

Бонус от Юли Захаровой Гос экзамены с ответами
.pdfисходного сообщения протокол AAL проверяет служебные поля61заголовка и концевика кадра AAL и на их основании принимает решение о корректности полученной информации.
Ни один из протоколов AAL при передаче пользовательских данных конечных узлов не занимается восстановлением потерянных или искаженных данных. Максимум, что делает протокол AAL, - это уведомляет конечный узел о таком событии. Так сделано для ускорения работы коммутаторов сети ATM в расчете на то, что случаи потерь или искажения данных будут редкими. Восстановление потерянных данных (или игнорирование этого события) отводится протоколам верхних уровней, не входящим в стек протоколов технологии ATM.
Протокол AAL1 обычно обслуживает трафик класса А с постоянной битовой скоростью (Constant Bit Rate, CBR), который характерен, например, для цифрового видео и цифровой речи и чувствителен к временным задержкам. В заголовке один байт отводится для нумерации ячеек, чтобы приемная сторона могла судить о том, все ли посланные ячейки дошли до нее или нет. При отправке голосового трафика временная отметка каждого замера известна, так как они следуют друг за другом с интервалом в 125 мкс, поэтому при потере ячейки можно скорректировать временную привязку байт следующей ячейки, сдвинув ее на 125х46 мкс. Потеря нескольких байт замеров голоса не так страшна, так как на приемной стороне воспроизводящее оборудование сглаживает сигнал. В задачи протокола AAL1 входит сглаживание неравномерности поступления ячеек данных в узел назначения.
Протокол AAL2 был разработан для передачи трафика класса В, но при развитии стандартов он был исключен из стека протоколов ATM, и сегодня трафик класса В передается с помощью протокола AAL1, AAL3/4 или AAL5.
Протокол AAL3/4 обрабатывает пульсирующий трафик - обычно характерный для трафика локальных сетей - с переменной битовой скоростью (Variable Bit Rate, VBR). Этот трафик обрабатывается так, чтобы не допустить потерь ячеек, но ячейки могут задерживаться коммутатором. Протокол AAL3/4 выполняет сложную процедуру контроля ошибок при передаче ячеек, нумеруя каждую составляющую часть исходного сообщения и снабжая каждую ячейку контрольной суммой. Правда, при искажениях или потерях ячеек уровень не занимается их восстановлением, а просто отбрасывает все сообщение - то есть все оставшиеся ячейки, так как для компьютерного трафика или компрессированного голоса потеря части данных является фатальной ошибкой. Протокол AAL3/4 образовался в результате слияния протоколов AAL3 и AAL4, которые обеспечивали поддержку трафика компьютерных сетей соответственно с установлением соединения и без установления соединения. Однако ввиду большой близости используемых форматов служебных заголовков и логики работы протоколы AAL3 и AAL4 были впоследствии объединены.
Протокол AAL5 является упрощенным вариантом протокола AAL4 и работает быстрее, так как вычисляет контрольную сумму не для каждой ячейки сообщения, а для всего исходного сообщения в целом и помещает ее в последнюю ячейку сообщения.
Протокол ATM занимает в стеке протоколов ATM примерно то же место, что протокол IP в стеке TCP/IP. Протокол ATM занимается передачей ячеек через коммутаторы при установленном и настроенном виртуальном соединении, то есть на основании готовых таблиц коммутации портов. Протокол ATM выполняет коммутацию по номеру виртуального соединения, который в технологии ATM разбит на две части - идентификатор виртуального пути (Virtual Path Identifier, VPI) и идентификатор виртуального канала (Virtual Channel Identifier, VCI). Кроме этой основной задачи протокол ATM выполняет ряд функций по контролю за соблюдением трафик-контракта со стороны пользователя сети, маркировке ячеек-нарушителей, отбрасыванию ячеек-нарушителей при перегрузке сети, а также управлению потоком ячеек для повышения производительности сети (естественно, при соблюдении условий трафик-контракта для всех виртуальных соединений).
Протокол ATM работает с ячейками следующего формата, представленного на рисунке.
Рис.: Формат ячейки ATM
Поле Управление потоком (Generic Flow Control) используется только при взаимодействии конечного узла и первого коммутатора сети. В настоящее время его точные функции не определены.
Поля Идентификатор виртуального пути (VirtualPath Identifier, VPI) и Идентификатор виртуального канала (Vrtual Channel Identifier, VCI) занимают соответственно 1 и 2 байта. Эти поля задают номер виртуального соединения, разделенный на старшую (VPI) и младшую (VCI) части.
Поле Идентификатор типа данных (Payload Type Identifier, PTI) состоит из 3-х бит и задает тип данных, переносимых ячейкой, - пользовательские или управляющие (например, управляющие установлением виртуального соединения). Кроме того, один бит этого поля используется для указания перегрузки в сети - он называется Explicit Congestion Forward Identifier, EFCI - и играет ту же роль, что бит FECN в технологии frame relay, то есть передает информацию о перегрузке по направлению потока данных.
Поле Приоритет потери кадра (Cell Loss Priority, CLP) играет в данной технологии ту же роль, что и поле DE в технологии frame relay - в нем коммутаторы ATM отмечают ячейки, которые нарушают соглашения о параметрах качества обслуживания, чтобы удалить их при перегрузках сети. Таким образом, ячейки с CLP=0 являются для сети высокоприоритетными, а ячейки с CLP=1 - низкоприоритетными.
Поле Управление ошибками в заголовке (Header Error Control, НЕС) содержит контрольную сумму, вычисленную для заголовка ячейки. Контрольная сумма вычисляется с помощью техники корректирующих кодов Хэмминга, поэтому она позволяет не только обнаруживать ошибки, но и исправлять все одиночные ошибки, а также некоторые двойные.
Рассмотрим методы коммутации ячеек ATM на основе пары чисел VPI/VCI. Коммутаторы ATM могут работать в двух режимах - коммутации виртуального пути и коммутации виртуального канала. В первом режиме коммутатор выполняет продвижение ячейки только на основании значения поля VPI, а значение поля VCI он игнорирует. Обычно так работают магистральные коммутаторы территориальных сетей. Они доставляют ячейки из одной сети пользователя в другую на основании только старшей части номера виртуального канала, что соответствует идее агрегирования адресов. В результате один виртуальный путь соответствует целому набору виртуальных каналов, коммутируемых как единое целое.
После доставки ячейки в локальную сеть ATM ее коммутаторы62начинают коммутировать ячейки с учетом как VPI, так и VCI, но при этом им хватает для коммутации только младшей части номера виртуального соединения, так что фактически они работают с VCI, оставляя VPI без изменения. Последний режим называется режимом коммутации виртуального канала.
Адресом конечного узла в коммутаторах ATM является 20-байтный адрес.
Для локальных сетей, в которых замена коммутаторов и сетевых адаптеров равнозначна созданию новой сети, переход на технологию ATM мог быть вызван только весьма серьезными причинами. Гораздо привлекательнее полной замены существующей локальной сети новой сетью ATM выглядела возможность «постепенного» внедрения технологии ATM в существующую на предприятии сеть. При таком подходе фрагменты сети, работающие по новой технологии ATM, могли бы мирно сосуществовать с другими частями сети, построенными на основе традиционных технологий, таких как Ethernet или FDDI, улучшая характеристики сети там, где это нужно, и оставляя сети рабочих групп или отделов в прежнем виде.
