

Bazy_dannykh_Uchebnik_novy
.pdfВ процессе поиска и извлечения из гиперкуба нужной информации над его измерениями производится ряд действий, наиболее типичными из которых являются:
сечение (срез);
транспонирование;
свертка;
детализация.
Сечение заключается в выделении подмножества ячеек гиперкуба при фиксировании значения одного или нескольких измерений. В результате сечения получается срез или несколько срезов, каждый из которых содержит информацию, связанную со значением измерения, по которому он был построен. Транспонирование – математическая операция,
которая представляет зеркальное отображение данных относительно главной диагонали.
Многомерная модель данных применяется для оперативного анализа данных.
Традиционные отчеты, получаемые в рамках СУБД, лишены одного - гибкости. Их нельзя
"покрутить", "развернуть" или "свернуть", чтобы получить желаемое представление данных. Конкретные OLAP-продукты, как правило, представляют собой либо средство многомерного представления данных, OLAP-клиент (например, Pivot Tables в Excel 2000
фирмы Microsoft или ProClarity фирмы Knosys), либо многомерную серверную СУБД, OLAP-сервер (например, Oracle Express Server или Microsoft OLAP Services). Слой многомерной обработки обычно бывает встроен в OLAP-клиент и/или в OLAP-сервер, но может быть выделен в чистом виде, как, например, компонент Pivot Table Service фирмы
Microsoft.
Внутризаписная структура базы данных
Структура данных, которая является логической единицей хранения данных. На современном этапе развития внутризаписная структура тоже может иметь сложный характер, например в качестве элемента данных могут храниться массивы или более сложные структуры. Потребность усложнения внутризаписной структуры возникает при переходе к хранению объектов, имеющих пространственные характеристики: набор координат. Например, пространственная часть объекта «река» представляет собой однородный массив координат вида ((x1,y1), (x2,y2),(x3,y3), …), описывающих пространственное расположение объекта.
Принципиально возможны довольно сложные структуры, например, когда в состав повторяющейся группы в качестве составляющего компонента входит другая повторяющаяся группа. Однако по разным причинам (в частности, из-за сложности реализации) в конкретных СУБД имеются различные ограничения (например,
31
повторяющаяся группа может существовать только на первом уровне иерархии,
ограничивается число уровней иерархии и т. п.).
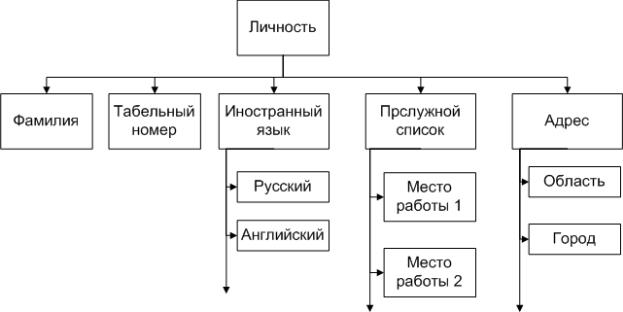
Записи могут быть с постоянным и переменным составом. Последнее обычно понимается так: если значение какого-либо компонента записи отсутствует для конкретного объекта, то и сам этот компонент в данной записи отсутствует. В случае иерархической внутризаписной структуры в состав записи могут входить не только простые, но и составные компоненты. Это могут быть векторы (когда повторяются однотипные элементы), повторяющиеся группы (когда в записи может присутствовать несколько экземпляров составных единиц информации, включающих в себя несколько разнотипных элементов), а также неповторяющиеся составные единицы информации внутри записи – рисунок 12.
Рисунок 12. Пример сложной внутризаписной структуры.
32

4. Реляционная модель базы данных
Терминология
Реляционная модель базы данных по нашей классификации – модель логического уровня.
В реляционной модели используется своеобразная терминология. Понятие «схема отношения» соответствует описанию структуры таблицы. Таблица с заполненными значениями (заполненными строками) соответствует понятие «отношение». Для
Атрибута сущности используются термины "колонки", "столбец", "поле". Совокупность атрибутов образует кортеж (ряд, запись, строку ).
