

3.1 Методы и стандарты передачи речи по трактам связи, применяемые в современном оборудовании (7 кГц)
Речь представляет собой колебания сложной формы, зависящей от произносимых слов, тембра голоса, интонации, пола и возраста говорящего.
Спектр речи весьма широк (примерно от 50 до 10000 Гц), но для передачи речи в аналоговой телефонии когда-то отказались от составляющих, лежащих вне полосы 0,3-3,4 кГц, что ухудшило восприятие ряда звуков, но мало затронуло разборчивость. Ограничение частоты снизу (до 300 Гц) также ухудшает восприятие из-за потерь низкочастотных гармоник основного тона. А в цифровой телефонии к влиянию ограничения спектра добавляются еще шумы дискретизации, квантования и обработки, дополнительно зашумляющие речь.
Решающими в выборе полосы 0,3-3,4 кГц были экономические соображения и нехватка телефонных каналов. Для совместимости по полосе с распространенными аналоговыми сетями в цифровой телефонии отсчеты аналоговой речи приходится брать согласно теореме Котельникова с частотой 8 кГц — не меньше двух отсчетов на 1 Гц полосы. Правда, в цифровой телефонии существует принципиальная возможность использовать спектр речи за пределами полосы 0,3-3,4 кГц и тем самым повысить качество, но эти методы не реализуются, так как они вычислительно пока еще очень сложны. При полосе исходного сигнала до 6 кГц и тактовой частоте отсчетов около 16 кГц сжатый цифровой сигнал требует для передачи канал в 12 кбит/с. При этом оценка качества по критерию MOS может быть выше 4,5 балла.
Озвученная речь, представляющая большую трудность для сжатия, образуется с помощью звуковых связок человека. Скорость их периодических колебаний задает так называемую частоту основного тона (ОТ) — периодическую подпитку энергией голосового тракта человека, который представляет собой объемный резонатор. Голосовой тракт формирует спектральную окраску речи, или, другими словами, ее формантную структуру. Другое название голосового тракта - синтезирующий фильтр — нам более удобно, так как математическое описание речеобразования обычно ведется в терминах линейной фильтрации. Тогда, условно, речевой сигнал можно разделить на две составляющие, отвечающие за 1- ый ОТ (возбуждение фильтра) и 2-ой голосовой тракт (формантная структура сигнала). Соответственно, большинство на сегодня используемых алгоритмов, так или иначе, решают один вопрос - как наиболее эффективно выделить и сокращенно описать обе составляющие. А отрезки глухой речи при моделировании заменяют спектрально окрашенным шумом.
3.1.1 Импульсно-кодовая модуляция (pcm — Pulse-Code Modulation)
Прямое аналого-цифровое преобразование является низкоэффективным (т. е. имеющим малую скорость кодирования при заданном качестве) высококачественным методом кодирования.
Кодеки, построенные на базе данного метода, работают на скоростях не ниже 32 кбит/с. При этом полоса входного аналогового сигнала ограничена диапазоном 0,3-3,4 кГц. Для повышения качества преобразования полоса может быть расширена до 6 кГц, что соответствует скорости передачи 88 кбит/с при частоте дискретизации 12 кГц (при дальнейшем расширении полосы качество представления речи не повышается).
Еще в 60-х годах был принят алгоритм оцифровки голоса под названием импульсно-кодовой модуляции (Pulse-Code Modulation — PCM, международный стандарт G.711). Оцифровка голосового сигнала включает измерение уровня аналогового сигнала через равные промежутки времени. В соответствии со стандартом G.711 принимается, что для узнаваемости голоса необходимо обеспечить передачу его частотных составляющих в диапазоне от 200 до 3400 Гц. Известно, что для правильной передачи всех частотных составляющих необходимо измерять уровень сигнала с частотой 8 кГц. В стандарте также принимается, что оцифровка аналогового сигнала производится с восьмиразрядным разрешением. При этом обычно используется один из двух способов установления соответствия между амплитудой звукового сигнала и цифровым значением - либо A-кодирование (оно принято в Европе и Азии), либо мю-кодирование (принятое в США, Канаде и некоторых других странах) . И то и другое — просто таблицы соответствия между измеряемым значением напряжения и числом, при помощи которого оно кодируется. Для передачи одного голосового канала в цифровом виде требуется пропускная способность 64 кбит/с (8 кГц х 8 разрядов).
3.1.2 m-Law и A-Law кодирование
Когда звуковая карта получает звуковые данные, она преобразует каждое значение дискретизации в соответствующее значение напряжения, которое затем усиливается и подается на динамик или наушники. При изменении значения оцифрованного звука меняется напряжение, а динамик преобразует изменение напряжения в изменение звукового давления, которое в виде звуковой волны распространяется в воздухе и достигает вашего уха.
Какая же связь между значением оцифрованного звука и генерируемым звуковой картой напряжением? Наиболее очевидный подход заключается в использовании линейной связи (linear relation), при которой, например, увеличение значения цифрового представления звука вдвое будет приводить к увеличению напряжения также в два раза. Однако этот подход не эффективен. Человеческое ухо воспринимает звук нелинейно: разница между малыми цифровыми представлениями звукового сигнала может быть слишком велика для слабых звуков, в то время как разница между большими представлениями будет слишком мала, чтобы ухо ее различило.
Принимая во внимание указанную природу человеческого слуха вводят логарифмическую шкалу. Соотношения m-Law и A-Law соответствуют этой шкале. Соотношение m-Law используется, прежде всего, в Северной Америке и в Японии.
Для преобразования значения линейной дискретизации m в дискретизацию Ym используется следующее уравнение:
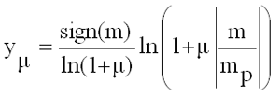
где mp — максимальное входное значение оцифрованного звука, а m — константа, обычно 100 или 255.
A-Law используется в Европе. Оно также используется для преобразования значения линейной дискретизации в дискретизацию YA . А — это константа 87.6:
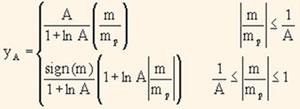
Соотношения m-Law и A-Law позволяют восьмиразрядные измерения представлять в том же диапазоне, что и линейные 12-разрядные. Таким образом, можно получить более чем 30% сжатия.