В ответ на такую потребность ATM Forum разработал спецификацию, называемую LAN emulation, LANE (то есть эмуляция локальных сетей), которая призвана обеспечить совместимость традиционных протоколов и оборудования локальных сетей с технологией ATM. Эта спецификация обеспечивает совместную работу этих технологий на канальном уровне. При таком подходе коммутаторы ATM работают в качестве высокоскоростных коммутаторов магистрали локальной сети, обеспечивая не только скорость, но и гибкость соединений коммутаторов ATM между собой, поддерживающих произвольную топологию связей, а не только древовидные структуры.
Спецификация LANE определяет способ преобразования кадров и адресов МАС-уровня традиционных технологий локальных сетей в ячейки и коммутируемые виртуальные соединения SVC технологии ATM, а также способ обратного преобразования. Всю работу по преобразованию протоколов выполняют специальные компоненты, встраиваемые в обычные коммутаторы локальных сетей, поэтому ни коммутаторы ATM, ни рабочие станции локальных сетей не замечают того, что они работают с чуждыми им технологиями. Такая прозрачность была одной из главных целей разработчиков спецификации LANE.
Так как эта спецификация определяет только канальный уровень взаимодействия, то с помощью коммутаторов ATM и компонентов эмуляции LAN можно образовать только виртуальные сети, называемые здесь эмулируемыми сетями, а для их соединения нужно использовать обычные маршрутизаторы.
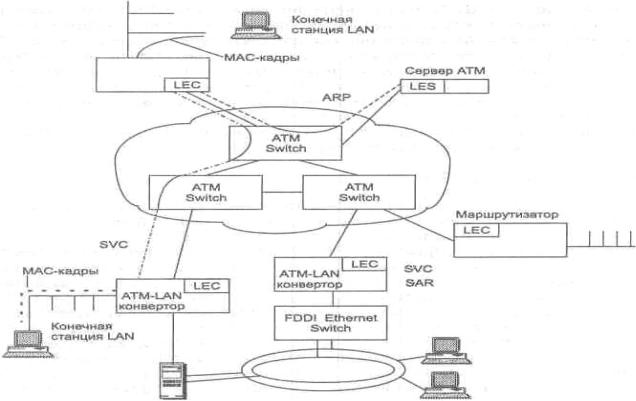
Рассмотрим основные идеи спецификации на примере сети, изображенной на рисунке.
Основными элементами, реализующими спецификацию, являются программные компоненты LEC (LAN Emulation Client) и LES (LAN Emulation Server). Клиент LEC выполняет роль пограничного элемента, работающего между сетью ATM и станциями некоторой локальной сети. На каждую присоединенную к сети ATM локальную сеть приходится один клиент LEC.
Сервер LES ведет общую таблицу соответствия MAC-адресов станций локальных сетей и АТМ-адресов пограничных устройств с установленными на них компонентами LEC, к которым присоединены локальные сети, содержащие эти станции. Таким образом, для каждой присоединенной локальной сети сервер LES хранит один АТМ-адрес пограничного устройства LEC и несколько МАС-адресов станций, входящих в эту сеть. Клиентские части LEC динамически регистрируют в сервере LES МАС-адреса каждой станции, заново подключаемой к присоединенной локальной сети.
Рис.: Принципы работы технологии LAN emulation
Программные компоненты LEC и LES могут быть реализованы в любых устройствах - коммутаторах, маршрутизаторах или рабочих станциях ATM.
Когда элемент LEC хочет послать пакет через сеть ATM станции другой локальной сети, также присоединенной к сети ATM, он посылает запрос на установление соответствия между МАС-адресом и АТМ-адресом серверу LES. Сервер LES отвечает на запрос, указывая АТМадрес пограничного устройства LEC, к которому присоединена сеть, содержащая станцию назначения. Зная АТМ-адрес, устройство LEC исходной сети самостоятельно устанавливает виртуальное соединение SVC через сеть ATM обычным способом, описанным в спецификации
UNI. После установления связи кадры MAC локальной сети63преобразуются в ячейки ATM каждым элементом LEC с помощью стандартных функций сборки-разборки пакетов (функции SAR) стека ATM.
Вспецификации LANE также определен сервер для эмуляции в сети ATM широковещательных пакетов локальных сетей, а также пакетов
снеизвестными адресами, так называемый сервер BUS (Broadcast and Unknown Server). Этот сервер распространяет такие пакеты во все пограничные коммутаторы, присоединившие свои сети к эмулируемой сети.
На рисунке все пограничные коммутаторы образуют одну эмулируемую сеть. Если же необходимо образовать несколько эмулируемых сетей, не взаимодействующих прямо между собой, то для каждой такой сети необходимо активизировать собственные серверы LES и BUS, а в пограничных коммутаторах активизировать по одному элементу LEC для каждой эмулируемой сети. Для хранения информации о количестве
активизированных эмулируемых сетей, а также АТМ-адресах соответствующих серверов LES и BUS вводится еще один сервер - сервер конфигурации LECS (LAN Emulation Configuration Server).
Технология ATM расширяет свое присутствие в локальных и глобальных сетях не очень быстро, но неуклонно. В последнее время наблюдается устойчивый ежегодный прирост числа сетей, выполненных по этой технологии, в 20-30%.
Влокальных сетях технология ATM применяется обычно на магистралях, где хорошо проявляются такие ее качества, как масштабируемая скорость (выпускаемые сегодня корпоративные коммутаторы ATM поддерживают на своих портах скорости 155 и 622 Мбит/с), качество обслуживания (для этого нужны приложения, которые умеют запрашивать нужный класс обслуживания), петлевидные связи (которые позволяют повысить пропускную способность и обеспечить резервирование каналов связи). Петлевидные связи поддерживаются в силу того, что ATM - это технология с маршрутизацией пакетов, запрашивающих установление соединений, а значит, таблица маршрутизации может эти связи учесть - либо за счет ручного труда администратора, либо за счет протокола маршрутизации PNNI.
Основной соперник технологии ATM в локальных сетях - технология Gigabit Ethernet. Она превосходит ATM в скорости передачи данных - 1000 Мбит/с по сравнению с 622 Мбит/с, а также в затратах на единицу скорости. Там, где коммутаторы ATM используются только как высокоскоростные устройства, а возможности поддержки разных типов трафика игнорируются, технологию ATM, очевидно, заменит технология Gigabit Ethernet. Там же, где качество обслуживания действительно важно (видеоконференции, трансляция телевизионных передач и т. п.), технология ATM останется. Для объединения настольных компьютеров технология ATM, вероятно, еще долго не будет использоваться, так как здесь очень серьезную конкуренцию ей составляет технология Fast Ethernet.
Вглобальных сетях ATM применяется там, где сеть frame relay не справляется с большими объемами трафика, и там, где нужно обеспечить низкий уровень задержек, необходимый для передачи информации реального времени.
Сегодня основной потребитель территориальных коммутаторов ATM - это Internet. Коммутаторы ATM используются как гибкая среда коммутации виртуальных каналов между IP-маршрутизаторами, которые передают свой трафик в ячейках ATM. Сети ATM оказались более выгодной средой соединения IP-маршрутизаторов, чем выделенные каналы SDH, так как виртуальный канал ATM может динамически перераспределять свою пропускную способность между пульсирующим трафиком клиентов IP-сетей.
