

Bazy_dannykh_Uchebnik_novy
.pdfдинамические операции, которые основаны на очертаниях и понятии видимости. Это операции, которые используются для 3D моделирования объектов.
Пример 73:
Создание пространственных таблиц.
Таблица «Страны»
CREATE TABLE СТРАНЫ( Название varchar(30), Континент varchar(30), Столица varchrar(30),
Население Integer,
ВВП Number,
Очертания Polygon
);
Таблица «Реки»
CREATE TABLE РЕКИ( Название varchar(30), Страна varchar(30), Длина Number, Очертания LineString
);
Таблица «Города»
CREATE TABLE ГОРОДА ( Название varchar(30), Страна varchar(30),
Население integer, Очертания Point
);
Запросы к пространственным данным.
Для выполнения пространственных запросов и работы с пространственными данными в стандарт языка SQL был расширен и дополнен. Покажем расширения на примерах. В
стандарте OGIS введены 9 пространственных операторов для расширения возможностей системы запросов.
1.Функция Touch – Касание имеет логический тип, и проверяет, являются ли два любых геометрических объекта смежными без наложения. Эта операция полезна для отыскания соседних объектов,
2.Функция Cross – Пересечение. Имеет логический тип, и чаще всего он используется для проверки наличия пересечения между объектами типа ЛоманаяЛиния и Многоугольник, или между парой объектов типа ЛоманаяЛиния.
111
3.Функция Distance – Расстояние. Функция имеет два аргумента. Имеет вещественный тип. Используется в предложении WHERE и в предложении
SELECT подзапроса. Определена для геометрических объектов любого типа.
Очевидно, что вычисление результата зависит от базовой системы координат,
заданных для базы данных. Например, если очертания в кортежах таблицы СТРАНЫ заданы широтой и долготой, то расчету значения Distance должно
предшествовать промежуточное преобразование координат. Все сказанное справедливо и для функций Area – Плошадь, и Length – Расстояние.
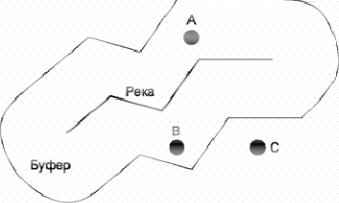
5. Оператор Buffer |
– |
||
Буферизация. |
|
||
Имеет |
|
|
|
геометрический |
|
||
тип, |
т.е. |
|
в |
результате |
|
|
|
применения |
этого |
||
оператора |
|
4. |
|
получается |
|
||
|
Рисунок 37. Геометрический объект Река и построенный |
||
геометрический |
вокруг него буфер. |
||
объект |
- |
буфер. |
|
Буфером геометрического объекта называется центрированная относительно объекта геометрическая область, размер которой определяется параметром операции Buffer. Пример – на рисунке 37.
6.Функция Area - Площадь. Имеет вещественный тип. Данная функция применяется только для геометрических типов Многоугольник и НаборМногоугольников. Очевидно, что вычисление результата зависит от базовой системы координат, заданных для базы данных. Например, если очертания в кортежах таблицы СТРАНЫ заданы широтой и долготой, то расчету значения Area
должно предшествовать промежуточное преобразование координат.
7.Оператор Intersection – Пересечение. Имеет геометрический тип, т.е возвращает геометрический объект. Результат операции Intersection над объектами типа ЛоманаяЛиния и Многоугольник может иметь тип Точка или ЛоманаяЛиния.
Например, если река (ЛоманаяЛиния) пересекает территорию страны
(Многоугольник), то результат будет иметь тип ЛоманаяЛиния.
112
8.Функция Overlap – Перекрытие. Имеет логический тип. Используется для объектов типа Многоугольник. Определяет наличие перекрытия многоуголоьников
между собой.
Помимо представленных расширений языка запросов SQL конкретная СУБД мржет содержать и иные возможности.
Пример 74:
Отыскать в таблице СТРАНЫ названия всех стран, которые являются соседями Соединенных Штатов. Запрос выполняется с помощью операnора Touch.
SELECT |
C1.Название AS "Соседи США" |
FROM |
СТРАНЫ C1, СТРАНЫ C2 |
WHERE |
(Touch(C1.Очертания, C2.очертания) = 1) |
|
AND (C2.Название = ‘США’); |
Пример 75:
Для всех рек, перечисленных в таблице РЕКИ, определить страны, по которым они протекают. Запрос выполняется с помощью оператора Cross.
SELECT |
РЕКИ.Название CТРАНЫ.Название |
FROM РЕКИ, CТРАНЫ |
|
WHERE |
Cross(РЕКИ.Очертания, CТРАНЫ.Очертания) = 1; |
Пример 76:
Какой из городов, содержащихся в таблице ГОРОДА, ближе других расположен ко всем рекам, перечисленным в таблице РЕКИ. Запрос выполняется с помощью функции Distance.