Создателем концепции реляционной модели данных является Эдгар (Тед) Кодд, работавший в то время в компании IBM. Компьютерные вычисления стоили сотни долларов в минуту, так что большие человеческие усилия затрачивались на то, чтобы сделать программы максимально эффективными, прежде чем запустить их на выполнение. Ранние базы данных использовали либо жесткую иерархическую структуру, либо сложный план навигации по указателям на физическое размещение данных на магнитных лентах. Кодд первым обнаружил,
что хранение данных в виде большого массива имеет побочные эффекты, которые он назвал аномалиями.
Кодд выявил три аномалии: аномалия обновления,
аномалия вставки и аномалия удаления.
Рассмотрим таблицу, где хранятся сведения об успеваемости студентов – таблица 2.
Таблица 2. Данные об успеваемости студентов.
№ |
ФИО |
Дисциплина |
Оценка |
Дата |
Преподаватель |
группы |
|
|
|
оценки |
|
|
|
|
|
|
|
105 |
Иванов |
Базы данных |
Отлично |
01.12.2011 |
Смирнов |
|
|
|
|
|
|
105 |
Иванов |
Базы данных |
Хорошо |
10.07.2001 |
Суворову |
|
|
|
|
|
|
105 |
Иванов |
Иностранный |
Хорошо |
25.12.2011 |
Соколова |
|
|
язык |
|
|
|
|
|
|
|
|
|
.. |
|
|
|
|
|
|
|
|
|
|
|
Каждая строка характеризуется тем, что сочетание |
|
|
|||
33
ФИО+Дисциплина+Оценка+Дата_оценки+Преподаватель
является уникальным (является ключом). Имеется в виду, что Иванов сдавал предмет
«Базы данных» дважды - в зимнюю и в летнюю сессию.
Аномалия обновления
Предположим, что в базу данных ошибочно занесена фамилия преподавателя, тогда для исправления ошибки необходимо последовательно проверить все строки таблицы, для чего требуется писать программный код, что, в свою очередь требует времени и сил.
Аномалия вставки
Если в группу приходит новый студент, то в таблицу необходимо вставить записи со всеми его дисциплинами по учебному плану. Но оценок на данный момент по ним еще нет. Формально необходимо вставить в базу данных строчки – таблица 3.
|
|
Таблица 3. Новые строки для добавления в базу. |
|||
|
|
|
|
|
|
105 |
Сидоров |
Базы данных |
|
|
|
|
|
|
|
|
|
105 |
Сидоров |
Базы данных |
|
|
|
|
|
|
|
|
|
что нарушает уникальность ключа
ФИО+Дисциплина+Оценка+Дата_оценки+Преподаватель .
Нарушение уникальности ключа приведет к появлению программной ошибке при попытке выполнить данное действие.
Аномалия удаления
Предположим, что в учебный план внесены изменения и вместо одной дисциплины появилась другая, которую студенты пересдают и получают новые оценки. В этом случае удаляется полезная информация о том, какие оценки были по старой дисциплине.
Причины аномалий причина подобных аномалий кроется в том, что существуют неявно
выраженные зависимости между различными данными. Следовательно, для построения корректной структуры базы данных необходимо устранять излишние зависимости и оставлять только необходимые.
В нашем случае причина проблем в том, что мы потребовали существования ключа ФИО+Дисциплина+Оценка+Дата_оценки+Преподаватель. На первый взгляд, это требование можно отбросить, и тогда часть аномалий пропадет. Однако, это будет означать, что мы одну функциональную зависимость заменили другой, т.к хранение никак не структурированных и неформализованных данных невозможно. Во второй лекции мы говорили, что данные - это представление фактов и идей в формализованном виде,
пригодном для передачи и обработки в некотором информационном процессе.
34
Следовательно, наличие различных ограничений, содержащихся в данных, является следствием процесса формализации.
