

Сортировка агрегатных значений
По полученным в результате выполнения агрегатных функций значениям может выполняться сортировка результирующей таблицы. Для этого столбцу назначается псевдоним при помощи оператора AS, который передается конструкции ORDER BY.
Сортировка результирующей таблицы
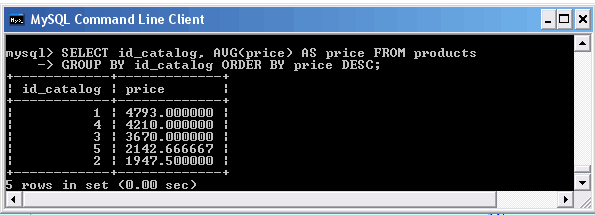
Подсчет количества записей в таблице
Подсчет количества записей в таблице осуществляется при помощи функции COUNT(), имеющей несколько форм со следующим синтаксисом:
COUNT(expr) COUNT(*) COUNT(DISTINCT expr1, expr2, . . .)
Первая форма возвращает количество записей в таблице, поле expr для которых не равно NULL.
Для примера, воспользуемся ранее созданной таблицей tb1 в базе данных wet.
Использование функции COUNT()
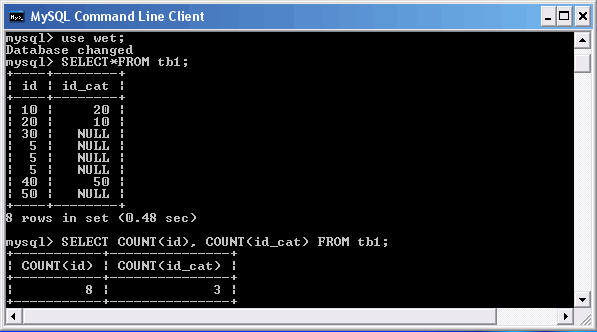
Как видно из примера, для полей id и id_cat возвращаются различные значения. Это связано с тем, что количество NULL-полей в столбцах различаются.
Форма функции COUNT(*) возвращает общее количество строк в таблице, независимо от того, принимает какое-либо поле значение NULL или нет. Запись учитывается в результате, даже если все поля равны NULL.
Использование функции COUNT(*)
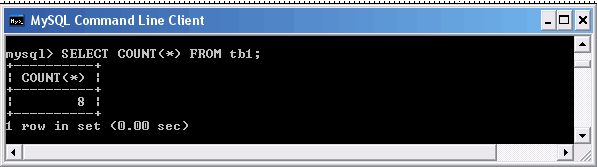
Функция COUNT(*) оптимизирована для быстрого возврата результата при условии, что команда SELECT извлекает данные из одной таблицы, ни какие другие столбцы не обрабатываются и запрос не содержит условие WHERE.
Функция COUNT() может быть использована не только для подсчета общего количества записей в таблице, но и для подсчета количества строк в выборке с условием WHERE.
Использование функции COUNT() совместно с WHERE
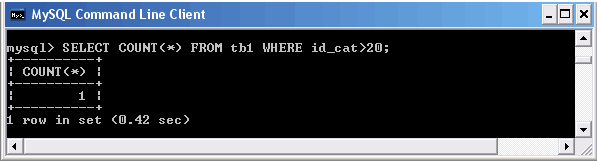
В примере, представлен запрос, извлекающий из таблицы tb1 записи, чье поле id_cat больше 20. Следует обратить внимание, что поля, содержащие NULL, не удовлетворяют этому условию, так как NULL обозначает отсутствие данных.
Разумеется, как агрегатная функция COUNT() может быть использована для вычисления количества записей в каждой из групп, полученных в результате применения группировки результата с помощью конструкции GROUP BY.
Рассмотрим запрос к таблице products, сообщающий о количестве имеющегося товара по каждому разделу каталога.
Подсчет количества товара для каждого раздела каталога
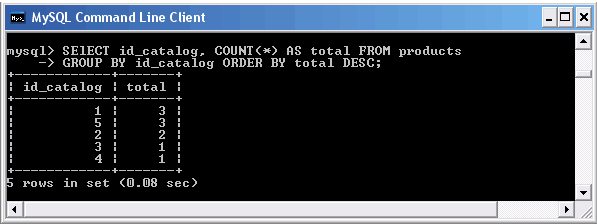
Сортировка строк в результирующей таблице производится по количеству имеющегося товара. Для этого столбцу COUNT(*) при помощи ключевого слова AS назначается псевдоним total, который затем используется в выражении GROUP BY.