Сегодня по данным исследовательской компании Distributed Networking Associates около 85% всего трафика, переносимого в мире сетями ATM, составляет трафик компьютерных сетей (наибольшая доля приходится на трафик IP - 32%).
Что же касается совместимости ATM с технологиями компьютерных сетей, то разработанные в этой области стандарты вполне работоспособны и удовлетворяют пользователей и сетевых интеграторов.
Билет 16
1. -Классификация информационно-вычислительных сетей. Сети одноранговые и "клиент/сервер"
Сети одноранговые и «Клиент/Сервер»
Локальные, глобальные и территориальные сети могут быть одноранговыми сетями, сетями типа «Клиент/Сервер» (они также называются сетями с выделенным сервером) или смшанными сетями (в которых используются как одноранговые технологии, так и технологии с выделенным сервером).
Компьютеры в одноранговых сетях могут выступать как в роли клиентов, так и в роли серверов. Так как все компьютеры в этом типе сетей равноправны, одноранговые сети не имеют централизованного управления резделением ресурсов. Любой из компьютеров может разделять свои ресурсы с любым компьютером в той же сети. Одноранговые взаимоотношения также означают, что ни один компьютер не имеет ни высшего приоритета на доступ, ни повышенной ответственности за предоставление ресурсов в совместное пользование.
Каждый пользователь в одноранговой сети является одновременно сетевым администратором. Это означает, что каждый пользователь в сети управляет доступом к ресурсам, расположенным на его компьютере. Он может дать всем остальным неограниченный доступ к локальным ресурсам, дать ограниченный доступ, а может не дать вообще никакого доступа другим пользователям. Каждый пользователь также решает, дать другим пользователям доступ просто по их запросу или защитить эти ресурсы паролем.
Основной проблемой в одноранговых сетях является безопасность, т.к. отсутствуют средства обеспечения безопасности в масштабе сети. При этом отдельные ресурсы отдельных компьютеров могут быть защищены системой паролей, и только те пользователи, которые знают пароль, могут получить доступ к ресурсам.
Этот тип сети может быть работоспособным в малых сетях, но так же требует, чтобы пользователи знали и помнили различные пароли для каждого разделенного ресурса в сети. С ростом количества пользователей и ресурсов одноранговая сеть становится неработоспособной. Это происходит не потому, что сеть не может функционировать правильно, а потому, что пользователи не в состоянии справиться со сложностью сети.
К тому же большинство одноранговых сетей состоит из набора типичных персональных компьютеров, связанных общим сетевым носителем. Эти типы компьтеров не были разработаны для работы в качестве сетевых серверов, поэтому производительность сети может упасть, когда много пользователей попытаются одновременно получить доступ к ресурсам какого-то одного компьютера. Кроме того, пользователь, к чьей машине происходит доступ по сети, сталкивается с падением производительности в то время, когда компьютер выполняет затребованные сетевые службы. Например, если к компьютеру пользователя подключен принтер, к которому осуществляется доступ по сети, компьютер будет замедлять свою работу каждый раз, когда пользователи посылают задание на этот принтер. Это может раздражать того, кто работает на данной машине.
В одноранговой сети также трудно организовать хранение и учет данных. Когда каждый сетевой компьютер может служить сервером, пользователям трудно отслеживать, на какой машине лежит интересующая их информация. Децентрализованная природа такого типа сети делает поиск ресурсов чрезвычайно сложным с ростом числа узлов, на которых должна происходить проверка. Децентрализация также затрудняет процедуру резервного копирования данных – вместо копирования централизованного хранилища данных требуется осуществлять резервное копирование на каждом сетевом компьютере, чтобы защитить разделенные данные.
Однако одноранговые сети имеют серьезные преимущества перед сетями с выделенным сервером, особенно для малых организаций и сетей. Одноранговые сети являются наиболее легким и дешевым типом сетей для установки. Большинство одноранговых сетей требует
наличия на компьютерах, кроме сетевой карты и сетевого носителя64(кабеля), только операционной системы. Как только компьютеры соединены, пользователи немедленно могут начинать предоставление ресурсов и информации в совместное пользование.
Преимущества одноранговых сетей:
Легкость в установке и настройке;
Независимость отдельных машин от выделенного сервера;
Возможность пользователем контролировать свои собственные ресурсы;
Сравнительная дешевизна в прибретении и эксплуатации;
Отсутствие необходимости в дополнительном программном обеспечении, кроме операционной системы;
Отсутствие необходимости иметь отдельного человека в качестве выделенного администратора сети.
Недостатки одноранговых сетей:
Необходимость помнить столько паролей, сколько имеется разделенных ресурсов;
Необходимость производить резервное копирование на каждом компьютере, чтобы защитить все совместные данные;
Падение производительности при доступе к разделенному ресурсу на компьютере, где этот ресурс расположен;
Отсутствие централизованной организационной схемы для поиска и управления доступом к данным.
Сети с выделенным сервером или сети типа «клиент/сервер» опираются на специализированные компьютеры, называемые серверами, представляющими собой централизованные хранилища сетевых ресурсов и объединяющими централизованное обеспечение безопасности и управления доступом. В отличие от сетей с выделенным сервером, одноранговые сети не имеют централизованного обеспечения безопасности и управления. Сервер представляет собой сочетание специализированного программного обеспечения и оборудования, которое предоставляет службы в сети для остальных клиентских компьютеров (рабочих станций) или других процессов.
Имеется несколько причин для реализации сети с выделенным сервером, включающих централизованное управление сетевыми ресурсами путем использования сетевой безопасности и управления доступом посредством установки и настройки сервера. С точки зрения оборудования, сетевые компьютеры обычно имеют более быстрый центральный процессор, больше памяти, большие жесткие диски и дополнительные перифирийные устройства, например, накопители на магнитной ленте и приводы компакт-дисков, по сравнению с клиентскими машинами. Серверы также ориентированы на то, чтобы обрабатывать многочисленные запросы на разделяемые ресурсы быстро и эффективно. Серверы обычно выделены для обслуживания сетевых запросов клиентов. В дополнение, физическая безопасность – доступ к самой машине – является ключевым компонентом сетевой безопасности. Поэтому важно, чтобы серверы располагались в специальном помещении с контролируемым доступом, отделенном от помещений с общим доступом.
Сети с выделенным сервером такжк предоставляют централизованную проверку учетных записей пользователей и паролей. Например, Windows NT использует доменную концепцию для управленя пользователями, группами и машинами и для контроля над доступом к сетевым ресурсам. Прежде чем пользователь сможет получить доступ к сетевым ресурсам, он должен сообщить свое регистрационное имя и пароль контроллеру домена – серверу, который проверяет имена учетных записей и пароли в базе данных с такой информацией. Контроллер домена позволит доступ к определенным ресурсам только в случае допустимой комбинации данных регистрационного имени и пароля. Изменять связанную с безопасностью информацию в базе данных контроллера домена может только сетевой администратор. Этот подход обеспечивает централизованную безопасность и позволяет управлять ресурсами с изменяющейся степенью контроля в зависимсти от их важности и расположения.
В отличи от одноранговой модели, сеть с выделенным сервером обычно требует только один пароль для доступа к самой сети, что уменьшает количество паролей, которые пользователь должен помнить. Кроме того, сетевые ресурсы типа файлов и принтеров легче найти, потому что они расположены на определенном сервере, а не на чьей-то машине в сети. Концентрация сетевых ресурсов на небольшом количестве серверов также упрощает резервное копирование и поддержку данных.