SELECT C1.Название, R1.Название
FROM ГОРОДА C1, РЕКИ R1
WHERE Distance (C1.Очертания, R1.Очертания) < ALL (
SELECT Distance(C2.Очертания, R1.Очертания) FROM ГОРОДА C2
WHERE C1.Название <> C2.Название
);
В условие WHERE основного запроса входит функция Distance, определяющая расстояния между странами, которые обозначены псевдонимом C1 и реками,
которые обозначены псевдонимом R1. Конкретное значение расстояния определяется с помощью вложенного запроса, который выбирает расстояния между всеми странами, обозначенными псевдонимом C2, названия которых не совпадают названием страны С1.Название, фигурирующей в основном запросе.
113
Пример 77:
Река Св. Лаврентия может снабжать водой города, удаленные от нее не далее чем на 300 км. Составить список городов, которые могут получать воду из реки Св.
Лаврентия. Задача решается с использованием операции буферизации.
Построенный буфер проверяется с на наличе перекрывания территории сближайши городом с помощью функции Overlap.
SELECT ГОРОДА.Название
FROM ГОРОДА, РЕКИ
WHERE (Overlap(Города.Очертание, Buffer(Реки.Очертание,300)) = 1) AND (R.Name = ‘Св. Лаврентия’);
Пример 78:
Составить список названий, численности населения и площади стран,
содержащихся в таблице СТРАНЫ..
SELECT C.Название, C.Население, Area(C.Очертания) AS "Площадь"
FROM СТРАНЫ C;
Этот запрос иллюстрирует во-первых, что настоящие программисты – ленивые люди. Вместо того, чтобы писать в запросе СТРАНЫ.Название, разработчик запроса использует псевдоним С, чтобы уменьшить размер написанного кода. Во-
вторых псевдоним используется, чтобы форматировать вывод, для того, чтобы задать нужное название для последнего столбца. В-третьих, в запросе используется функции Area - Площадь.
Пример 79:
Составить список длин рек в пределах каждой страны, по которой они протекают.
Для выполнения поставленной задачи используется функция Cross, фиксирующая факт пересечения геометрических объектов. Псевдонимы (алиасы) используются также, как описано выше.
SELECT R.Название, C.Название,
Length(Intersection(R.Очертание, C.Очертание)) AS "Длина"
FROM РЕКИ R, СТРАНЫ C
WHERE Cross(R.Очертание, C.Очертание) = 1;
Пример 80:
114
Для всех стран составить список ВВП для всех стран и их расстояний столичных городов этих стран от экватора. Чтобы выполнить запрос, необходимо описать такой объект, как экватор. Для этого используем геометрический объект
Point(0,Cтрана.Очертание.y) – это точка на экваторе, имеющая ту же долготу, что и текущая столица, представленная атрибутом Cтрана.Название. Обратите внимание, что запись Страна.Очертание.y означает неизвестную точку y. Страна
– экземпляр сущности СТРАНЫ, Очертание – ее атрибут, y – атрибут атрибута Очертание. В итоге получаем следующий запрос.
SELECT CТРАНЫ.ВВП, Distance(Point(0,ГОРОДА.Очертание.y),ГОРОДА.Очертание) AS "Расстояние" FROM СТРАНЫ, ГОРОДА
WHERE СТРАНЫ.Столица = ГОРОДА.Название;
Пример 81:
Составить список всех стран, упорядоченный по количеству государств-соседей.
Для решения задачи необходимо определить количество соседей у каждого государства. Для этого используем функцию Touch в сочетании с оператором группировки и агрегатной функцией. В итоге запрос будет иметь следующий вид.
SELECT Co.Название, Count(Co1.Название)
FROM СТРАНЫ Co, СТРАНЫ Co1
WHERE Touch(Co.Очертание, Co1.Очертание)
GROUP BY Co.Название
ORDER BY Count(Co1.Название)
Пример 82:
Перечислить страны, имеющие только одного соседа. Страна является соседней по отношению к другой стране, если их территории имеют общую сухопутную границу. В соответствии с этим определением островные государства, скажем Исландия, соседей не имеют. Для решения задачи создаем следующий запрос.
SELECT Co.Name
FROM СТРАНЫ Co, СТРАНЫ Co1
WHERE Touch(Co.Очертание, Co1.Очертание))
GROUP BY Co.Название
HAVING Count(Co1.Название) = 1
SELECT |
Co.Название |
|
FROM |
СТРАНЫ Co |
|
WHERE |
Co.Название IN |
|
( |
|
|
SELECT |
Co.Название |
|
FROM СТРАНЫ Co, СТРАНЫ Co1 |
||
WHERE |
Touch(Co.Очертание, Co1.Очертание) |
|
115
GROUP BY Co.Название HAVING Count(*) = 1 );
Запрос работает следующим образом. Самый внутренний запрос в предложении
FROM создает таблицу, состоящую из пар стран, которые являются соседями.
