

Bazy_dannykh_Uchebnik_novy
.pdfлокальных блокировок на измененные таблицы в целях предотвращения считывания незафиксированных данных. На второй фазе двухфазной фиксации выполняется либо фиксация транзакции, либо ее откат. Автоматический откат предпринимается, если фиксация транзакции невозможна в любом из узлов. Сайт пункта фиксации инициализирует фазу фиксации по инструкции глобального координатора. В качестве сайта пункта фиксации назначается наиболее надежный сайт, имеющий наибольшее значение параметра инициализации COMMIT_POINT_STRENGTH (обычно это значение устанавливает администратор базы данных). После фиксации транзакции каждый узел снимает свои блокировки, вносит запись о фиксации в свой локальный журнал повтора и уведомляет об этом глобального координатора.
В настоящее время такой механизм поддерживают СУБД CA-OpenIngres, Informix, Microsoft SQL Server, Oracle, Sybase.
Прозрачность расположения
Это качество распределенной базы в реальных продуктах должно поддерживаться соответствующими механизмами. Разработчики СУБД придерживаются различных подходов. Рассмотрим пример из Oracle.
Пример 86:
Допустим, что у нас Вы являетесь системным администратором международной компании. Каждое утро Вам необходимо готовить сводку данных по всем покупателям и всем заказам, которые они сделали. Часть базы данных Вашей компании размещена в на узле в Лондоне.
Создадим вначале ссылку (database link), связав ее с символическим именем
(london_unix), транслируемым в IP-адрес узла в Лондоне.
CREATE PUBLIC DATABASE LINK london.com
CONNECT TO london_unix USING oracle_user_ID;
Теперь мы можем явно обращаться к базе данных на этом узле, запрашивая,
например, в операторе SELECT таблицу, хранящуюся в этой базе:
SELECT ПОКУПАТЕЛИ.ФИО, ЗАКАЗЫ.Дата
FROM ПОКУПАТЕЛИ@london.com, ЗАКАЗЫ
WHERE ПОКУПАТЕЛИ.Код = ЗАКАЗЫ.Покупатель;
121
Очевидно, однако, что мы написали запрос, зависящий от расположения базы данных, поскольку явно использовали в нем ссылку. Задача решается с помощью оператора SQL CREATE SYNONYM, который позволяет создавать новые имена для существующих таблиц. При этом оказывается возможным обращаться к другим базам данных и к другим компьютерам. Определим ПОКУПАТЕЛИ и ПОКУПАТЕЛИ@london.com как синонимы:
CREATE SYNONYM ПОКУПАТЕЛИ FOR ПОКУПАТЕЛИ@london.com;
и в результате можем написать полностью независимый от расположения базы данных запрос:
SELECT ПОКУПАТЕЛИ.ФИО, ЗАКАЗЫ.ДАТА
FROM ПОКУПАТЕЛИ, ЗАКАЗЫ
WHERE ПОКУПАТЕЛИ.Код = ЗАКАЗЫ.Покупатель
Обработка распределенных запросов
Обработка распределенных запросов (Distributed Query -DQ) - задача, более сложная,
нежели обработка локальных и она требует интеллектуального решения с помощью особого компонента - оптимизатора распределенных запросов.
Пример 87:
Пусть имеется база данных, распределенная по двум узлам сети. Таблица ДЕТАЛИ хранится на одном узле, таблица ПОСТАЩИКИ - на другом. Размер первой таблицы - 10000 строк, размер второй - 100 строк (множество деталей поставляется небольшим числом поставщиков). Допустим, что выполняется запрос:
SELECT ДЕТАЛИ.Название, ПОСТАВЩИКИ.Название,
ПОСТАВЩИКИ.Адрес
FROM ДЕТАЛИ, ПОСТАВЩИКИ
WHERE ДЕТАЛИ.Код = ПОСТАЩИКИ.Деталь;
Результирующая таблица представляет собой объединение таблиц ДЕТАЛИ и ПОСТАЩИКИ, выполненное по столбцу ПОСТАЩИКИ.Деталь (внешний ключ) и
ДЕТАЛИ.Код (первичный ключ). Данный запрос - распределенный, так как затрагивает таблицы, принадлежащие различным локальным базам данных. Для его нормального выполнения необходимо иметь обе исходные таблицы на одном узле. Следовательно, одна из таблиц должна быть передана по сети. Очевидно, что
122
это должна быть таблица меньшего размера, то есть таблица ПОСТАЩИКИ.
Следовательно, оптимизатор распределенных запросов должен учитывать такие параметры, как, в первую очередь, размер таблиц, статистику распределения данных по узлам, объем данных, передаваемых между узлами, скорость коммуникационных линий, структуры хранения данных, соотношение производительности процессоров на разных узлах и т.д. От интеллекта оптимизатора распределенных запросов впрямую зависит скорость выполнения распределенных запросов.
