

Бонус от Юли Захаровой Гос экзамены с ответами
.pdf21
В состав функциональных типов (function type) включаются следующие элементы приложений разрабатываемой системы:
1. Внутренний логический файл (Internal Logical File, ILF) - идентифицируемая совокупность логически взаимосвязанных записей данных, поддерживаемая внутри приложения посредством элементарного процесса (рис. 10.3).
Рис. 10.3. Внутренний логический файл
2. Внешний интерфейсный файл (External Interface File, EIF) - идентифицируемая совокупность логически взаимосвязанных записей данных, передаваемых другому приложению или получаемых от него и поддерживаемых вне данного приложения (рис. 10.4).
Рис. 10.4. Внешний интерфейсный файл
3. Входной элемент приложения (External Input, EI) - элементарный процесс, связанный с обработкой входной информации приложения - входного документа или экранной формы. Обрабатываемые данные могут соответствовать одному или более ILF (рис. 10.5).
Рис. 3.5. Входной элемент приложения
4. Выходной элемент приложения (External Output, EO) - элементарный процесс, связанный с обработкой выходной информации приложения - выходного отчета, документа, экранной формы (рис. 10.6).
Рис. 10.6. Выходной элемент приложения
5. Внешний запрос (External Query, EQ) - элементарный процесс, состоящий из комбинации «запрос/ответ», не связанной с вычислением производных данных или обновлением ILF (базы данных) (рис. 10.7).
Рис. 10.7. Внешний запрос
10.2.2. ОПРЕДЕЛЕНИЕ КОЛИЧЕСТВА И СЛОЖНОСТИ ФУНКЦИОНАЛЬНЫХ ТИПОВ ПО ДАННЫМ
Количество функциональных типов по данным (внутренних логических файлов и внешних интерфейсных файлов) определяется на основе диаграмм «сущность-связь» (для структурного подхода) и диаграмм классов (для объектно-ориентированного подхода). В последнем случае в расчете участвуют только устойчивые (persistent) классы.
Устойчивый класс соответствует ILF (если его объекты обязательно создаются внутри самого приложения) или EIF (если его объекты не создаются внутри самого приложения, а получаются в результате запросов к базе данных).
Примечание. Если операции класса являются операциями-запросами, то это характеризует его принадлежность к EIF.
Далее для каждого выявленного функционального типа (ILF и EIF) определяется его сложность (низкая, средняя или высокая). Она зависит от количества связанных с этим функциональным типом элементарных данных (Data Element Types, DET) и элементарных записей (Record Element Types, RET), которые, в свою очередь, определяются следующим образом:
DET - уникальный идентифицируемый нерекурсивный элемент данных (включая внешние ключи), входящий в ILF или EIF;
RET - идентифицируемая подгруппа элементов данных, входящая в ILF или EIF. На диаграммах «сущность-связь» такая подгруппа обычно представляется в виде сущности-подтипа в связи «супертип-подтип».

Один DET соответствует отдельному атрибуту или связи22класса. Количество DET не зависит от количества объектов класса или количества связанных объектов. Если данный класс связан с некоторым другим классом, который обладает явно заданным идентификатором, состоящим более чем из одного атрибута, то для каждого такого атрибута определяется один отдельный DET (а не один DET на всю связь). Производные атрибуты могут игнорироваться. Повторяющиеся атрибуты одинакового формата рассматриваются как один DET.
Одна RET на диаграмме устойчивых классов соответствует либо абстрактному классу в связи обобщения (generalization), либо классу - «части целого» в композиции, либо классу с рекурсивной связью «родитель-потомок» (агрегацией).
Зависимость сложности функциональных типов от количества DET и RET определяется следующей таблицей (табл. 10). Таблица 10.
Зависимость сложности ILF и EIF от количества DET и RET
Количество RET |
Количество DET |
|
|
|
|
|
1 - 19 |
20 - 50 |
51 + |
2 |
|
Низкая |
Низкая |
Средняя |
2 |
– 5 |
Низкая |
Средняя |
Высокая |
6 |
+ |
Средняя |
Высокая |
Высокая |
10.2.3. ОПРЕДЕЛЕНИЕ КОЛИЧЕСТВА И СЛОЖНОСТИ ТРАНЗАКЦИОННЫХ ФУНКЦИОНАЛЬНЫХ ТИПОВ
Количество транзакционных функциональных типов (входных элементов приложения, выходных элементов приложения и внешних запросов) определяется на основе выявления входных и выходных документов, экранных форм, отчетов, а также по диаграммам классов (в расчете участвуют граничные классы).
Далее для каждого выявленного функционального типа (EI, ЕО или EQ) определяется его сложность (низкая, средняя или высокая). Она зависит от, количества связанных с этим функциональным типом DET, RET и файлов типа ссылок (File Type Referenced, FTR) - ILF или EIF, читаемых или модифицируемых функциональным типом.
Правила расчета DET для El:
каждое нерекурсивное поле, принадлежащее (поддерживаемое) ILF и обрабатываемое во вводе; каждое поле, которое через процесс ввода поддерживается в ILF;
логическое поле, которое физически представляет собой множество полей, но воспринимается пользователем как единый блок информации;
группа полей, которые появляются в ILF более одного раза, но в связи с особенностями алгоритма их использования воспринимаются как один DET;
группа полей, которые фиксируют ошибки в процессе обработки или подтверждают, что обработка закончилась успешно; действие, которое может быть выполнено во вводе.
