

Вказівки до лаб_2010
.pdfВибірковий метод у математичній статистиці полягає в тому, що результати, отримані для вибірки, переносяться на всю генеральну сукупність із достатньо високим ступенем точності.
Об’єм (обсяг) вибірки — це кількість елементів вибірки. Різні елементи вибірки називаються варіантами.
Ранжований ряд — послідовність елементів вибірки, записаних у порядку зростання. Зауважимо, що деякі елементи в ранжованому ряді можуть повторюватися по декілька разів.
Якщо елементи, які повторюються у ранжованому ряді, записати лише один раз, то отримаємо варіаційний ряд. Наприклад, для вибірки
9, 3, 2, 3, 5, 4, 7, 4, 5, 5
ранжованим рядом буде
2, 3, 3, 4, 4, 5, 5, 5, 7, 9,
а варіаційним рядом:
|
|
|
|
2, 3, 4, 5, 7, 9; |
|
|
|||
об’єм вибірки n =10 . |
|
|
|
|
|
|
|
|
|
Частота ni — кількість повторень елемента у вибірці. |
|||||||||
Відносна частота ω = ni |
— відношення n до обсягу вибірки n . |
||||||||
|
|
i |
n |
|
|
|
|
i |
|
|
|
|
|
|
|
|
|
|
|
Таблиця частот — це таблиця вигляду |
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
xi |
|
x1 |
|
x2 |
|
|
xk |
, |
|
ni |
|
n1 |
|
n2 |
|
|
nk |
|
|
|
|
|
|
|
||||
де xi — варіанти, ni — відповідні їм частоти. Сума всіх частот ni у цій таблиці
k
дорівнює об’єму вибірки: n = åni .
i=1
Таблиця відносних частот (дискретний статистичний ряд) — це таб-
лиця вигляду |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
xi |
x1 |
x2 |
|
xk |
, |
|
ωi |
ω1 |
ω2 |
|
ωk |
|
|
|
|
||||
де xi — варіанти, ωi — відповідні їм відносні частоти. Зауважимо, що сума |
||||||
|
|
|
k |
|
|
|
всіх відносних частот ωi дорівнює 1: åωi = 1. |
|
|
||||
|
|
|
i=1 |
|
|
|
21
Полігон частот — це ламана, відрізки якої послідовно з’єднують точки з координатами (x1; n1 ) , (x2; n2 ) , , (xk ; nk ) .
Полігон відносних частот — це ламана, відрізки якої послідовно з’єднують точки з координатами (x1;ω1 ), (x2;ω2 ), , (xk ;ωk ).
Розмах вибірки — різниця між найбільшим і найменшим її елементами:
R = xmax − xmin .
Мода вибірки Mo — це такий елемент вибірки, якому відповідає найбільша частота. Модальних значень може бути декілька. Якщо мода єдина, то вибірка називається одномодальною, в іншому випадку — багатомодальною.
Медіана вибірки Me — це такий елемент вибірки, який ділить ранжований ряд навпіл, якщо кількість елементів вибірки непарна, і дорівнює середньому арифметичному двох „середніх” елементів ранжованого ряду, якщо кількість елементів вибірки — парна. Наприклад, для вибірки 4, 5, 6, 7, 8, 7, 7, 5, 4 отримаємо Me = 6, Mo = 7 ; для вибірки 9, 3, 3, 3, 5, 4, 7, 4, 5, 5 матимемо
Me = |
4 + 5 |
= 4,5 ; Mo = 3, |
Mo = 5 . |
|
|||
|
2 |
1 |
2 |
|
|
|
Типовий приклад
У таблиці наведено кількість телевізорів, які були продані на протязі тижня у 30 навмання вибраних магазинах великого міста:
6 |
7 |
2 |
6 |
6 |
4 |
3 |
6 |
5 |
3 |
4 |
7 |
4 |
5 |
4 |
5 |
6 |
4 |
5 |
6 |
6 |
2 |
3 |
5 |
8 |
4 |
7 |
5 |
5 |
3 |
Для заданої вибірки побудувати ранжований та варіаційний ряди. Записати таблиці частот та відносних частот. Побудувати полігони частот і відносних частот. Знайти об’єм вибірки, мінімальний та максимальний елементи, розмах, моду і медіану. Вказати, чи вибірка одномодальна. Дати інтерпретацію отриманих результатів.
22
Хід роботи
Крок 1. У переважній більшості програм для обробки статистичної інформації (Excel, STATISTICA, E-Views) передбачено, що дані для аналізу введені в стовпчик.