Межоперабельность
В контексте распределенных баз данных межоперабельность означает две вещи. Во-
первых, - это качество, позволяющее обмениваться данными между базами данных различных поставщиков. Есть два пути решения задачи: разработка программных продуктов для обмена данными, либо использование универсального формата обмена данными, например XML.
Во-вторых, межоперабельность - это возможность унифицированного доступа к данным в распределенной базе из прикладных программных продуктов, работающих с этой базой. В
свое время в качестве универсального решения Microsoft предложила технологию ODBC – Open Database Connectivity Overview Открытый - Протокол доступа к данным. Суть заключается в том, что к каждому файлу независимо от его формата: Excell, Access, Foxpro и пр. можно создать «подключение», по которому можно отправлять строку текста, содержащую SQL-запрос и получать в ответ данные. Сейчас эти технологии получили продолжение и развитие. Для любой СУБД можно определить внешний интерфейс – набор функций и процедур, обеспечивающих доступ к базе данных, которую поддерживает конкретная СУБД.
Технология тиражирования данных
Тиражирование данных - это асинхронный перенос изменений объектов исходной базы данных в базы, принадлежащим различным узлам распределенной системы. Функции тиражирования данных выполняет, как правило, специальный модуль СУБД - сервер тиражирования данных, называемый репликатором (так устроены СУБД CA-OpenIngres и Sybase). В MS Access есть пункт «репликация», который позволяет создавать копию – реплицировать базу данных на определенную дату.
123
12. Программно-аппаратная организация (архитектура)
баз данных
Ранее для базы данных мы использовали термин «архитектура», понимая под этим концептуальную модель базы данных: сетевую, иерархическую, реляционную. В
настоящей лекции рассмотрим программно-аппаратную организацию работы пользователей с базами данных. Существует несколько способов организации взаимодействия пользователей с базами данных.
Архитектура файл-сервер
Показана на рисунке 39.
Принципы работы:
Существует локальная сеть, состоящая из клиентских компьютеров, на каждом из которых установлены локальные СУБД и приложения для работы с БД.
База данных в виде набора файлов находится на жестком диске специально выделенного компьютера (файлового сервера), см. рис 25.
На каждом из клиентских компьютеров пользователи имеют возможность запустить приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к БД на выборку/обновление информации.
Вся информация о структуре базы данных хранится на каждом клиентском компьютере и обращения к центральной базе идут через локальные СУБД.
Локальная СУБД инициирует обращения к данным, находящимся на файловом сервере, в результате которых часть файлов центральной БД копируется на клиентский компьютер и обрабатывается, что обеспечивает выполнение запросов пользователя (осуществляются необходимые операции над данными).
При необходимости (в случае изменения данных) данные отправляются назад на файловый сервер с целью обновления БД.
Результат СУБД возвращает в приложение.
Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов.
При обновлении данных используется механизм блокировок, когда обновления в базу вносятся поочередно и таблица (или ее часть) блокируется для остальных пользователей до тех пор, пока пользователь не закончит редактирование записи.
124
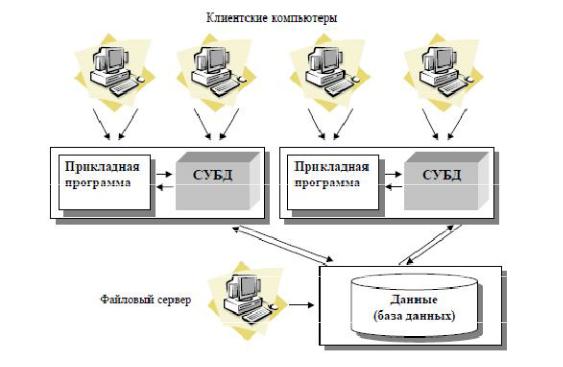
Рисунок 39. Архитектура файл-сервер
Недостатки
При одновременном обращении множества пользователей к одним и тем же данным из-за наличия блокировок производительность работы резко падает, т.к.
необходимо дождаться пока пользователь, работающий с данными, завершит свою работу.
Вся тяжесть вычислительной нагрузки при доступе к БД ложится на приложение клиента, так как при выдаче запроса на выборку информации из таблицы вся таблица БД копируется на клиентскую машину и выборка осуществляется на клиенте. Таким образом, неоптимально расходуются ресурсы клиентского компьютера и сети. В результате возрастает сетевой трафик и увеличиваются требования к аппаратным мощностям пользовательского компьютера.
Как правило, используется навигационный подход, ориентированный на работу с отдельными записями.