Правила расчета DET для ЕО:
каждое распознаваемое пользователем нерекурсивное поле, участвующее в процессе вывода; поле, которое физически отображается в виде нескольких полей, его составляющих, но используемое как единый информационный
элемент; каждый тип метки и каждое значение числового эквивалента при графическом выводе;
текстовая информация, которая может содержать одно слово, предложение или фразу; литералы не могут считаться элементами данных;
переменные, определяющие номера страниц или генерируемые системой логотипы, не являются элементами данных.
Правила расчета DET для EQ
Правила определения DET для вводной части:
каждое распознаваемое пользователем нерекурсивное поле, появляющееся во вводной части запроса; каждое поле, которое определяет критерий выбора данных;
группа полей, в которых выдаются сообщения о возникающих ошибках в процессе ввода информации в DET или подтверждающих успешное завершение процесса ввода;
группа полей, которые позволяют выполнять запросы.
Правила определения DET для выводной части:
каждое распознаваемое пользователем нерекурсивное поле, которое появляется в выводной части запроса; логическое поле, которое физически отображается как группа полей, однако воспринимается пользователем как единое поле; группа полей, которые в соответствии с методикой обработки могут повторяться в ILF;
литералы не могут считаться DET;
колонтитулы или генерируемые системой пиктограммы не могут считаться DET.
Зависимость сложности функциональных типов от количества DET, RET или FTR определяется по табл. 11 и 12. Таблица 11.
Зависимость сложности EI от количества DET, RET или FTR
|
Количество FTR |
Количество DET |
|
|
|
|
|
|
1 - 4 |
5 - 15 |
16 + |
|
0 |
- 1 |
Низкая |
Низкая |
Средняя |
|
2 |
|
Низкая |
Средняя |
Высокая |
|
3 |
+ |
Средняя |
Высокая |
Высокая |
Таблица 12. |
|
|
|
|
|
Зависимость ложности ЕО от количества DET и FTR |
|
|
|||
|
Количество FTR |
Количество DET |
|
|
|
|
|
|
1 - 5 |
6 - 19 |
20 + |
|
0 |
- 1 |
Низкая |
Низкая |
Средняя |
|
2 |
– 3 |
Низкая |
Средняя |
Высокая |
|
4 |
+ |
Средняя |
Высокая |
Высокая |
Сложность EQ определяется как максимальная суммированием значений EI и ЕО, связанных с данным запросом.
10.2.4. ПОДСЧЕТ КОЛИЧЕСТВА ФУНКЦИОНАЛЬНЫХ ТОЧЕК
Для каждого функционального |
типа подсчитывается23количество входящих в его состав функциональных точек (Function Point, |
||||||
FP) - условных элементарных единиц. Этот подсчет выполняется в соответствии с табл. 13. |
|
|
|||||
Таблица 13. |
|
|
|
|
|
||
Зависимость количества FP от сложности функционального типа |
|
|
|
||||
|
Функциональны |
|
Сложность |
|
|
|
|
|
й тип |
|
низкая |
|
средняя |
высокая |
|
|
ILF |
|
7 |
|
10 |
15 |
|
|
EIF |
|
5 |
|
7 |
10 |
|
|
EI |
|
3 |
|
4 |
6 |
|
|
EO |
|
4 |
|
5 |
7 |
|
|
EQ |
|
3 |
|
4 |
6 |
|
В результате суммирования количества FP по всем функциональным типам получается общее количество FP (UFP, Unadjusted Function Points) без учета поправочного коэффициента. Значение поправочного коэффициента (VAF, Value Adjustment Factor) определяется набором из 14 общих характеристик системы (GSC, General System Characteristics) и вычисляется по формуле
VAF = (0,65 + (sum GSC * 0,01)).
Значения GSC варьируются в диапазоне от 0 до 5 и определяются по табл.14 - 27.
|
|
Таблица 14. |
|
|
Коммуникации данных |
0 |
Полностью пакетная обработка на локальном ПК |
|
1 |
Пакетная обработка, удаленный ввод данных или удаленная печать |
|
2 |
Пакетная обработка, удаленный ввод данных и удаленная печать |
|
3 |
Сбор данных в режиме «он-лайн» или дистанционная обработка, связанная с пакетным процессом |
|
4 |
Несколько внешних интерфейсов, один тип коммуникационного протокола |
|
5 |
Несколько внешних интерфейсов, более одного типа коммуникационного протокола |
|
|
|
Таблица 15. |
|
|
Распределенная обработка данных |
0 |
|
Передача данных или процессов между компонентами системы отсутствует |
1 |
|
Приложение готовит данные для обработки на ПК конечного пользователя |
2 |
|
Данные готовятся для передачи, затем передаются и обрабатываются на другом компоненте системы |
|
|
(не на ПК конечного пользователя) |
3 |
|
Распределенная обработка и передача данных в режиме «он-лайн» только в одном направлении |
4 |
|
Распределенная обработка и передача данных в режиме «он-лайн» в обоих направлениях |
5 |
|
Динамическое выполнение процессов в любом подходящем компоненте системы |
|
|
Таблица 16. |
|
|
Производительность |
0 |
К системе не предъявляется специальных требований, касающихся производительности |
|
1 |
Требования к производительности определены, но не требуется никаких специальных действий |
|
2 |
Время реакции или пропускная способность являются критическими в пиковые периоды. Не |
|
|
|
требуется никаких специальных решений относительно использования ресурсов процессора. Обработка |
|
|
может быть завершена в течение следующего рабочего дня |
3 |
Время реакции или пропускная способность являются критическими в обычное рабочее время. Не |
|
|
|
требуется никаких специальных решений относительно использования ресурсов процессора. Время |
|
|
обработки ограничено взаимодействующими системами |
4То же, что в случае 3, кроме того, пользовательские требования к производительности достаточно
серьезны, чтобы ее необходимо было анализировать на стадии проектирования
5То же, что в случае 4, кроме того, на стадиях проектирования, разработки и/или реализации для
удовлетворения пользовательских требований к производительности используются специальные средства анализа
Таблица 17.