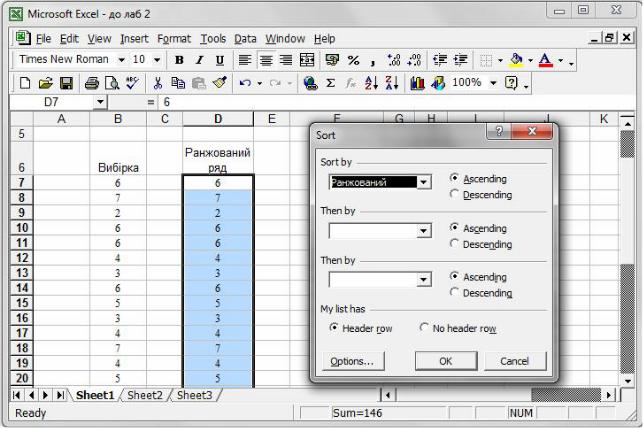
Крок 2. Надалі всі трансформації вибірки зображатимемо в окремих стовпцях. Так, для побудови ранжованого ряду потрібно початковий стовбець елементів вибірки скопіювати в інший, виділити елементи нового стовпця і скори-
статись процедурою сортування за допомогою меню Data → Sort (рис. 17).
Рис. 17. Побудова ранжованого ряду для вибірки.
Крок 3. Побудувати таблицю частот. Для цього необхідно:
1.Скористатись меню Data → PivotTable and PivotChart Report і натисну-
ти кнопку Next (рис. 18).
23
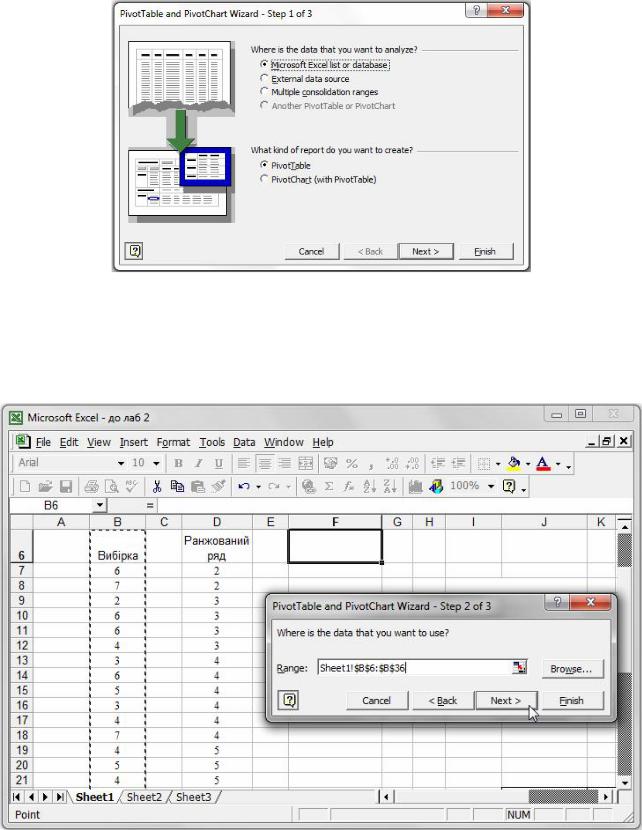
Рис. 18. Початок побудови зведеної таблиці.
2.У новому діалоговому вікні (рис. 19) у полі Range вказати стовбець статистичних даних разом із заголовком „Вибірка”.
Рис. 19. Задання вхідних даних для зведеної таблиці.
3. У діалоговому вікні, що з’явилось (рис. 20):
а) вибрати опцію Existing worksheet і вказати результуючу клітинку;
24

б) натиснути кнопку Layout;
Рис. 20. Задання результуючої клітинки для зведеної таблиці.
в) „перетягнути” кнопку із заголовком „Вибірка” спершу у поле ROW, потім — у поле DATA (рис. 21);
Рис. 21. Задання стовпців зведеної таблиці.
г) двічі клацнути по кнопці Sum of Вибірка і в списку Summarize by вибрати Count (рис. 22), натиснути OK, ще раз OK і Finish.
Рис. 22. Задання стовчика „Частоти” у зведеній таблиці.