Предложение GROUP BY делит новую таблицу на части в соответствии с названиями государств. Наконец, HAVING инициирует принудительное объединение результатов выборки в пары с теми странами, которые имеют только одного соседа. Ключевое слово HAVING играет ту же роль, что и WHERE, за исключением одного: HAVING должно включать такие функции агрегирования,
как count.
Пример 83:
Какая страна имеет наибольшее число соседей? Задачу решает следующий запрос.
CREATE VIEW СОСЕДИ AS
(
SELECT Co.Название, Count(Co1.Название) AS Число_Соседей
FROM СТРАНЫ Co, СТРАНЫ Co1 WHERE Touch(Co.Очертание, Co1.Очертание) GROUP BY Co.Название
)
SELECT Co.Название, Число_Соседей FROM СОСЕДИ
WHERE Число_Соседей =
(
SELECT Max(Число_Соседей) FROM Neighbor
)
;
Этот запрос демонстрирует применение представлений VIEW (виртуальных таблиц) с целью упрощения сложных запросов. Вначале запроса создается виртуальная таблица СОСЕДИ для создания которой необходимо выполнить запрос, написанный в скобках. Виртуальная таблица содержит название страны и количество ее соседей. Далее следует запрос, который производит выборку страны с наибольшим количеством соседей из виртуальной таблицы СОСЕДИ.
116
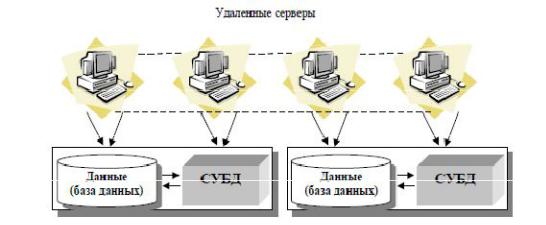
11. Распределенные базы данных и хранилища данных
Под распределенной (Distributed DataBase - DDB) обычно подразумевают базу данных, включающую фрагменты из нескольких баз данных, которые располагаются на различных узлах сети компьютеров, и, возможно управляются различными СУБД.
Распределенная база данных – слабо связанная сетевая структура, узлы которой представляют собой локальные базы данных. Локальные базы данных автономны,
независимы и самоопределены; доступ к ним обеспечиваются СУБД, в общем случае от различных поставщиков. Связи между узлами - это потоки тиражируемых данных.
Распределенная база данных выглядит с точки зрения пользователей и прикладных программ как обычная локальная база данных, как показано на рисунок 38. В этом смысле слово "распределенная" отражает способ организации базы данных, но не внешнюю ее характеристику. ("распределенность" базы данных невидима извне).
Рисунок 38. Распределенная база данных
Определение Дэйта.
Одно из лучших определений распределенных баз данных (DDB) предложил Дэйт
(C.J. Date. Он установил 12 свойств или качеств идеальной DDB:
Локальная автономия (local autonomy)
Независимость узлов (no reliance on central site)
Непрерывные операции (continuous operation)
Прозрачность расположения (location independence)
Прозрачная фрагментация (fragmentation independence)
Прозрачное тиражирование (replication independence)
Обработка распределенных запросов (distributed query processing)
117
Обработка распределенных транзакций (distributed transaction processing)
Независимость от оборудования (hardware independence)
Независимость от операционных систем (operationg system independence)
Прозрачность сети (network independence)
Независимость от баз данных (database independence)
Локальная автономия
Это качество означает, что управление данными на каждом из узлов распределенной системы выполняется локально. Будучи фрагментом общего пространства данных, каждая локальная база, в то же время функционирует как полноценная локальная база данных;
управление ею выполняется локально и независимо от других узлов системы.
Независимость от центрального узла
В идеальной системе все узлы равноправны и независимы, а расположенные на них базы являются равноправными поставщиками данных в общее пространство данных. База данных на каждом из узлов самодостаточна - она включает полный собственный словарь данных и полностью защищена от несанкционированного доступа.
Непрерывные операции
Это качество можно трактовать как возможность непрерывного доступа к данным вне зависимости от их расположения и вне зависимости от операций, выполняемых на локальных узлах. Это качество можно выразить лозунгом "данные доступны всегда, а
операции над ними выполняются непрерывно".
Прозрачность расположения
Это свойство означает полную прозрачность расположения данных. Пользователь,
обращающийся к DDB, ничего не должен знать о реальном, физическом размещении данных в узлах информационной системы. Все операции над данными выполняются без учета их местонахождения. Транспортировка запросов к базам данных осуществляется встроенными системными средствами.