Эксплуатационные ограничения
0Какие-либо явные или неявные ограничения отсутствуют
1Эксплуатационные ограничения присутствуют, но не требуют никаких специальных усилий
2Должны учитываться некоторые ограничения, связанные с безопасностью или временем реакции
3Должны учитываться конкретные требования к процессору со стороны конкретных компонентов
приложения
4Заданные эксплуатационные ограничения требуют специальных ограничений на выполнение
приложения в центральном или выделенном процессоре
5То же, что в случае 4, кроме того, специальные ограничения затрагивают распределенные
компоненты системы
Таблица 18.
Частота транзакций
0 |
Пиковых периодов не ожидается |
1 |
Ожидаются пиковые периоды (ежемесячные, ежеквартальные, ежегодные) |
2 |
Ожидаются еженедельные пиковые периоды |
3 |
Ожидаются ежедневные пиковые периоды |
24
4Высокая частота транзакций требует анализа производительности на стадии проектирования
5То же, что в случае 4, кроме того, на стадиях проектирования, разработки и/или внедрения
необходимо использовать специальные средства анализа производительности
Таблица 19.
Ввод данных в режиме «он-лайн»
0 |
Все транзакции обрабатываются в пакетном режиме |
|
1 |
От 1 |
до 7% транзакций требуют интерактивного ввода данных |
2 |
От 8 |
до 15% транзакций требуют интерактивного ввода данных |
3 |
От 16 до 23% транзакций требуют интерактивного ввода данных |
|
4 |
От 24 до 30% транзакций требуют интерактивного ввода данных |
|
5 |
Более 30% транзакций требуют интерактивного ввода данных |
|
Таблица 20.
Эффективность работы конечных пользователей*
0Ни одной из перечисленных функциональных возможностей*
1От одной до трех функциональных возможностей
2От четырех до пяти функциональных возможностей
3Шесть или более функциональных возможностей при отсутствии конкретных пользовательских
требований к эффективности
4То же, что в случае 3, кроме того, пользовательские требования к эффективности включают
специальные проектные решения для учета эргономических факторов (например, минимизации нажатий клавиш, максимизации значений по умолчанию, использования шаблонов)
5То же, что в случае 4, кроме того, пользовательские требования к эффективности включают
применение специальных средств и процессов, демонстрирующих их выполнение
*Эффективность работы конечных пользователей определяется наличием следующих функциональных возможностей: средств навигации (например, функциональные клавиши, динамически генерируемые меню); меню; онлайновых подсказок и документации;
автоматического перемещения курсора; скроллинга; удаленной печати;
предварительно назначенных функциональных клавиш; выбора данных на экране с помощью курсора;
использования видеоэффектов, цветового выделения, подчеркивания и других индикаторов;
всплывающих окон; минимизации количества экранов, необходимых для выполнения бизнес-функций; поддержкой двух и более языков.
Таблица 21.
Онлайновое обновление
0Отсутствует
1Онлайновое обновление от одного до трех управляющих файлов. Объем обновлений незначителен,
восстановление несложно
2Онлайновое обновление четырех или более управляющих файлов. Объем обновлений
незначителен, восстановление несложно
3Онлайновое обновление основных внутренних логических файлов
4То же, что в случае 3, плюс необходимость специальной защиты от потери данных
5То же, что в случае 4, кроме того, большой объем данных требует учета затрат на процесс
восстановления. Требуются автоматизированные процедуры восстановления с минимальным вмешательством оператора
Таблица 22.
Сложная обработка*
0 |
Ни одной из перечисленных функциональных возможностей* |
1 |
Любая одна из возможностей |
2 |
Любые две из возможностей |
3 |
Любые три из возможностей |
4 |
Любые четыре из возможностей |
5 |
Все пять возможностей |
* Сложная обработка характеризуется наличием у приложения следующих функциональных возможностей: повышенной реакцией на внешние воздействия и/или специальной защитой от внешних воздействий; экстенсивной логической обработкой; экстенсивной математической обработкой;
обработкой большого количества исключительных ситуаций; поддержкой разнородных типов входных/выходных данных.
Таблица 23.
Повторное использование
0 Отсутствует

|
25 |
1 |
Повторное использование кода внутри одного приложения |
2 |
Не более 10% приложений будут использоваться более чем одним пользователем |
3 |
Более 10% приложений будут использоваться более чем одним пользователем |
4 |
Приложение оформляется как продукт и/или документируется для облегчения повторного |
|
использования. Настройка приложения выполняется пользователем на уровне исходного кода |
5 |
То же, что в случае 4, с возможностью параметрической настройки приложений |
Таблица 24.