Для того, чтобы избежать описанных проблем Эдгар Кодд разработал стройную математическую теорию, которая получила название «реляционное исчисление».
Изложение этой теории начнем с того, что рассмотрим процесс, с помощью которого исходная структура данных приводится к набору взаимосвязанных таблиц,
гарантирующих отсутствие проблем вышеописанного типа. Выше упоминалось, что для построения корректной структуры базы данных необходимо выявлять и устранять различного рода ограничения, содержащиеся в данных. В основе этого процесса лежит понятие функциональной зависимости.
Функциональная зависимость
Если даны два атрибута X и Y некоторого отношения, то говорят, что Y
функционально зависит от X, если в любой момент времени каждому значению X соответствует ровно одно значение Y.
Функциональная зависимость обозначается
X -> Y.
Отметим, что X и Y могут представлять собой не только единичные атрибуты, но и группы, составленные из нескольких атрибутов одного отношения. Функциональные зависимости могут обладать свойством избыточности.
Избыточная функциональная зависимость
- зависимость, заключающая в себе такую информацию, которая может быть получена на основе других зависимостей, имеющихся в базе данных.
Пример 3:
Пусть A1 – номер зачетки студента, A2 – фамилия, A3 – дата рождения, A4 – место рождения, A5 – сокращенное название (номер) факультета, A6 – название факультета, A7
– код специальности, A8 – название специальности. Тогда имеют место функциональные зависимости.
(A2, A3, A4) ->A1 A6 -> A5
A7 -> A8
A1 -> A5
A1 -> A7
A5 -> A7
Если каждую функциональную зависимость назвать своим именем, то функциональные зависимости можно переписать в предикатной форме.
35
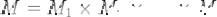
Предикат
(n-местный, или n-арный) – это функция с множеством значений {0,1} (или
«ложь» |
и |
«истина»), |
определённая |
на |
множестве |

















 .
.
Таким образом, каждый набор элементов множества M характеризуется либо как
«истинный», либо как «ложный».
Пример 4:
возьмем функциональную зависимость (A2, A3, A4) ->A1 обозначим ее как СТУДЕНТ, тогда предикатная форма записи этого отношения будет СТУДЕНТ
(А1, A2, A3, A4) или развернуто
СТУДЕНТ (номер_зачетки, фамилия, дата_рождения, место_рождения)
Значение предикатной функции СТУДЕНТ (1234, Иванов, 01.011995,
Екатеринбург) будет «истина», если студент имеется студент Иванов, родившийся
01.01.1995 в Екатеринбурге, и номер его зачетки равен 1234. Функциональную зависимость в предикатной форме можно представить в виде таблицы, строки которой образуют все значения атрибутов, делающие предикат истинным.
Пример 5:
интерпретация отношения Деталь может быть следующей. Деталь с определенным номером (Номер_детали) имеет определенное имя (Название_детали), имеется на складе в количестве (Кол-во_детали) весом (Вес) килограмм каждая и выполнена из (Материал); кроме того нет двух деталей с одинаковыми номерами.
Коль скоро в модели базы данных имеются избыточные функциональные зависимости, т.е
зависимости, которые можно выразить через другие функциональные зависимости, то нужно эти избыточные зависимости устранить. Процесс устранения избыточных зависимостей между данными называется отпимизацией.
Оптимизация реляционной базы данных заключается в поиске и удалении избыточных функциональных зависимостей
и заключается в выполнении последовательности шагов, называемых нормализацией отношений..
Дадим более строгое определение понятиям «отношение» и «схема базы данных».
Домен
Для одной переменной - множество значений переменной. Для нескольких переменных – декартового произведение (все возможные сочетания) значений каждой переменной.