Сети с выделенным сервером лучше масштабируются – в сравнении с одноранговыми сетями. С ростом размера одноранговые сети сильно замедляют свою работу и становятся неуправляемыми. Сети с выделенным сервером, наоборот, могут обслуживать от единичных пользователей до десятков тысяч пользователей и географически распределенных ресурсов. Другими словами, сеть с выделенным сервером может расти с ростом используюущей ее организации.
Подобно одноранговой модели, сеть с выделенным сервером также имеет недостатки. Первой в этом списке стоит необходимость дополнительных расходов на такие сети. Сеть с выделенным сервером требует наличия одного или нескольких более мощных – и, соответственно, более дорогих – компьютеров для запуска специального (и тоже дорогого) серверного программного обеспечения. Вдобавок серверное программное обеспечение требует квалифицированного персонала для его обслуживания. Подготовка персонала для овладения необходимыми для обслуживания сети с выделенным сервером навыками или наем на работу подготовленных сетевых администраторов также увеличивает стоимость такой сети.
Есть и другие негативные аспекты сетей с выделенным сервером. Централизация ресурсов и управления упрощает доступ, контроль и объединение ресурсов, но при этом приводит к появлению точки, которая может привести к неполадкам во всей сети. Если сервер вышел из строя, -- не работает вся сеть. В сетях с несколькими серверами потеря одного сервера означает потерю всех ресурсов, связанных с этим сервером. Также, если неисправный сервер является единственным источником информации о правах доступа определенной части пользователей, эти пользователи не смогут получить доступ к сети.
Преимущества сетей с выделенным сервером:
Обеспечение централизованного управления учетными записями пользователей, безопасностью и доступом, что упрощает сетевое администрирование;
Использование более мощного серверного оборудования означает и более эффективный доступ к сетевым ресурсам;
Пользователям для входа в сеть нужно помнить только один пароль, что позволяет им получить доступ ко всем ресурсам, к которым имеют права.
Недостатки сетей с выделенным сервером:
Неисправность сервера может сделать сеть неработоспособной, что в лучшем случае означает потерю сетевых ресурсов;
Сети требуют квалифицированного персонала для сопровождения сложного специализированного программного обеспечения, что увеличивает общую стоимость сети;
Стоимость также увеличивается благодаря потребности в выделенном оборудовании и специализированном программном обеспечении.
2. -Классификация видов моделирования; имитационные модели систем
Моделирование, в общем смысле – это представление какого-либо явления (процесса) некоторым описанием. Описание может быть словесным, в виде моделей:
Физическое моделирование - это исследование объектов на физических моделях, представляющих собой некоторые объекты, сохраняющие физическую природу исходного объекта, либо описываемые математическими уравнениями, аналогичными уравнениям.

описывающим исходный объект. Примером первого типа65моделирования является исследование аэродинамических свойств самолета или автомобиля на макетах, примером второго типа моделирование маятника с помощью RLC – цепочки (колебательного звена).
Математическое моделирование - ММ – запись на языке математики законов, управляющих протеканием исследуемого процесса или описывающих функционирование изучаемого объекта. ММ представляет собой компромисс между бесконечной сложностью изучаемого объекта или явления и желаемой простотой его описания.
ММ должна быть достаточно полной для того. чтобы можно было изучать свойства объекта и в то же время простой для того. чтобы ее анализ существующими в математике и вычислительной технике средствами был возможен.
Имитационное моделирование основано на воспроизведении с помощью ЭВМ развернутого во времени процесса функционирования системы с учетом взаимодействия с внешней средой. Основой всякой имитационной модели (ИМ) является: разработка модели исследуемой системы, выбор информативных характеристик объекта, построение модели воздействия внешней среды на систему, выбор способа исследования имитационной модели. Условно имитационную модель можно представить в виде действующих, программно (или аппаратно) реализованных блоков. Блок имитации внешних воздействий (БИВВ) формирует реализации случайных или детерминированных процессов, имитирующих воздействия внешней среды на объект. Блок обработки результатов (БОР) предназначен для получения информативных характеристик исследуемого объекта. Необходимая для этого информация поступает из блока математической модели объекта (БМО). Блок управления (БУИМ) реализует способ исследования имитационной модели, основное его назначение – автоматизация процесса проведения ИЭ.
Целью имитационного моделирования является конструирование ИМ объекта и проведение ИЭ над ней для изучения закона функционирования и поведения с учетом заданных ограничений и целевых функций в условиях иммитации и взаимодействия с внешней средой. К достоинствам метода имитационного моделирования могут быть отнесены: 1. проведение ИЭ над ММ системы, для которой натурный эксперимент не осуществим по этическим соображениям или эксперимент связан с опасностью для жизни, или он дорог, или из-за того, что эксперимент нельзя провести с прошлым; 2. решение задач, аналитические методы для которых неприменимы, например, в случае непрерывнодискретных факторов, случайных воздействий, нелинейных характеристик элементов системы и т.п.; 3.возможность анализа общесистемных ситуаций и принятия решения с помощью ЭВМ, в том числе для таких сложных систем, выбор критерия сравнения стратегий поведения которых на уровне проектирования не осуществим; 4.сокращение сроков и поиск проектных решений, которые являются оптимальными по некоторым критериям оценка эффективности; 5.проведение анализа вариантов структуры больших систем, различных алгоритмов управления изучения влияния изменений параметров системы на ее характеристики и т.д. Задачей имитационного моделирования является получение траектории движения рассматриваемой системы в n – мерном пространстве (Z1, Z2, … Zn), а также вычисление некоторых показателей, зависящих от выходных сигналов системы и характеризующих ее свойства. Основные методы имитационного моделирования: Аналитический метод применяется для имитации процессов в основном для малых и простых систем, где отсутствует фактор случайности. Метод статистического моделирования первоначально развивался как метод статистических испытаний. Это численный метод, состоящий в получении оценок вероятностных характеристик, совпадающих с решением аналитических задач (например, с решением уравнений и вычислением определенного интеграла).Комбинированный метод (аналитико-статистический) позволяет объединить достоинства аналитического и статистического методов моделирования. Он применяется в случае разработки модели, состоящей из различных модулей, представляющих набор как статистических так и аналитических моделей, которые взаимодействуют как единое целое. Причем в набор модулей могут входить не только модули соответствующие динамическим моделям, но и модули соответствующие статическим математическим моделям.
3. -Принципы IP-адресации в сетях Три типа адресов стека протоколов. Локальные, IP-адреса, символьные доменные адреса.
Каждый компьютер в сети TCP/IP имеет адреса трех уровней:
Локальный адрес узла, определяемый технологией, с помощью которой построена отдельная сеть, в которую входит данный узел. Для узлов, входящих в локальные сети – это МАС-адрес сетевого адаптера или порта маршрутизатора, например, 23-В4-65-7С-DC-11. Эти адреса назначаются производителями оборудования и являются уникальными адресами, так как управляются централизованно. Для существующих технологий локальных сетей МАС-адрес имеет формат 6 байтов: старшие 3 байта – идентификатор фирмы производителя, а младшие 3 байта назначаются уникальным образом самим производителем. Для узлов, входящих в глобальные сети, такие как Х.25 или frame relay, локальный адрес назначается администратором глобальной сети.
IP-адрес, состоящий из 4-х байт, например, 192.15.0.30. Этот адрес используется на сетевом уровне и назначается администратором во время конфигурирования компьютеров и маршрутизаторов.