Простота установки
0 |
К установке не предъявляется никаких специальных требований |
1 |
Для установки требуется специальная процедура |
2 |
Заданы пользовательские требования к конвертированию (переносу существующих данных и |
|
приложений в новую систему) и установке, должны быть обеспечены и проверены соответствующие |
|
руководства. Конвертированию не придается важное значение |
3 |
То же, что и в случае 2, однако конвертированию придается важное значение |
4 |
То же, что и в случае 2, плюс наличие автоматизированных средств конвертирования и установки |
5 |
То же, что и в случае 3, плюс наличие автоматизированных средств конвертирования и установки |
Таблица 25.
Простота эксплуатации
0 |
|
К эксплуатации не предъявляется никаких специальных требований, за исключением обычных |
|
|
процедур резервного копирования |
1 |
- |
Приложение обладает одной, несколькими или всеми из перечисленных далее возможностей. |
4 |
|
Каждая возможность, за исключением второй, обладает единичным весом: 1) наличие процедур запуска, |
|
|
копирования и восстановления с участием оператора; 2) то же, без участия оператора; 3) минимизируется |
|
|
необходимость в монтировании носителей для резервного копирования; 4) минимизируется |
|
|
необходимость в средствах подачи и укладки бумаги при печати |
5 |
|
Вмешательство оператора требуется только при запуске и завершении работы системы. |
|
|
Обеспечивается автоматическое восстановление работоспособности приложения после сбоев и ошибок |
Таблица 26.
Количество возможных установок на различных платформах
0Приложение рассчитано на установку у одного пользователя
1Приложение рассчитано на много установок для строго стандартной платформы (технические
средства плюс программное обеспечение)
2Приложение рассчитано на много установок для платформ с близкими характеристиками
3Приложение рассчитано на много установок для различных платформ
4То же, что в случаях 1 или 2, плюс наличие документации и планов поддержки всех установленных
копий приложения
5То же, что в случае 3, плюс наличие документации и планов поддержки всех установленных копий
приложения
Таблица 27.
Гибкость*
0Ни одной из перечисленных возможностей*
1Любая одна из возможностей
2Любые две из возможностей
3Любые три из возможностей
4Любые четыре из возможностей
5Все пять возможностей
* Гибкость характеризуется наличием у приложения следующих возможностей:
поддержкой простых запросов, например логики и/или в применении только к одному ILF (вес - 1);
поддержкой запросов средней сложности, например логики и/или в применении более чем к одному ILF (вес - 2);
поддержкой сложных запросов, например комбинации логических связок и/или в применении к одному или более ILF (вес - 3); управляющая информация хранится в таблицах, поддерживаемых пользователем в интерактивном режиме, однако эффект от ее
изменений проявляется на следующий рабочий день; то же, что в предыдущем случае, но эффект проявляется немедленно (вес - 2).
После определения всех значений GSC и вычисления поправочного коэффициента VAF вычисляется итоговая оценка количества функциональных точек (Adjusted Function Points, AFP):
AFP = UFP * VAF.
10.2.5. ОЦЕНКА ТРУДОЕМКОСТИ РАЗРАБОТКИ Вариант 1.
По таблице 28 (данные SPR) определяется количество строк кода (SLOC) на одну функциональную точку в зависимости от используемого языка программирования.
Таблица 28.
Количество строк кода на одну функциональную точку
Язык (средство) |
Количество SLOC на FP |
ABAP/4 |
16 |
Access |
38 |

26
ANSI SQL |
13 |
C++ |
53 |
Clarion |
58 |
Data base default |
40 |
Delphi 5 |
18 |
Excel 5 |
6 |
FoxPro 2.5 |
34 |
Oracle Developer |
23 |
PowerBuilder |
16 |
Smalltalk |
21 |
Visual Basic 6 |
24 |
Visual C++ |
34 |
HTML 4 |
14 |
Java 2 |
46 |
Умножая AFP на количество SLOC на FP, получаем количество SLOC в приложении.
Далее используется один из (вариантов известной модели оценки трудоемкости разработки ПО под названием СОСОМО (Constructive Cost Model), опубликованной в книге Б.У. Боэма1, и ее современной версии СОСОМО II.
В табл. 29 приведены значения линейного коэффициента производительности (LPF), полученные в СОСОМО. Таблица 29.
Линейный коэффициент производительности
Тип проекта |
LPF |
COCOMO II Default |
2,94 |
Встроенное ПО |
2,58 |
Электронная коммерция |
3,60 |
Web-приложения |
3,30 |
Военные разработки |
2,77 |
Трудоемкость разработки (количество человеко-месяцев) вычисляется по следующей формуле: Трудоемкость = LPF * KSLOC,
где KSLOC - количество тысяч строк кода в приложении.
Приведенная формула применяется для проектов малого размера, а для больших проектов учитывается ESPF, значения которого приведены в табл. 30.
Таблица 30.
Экспоненциальный коэффициент размера
Тип проекта |
ESPF |
COCOMO II Default |
1,052 |
Встроенное ПО |
1,110 |
Электронная коммерция |
1,030 |
Web-приложения |
1,030 |
Военные разработки |
1,072 |
С учетом данного коэффициента Трудоемкость = LPF * KSLOCESPF.