В БД на файл-сервере гораздо проще вносить изменения в отдельные таблицы,
минуя приложения, непосредственно из инструментальных средств; все это позволяет говорить о низком уровне безопасности – как с точки зрения хищения и нанесения вреда, так и с точки зрения внесения ошибочных изменений.
Недостаточно развитый аппарат транзакций служит потенциальным источником ошибок в плане нарушения смысловой и ссылочной целостности информации при одновременном внесении изменений в одну и ту же запись.
125
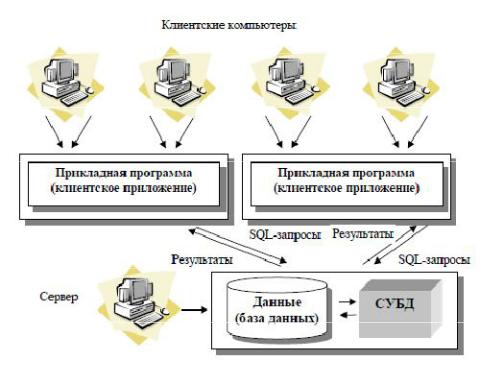
Архитектура "клиент-сервер". Показана на рисунке 40.
Принципы работы:
Существует локальная сеть, состоящая из клиентских компьютеров, на каждом из которых установлено клиентское приложение для работы с БД.
База данных в виде набора файлов находится на жестком диске специально выделенного компьютера (сервера сети), там же располагается и СУБД.
На каждом из клиентских компьютеров пользователи имеют возможность запустить приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к СУБД, расположенной на сервере, на выборку/обновление информации. Для общения используется специальный язык запросов SQL, т.е. по сети от клиента к серверу передается лишь текст запроса.
СУБД инкапсулирует внутри себя все сведения о физической структуре БД,
расположенной на сервере.
СУБД инициирует обращения к данным, находящимся на сервере, в результате которых на сервере осуществляется вся обработка данных и лишь результат выполнения запроса копируется на клиентский компьютер. Таким образом СУБД возвращает результат в приложение.
Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов.
Рисунок 40. Архитектура «клиент-сервер».
126
Разграничение функций между сервером и клиентом
Функции приложения-клиента:
Посылка запросов серверу.
Интерпретация результатов запросов, полученных от сервера.
Представление результатов пользователю в некоторой форме (интерфейс пользователя).
Функции серверной части:
Прием запросов от приложений-клиентов.
Интерпретация запросов.
Оптимизация и выполнение запросов к БД.
Отправка результатов приложению-клиенту.
Обеспечение системы безопасности и разграничение доступа.
Управление целостностью БД.
Реализация стабильности многопользовательского режима работы.
Достоинства по сравнению с «файл-серверной» архитектурой
Существенно уменьшается сетевой трафик.
Уменьшается сложность клиентских приложений (большая часть нагрузки ложится на серверную часть), а следовательно, снижаются требования к аппаратным мощностям клиентских компьютеров.
Наличие специального программного средства – SQL-сервера – приводит к тому,
что существенная часть проектных и программистских задач становится уже решенной.
Существенно повышается целостность и безопасность БД.
Недостатки
более высокие финансовые затраты на аппаратное и программное обеспечение,
большое количество клиентских компьютеров, расположенных в разных местах,
вызывает определенные трудности со своевременным обновлением клиентских приложений на всех компьютерах-клиентах.
Трехуровневая архитектура «клиент-сервер»
Трехзвенная (в некоторых случаях многозвенная) архитектура (N-tier или multi-tier).
представляет собой дальнейшее совершенствование технологии «клиент – сервер».
Рассмотрев архитектуру «клиент – сервер», можно заключить, что она является 2-звенной:
127
первое звено – клиентское приложение, второе звено – сервер БД + сама БД. В
трехзвенной архитектуре вся бизнес-логика (деловая логика), ранее входившая в клиентские приложения, выделяется в отдельное звено, называемое сервером приложений. При этом клиентским приложениям остается лишь пользовательский интерфейс. Так, в качестве клиентского приложения в описанном выше примере выступает Web-браузер. Что улучшается при использовании трехзвенной архитектуры?
Теперь при изменении бизнес-логики более нет необходимости изменять клиентские приложения и обновлять их у всех пользователей. Кроме того, максимально снижаются требования к аппаратуре пользователей.
Принципы работы:
База данных в виде набора файлов находится на жестком диске специально выделенного компьютера (сервера сети).
СУБД располагается также на сервере сети.
Существует специально выделенный сервер приложений, на котором располагается программное обеспечение (ПО) делового анализа (бизнес-логика).