Символьный идентификатор-имя, например COMP21.AUD.221.COM, также назначаемый администратором. Его так же называют DNSименем.
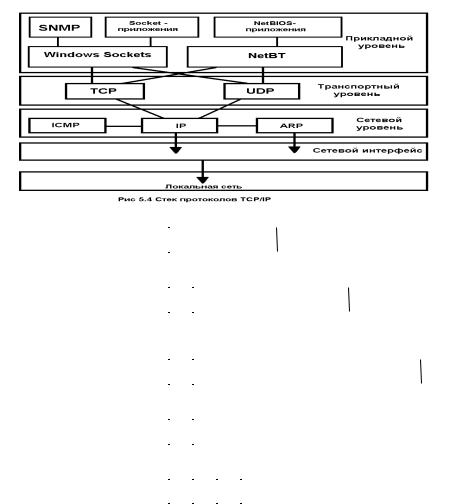
TCP/IP – это стек протоколов, созданный для межсетевого обмена. На рис. 5.4 представлена структура протокола TCP/IP.
Логический 32-разрядный IP-адрес адрес, используемый для идентификации TCP/IP-хоста, состоит из 2-х частей: идентификатора сети и идентификатора хоста и имеет длину 4 байта – первый определяет номер сети, вторая – номер узла в сети. Каждый компьютер, использующий протокол TCP/IP, должен иметь уникальный адрес-IP, например, 10.0.0.2.
Каждый узел в объединенной сети, как указывалось выше, должен иметь свой уникальный IP-адрес и состоять из двух частей – номера сети и номера узла. Какая часть адреса относится к номеру сети, а какая к номеру узла, определяется значениями первых битов адреса:
Если адрес начинается с 0, то сеть относят к классу А, и номер сети занимает один байт, остальные 3 байта интерпретируются как номер узла в сети. Сети класса А имеют номера в диапазоне то 1 до 126 (рис 5.5). в таких сетях количество узлов должно быть больше 216, но не превышать 224.
Если первые два бита адреса равны 1, т.е. относятся к классу В, и является сетью средних размеров с числом узлов 28 – 216.
Если адрес начинается с последовательности 110, т.е. класса С, с числом узлов не больше 28 (см. рис.5.5).
Если адрес начинается с последовательности 1110, то он является адресом класса D, и обозначает особый, групповой адрес – multicast. Если в пакете в качестве адреса назначения указан адрес класса D, то такой пакет должны получить все узлы, которые образуют группу с номером, указанным в поле адреса.
Если адрес начинается с последовательности 11110, то это адрес класса Е, он зарегистрирован для будущих применений (рис.5.5). В общем случае, такие числовые адреса могут иметь некоторое разнообразие трактовок, из которых приведем здесь следующую:
<класс сети> <номер сети> <номер компьютера>.
Такая комбинация подразумевает, что множество представимых числовых номеров делится на сети разного масштаба, а именно (рис5.5,
5.6).
С помощь специального механизма маскирования любая сеть,66в свою очередь, может быть представлена набором более мелких сетей. Определение номеров сети по первым байтам адреса не вполне гибкий механизм для адресации. На сегодняшний день получили широкое распространение маски. Маска – это тоже 32-разрядное число, она имеет такой же вид, как и IP-адрес. Маска используется в паре с
IP-адресом, но не совпадает с ним.
Принцип определения номера сети и номера узла IP-адреса с использованием адреса состоит в следующем: двоичная запись маски содержит единицы в тех разрядах, которые представляются как номер хоста. Кроме того, поскольку номер сети является целой частью адреса, единицы в маске должны представлять непрерывную последовательность.
Каждый класс IP-адресов (А, В, С) имеет свою маску, используемую по умолчанию:
Класс А – 11111111.00000000.00000000.00000000 (255.0.0.0)
Класс В – 11111111.11111111.00000000.00000000 (255.255.0.0)
Класс С – 11111111.11111111.11111111.00000000 (255.255.255.0)
Например, если адресу 190.215.214.30 задать маску 255.255.255.0, то номер сети будет 190.215.124.0, а не 190.215.0.0, как это определяется правилами системы классов.
Доменные адреса.
С ростом объемов информации в Internet, увеличилось и количество его узлов. В результате путешествие по глобальной сети с помощью адресов, представленных в виде чисел, стало неудобным. На смену им пришли так называемые доменные адреса.
Домен (domain) – территория, область, сфера, – фрагмент, описывающий адрес в текстовой форме. Адрес конечного узла представляется в виде не цифрового кода, как было указано выше, а в виде набора текстовой информации формата:
domain4.domain3.domain2.domain1 ,
где domain1 – буквенное обозначение страны, например, ru, eng и др., или одной из следующих спецификаций: com – коммерческие организации,
edu – учебные и научные организации, gov – правительственные организации, mil – военные организации,
net – сетевые организации разных сетей, org -- другие организации.
domain4.domain3.domain2 -- описывают, как правило, более низшие уровни адреса, например, наименование города, отдела, раздела и
т.д..
|
|
|
|
|
|
7 бит |
|
|
|
|
|
|
|
|
|
|
|
|
24 бита |
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
Класс А |
С |
Идентификатор сети |
|
|
Идентификатор хоста |
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
14 бит |
|
|
|
|
|
|
|
|
|
|
|
16 бит |
|
|
|
||||||
Класс В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
0 |
|
Идетификатор сети |
|
Идентификатор хоста |
|
|
|||||||||||||||||||||
|
|
|
|
|
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
21 бит |
|
|
|
|
|
|
16 бит |
|
|
||||||||
Класс С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
1 |
|
0 |
Идетификатор сети |
|
|
|
|
|
Идентификатор хоста |
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
28 бит |
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Класс D |
1 |
1 |
|
1 |
0 |
|
|
|
|
|
|
Идентификатор группы (multicast) |
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
27 бит |
|
|
|
|
|
||||
Класс Е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
1 |
|
1 |
1 |
|
С |
|
(зарезервировано для дальнейшего использования) |
|
|
||||||||||||||||||
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
Рис. 5.5 Классы адресов Internet |
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Класс |
|
|
|
|
|
|
|
|
|
|
|
Диапазон |
|
|
||||||||||
|
|
|
|
A |
|
|
|
|
|
|
|
|
|
|
|
|
0.0.0.0 - 127.255.255.255 |
|
|
|
|
|||||||
|
|
|
|
B |
|
|
|
|
|
|
|
|
|
|
|
|
128.0.0.0 - 191.255.255.255 |
|
|
|
||||||||
|
67 |
C |
192.0.0.0 – 223.255.255.255 |
D |
224.0.0.0 – 239.255.255.255 |
E |
240.0.0.0 – 247.255.255.255 |
Рисунок 5.6. Диапазоны IP адресов в разных классах сетей.
Билет 17
1. -Микропроцессоры с «жестким» и программируемым принципами управления
Микропроцессоры с «жестким» и программируемым принципами управления
Организация режимов работы процессоров
Режимы работы ЭВМ IBM PC с центральным процессором (ЦП) 80х86 (x > 2)
ЭВМ IВМ РС с ЦП 8086 могла работать только в так называемом реальном режиме. Начиная с ЦП 80286 появилась возможность использования защищенного режима работы, однако вскоре появился более современный ЦП 80386, основные особенности архитектуры которого нашли свое отображение и в следующих моделях ряда этих ЦП: 80486, 80586 и т.д. Поэтому режимы функционирования ряда этих ЦП будем рассматривать для ЦП 80386 и выше. Каждый из этих ЦП может функционировать в одном из трех режимов: реальном, защищенном и виртуальном; далее будут кратко рассмотрены основные особенности функционирования и использования этих режимов.