Подсчитанная таким образом трудоемкость подлежит дальнейшему уточнению с учетом поправок на характеристики среды разработки. Эти характеристики учитываются в двух поправочных коэффициентах: нелинейном коэффициенте среды (NEF) и линейном коэффициенте среды (LEF), значения которых приведены в табл. 31 и 32.
Таблица 31.
Нелинейный коэффициент среды
|
|
Значение |
|
|
|
Фактор |
низкое |
номинально |
высокое |
|
|
е |
||
|
|
|
|
|
|
Архитектурный риск |
0,0423 |
0,014 |
-0,0284 |
|
Гибкость среды разработки |
0,0223 |
0,002 |
-0,0284 |
|
Уровень знания новых технологий и предметной |
0,0336 |
0,0088 |
-0,0284 |
|
области |
|
|
|
|
Зрелость процессов в организации |
0,0496 |
0,0814 |
-0,0284 |
|
Сплоченность проектной команды |
0,0264 |
0,0045 |
-0,0284 |
Таблица 32. |
|
|
|
|
Линейный коэффициент среды |
|
|
|
|
|
|
Значение |
|
|
|
Фактор |
низкое |
номинально |
высокое |
|
|
е |
||
|
|
|
|
|
|
Квалификация аналитиков |
1,42 |
1,00 |
0,71 |
|
Опыт разработки приложений |
1,22 |
1,00 |
0,81 |
|
Опыт работы с языками и инструментальными |
1,20 |
1,00 |
0,84 |
|
средствами |
|
|
|
1 См.: Боэм Б. У. Инженерное проектирование программного обеспечения: Пер. с англ. - М: Радио и связь, 1985.
27
Преемственность персонала |
1,29 |
1,00 |
0,81 |
Квалификация руководства |
1,18 |
1,00 |
0,87 |
Опыт руководства |
1,11 |
1,00 |
0,90 |
Опыт работы с данной платформой |
1,19 |
1,00 |
0,85 |
Квалификация программистов |
1,34 |
1,00 |
0,76 |
Ограничения на время выполнения |
1,00 |
1,00 |
1,63 |
Ограничения на объем памяти |
1,00 |
1,00 |
1,46 |
Нестабильность платформы |
0,87 |
1,00 |
1,30 |
Эффективность средств управления |
1,22 |
1,00 |
0,84 |
Распределенная разработка |
1,22 |
1,00 |
0,80 |
Эргономика офиса |
1,19 |
1,00 |
0,82 |
Использование CASE-средств |
1,17 |
1,00 |
0,78 |
Размер базы данных |
0,90 |
1,00 |
1,28 |
Требуемая степень документированности |
0,81 |
1,00 |
1,23 |
Интернационализация |
0,97 |
1,00 |
1,35 |
Сложность продукта |
0,75 |
1,00 |
1,66 |
Степень повторного использования |
0,95 |
1,00 |
1,24 |
Требуемая надежность |
0,82 |
1,00 |
1,26 |
Графика и мультимедиа |
0,95 |
1,00 |
1,35 |
Интеграция с унаследованным ПО |
1,00 |
1,00 |
1,18 |
Уровень безопасности |
0,92 |
1,00 |
1,40 |
Необходимость выбора инструментальных средств |
0,95 |
1,00 |
1,14 |
Интенсивность транзакций |
0,96 |
1,00 |
1,59 |
Разработка для использования в Web |
0,88 |
1,00 |
1,45 |
Сумма значений NEF добавляется к значению ESPF.
Значение трудоемкости, подсчитанное с учетом NEF, последовательно умножается на все выбранные значения LEF. Срок разработки можно определить с помощью коэффициента преобразования (CF) по следующей формуле:
Срок разработки = CF * Трудоемкость0,33, где значение CF определяется по табл. 33.
Таблица 33.
Коэффициент преобразования
Тип проекта |
CF |
COCOMO II Default |
3,67 |
Встроенное ПО |
4,00 |
Электронная коммерция |
3,20 |
Web-приложения |
3,10 |
Военные разработки |
3,80 |
Вариант 2
Используется промежуточная модель COCOMO, в соответствии с которой номинальную трудоёмкость (без учета коэффициентов затрат труда, стоимостных факторов и сложности) можно вычислить по формуле
Трудоемкость = N1 * KSLOCN2.
Значения N1 и N2 определяются по табл. 34.
Таблица 34.
Коэффициенты N1 и N2
Тип ПО |
N1 |
N2 |
Распространенное |
3,2 |
1,05 |
Полунезависимое |
3,0 |
1,12 |
Встроенное |
2,8 |
1,20 |
Распространенное ПО - ПО небольшого объема (не более 50 K.SLOC), разрабатываемое относительно небольшой группой опытных специалистов в стабильных условиях.
Полунезависимое ПО - ПО среднего объема (не более 300 KSLOQ, разрабатываемое неоднородной группой специалистов средней квалификации.
Встроенное ПО - ПО с жесткими ограничениями (система резервирования авиабилетов, система управления воздушным движением и т.п.).
Время разработки вычисляется по формуле Время = 2,5 * ТрудоемкостьN3.
Значения N3 приведены в табл. 35.
Таблица 35. Коэффициент N3
Тип ПО |
N3 |
Распространенное |
0,38 |
Полунезависимое |
0,35 |
Встроенное |
0,32 |
Время разработки может быть изменено с учетом статистических данных, накопленных в реальных проектах и отраженных в табл. 36, где сопоставлены планируемый и реальный сроки выполнения проекта в зависимости от его размера, выраженного в количестве
функциональных точек. Частично это отставание объясняется28неточной оценкой, частично - ростом количества требований к системе после того, как выполнена начальная оценка.