Пример 6:
36
|
|
|
Таблица 4. Декартово произведение доменов. |
||||
Допустим, |
содержание |
доменов |
|
|
|
|
|
Домен отношения |
|||||||
следующее: |
|
|
Фамилия |
Предмет |
Оценка |
|
|
|
|
Иванов |
Физика |
4 |
|
||
D1 |
= {Иванов, Петров, Сидоров} |
|
|||||
Иванов |
Химия |
3 |
|
||||
D2 |
= {Физика, Химия} |
|
Петров |
Химия |
5 |
|
|
|
Сидоров |
Физика |
5 |
|
|||
D3 |
= {3,4,5} |
|
|
||||
|
Сидоров |
Химия |
4 |
|
|||
|
|
|
|
|
|||
Тогда полное декартово произведение D1*D2*D3 состоит из троек, где первый
элемент тройки - одна из фамилий, второй элемент - учебная дисциплина, а третий
- оценка. Тогда домен домен – полное декартово произведение задается таблицей.
Отношение Функциональная зависимость вместе со своим доменом.
Табличное представление отношения Любое отношение имеет может быть представлено в виде таблицы, столбцы
(поля, атрибуты) которой соответствуют вхождениям доменов в отношение, а
строки (записи) — наборам из n значений, взятых из исходных доменов.
Число строк (кортежей) n, называют кардиальным числом отношения, или мощностью
отношения.
Схема отношения
Схемой отношения R называется перечень имен атрибутов отношения
(соответствующих столбцам таблицы) с указанием доменов этих атрибутов и обозначается R (A1, A2, …, An); {Ai} Di , где {Ai} – множество значений,
принимаемых атрибутом Ai ( i =1, n ).
Схема базы данных Совокупность схем отношений, используемых для представления
концептуальной модели, называется схемой реляционной базы данных, а
текущие значения соответствующих отношений – реляционной базой данных.
Ключ в отношении Потенциальный ключ - это такой набор атрибутов, который однозначно
определяет кортеж – строку таблицы и ни один из атрибутов (столбцов) нельзя убрать. Из множества потенциальных ключей выбирается первичный ключ.
При добавлении новых записей первичный ключ обязан оставаться первичным ключом
(например, неверным будет использование в качестве первичного ключа набора Имя +
Отчество + Фамилия сотрудника, даже если на момент создания таблицы полных тёзок среди заносимых в неё людей не было).
37
Пример 7:
Обозначим схему отношения:
СТУДЕНТ как R1,
ФАКУЛЬТЕТ как R2,
СПЕЦИАЛЬНОСТЬ как R3,
СТУДЕНТ УЧИТСЯ НА ФАКУЛЬТЕТЕ как R4,
СТУДЕНТ УЧИТСЯ ПО СПЕЦИАЛЬНОСТИ как R5,
НА ФАКУЛЬТЕТЕ ИМЕЮТСЯ СПЕЦИАЛЬНОСТИ как R6.
Тогда реляционная модель соответствующего примера описывается следующей совокупностью схем отношений:
R1(A1, A2, A3, A4)
R2(A5, A6)
R3(A7, A8)
R4(A1, A5)
R5(A1, A7)
R6(A5, A7)
Нормальная форма
- требование, предъявляемое к структуре таблиц в теории реляционных баз данных для устранения из базы избыточных функциональных зависимостей между атрибутами (полями таблиц).
Нормализация
- процесс преобразования базы данных к виду, отвечающему нормальным формам.
Если таблица не соответствует нормальной форме, она может быть приведена к ней
(нормализована) за счёт декомпозиции, то есть разбиения на несколько таблиц, связанных между собой с помощью операций реляционной алгебры. Корректной считается такая схема базы данных, в которой отсутствуют избыточные функциональные зависимости.
Вернемся к примеру с аномалиями вставки и удаления. Функциональные зависимости характеризуют все отношения, которые могут быть значениями схемы отношения R в
принципе. Поэтому единственный способ определить функциональные зависимости – внимательно проанализировать семантику (смысл) атрибутов.
Пример 8:
функциональных зависимостей для отношения ЭКЗАМЕНАЦИОННАЯ ВЕДОМОСТЬ
Код студента -> Фамилия
38
Код студента, Код экзамена -> Оценка Пример функциональных зависимостей для отношения СТУДЕНТ,
приведенного в начале настоящей лекции Код студента -> Фамилия,
Код студента -> Факультет Заметим, что последняя зависимость существует при условии, что один студент не может обучаться на нескольких факультетах.