Реальный режим работы ЦП 80386
При включении питания или после сигнала "Сброс" ЦП 80386 устанавливается в реальный режим работы, который соответствует ЦП 8086 с добавлением возможности использования 32-разрядных регистров. Механизм адресации, пространство адресов памяти, управление прерываниями осуществляется аналогично реальному режиму ЦП 8086. В реальном режиме могут использоваться любые команды ЦП
80386.
Размер операнда по умолчанию в реальном режиме составляет 16 бит, как и у ЦП 8086. Для того, чтобы использовать 32-разрядные регистры, необходимо предварительно выполнить соответствующую настройку выполняемой программы. Размер сегмента в реальном режиме равен 64К байт, поэтому 32-разрядные адреса должны быть меньше, чем 0000FFFFh. В реальном режиме максимальный размер памяти составляет 1М байт. Так как в реальном режиме не используется страничная адресация, то линейный адрес равен физическому.
Физические адреса, как и в ЦП 8086, формируются в реальном режиме сложением содержимого соответствующего сегментного регистра, который сдвигается влево на 4 разряда, с исполнительным адресом, указанным в команде. В результате создается адресное пространство, определяемое 20-разрядным физическим адресом, т.е. равное 1М плюс 64К байт.
Вреальном режиме имеется две зарезервированные области памяти: зона системной инициализации, находящаяся по адресам с FFFFFFF0h по FFFFFFFFh, и зона таблицы прерываний, находящаяся по адресам с 00000h по 003FFh.
Внастоящее время реальный режим на ЭВМ IВМ РС с ЦП 80386 используется для реализации двух целей:
1.выполнения на этих ЭВМ программ, написанных под MS DOS или другие родственные ей ОС;
2.для подготовки перехода этой ЭВМ в защищенный режим.
Защищенный режим работы ЦП 80386
Возможности ЦП 80386 раскрываются полностью, если он работает в защищенном режиме. Защищенный режим позволяет использовать дополнительные команды, специально предназначенные для многозадачных ОС. Главные отличия защищенного режима от реального состоят в следующем:
1.адресное пространство расширяется до 4Г байт, а область виртуальных адресов - до 64Т байт, т.е. практически не ограничена;
2.используются другие механизмы адресации, при этом существенно, что выполняемой в каком-то отрезке времени задаче выделяется определенная область оперативной памяти (ОП), за пределы которой задача не может обращаться, - при попытке такого обращения возникает так называемое нарушение общей защиты, вследствие чего выполнение задачи прекращается и включается принадлежащая ОС программа обработки прерывания по этой причине;
3.используется другая область ОП для размещения векторов прерываний, при этом ввиду того, что номера векторов для одинаковых по смыслу событий могут различаться в этих режимах и к тому же сами наборы прерываний отличаются между собой, при переходе из одного режима в другой требуется произвести соответствующую настройку аппаратных средств с помощью команд программы, производящей переключение из режима в режим.
Защищенный режим может использоваться в следующих случаях:
1.для использования ЭВМ в многопользовательском режиме, например, если ЭВМ является сервером вычислительной сети и на нем
установлена многопользовательская ОС для обслуживания запросов рабочих станций этой сети;
2.для использования ЭВМ в однопользовательском многозадачном режиме;
3.для использования ЭВМ в однопользовательском однозадачном режиме, но при этом для решения задачи необходимо выделение ей объема ОП, превышающего величину 1М байт;
4.для использования ЭВМ в однопользовательском однозадачном режиме, но при этом используемая ОС предоставляет пользователю для общения с ЭВМ интерфейс, существенно превосходящий по своим возможностям интерфейс, предоставляемый MS DOS (такие возможности обеспечивают ОС типа Windows).
Виртуальный режим работы ЦП 80386 (режим V86). Эмуляция MS DOS в режиме V86. Основной целью использования режима V86
является одновременное выполнение программ, написанных под MS DOS, под управлением многопользовательской ОС. При этом у каждого пользователя создается иллюзия монопольного владения всеми ресурсами ЭВМ.
Реальный режим работы ЦП 80386, эмулирующий ЦП 8086, и режим виртуального ЦП 8086, работающий в защищенном режиме ЦП 80386, несколько различаются. Когда ЦП работает в режиме V86, его селекторы, несмотря на то, что включен защищенный режим, интерпретируются также, как и в реальном режиме. Эффективный адрес при этом получается сложением смещения со сдвинутым на 4 разряда влево содержимым сегментного регистра. На ОС возлагаются обязанности по определению программ, использующих механизм адресации ЦП 8086, и программ, использующих адресацию собственно ЦП 80386. Отличие адресации виртуального ЦП 8086 от реального заключаются в использовании механизма страничной адресации, благодаря которому адресное пространство задачи в 1М байт может быть размещено в любом месте пространства линейных адресов ЦП 80386 объемом 4Г байт. Адреса, превышающие величину 1М в режиме виртуального ЦП 8086, будут вызывать возникновение прерывания 13 защищенного режима (нарушение общей защиты).
Все программы виртуального режима выполняются на уровне68привилегированности 3, т.е. на низшем уровне, в отличие от реального режима, который всегда имеет уровень привилегированности 0, т.е. высший уровень. Поэтому попытка выполнить в виртуальном режиме привилегированную команду также приведет к возникновению прерывания 13.
Аппаратные средства страничной адресации поддерживают параллельную работу нескольких задач, использующий виртуальный режим, и обеспечивают защиту и независимость работы их ОС. Эти средства могут использоваться в многозадачных ОС для обеспечения одновременного выполнения нескольких задач.
Важнейшей чертой программ реального режима является широкое использование средств MS DOS и BIOS. Поэтому виртуальный режим может иметь право на вектора программного прерывания) и передача управления через этот вектор требуемой программе ОС, которая, очевидно, должна выполняться опять в режиме V86. Всю эту процедуру иногда называют "отражением" прерывания на MS DOS (или другую ОС реального режима), или "эмуляцией" DOS в режиме виртуального ЦП 8086. Подобная эмуляция должна осуществляться и при возникновении аппаратных прерываний, обеспечивая обычно их обработку с помощью BIOS.
Таким образом многозадачная ОС, выполняемая на ЦП 80386, может полностью моделировать вызовы однозадачной ОС, например, MS DOS. Кроме того, эта многозадачная ОС должна также выполнять подобным образом производить обработку команд обращения задач, выполняемых в режиме V86, к портам ввода-вывода - команд in и out.
Принципы обеспечения в ОС многозадачного и многопользовательского режимов (на примере ОС типа Windows)
Наиболее характерные примеры, когда возникает необходимость использования таких ОС:
-при размещении ОС на сервере вычислительной сети для управления работой этой сети;
-при управлении работой супер-ЭВМ, работающей в режиме разделения времени;
-при управлении работой системой реального времени, для которых характерна ситуация, когда процесс обслуживания одной заявки может быть прерван ввиду необходимости срочного обслуживания вновь поступившей заявки.