Таблица 36.
Статистические данные
Размер проекта |
|
<100 |
100-1000 FP |
1000-10000 FP |
>10000 |
|
FP |
|
|
|
FP |
Планируемый срок (мес.) |
|
6 |
12 |
18 |
24 |
Реальный срок (мес.) |
|
8 |
16 |
24 |
36 |
Отставание |
|
2 |
4 |
6 |
12 |
2. -Управляемость и наблюдаемость динамических систем
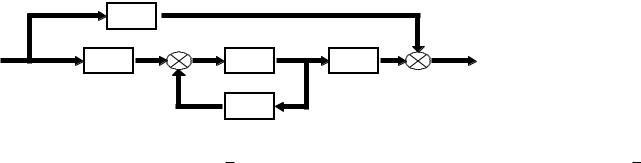
Для линейных динамических систем, представленных на рис. 1, и описываемых уравнениями в пространстве состояний порядка n
x Ax Bu ,
y Cx Du ,
полная управляемость означает существование ограниченного входного сигнала u , переводящего объект за конечный интервал
времени из любого начального состояния x 0 в любое наперёд заданное состояние x . Если бы объект не был полностью управляемым, то нельзя рассчитывать на то, что замкнутой системе, содержащей этот объект, можно придать любые динамические свойства, т.е. желаемое расположение корней.
Условием полной управляемости объекта является равенство ранга его матрицы управляемости Q y порядку n объекта. Матрица
управляемости выражается через параметры объекта формулой
Qy B AB A2B An -1B .
Матрица Q y записана в блочной форме. Если элементы – блоки B, AB, , An-1B записать в развернутой форме, то матрица Q y станет прямоугольной типа n mn .
D
u |
|
x |
|
x |
y |
|
B |
|
|
С |
|
|
|
|
A |
|
|
Рис. 1 Схема многомерной системы в пространстве состояний
Наблюдаемость – произвольное состояние x(t0 ) можно найти по имеющимися записям вектора выходного сигнала y(t) (t>t0 ). Условием наблюдаемости является равенство ранга матрицы Q порядку системы n :
C |
|
||
|
C A |
|
|
Q |
|
||
|
|||
........ |
|
||
C A n 1 |
|
||
|
|
|
|
3. +Эргономика. Эргономическая экспертиза ЭРГОНОМИКА - научная дисциплина, комплексно изучающая трудовую деятельность человека в системах "человек - техника - среда"
(СЧТС) с целью обеспечения ее эффективности, безопасности и комфорта. Аналогичную область знаний в США называют "человеческими факторами" (human factors).
ЭРГОНОМИЧЕСКАЯ ЭКСПЕРТИЗА - комплекс научно-технических и организационно-методических мероприятий по оценке выполнения в проектных, предпроектных и рабочих документах и в образцах СЧТС эргономических требований технического задания, нормативнотехнических документов, а также по разработке рекомендаций для устранения отступлений от этих требований.
Указанная экспертиза проводится при обосновании выполнения каждого этапа опытно-конструкторской разработки: технического предложения, эскизного проекта, технического проекта, рабочего проекта. Материалы ее - акт либо протокол - включаются в документы, представляемые на защиту проекта.
Эргономическая экспертиза может проводится, например, по таким направлениям, как:
"Интерфейс "человек - компьютер"" по показателям психологическим, психофизиологическим, комфортности, цветовой совместимости элементов, "рабочее место пользователя компьютера" по показателям психологическим, психофизиологическим, антропометрическим, обслуживаемость, осваиваемость.
Билет 10
1. -Функциональная и структурная организация процессора
Процессор, или более полно микропроцессор, а также часто называемый ЦПУ (CPU - central processing unit) является центральным компонентом компьютера. Это разум, который управляет, прямо или косвенно, всем происходящим внутри компьютера. Когда фон Нейман
впервые предложил хранить последовательность инструкций,29так называемые программы, в той же памяти, что и данные, это была поистине новаторская идея. Опубликована она в "First Draft of a Report on the EDVAC" в 1945 году. Этот отчет описывал компьютер состоящим из четырех основных частей: центрального арифметического устройства, центрального управляющего устройства, памяти и средств вводавывода. Сегодня, более полувека спустя, почти все процессоры имеют фон-неймановскую архитектуру.
На первый взгляд, процессор – просто выращенный по специальной технологии кристалл кремния (не зря его ещё называют «камень»). Однако камешек этот содержит в себе множество отдельных элементов – транзисторов, которые в совокупности и наделяют компьютер способностью «думать». Точнее, вычислять, производя определённые математические операции с числами, в которые преображается любая поступающая в компьютер информация. Таких транзисторов в любом микропроцессоре многие миллионы.
Сегодняшний процессор – это не просто скопище транзисторов, а целая система множества важных устройств. На любом процессорном кристалле находятся:
Собственно, процессор, главное вычислительное устройство, состоящее из миллионов логических элементов – транзисторов. Сопроцессор – специальный блок для операций с «плавающей точкой». Применяется для особо точных и сложных расчётов, а так же для
работы с рядом графических программ.
Кэш-память первого уровня – небольшая (несколько десятков килобайт) сверхбыстрая память, предназначенная для хранения промежуточных результатов вычислений.
