∙показникове рівняння регресії yˆx =19,28×e0,20 x ; R2 = 0,94.
Серед нелінійних регресійних моделей найбільший коефіцієнт детермінації — у кубічної, але вирішення питання адекватності цих моделей потребує детальнішого аналізу.
Лабораторна робота № 8
Множинна лінійна регресія
Основні поняття
Кореляція, за допомогою якої вивчається вплив на результативну ознаку двох та більше факторних ознак, називається множинною. Багатофакторні регресійні моделі дають змогу оцінювати вплив факторних ознак на середнє значення результативної ознаки.
При вивченні множинної кореляції можна застосовувати як лінійні, так і нелінійні рівняння регресії. При цьому важливою умовою придатності множинного рівняння регресії є відсутність лінійних кореляційних зв’язків між факторними ознаками.
При наявності k факторів вибіркове рівняння множинної лінійної ре-
гресії має вигляд
yˆ = β0 + β1x1 + β2x2 +... + βk xk ,
де β0 — вільний член рівняння регресії, β j ( j =1, k ) — коефіцієнти регресії,
які показують, на скільки одиниць збільшиться середнє значення результативної змінної Y при збільшенні факторної змінної X j на одну одиницю (за умови,
що значення всіх решта факторних змінних залишаються незмінними). Розглянемо рівняння множинної лінійної регресії з двома незалежними
змінними: yˆ = β0 + β1x1 + β2 x2 . Тоді коефіцієнт β1 показує зміну середнього зна-
77

чення результативної змінної Y при збільшенні X1 на одну одиницю, якщо значення фактора X2 залишається незмінним. І навпаки, β2 вказує, на скільки одиниць збільшиться середнє значення результативної змінної Y при збільшенні X2 на одну одиницю, якщо значення X1 залишиться незмінним.
Якщо задано n спостережень над результативною змінною Y та факторними змінними X1 , X2 :
|
Y |
|
y1 |
|
|
|
y2 |
... |
yi |
... |
yn |
, |
|
|
|
|
|||||
|
X1 |
|
x11 |
|
|
|
x12 |
... |
x1i |
... |
x1n |
|
|
|
|
||||||
|
X2 |
x21 |
|
|
|
x22 |
... |
x2i |
... |
x2n |
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
то на практиці коефіцієнти β0 , |
β1 , β2 |
рівняння регресії yˆ = β0 + β1x1 + β2 x2 , які є |
|||||||||||||||||||
точковими оцінками параметрів β0 , β1 та β2 теоретичного рівняння регресії,
знаходять із системи нормальних рівнянь Гаусса
ì |
|
|
|
|
|
n |
|
|
|
|
n |
n |
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
åx2i = |
åyi , |
||||||||||||
ïβ0 × n + β1åx1i + β2 |
||||||||||||||||||||||||
ï |
|
|
|
|
i=1 |
|
|
|
i=1 |
i=1 |
||||||||||||||
ï |
|
|
n |
|
|
n |
|
|
|
n |
n |
|||||||||||||
|
|
|
|
|
|
|||||||||||||||||||
íβ0 åx1i + β1åx12i + β2 åx1i x2i = åx1i yi , |
||||||||||||||||||||||||
ï |
|
|
i=1 |
i=1 |
|
|
i=1 |
i=1 |
||||||||||||||||
ï |
|
|
n |
|
|
n |
|
|
|
|
n |
n |
||||||||||||
ïβ0 |
åx2i + β1 |
åx1i x2i + β2 åx22i = åx2i yi . |
||||||||||||||||||||||
î |
|
|
i=1 |
i=1 |
|
|
|
|
i=1 |
i=1 |
||||||||||||||
Побудоване рівняння множинної лінійної регресії потрібно перевірити на |
||||||||||||||||||||||||
|
|
|
|
|
|
|
||||||||||||||||||
адекватність. Рівняння множинної лінійної регресії yˆ = β0 + β1x1 + β2 x2 назива- |
||||||||||||||||||||||||
ють адекватним для заданого рівня значущості α , якщо на цьому рівні значу-
щими виявляться коефіцієнти регресії β1 , β2 та коефіцієнт детермінації R2 .
Перевірку на значущість коефіцієнтів β1 та β2 проводять за критерієм Стью-
дента, а коефіцієнта детермінації R2 — за критерієм Фішера.
У випадку адекватності багатьох різних рівнянь регресії, побудованих на основі спостережуваних даних, перевага надається тому, для якого найбільшим є виправлений коефіцієнт детермінації R%2 .
78

Типове завдання
Відомі результати спостережень (змінна Y відповідає результативній
ознаці, X1 |
та X2 — факторним ознакам генеральної сукупності): |
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Y |
|
5,6 |
7,4 |
7,8 |
9,4 |
9,5 |
10,5 |
12,2 |
12,4 |
12,6 |
13,5 |
|
X1 |
|
5,5 |
3,7 |
3,6 |
5,5 |
7,1 |
3,6 |
6,0 |
5,6 |
3,7 |
6,6 |
|
X2 |
|
– 2,0 |
– 1,8 |
– 0,4 |
– 0,4 |
0,2 |
0,7 |
1,0 |
2,4 |
3,1 |
5,3 |
1.За допомогою надбудови Data Analysis знайти вибіркові коваріаційну та кореляційну матриці. Зробити висновки.
2.За допомогою процедури Regression надбудови Data Analysis знайти рівняння множинної лінійної регресії yˆ = β0 + β1x1 + β2 x2 . Дослідити знайде-
не рівняння регресії на адекватність (рівень значущості α = 5% ) та у випадку його адекватності зробити належні висновки.
3.Виключити по черзі одну з двох факторних змінних та побудувати вибіркові рівняння парної лінійної регресії yˆ = β0 + β1x1 та yˆ = β0 + β1x2 , здійснивши їх перевірку на адекватність. У випадку адекватності цих рівнянь зробити належні висновки.
4.Яка з побудованих адекватних моделей найкраще описує зміну середнього значення змінної Y ?
Хід роботи
Крок 1. Записати задану тривимірну вибірку у вигляді трьох стовпців, які відповідають змінним Y , X1 та X2 (рис. 60).
79
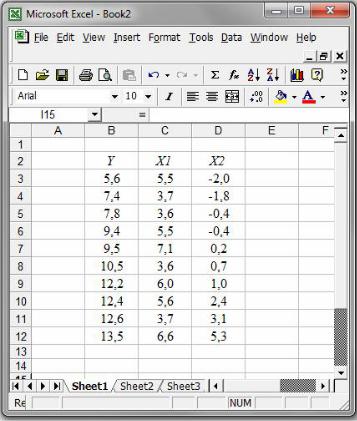
Рис. 60. Вхідні дані для лабораторної роботи № 8.
Крок 2. Для побудови вибіркових коваріаційної та кореляційної матриць потрібно викликати надбудову Data Analysis в меню Tools (як під’єднати надбудову Data Analysis у випадку її відсутності в Excel — див. с. 11) та скористатися в ній процедурами Covariance (для коваріаційної матриці) чи Correlation (для кореляційної матриці). Тоді в діалоговому вікні, в полі Іnput Range (рис. 61) необхідно ввести водночас діапазон клітинок для змінних Y , X1 , X2 , а
в полі Output Range — результуючу клітинку. При цьому бажано адреси комірок вводити разом із заголовками Y , X1 , X2 , а в діалоговому вікні відміти-
ти опцію Labels.
80