Существует множество клиентских компьютеров, на каждом из которых установлен так называемый «тонкий клиент» – клиентское приложение,
реализующее интерфейс пользователя.
На каждом из клиентских компьютеров пользователи имеют возможность запустить приложение – тонкий клиент. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к ПО делового анализа,
расположенному на сервере приложений.
Сервер приложений анализирует требования пользователя и формирует запросы к БД. Для общения используется специальный язык запросов SQL, т.е. по сети от сервера приложений к серверу БД передается лишь текст запроса.
СУБД инкапсулирует внутри себя все сведения о физической структуре БД,
расположенной на сервере.
СУБД инициирует обращения к данным, находящимся на сервере, в результате которых результат выполнения запроса копируется на сервер приложений.
Сервер приложений возвращает результат в клиентское приложение
(пользователю).
Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов.
Хранилища данных
128
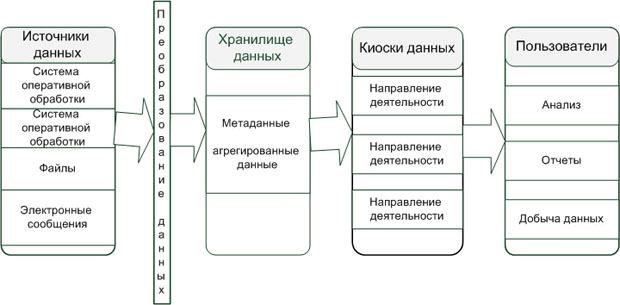
Исторически концепция хранилищ данных возникла после того, как на предприятиях накопилось большое количество база данных в различных подразделениях: бухгалтерии,
финансовом отделе, отделе кадров и появилась необходимость связать эти сведения в единое целое для построения общей картины. По сути, это просто объединение разнородных СУБД в единую информационную систему уровня предприятия. Смотрите рисунок 41. Согласно классическому определению Б. Инмона,
хранилище данных есть предметно ориентированный, интегрированный,
неизменный, поддерживающий хронологию набор данных, предназначенный для поддержки принятия решений.
От полноценной базы данных хранилище отличается тем, что предназначено для накопления информации и ее анализа. В определении Хранилищ Данных соединены две различные функции:
сбор, организация и подготовка данных для анализа в виде постоянно наращиваемой базы данных;
собственно анализ как элемент принятия решений.
Рисунок 41. Схема объединения разнородных баз
Как правило, в состав Хранилищ Данных входят следующие компоненты:
средства извлечения данных из различных баз данных и OLTP-систем,
унаследованных систем и других внешних источников данных;
средства трансформации и очистки данных. Точность существующих данных доставляет немало хлопот организации. Поэтому перед тем как поместить данные в хранилище их необходимо привести в порядок, иначе говоря — очистить;
129
программное обеспечение баз данных. Как правило, это высокопроизводительная реляционная СУБД, используемая для структуризации и хранения информации;
средства для соединения источников данных с хранилищем и клиентов с сервером.
Трудности внедрения хранилищ данных
Причины, которые затрудняют внедрение технологии хранилища данных на предприятии:
Разнобой в используемых технологических средствах.
Организационно-технологические факторы.
Отсутствие лингвистического обеспечения.
Для успешного использования DW огромное значение имеют метаданные, на основе которых пользователь получает доступ к данным.
Точное понимание со стороны руководства; чаще всего DW создается для задач принятия и поддержки решений.
Объединение плохо совместимого.
Корректность его данных, полученных из разных источников.
Облачные технологии
Облачные вычисления (англ. cloud computing) - технология распределенной обработки данных, в которой компьютерные ресурсы и мощности предоставляются пользователю как интернет-сервис. Облачный сервис представляет собой особую клиент-серверную технологию, когда использование клиентом ресурсов (процессорное время, оперативная память,
дисковое пространство, сетевые каналы, специализированные контроллеры,
программное обеспечение и т. д.) группы серверов в сети, взаимодействующих таким образом, что:
для клиента вся группа выглядит как единый виртуальный сервер;
клиент может прозрачно и с высокой гибкостью менять объемы
потребляемых ресурсов в случае изменения своих потребностей
(увеличивать / уменьшать мощность сервера с соответствующим
изменением оплаты за него).
Идея облачных технологий проиллюстрирована на рисунке 25. Наличие нескольких источников используемых ресурсов, с одной стороны, позволяет повышать доступность системы клиент-сервер за счет возможности масштабирования при повышении нагрузки
(увеличение количества используемых источников данного ресурса пропорционально увеличению потребности в нем и / или перенос работающего виртуального сервера на более мощный источник, «живая миграция»), а с другой - снижает риск неработоспособности виртуального сервера в случае выхода из строя какого-либо из
130