Прозрачная фрагментация
Это свойство трактуется как возможность распределенного (то есть на различных узлах)
размещения данных, логически представляющих собой единое целое. Существует фрагментация двух типов: горизонтальная и вертикальная. Первая означает хранение строк одной таблицы на различных узлах (фактически, хранение строк одной логической таблицы в нескольких идентичных физических таблицах на различных узлах). Вторая означает распределение столбцов логической таблицы по нескольким узлам.
118
Пример 84:
Имеется таблица РАБОТНИК(Код, ФИО, телефон), определенная в базе данных на узле в городе Москва. Имеется точно такая же таблица, определенная в базе данных на узле в Екатеринбурге. Обе таблицы хранят информацию о сотрудниках компании. Кроме того, в базе данных на узле в Казани определена таблица
ЗАР_ПЛАТА(Код, Сумма). Тогда запрос "получить информацию о сотрудниках компании" может быть сформулирован так:
SELECT * FROM РАБОТНИК@МОСКВА, РАБОТНИК@ЕКАТЕРИНБУРГ
ORDER BY Код;
В то же время запрос "получить информацию о заработной плате сотрудников
компании" будет выглядеть следующим образом:
SELECT РАБОТНИК.Код, РАБОТНИК.ФИО, ЗАР_ПЛАТА.Сумма
FROM РАБОТНИК@МОСКВА, РАБОТНИК@ЕКАТЕРИНБУРГ,
ЗАР_ПЛАТА@КАЗАНЬ
ORDER BY Код;
Прозрачность тиражирования
Тиражирование данных - это асинхронный (в общем случае) процесс переноса изменений объектов исходной базы данных в базы, расположенные на других узлах распределенной системы. В данном контексте прозрачность тиражирования означает возможность переноса изменений между базами данных средствами, невидимыми пользователю распределенной системы. Данное свойство означает, что тиражирование возможно и достигается внутрисистемными средствами.
Обработка распределенных запросов.
Это свойство распределенной базы данных трактуется как возможность выполнения операций выборки над распределенной базой данных, сформулированных в рамках обычного запроса на языке SQL. То есть операцию выборки из распределенных баз можно сформулировать с помощью тех же языковых средств, что и операцию над локальной базой данных.
Пример 85:
SELECT ПОКУПАТЕЛЬ.ФИО, ПОКУПАТЕЛЬ.Адрес, ЗАКАЗЫ.Номер,
ЗАКАЗЫ.Дата
FROM ПОКУПАТЕЛЬ@ЛОНДОН, ЗАКАЗЫ@ПАРИЖ
WHERE ПОКУПАТЕЛЬ.Код = ЗАКАЗЫ.Покупатель;
119
Обработка распределенных транзакций
Это качество распределенной базы можно трактовать как возможность выполнения операций обновления распределенной базы данных (INSERT, UPDATE, DELETE), не разрушающее целостность и согласованность данных.
Независимость от оборудования
Это свойство означает, что в качестве узлов распределенной системы могут выступать компьютеры любых моделей и производителей.
Независимость от операционных систем
Это качество вытекает из предыдущего и означает многообразие операционных систем,
управляющих узлами распределенной системы.
Прозрачность сети
Данное качество формулируется максимально широко - в распределенной системе возможны любые локальные сетевые протоколы.
Независимость от баз данных
Это качество означает, что в распределенной системе могут мирно сосуществовать СУБД различных производителей, и возможны операции поиска и обновления в базах данных различных моделей и форматов.
Обеспечение целостности данных
В распределенных базах данных поддержка целостности и согласованности данных, ввиду свойств 1-2, представляет собой сложную проблему. Ее решение - синхронное и согласованное изменение данных в нескольких локальных базах данных, составляющих распределенную базу данных - достигается применением протокола двухфазной фиксации транзакций. Если распределенная база однородна - то есть на всех узлах данные хранятся в формате одной базы и на всех узлах функционирует одна и та же СУБД, то используется механизм двухфазной фиксации транзакций данной СУБД. В случае же неоднородности
DDB для обеспечения согласованных изменений в нескольких базах данных используют менеджеры распределенных транзакций.
Механизм двухфазной транзакции
Первая фаза двухфазной фиксации распределенных транзакций называется фазой предварительной подготовки. На этой фазе инициирующая система или узел (называемый глобальным координатором) уведомляет все сайты, участвующие в транзакции, и
подготавливает их к выполнению фиксации или отката. Узлы, которые для завершения транзакции вынуждены ссылаться на данные в других узлах, иногда называют локальными координаторами. Подготовка включает в себя запись информации в сетевые журналы повтора для последующего выполнения фиксации или отката и размещение
120