Кэш-память второго уровня – эта память чуть помедленнее, зато больше – от 128 кбайт до 2048 кбайт.
Все эти устройства размещаются на кристалле площадью не более 4-6 квадратных сантиметров. Только под микроскопом можно разглядеть крохотные элементы, из которых состоит микропроцессор, и соединяющие их металлические «дорожки» (для их изготовления ранее использовали алюминий, сейчас же на смену ему пришла медь). Их размер поражает воображение – десятые доли микрона! Сейчас большая часть процессоров производится по 0,09-микронной технологии. Но это не самое важное. Существуют другие, гораздо более важные для нас характеристики процессора, которые прямо связаны с возможностями и скоростью работы.
Основные функциональные компоненты процессора Ядро: Сердце современного процессора - исполняющий модуль. Современный процессор имеет два параллельных целочисленных
потока, позволяющих читать, интерпретировать, выполнять и отправлять две инструкции одновременно.
Предсказатель ветвлений: Модуль предсказания ветвлений пытается угадать, какая последовательность будет выполняться каждый раз когда программа содержит условный переход, так чтобы устройства предварительной выборки и декодирования получали бы инструкции готовыми предварительно.
Блок плавающей точки. Третий выполняющий модуль внутри процессора, выполняющий нецелочисленные вычисления
Первичный кэш: Pentium имеет два внутричиповых кэша по 8kb, по одному для данных и инструкций, которые намного быстрее большего внешнего вторичного кэша.
Шинный интерфейс: принимает смесь кода и данных в CPU, разделяет их до готовности к использованию, и вновь соединяет, отправляя наружу.
Все элементы процессора синхронизируются с использованием частоты часов, которые определяют скорость выполнения операций. Самые первые процессоры работали на частоте 100kHz, сегодня рядовая частота процессора - 200MHz, иначе говоря, часики тикают 200 миллионов раз в секунду, а каждый тик влечет за собой выполнение многих действий. Счетчик Команд (PC) - внутренний указатель, содержащий адрес следующей выполняемой команды. Когда приходит время для ее исполнения, Управляющий Модуль помещает инструкцию из памяти в регистр инструкций (IR). В то же самое время Счетчик команд увеличивается, так чтобы указывать на последующую инструкцию, а процессор выполняет инструкцию в IR. Некоторые инструкции управляют самим Управляющим Модулем, так если инструкция гласит 'перейти на адрес 2749', величина 2749 записывается в Счетчик Команд, чтобы процессор выполнял эту инструкцию следующей.
Многие инструкции задействуют Арифметико-логическое Устройство (ALU), работающее совместно с Регистрами Общего Назначения - место для временного хранения, которое может загружать и выгружать данные из памяти. Типичной инструкцией ALU может служить добавление содержимого ячейки памяти к регистру общего назначения. ALU также устанавливает биты Регистра Состояний (Status register - SR) при выполнении инструкций для хранения информации о ее результате. Например, SR имеет биты, указывающие на нулевой результат, переполнение, перенос и так далее. Модуль Управления использует информацию в SR для выполнения условных операций, таких как 'перейти по адресу 7410 если выполнение предыдущей инструкции вызвало переполнение'.
Это почти все что касается самого общего рассказа о процессорах - почти любая операция может быть выполнена последовательностью простых инструкций, подобных описанным. Большинство процессоров сегодня применяют поточную обработку (pipelining), которая больше похожа на фабричный конвейер. Одна стадия потока выделена под каждый шаг, необходимый для выполнения инструкции, и каждая стадия передает инструкцию следующей, когда она выполнила свою часть. Это значит, что в любой момент времени одна инструкция загружается, другая декодируется, доставляются данные для третьей, четвертая исполняется, и записывается результат для пятой. При текущей технологии одна инструкция за тик может быть достигнута.
Более того, многие процессоры сейчас имеют суперскалярную архитектуру. Это значит, что схема каждой стадии потока дублируется, так что много инструкций могут передаваться параллельно.
Что отличает микропроцессор от его предшественников, сконструированных из ламп, отдельных транзисторов, малых интегральных схем, такими какими они были первое время от полного процессора на едином кремниевом чипе.
Кремний или силикон - это основной материал из которого производятся чипы. Это полупроводник, который, будучи присажен добавками по специальной маске, становится транзистором, основным строительным блоком цифровых схем. Процесс подразумевает вытравливание транзисторов, резисторов, пересекающихся дорожек и так далее на поверхности кремния.
Сперва выращивается кремневая болванка. Она должна иметь бездефектную кристаллическую структуру, этот аспект налагает ограничение на ее размер. В прежние дни болванка ограничивалась диаметром в 2 дюйма, а сейчас распространены 8 дюймов. На следующей стадии болванка разрезается на слои, называемые пластинами (wafers). Они полируются до безупречной зеркальной поверхности. На этой пластине и создается чип. Обычно из одной пластины делается много процессоров.
Электрическая схема состоит из разных материалов. Например, диоксид кремния - это изолятор, из полисиликона изготавливаются проводящие дорожки. Когда появляется открытая пластина, она бомбардируется ионами для создания транзисторов - это и называется присадкой.
Чтобы создать все требуемые детали, на всю поверхность пластины добавляется слои и лишние части вытравливаются вновь. Чтобы сделать это, новый слой покрывается фоторезистором, на который проектируется образ требуемых деталей. После экспозиции проявление удаляет те части фоторезистора, которые выставлены на свет, оставляя маску, через которую проходило вытравливание. Оставшийся фоторезистор удаляется растворителем.