Кроме того, использование многозадачной ОС может оказаться весьма целесообразно и на обычной персональной ЭВМ, например, на фоне вывода на печать уже отредактированной части текста продолжается редактирование другой части текста, и т.д.
По числу одновременно выполняемых задач ОС можно разделить на однозадачные и многозадачные, но на самом деле можно произвести и более подробную классификацию по этому признаку:
-однозадачные ОС (MS DOS в значительной части случаев ее использования);
-использование в среде MS DOS резидентных программ (TSR), включаемых или по вызову пользователя, например, нажатием заданной комбинации клавиш, или от системного таймера; главный недостаток при использовании TSR заключается в отсутствии реентерабельности (повторной входимости) функций MS DOS и BIOS, вызываемых программами пользователей;
-невытесняющая многозадачность, реализованная в Windows 3.0 и Windows 3.1, явилась шагом вперед по сравнению с использованием
резидентных программ, так |
как при использовании этих вновь созданных |
программных продуктов была решена |
проблема |
реентерабельности для ОС; |
суть невытесняющей многозадачности состоит в том, |
что передача управления от программы к программе |
|
производится тогда, когда выполняемая в данный момент программа этого "пожелает", что является крупным недостатком метода ввиду отсутствия учета приоритетов при предоставлении задачам времени ЦП и вследствие этого низкой эффективности его использования;
- вытесняющая многозадачность, реализованная в ОС типа Windows, начиная с Windows 95, в ОС Unix и т.д., при которой каждой задаче предоставляется для ее выполнения ограниченный квант времени, вследствие чего существенно возрастает эффективность использования времени ЦП по сравнению со случаем использования невытесняющей многозадачности.
Характерные свойства современных многозадачных и многопользовательских ОС
1.Вытесняющая многозадачность;
2.Реентерабельность программ этих ОС;
3.Исключение из процесса обслуживания тех задач пользователей, в процессе решения которых проявились ошибки, которые делают невозможным дальнейшее выполнение этих задач без внесения пользователем коррекции в программу или начальные данные этих же
задач; сообщение о сложившейся ситуации выдается на экран монитора пользователя, а процесс обслуживания задач других пользователей при этом не прекращается;
4.Адресное пространство ОП каждой задачи и ОС должно быть защищено от воздействия друг друга; эта защита организуется при блоковой организации ОП (подобная защита отсутствует при функционировании MS DOS, так как при этом используется реальный режим работы ЦП 80х86, в котором отсутствуют средства рассматриваемой защиты);
5.Учитывая, что каждой задаче выделяется относительно небольшой квант времени, обычно порядка нескольких десятков милисекунд, и поэтому переключение с задачи на задачу происходит сравнительноно часто, целесообразно иметь ОП достаточно большого объема, так как
впротивном случае будут иметь место весьма большие потери времени на обмен данными между ОП и дисковой памятью;
6.Целесообразно, чтобы ОС поддерживала механизм реализации виртуальной памяти, для чего в ОС должен иметься обработчик прерывания, возникающего при обращении к незагруженному в ОП блоку, и средства взаимодействия с ОП, имеющей блочную организацию;
7.Для многопользовательских ОС должен быть предусмотрен ввод имен пользователей и их паролей, причем передачу пароля от терминала пользователя к ЦП ЭВМ предпочтительнее производить в закодированном виде с целью усложнения проникновения злоумышленников к данным, содержащимся в ЭВМ;
8.ОС должна содержать средства синхронизации взаимодействующих задач, необходимость в использовании которых может возникнуть в следующих случаях:
- при использовании задачами общих данных; - при наличии в задачах критических секций, во время выполнения любой из которых задача не может быть прервана, что в особенности
характерно для ОС в системах реального времени; - при ожидании основной задачей, когда организованная ей вспомогательная задача подготовит для нее данные.
9. ОС должна содержать средства, которые управляют доступом различных задач к файлам на жестком диске; примерами таких средст в являются матрица доступа пользователей к файлам и управление доступом к файлам в зависимости от принадлежности пользователя к тому или иному классу.
10.Задачи пользователей не должны иметь непосредственный доступ к системным ресурсам: портам устройств ввода-вывода, установке векторов прерываний и т.д.; при этом все управление системными ресурсами должно осуществляться только самой ОС, в том числе и по заданию задач пользователей.
2. -Основные этапы моделирования систем
1.Построение математической модели (ММ).
ММ – запись на языке математики законов, управляющих протеканием исследуемого процесса или описывающих функционирование изучаемого объекта. ММ представляет собой компромисс между бесконечной сложностью изучаемого объекта или явления и желаемой простотой его описания.

ММ должна быть достаточно полной для того. чтобы69можно было изучать свойства объекта и в то же время простой для того. чтобы ее анализ существующими в математике и вычислительной технике средствами был возможен.
2. Постановка, исследование и решение вычислительных задач. Величины, входящие в модель, можно разбить на 3 группы: 1)
входные данные X; 2) параметры модели A; 3) выходные данные Y. В динамических задачах решаются 3 типа задач: Прямая задача: по заданному значению X при фиксированных значениях параметров А найти решение Y;
Обратная задача: определение Х по заданному Y при фиксированном А;
Задача идентификации: по заданным Х и Y найти параметры модели А (среди заданного класса моделей).
Как правило, решение вычислительной задачи не удается выразить в виде конечной формулы через входные данные, поэтому пользуются численными методами, которые позволяют свести получение решения к последовательности арифметических операций над значениями входных данных.
3.Выбор или построение численного метода.
На этом этапе возможны два случая: а) решение задачи сводится к последовательному решению стандартных вычислительных задач, для которых разработаны эффективные численные методы, и их нужно только выбрать и применить;
б) для решения задачи нет готовых численных методов и их необходимо разрабатывать с привлечением специалистов или самостоятельно. В том и другом случае необходимо обладать квалификацией для решения задачи наиболее эффективным образом.
4.Алгоритмизация и программирование.
Выбранный на предыдущем этапе численный метод содержит только принципиальную схему решения задачи без детализации. Для решения задачи нужно разработать алгоритм и соответствующую ему программу на одном из языков программирования. Часто для этих целей выбирают пакеты прикладных программ (ППП), соответствующие поставленной задаче.
5.Отладка программы.
На этом этапе устраняются ошибки программирования или моделирования с помощью ППП и проводится тщательное тестирование программы – проверку правильности ее работы на тестовых задачах, имеющих известное решение.
6.Вычисления по программе.
Многократные вычисления по программе с различными входными данными для получения полной картины зависимости решения от входных данных.
7.Обработка и интерпретация результатов.
на этом этапе разрабатываются или используются готовые средства представления результатов (так называемая визуализация) (графики, таблицы, диаграммы и так далее)
8.Проверка качества модели на практике и модификация модели.
На этом этапе выясняется пригодность математической модели для описания исследуемого явления. Результаты моделирования сопоставляются с экспериментальными данными и, в случае их противоречия, происходит возврат к 1-му этапу.
3. -Реляционная алгебра и язык манипулирования данными SQL
Реляционная база данных — это связанная информация, представленная в виде двумерных таблиц.
Для обеспечения максимальной гибкости при работе с данными строки таблицы, по определению, никак не упорядочены.
SQL — это язык, ориентированный специально на реляционные базы данных. Он позволяет исключить большую работу, выполняемую при использовании языка программирования общего назначения. Для создания реляционной базы данных, например на языке С, пришлось бы начать с определения объекта, называемого таблицей, который может иметь произвольное число строк, а затем создавать процедуры для ввода значений в таблицу и для поиска в ней данных.