25
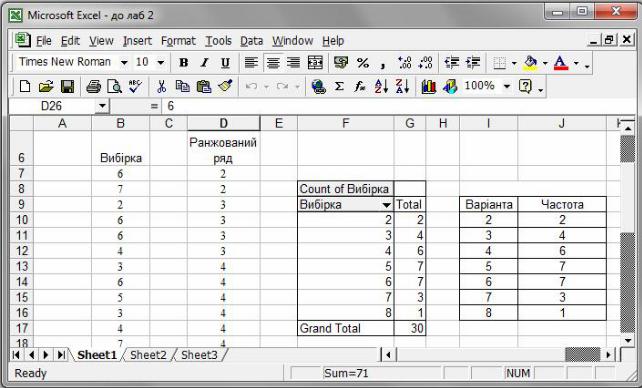
В отриманій таким чином зведеній таблиці у лівому стовпці відображенні елементи вибірки в порядку їх зростання, у правому — відповідні частоти, у клітинці Grand Total — об’єм вибірки. Скопіювати числові дані з отриманої таблиці для подальшої роботи окремо і дати їм заголовки (рис. 23).
Рис. 23. Таблиця частот.
Крок 4. Побудувати варіційний ряд шляхом копіювання лівого стовпця отриманої таблиці частот.
Крок 5. Побудувати таблицю відносних частот, користуючись формулою і не забуваючи зафіксувати адресу клітинки, в якій отримано об’єм вибірки
(рис. 24).
26
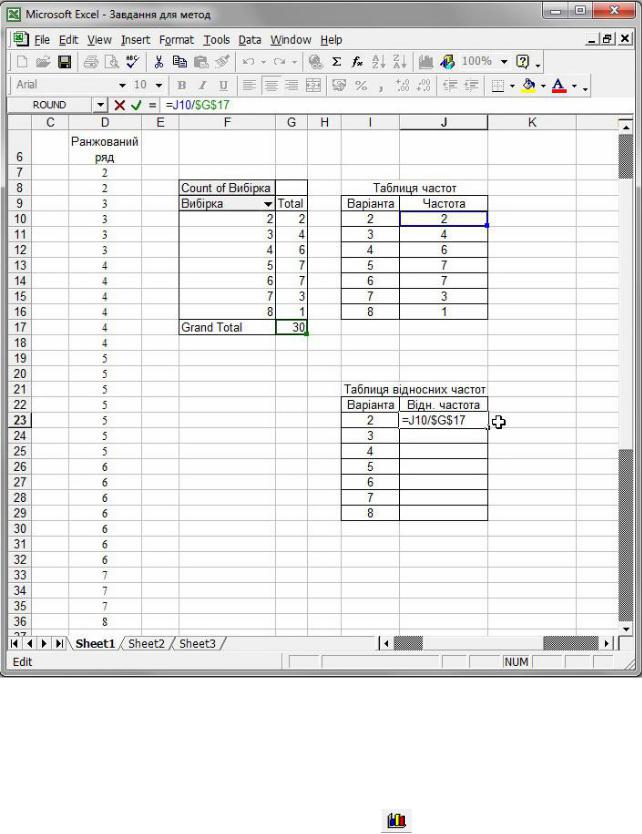
Рис. 24. Побудова таблиці відносних частот.
Крок 6. |
Для побудови полігона частот потрібно: |
||
а) |
|
виділити стовпці таблиці частот; |
|
б) |
викликати конструктор діаграм |
; |
|
в) |
|
обрати тип діаграми XY (Scatter), |
підтип — ламана (рис. 25); |
г) |
|
натиснути кнопку Next, знову Next; |
|
д) |
далі у відповідних полях вказати назви діаграми і осей; |
||
|
|
27 |
|
е) натиснути кнопку Next, потім Finish; отримаємо полігон частот
(рис. 26). |
|
|
|
|
|
|
|
|
|
|
|
|
|
Полігон частот |
|
|
|
|
|
8 |
|
|
|
|
|
|
|
|
|
7 |
|
|
|
|
|
|
|
|
|
6 |
|
|
|
|
|
|
|
|
|
5 |
|
|
|
|
|
|
|
|
|
Частота |
|
|
|
|
|
|
|
|
|
4 |
|
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
|
|
|
Варіанта |
|
|
|
|
Рис. 25. Конструктор діаграм. |
|
Рис. 26. Полігон частот. |
|
|
|||||
Крок 7. Аналогічно побудувати полігон відносних частот.
Крок 8. Для знаходження найпростіших характеристик вибірки застосувати наступні функції Excel:
COUNT — об’єм (обсяг) вибірки; MIN — найменший елемент вибірки; MAX — найбільший елемент вибірки; MODE — мода вибірки;
MEDIAN — медіана вибірки.
Зауваження 1. Якщо вибірка має декілька модальних значень, то функція MODE дозволяє знайти лише одне з них. Інші модальні значення знаходять безпосередньо з таблиці частот або полігонів.
Зауваження 2. Аргументом кожної із зазначених вище функцій є масив всіх елементів вибірки (незалежно від того, записані вони в один стовбець чи ні).