Говоря о скорости процессора, подразумевается его тактовая частота. Это величина, измеряемая в мегагерцах (МГц), показывает, сколько инструкций способен выполнить процессор в течение секунды. Тактовая частота обознается цифрой в названии процессора (например, Pentium 4-2400, то есть процессор поколения Pentium 4 с тактовой частотой 2400 МГц или 2.4 ГГц).
Тактовая частота – бесспорно, самый важный показатель скорости работы процессора. Но далеко не единственный.
Системная шина (FSB = Front Side Bus или System Bus)30служит для связи процессора с остальным компьютером. Системная шина является основой для формирования частоты других шин передачи данных компьютера – AGP, память, PCI, путем умножения на определенный коэффициент.
Современные процессоры работают быстрее, чем память.Чем медленнее память, тем больше процессору ждать новых данных от нее и ничего не делать. В кэш памяти находятся машинные слова (можно их назвать данными), которые чаще всего используются процессором. Если ему требуется какое-нибудь слово, то он сначала обращается к кэш памяти. Существует принцип локализации, по которому в кэш вместе с требуемым в данный момент словом загружаются также и соседние с ним слова, т.к. велика вероятность того, что они в ближайшее время тоже понадобятся. В современных десктопных процессорах существует два уровня кэш-памяти (для серверов существует процессоры с третьим уровнем кэша, его также). Кэш первого уровня (Level 1 = L1) обычно разделён пополам, половина выделена для данных, а другая половина под инструкции. Кэш второго уровня (Level 2 = L2) предназначается только для данных. Пропускная способность оперативной памяти конечно высока, но кэш память работает в несколько раз быстрее. У старых процессоров микросхемы кэша L2 находились на материнской плате. Скорость работы кэша при этом была довольно низкой (равнялась частоте FSB), но её хватало. У последних процессоров, в целях увеличения быстродействия, упрощения и удешевления производства, кэш L2 интегрирован в ядро и работает на его полной частоте. Чем больше кэш, тем лучше, но с другой стороны, при увеличении кэша увеличивается время выборки (поиска и извлечения) данных из него. Хотя увеличение кэша L2, не смотря на это, почти всегда дает прирост по скорости.
Ядром называют сам процессорный кристалл, ту часть, которая непосредственно является "процессором". Сам кристалл у современных моделей имеет небольшие размеры, а размеры готового процессора увеличиваются очень сильно за счет его корпусировки и разводки. Процессорный кристалл можно увидеть, например, у процессоров Athlon, у них он не закрыт. У P4 вся верхняя часть скрыта под теплорассеивателем (который так же выполняет защитную функцию
Форм-фактор – это тип исполнения процессора, его «внешности» и способа подключения к материнской плате.
Как правило, все элементы процессора расположены на одном и том же кристалле кремния и имеют квадратную форму (тип разъёма «Socket»). Прямоугольный корпус с торчащими из него ножками-контактами.
Процессоры имеют разные разъёмы по причине принципиальных конструктивных отличий (количество транзисторов, архитектура и т. п.). Пока было только два принципиально разных типа разъёмов - Slot и Soсket. По заверениям Intel (но если посмотреть на Pentium Pro, то всё становится ясно), Slot 1 был использован только из-за необходимости помещения кэша поближе к ядру и больше применяться, скорее всего, не будет. Socket же продолжает развиваться - количество контактов все растёт и растёт (если увеличение числа контактов можно считать развитием)
Коэффициент умножения (Frequency Ratio / Multiplier), это то число, на которое умножается частота системной шины, в результате чего получается рабочая частота процессора. Заблокированный коэффициент означает, что процессор будет умножать системную шину всегда на одну и ту же цифру. Т. е. разгон без увеличения частоты шины для такого процессора невозможен.
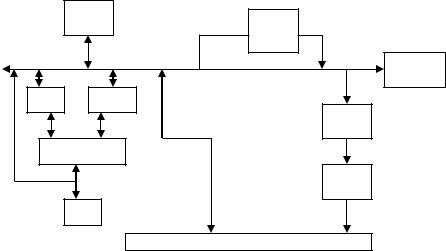
Обобщенная структурная схема процессора.
GR
IP
FB
A |
RB |
RI
ALU
DC
F
CU
IB
Схема состоит из:
GR – регистр общего назначения
ALU – арифметико-логическое устройство A – регистр аккумулятор
RB – буферный регистр
F – регистр флагов (признаков)
IP – указатель команд (счетчик команд) RI (IR) – регистр команд
DC – дешифратор команд CU – устройство управления
IB –внутренняя общая магистраль
FB – устройство сопряжения с внешней шиной.
Код операции попадает в регистр команд, затем в дешифратор и в устройство управления. В регистр флагов записывается:
1)С – carry (переполнение)
2)Z (флаг) – z=1, если результат равен 0, z=0 если результат не равен 0.
3)S – флаг указания положительного или отрицательного результата (положительный – s=0, отрицательный – s=1)
4)P – флаг четности (четное либо нечетное количество единиц в операнде)
р=1 – четное число единиц; р=0 – нечетное число единиц; При выполнении арифметических и логических операций флаги формируются всегда. Флаги помогают организовать ветвление программы.