SQL освобождает от подобной работы. Команды SQL могут выполняться над целой группой таблиц, как над единственным объектом, а также могут оперировать любым количеством информации, которая извлекается или выводится из них как из единого целого.
SQL символизирует структурированный язык запросов (Structured Query Language). Запросы являются наиболее часто используемым аспектом SQL. Есть категория пользователей SQL, которые используют язык только для формулировки запросов.
Что такое запрос? Это команда, которая формулируется для СУБД и требует предоставить определенную указанную информацию. Эта информация обычно выводится непосредственно на экран дисплея компьютера или используемый терминал, хотя в ряде случаев ее можно направить на принтер, сохранить в файле или использовать в качестве исходных данных для другой команды или процесса.
Язык SQL
Как и большинство современных реляционных языков, SQL основан на исчислении кортежей. В результате, каждый запрос, сформулированный с помощью исчисления кортежей (или иначе говоря, реляционной алгебры), может быть также сформулирован с помощью SQL. Однако, он имеет способности, лежащие за пределами реляционной алгебры или исчисления. Вот список некоторых дополнительных свойств, предоставленных SQL, которые не являются частью реляционной алгебры или исчисления:
Команды вставки, удаления или изменения данных.
Арифметические возможности: в SQL возможно вызвать арифметические операции, так же как и сравнения, например A < B + 3. Заметим, что + или других арифметических операторов нет ни в реляционной алгебре ни в реляционном исчислении.
Команды присвоения и печати: возможно напечатать отношение, созданное запросом и присвоить вычисленному отношению имя отношения.
Итоговые функции: такие операции как average, sum, max, и т.д. могут применяться к столбцам отношения для получения единичной величины.
Выборка
Наиболее часто используемая команда SQL - это оператор SELECT, используемый для получения данных. Синтаксис: SELECT [ALL|DISTINCT]
{ * | expr_1 [AS c_alias_1] [, ...
[, expr_k [AS c_alias_k]]]}
FROM table_name_1 [t_alias_1]
[, ... [, table_name_n [t_alias_n]]]
[WHERE condition] [GROUP BY name_of_attr_i
[,... [, name_of_attr_j]] [HAVING condition]] [{UNION [ALL] | INTERSECT | EXCEPT} SELECT ...] [ORDER BY name_of_attr_i [ASC|DESC]
[, ... [, name_of_attr_j [ASC|DESC]]]];

70
Итоговые операторы
SQL снабжён итоговыми операторами (например AVG, COUNT, SUM, MIN, MAX), которые принимают название атрибута в качестве аргумента. Значение итогового оператора высчитывается из всех значений заданного атрибута(столбца) всей таблицы. Если в запросе указана группа, то вычисления выполняются только над значениями группы (смотри следующий раздел).
Итоги по группам
SQL позволяет разбить кортежи таблицы на группы. После этого итоговые операторы, описанные выше, могут применяться к группам (т.е. значение итогового оператора вычисляется не из всех значений указанного столбца, а над всеми значениями группы. Таким образом, итоговый оператор вычисляет индивидуально для каждой группы.)
Разбиение кортежей на группы выполняется с помощью ключевых слов GROUP BY и следующим за ними списком атрибутов, которые определяют группы. Если мы имеем GROUP BY A1, ⃛, Ak мы разделяем отношение на группы так, что два кортежа будут в одной группе, если у них соответствуют все атрибуты A1, ⃛, Ak.
Заметим, что для получения результата запроса, использующего GROUP BY и итоговых операторов, атрибуты сгруппированных значений должны также быть в списке объектов. Все остальные атрибуты, которых нет в выражении GROUP BY, могут быть выбраны при использовании итоговых функций. С другой стороны ты можешь не использовать итоговые функции на атрибутах, имеющихся в выражении
GROUP BY.
Having
Оператор HAVING выполняет ту же работу что и оператор WHERE, но принимает к рассмотрению только те группы, которые удовлетворяют определению оператора HAVING. Выражения в операторе HAVING должны вызывать итоговые функции. Каждое выражение, использующее только простые атрибуты, принадлежат оператору WHERE. С другой стороны каждое выражение вызывающее итоговую функцию должно помещаться в оператор HAVING.
Подзапросы
В операторах WHERE и HAVING используются подзапросы (вложенные выборки), которые разрешены в любом месте, где ожидается значение. В этом случае значение должно быть получено предварительно подсчитав подзапрос. Использование подзапросов увеличивает выражающую мощность SQL.
Объединение, пересечение, исключение
Эти операции вычисляют объединение, пересечение и теоретико-множественное вычитание кортежей из двух подзапросов.
Определение данных
Существует набор команд, использующихся для определения данных, включенных в язык SQL.
Создание таблицы
Самая основная команда определения данных - это та, которая создаёт новое отношение (новую таблицу). Синтаксис команды CREATE TABLE:
CREATE TABLE table_name
(name_of_attr_1 type_of_attr_1 [, name_of_attr_2 type_of_attr_2
[, ...]]);
Типы данных SQL
Вот список некоторых типов данных, которые поддерживает SQL:
INTEGER: знаковое полнословное двоичное целое (31 бит для представления данных).
SMALLINT: знаковое полсловное двоичное целое (15 бит для представления данных).
DECIMAL (p[,q]): знаковое упакованное десятичное число с p знаками представления данных, с возможным q знаками справа от десятичной точки. (15 ≥ p ≥ qq ≥ 0). Если q опущено, то предполагается что оно равно 0.
FLOAT: знаковое двусловное число с плавающей точкой.
CHAR(n): символьная строка с постоянной длиной n.
VARCHAR(n): символьная строка с изменяемой длиной, максимальная длина n.
Создание индекса
Индексы используются для ускорения доступа к отношению. Если отношение R проиндексировано по атрибуту A, то мы можем получить все кортежи t имеющие t(A) = a за время приблизительно пропорциональное числу таких кортежей t, в отличие от времени, пропорциональному размеру R.
Для создания индекса в SQL используется команда CREATE INDEX. Синтаксис: CREATE INDEX index_name
ON table_name ( name_of_attribute );
Создание представлений
Представление можно рассматривать как виртуальную таблицу, т.е. таблицу, которая в базе данных не существует физически, но для пользователя она как-бы там есть. По сравнению, если мы говорим о базовой таблице, то мы имеем в виду таблицу, физически хранящую каждую строку где-то на физическом носителе.
Представления не имеют своих собственных, физически самостоятельных, различимых хранящихся данных. Вместо этого, система хранит определение представления (т.е. правила о доступе к физически хранящимся базовым таблицам в порядке претворения их в представление) где-то в системных каталогах . Для определения представлений в SQL используется команда CREATE VIEW. Синтаксис:
CREATE VIEW view_name
AS select_stmt
где select_stmt, допустимое выражение выборки, как определено в Выборка. Заметим, что select_stmt не выполняется при создании представления. Оно только сохраняется в системных каталогах и выполняется всякий раз когда делается запрос представления.
Drop Table, Drop Index, Drop View
Для уничтожения таблицы (включая все кортежи, хранящиеся в этой таблице) используется команда DROP TABLE:
DROP TABLE table_name;
Для уничтожения таблицы SUPPLIER используется следующее выражение:
DROP TABLE SUPPLIER;