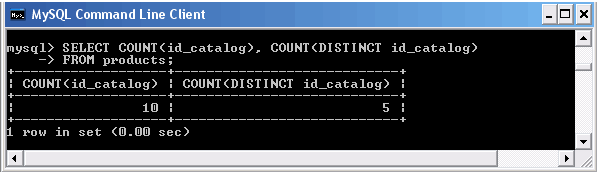
Третий вариант функции COUNT() позволяет использовать ключевое слово DISTINCT, которое обеспечивает подсчет только уникальных значений столбца.
Использование ключевого слова DISTINCT совместно с COUNT()
Объединение значений группы
Для объединения значения группы предназначена функция GROUP_CONCAT(), которая имеет следующий синтаксис:
GROUP_CONCAT([DISTINCT] expr [, expr ...] [ORDER BY {unsigned_integer|col_name|expr} [ASC|DESC] [, col_name ...]] [SEPARATOR str_val])
В простейшем случае функция принимает имя столбца expr и возвращает строку со значениями столбца, разделенными запятыми
.
Рассмотрим пример использования функции GROUP_CONCAT() для поля id_catalog таблицы products.
Использование функции GROUP_CONCAT()
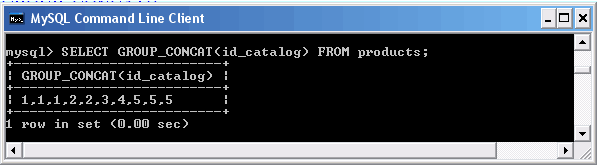
При передаче в качестве аргумента имени числового столбца его значения автоматически преобразуются к текстовому типу.
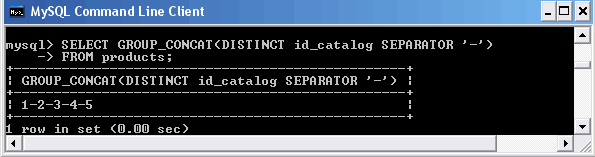
Ключевое слово DISTINCT требует вернуть только уникальные значения столбца, а ключевое слово SEPARATOR позволяет задать в качестве разделителя значений произвольный символ.
Рассмотрим пример, где представлен запрос, извлекающий уникальные значения столбца id_catalog таблицы products с использованием в качестве разделителя символа "-".
Использование ключевых слов DISTINCT и SEPARATOR
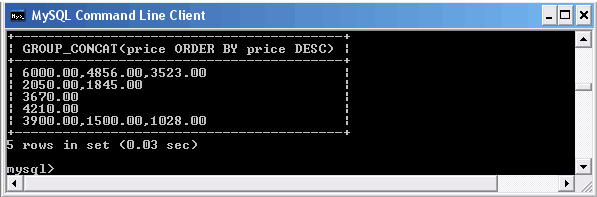
Ключевое слово ORDER BY позволяет отсортировать значения в рамках возвращаемой строки. Отсортируем значения в обратном порядке.
Использование ключевого слова ORDER BY

А теперь возвратим список цен (в порядке убывания) на товары из каждого раздела каталога.
Список цен на товары по разделам каталога
Поиск минимального и максимального значений
Для поиска минимального значения в столбце expr предназначена функция MIN([DISTINCT] expr).
В качестве аргумента обычно выступает имя столбца. Необязательное слово DISTINCT позволяет дать указание СУБД MySQL обрабатывать только уникальные значения столбцаexpr.
Рассмотрим пример запроса, который ищет в таблице products минимальную цену.
Использование функции MIN()
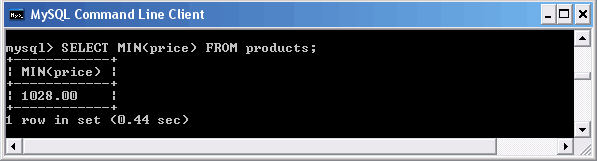
Использование конструкции GROUP BY id_catalog позволяет найти минимальную цену для каждого раздела каталога.
Использование функции MIN () совместно с конструкцией GROUP BY

Как видно из запроса, товар с минимальной ценой назодится в пятом разделе каталога.
Примечание. Функцию MIN() можно использовать также со строковыми столбцами. В этом случае возвращается минимальное лексикографическое значение.
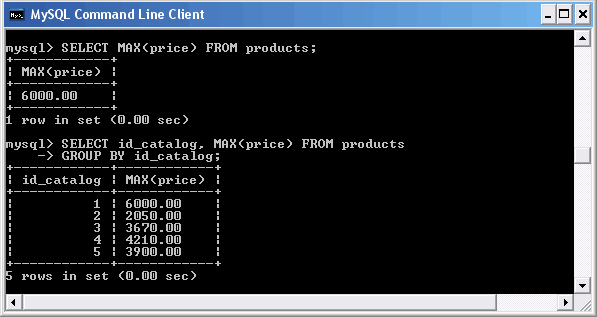
Для поиска максимального значения в столбце expr предназначена функция
MAX([DISTINCT] expr)
В качестве аргумента expr обычно выступает имя столбца. Необязательное ключевое слово DISTINCT позволяет дать указание СУБД MySQL обрабатывать только уникальные значения столбца expr.