Висновок. У даній лабораторній роботі ми досліджували вибірку із 30 елементів, кожен з яких — це кількість проданих за тиждень телевізорів у певному магазині. Так, у першому магазині було продано за тиждень 6 телевізорів, у другому — 7, у третьому — 2 телевізори і т. д.
28
Проведені дослідження показують, що найменша кількість телевізорів, проданих за тиждень в магазині, — 2 шт., а найбільша — 8 шт.
Ми переконалися в тому, що сума всіх відносних частот дорівнює 1. Крім того, із таблиці відносних частот видно, що 3,3% всіх магазинів, в яких проводились дослідження, продали за тиждень лише 2 телевізори; 3,3% всіх магазинів — аж 8 телевізорів; 23% — по 5 і по 6 телевізорів.
Вибірка, що аналізується, — двомодальна, оскільки максимально можливій частоті (7) відповідають дві варіанти — 5 і 6. Це також підтверджується на основі побудованих полігонів, оскільки мода вибірки — це точка максимуму для полігона.
Відмітимо, що ламана на кожній із побудованих діаграм спочатку монотонно зростає, а потім монотонно спадає і не містить циклічних коливань.
Розмах вибіркових значень незначний. Знайдені значення моди свідчать про те, що найбільш часто в магазинах продають 5 чи 6 телевізорів за тиждень. Значення медіани (5) показує, що за тиждень половина всіх магазинів, що досліджуються, продають £ 5 телевізорів, а інша половина магазинів — ³ 5 телевізорів.
Лабораторна робота №3
Вибірки з неперервно розподіленими ознаками та їх характеристики
Основні поняття
Якщо ознака генеральної сукупності — неперервно розподілена випадкова величина ξ , або кількість спостережень — достатньо велика, то розглянутий нами у попередній лабораторній роботі підхід до аналізу даних — неефективний. Справді, виходячи з властивостей неперервної випадкової величини (для будь-якого дійсного числа x0 ймовірність P(ξ = x0 ) дорівнює нулю), ймовір-
ність того, що деякий елемент вибірки матиме велику частоту (чи велику відносну частоту), прямує до нуля. Аналогічно якщо об’єм вибірки достатньо великий, то елементи з великими частотами траплятимуться у вибірці досить рідко.
29

Тому для аналізу неперервних вибірок використовують підхід, який базується на розбитті вибірки на інтервали.
Якщо ознака ξ генеральної сукупності — неперервна випадкова величи-
на, то вибірку з цієї генеральної сукупності називатимемо неперервною.
У першу чергу для неперервної вибірки будують ранжований ряд, тобто впорядковують елементи вибірки від найменшого до найбільшого. Далі шукають об’єм, мінімальний та максимальний елементи, а також розмах вибірки.
Наступний крок — визначити кількість інтервалів для розбиття (якщо їх кількість не задано в умові завдання). У літературі можна знайти різні підходи до визначення кількості таких інтервалів, проте більшість дослідників вважають, що їх повинно бути не менше 5 і не більше 10. Досить часто у прикладних дослідженнях для визначення кількості інтервалів l використовують формулу Стерджеса:
l »1+ 3,322× lg n,
де n — об’єм досліджуваної вибірки. Зауважимо, що в результаті таких розрахунків практично завжди отримують не ціле число, а дробове, тому його заокруглюють до цілих.
Потім будують інтервальний варіаційний ряд — для цього необхідно весь вiдрiзок [a; b] , де a £ min(x1, x2 , ..., xn ), b ³ max(x1, x2 , ..., xn ) , поділити на l iнтервалiв однакової довжини, які не перетинаються між собою (без спільних
точок): [z0; z1], (z1; z2 ], (z2; z3 ], ..., (zl−1; zl ], |
де a = z0 < z1 < z2 < ... < zl−1 < zl = b . |
||||||||||
При цьому довжина кожного інтервалу |
z = |
b − a |
. |
|
|
||||||
|
|
|
|
||||||||
|
|
|
|
|
|
|
l |
|
|
||
Побудоване розбиття дає можливість записати таблицю інтервальних |
|||||||||||
частот: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
(zi−1; zi ] |
[z0; z1] |
(z1; z2 ] |
|
(z2; z3 ] |
|
... |
(zl−1; zl ] |
, |
||
|
ni |
n1 |
n2 |
|
n3 |
|
... |
nl |
|||
|
|
|
|
||||||||
в якій ni (i =1,l) — інтервальні частоти, тобто кількість елементів вибірки,
які потрапляють в інтервал (zi−1; zi ].
30