Первая нормальная форма Отношение находится в первой нормальной форме (1НФ) тогда и только
тогда, когда все используемые домены содержат только скалярные значения
(атомарны).
Таблица5. Приведение к первой нормальной форме.
|
Исходная, ненормализованная, |
|
|
|
Нормализованная таблица |
|
|||
|
|
таблица |
|
|
|
|
|
|
|
|
Сотрудник |
|
Номер телефона |
|
|
|
Сотрудник |
Номер телефона |
|
|
Иванов И.И. |
|
283-56-82 |
|
|
|
Иванов И.И. |
283-56-82 |
|
|
|
390-57-34 |
|
|
|
Иванов И.И. |
390-57-34 |
|
|
|
|
|
|
|
|
|
|||
|
Петров П.Ю. |
|
708-62-34 |
|
|
|
|
|
|
|
|
|
|
|
Петров П.Ю. |
708-62-34 |
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Вторая нормальная форма Отношение (таблица) находится во второй нормальной форме (2НФ) тогда и
только тогда, когда оно находится в 1НФ и каждый неключевой атрибут зависит от всего первичного ключа, а не от его части (неприводимо зависит от первичного ключа).
Рисунок 13. Приведение базы данных ко второй нормальной форме
39
Разберем каждую таблицу на рисунке 13. Для таблицы «Детали» все ее атрибуты:
количество, вес, материал определяются ключевым атрибутом «Имя_детали», для таблицы «Поставщик» все ее атрибуты: город, дом, улица определяются ключом
«Поставщик», для таблицы «Поставки» все ее атрибуты: количество определяются ключом «Имя_детали»+ «Поставщик». Таким образом, для таблицы поставок первичный ключ имеет сложную структуру: он состоит из двух атрибутов, при этом неключевые атрибуты таблицы: количество зависят от всего первичного ключа, а не от его части.
Третья нормальная форма Отношение находится в третьей нормальной форме (3НФ) тогда и только
тогда, когда оно находится во второй нормальной форме и каждый неключевой атрибут зависит только от первичного ключа (нетранзитивно зависит от первичного ключа).
Пример 9:
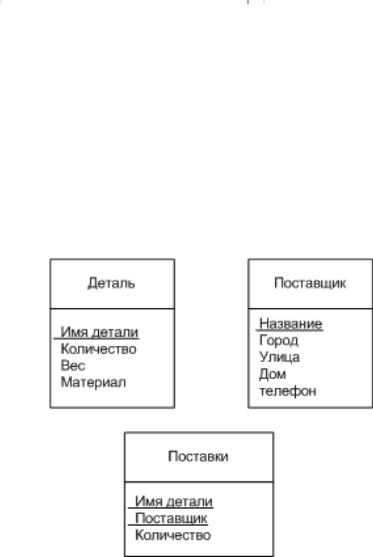
Имеются функциональные зависимости Код студента -> Факультет Факультет -> Дисциплина
Тогда существует функциональная зависимость Код студента –> Дисциплина
Функциональная зависимость может превратиться в транзитивную, как показано на рисунке 14. В базе данных транзитивная зависимость возникает в том случае, если в отношении (таблице) Дисциплина имеется атрибут Номер_Зачетки. Если такого атрибута в таблице нет, то транзитивная зависимость устранена.
Рисунок 14. Возникновение транзитивных зависимостей.
Схема базы данных приведена к третьей нормальной форме тогда, когда она свободна от транзитивных зависимостей. Чем плохи транзитивные зависимости? Тем, затрудняют обеспечение целостности базы данных. Обеспечению целостности базы данных посвящена отдельная тема. Сейчас можно привести пример, показанный на рис. 17, где создается связь между двумя таблицами, корректность которой будет автоматически поддерживаться - сама СУБД будет за этим следить. При наличии транзитивной
40