Использование функции MAX()
Сумма столбцов
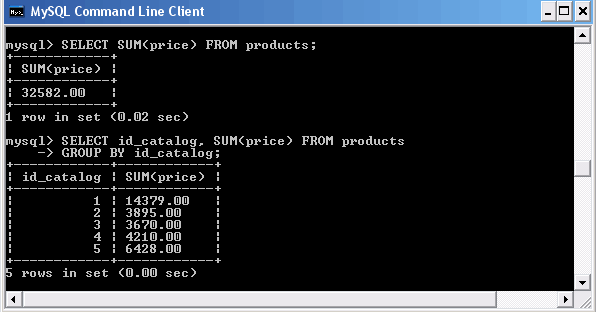
Сумму столбца expr позволяет подсчитать функции
SUM([DISTINCT] expr)
Если возвращаемый набор данных не содержит ни одной строки, то функция возвращает NULL. Необязательное ключевое слово DISTINCT позволяет потребовать от СУБД MySQL обрабатывать только уникальные значения столбца expr.
Использование функции SUM()
Вопрос 21
Внутреннее соединение
В операторе JOIN внутреннее соединение указывается ключевым словом INNER (впрочем, его можно опустить, так как соединение двух таблиц является внутренним по умолчанию). Условие соединения указывается после ключевого слова ON. В этом случае внутреннее соединение с помощью фразы FROM JOIN очень похоже на соединение с использованием фразы WHERE. Запишем первый пример с предыдущего раздела с использование оператора JOIN.
Запрос: Список всех клиентов с указанием названий городов, в которых они проживают
SELECT FName, LName, CityName
FROM Customer k JOIN
City c ON k.IdCity = c.IdCity
При соединении с использованием фразы FROM дополнительное условие можно для увеличения наглядности запроса помещать во фразу WHERE. В этом случае второй пример с предыдущего раздела примет такой вид. Запрос: Список всех клиентов из Казани с фамилией Иванов
SELECT K.IdCust, k.FName
FROM Customer k INNER JOIN
City c ON k.IdCity = c.IdCity
WHERE k.LName = 'Иванов' AND c.CityName = 'Казань'
Внешнее соединение
Все соединения таблиц, рассмотренные до сих пор, являются внутренними. Во всех примерах вместо ключевого слова JOIN можно писать INNER JOIN (внутреннее соединение). Из таблицы, получаемой при внутреннем соединении, отбраковываются все записи, для которых нет соответствующих записей одновременно в обеих соединяемых таблицах. При внешнем соединении такие несоответствующие записи сохраняются. В этом и заключается отличие внешнего соединения от внутреннего.
С помощью специальных ключевых слов LEFT OUTER, RIGHT OUTER и FULL OUTER, написанных перед JOIN, можно выполнить соответственно левое, правое и полное соединение. В SQL-выражении запроса таблица, указанная слева от оператора JOIN, называется левой, а указанная справа от него — правой.
При левом внешнем соединении несоответствующие записи, имеющиеся в левой таблице, сохраняются в результатной таблице, а имеющиеся в правой — удаляются. Значения столбцов из правой таблицы во всех строках, не имеющих соответствия с левой таблицей, принимают значение NULL.
При правом внешнем соединении несоответствующие записи, имеющиеся в правой таблице, сохраняются в результатной таблице, а имеющиеся в левой — удаляются. Значения столбцов из левой таблицы во всех строках, не имеющих соответствия с правой таблицей, принимают значение NULL.
Соответственно левое и правое внешние соединения различаются только порядком следования таблиц.
При полном внешнем соединении двух таблиц результирующая таблица содержит все строки внутреннего соединения этих таблиц, а также не включенные им строки и первой, и второй таблиц (дополненные значениями NULL для отсутствующих столбцов).
В следующем примере возвращается полный список городов с указанием количества клиентов из каждого из них
SELECT c.CityName, a.CountCity
FROM City c LEFT OUTER JOIN
(SELECT IdCity, COUNT(*) AS CountCity
FROM Customer
GROUP BY IdCity) a ON c.IdCity = a.IdCity
ORDER BY c.CityName
Если в данном запросе заменить левое внешнее соединение на внутреннее, то из результата будут потеряны города, из которых нет ни одного клиента (проверьте это заменив LEFT OUTER JOIN на INNER JOIN и объясните причину разницы). Обратите внимание, что таблица City соединяется не с таблицей, а с подзапросом, которому задан псевдоним a.