

Содержание
|
Введение |
4 |
|
|
1 Описание языка |
6 |
|
|
2 Лексический анализатор |
8 |
|
|
3 Синтаксический анализатор |
14 |
|
|
4 Абстрактный синтаксис |
17 |
|
|
Заключение |
19 |
|
|
Литература |
20 |
|
|
Приложение А – Модуль лексического анализатора |
| |
|
Приложение Б – Модуль синтаксического анализатора |
| |
|
Приложение В – Код основной программы |
| |
Введение
Для анализа синтаксиса формальных языков программирования используют сначала лексический, а затем синтаксический анализаторы.
Основная задача лексического анализа – разбить входной текст, состоящий из последовательности одиночных символов, на последовательность слов (лексем).
С точки зрения дальнейших этапов работы компилятора, лексический анализатор выдает информацию двух видов: класс лексемы и значение лексемы. Ключевые слова распознаются либо явным выделением из входной последовательности, либо сначала выделяется идентификатор, а затем делается проверка на принадлежность его множеству ключевых слов.
Лексический анализатор может работать или как самостоятельная фаза трансляции, или как подпрограмма, работающая по принципу “дай лексему”.
Синтаксический анализатор ( синтаксический разбор) – это часть компилятора, которая отвечает за выявление основных синтаксических конструкций входного языка. В задачу синтаксического анализа входит: найти и выделить основные синтаксические конструкции в тексте входной программы, установить тип и проверить правильность каждой синтаксической конструкции и, наконец, представить синтаксические конструкции в виде, удобном для дальнейшей генерации текста результирующей программы.
В основе синтаксического анализатора лежит распознаватель текста входной программы на основе грамматики входного языка.
Цель данной курсовой работы – создание компилятора для подмножества языка Модула 2. Язык Модула-2 — структурный, модульный язык программирования, с синтаксисом, основанным на языке Паскаль, но заметно переработанным и улучшенным. Компилятор должен проверять входную последовательность на корректность ввода. В случае правильного разбора программа строит абстрактное синтаксическое дерево. При обнаружении ошибки должно выводиться соответствующее сообщение.
Курсовая работа предполагает использование лексического и синтаксического анализатора. Первый реализован с помощью детерминированного конечного автомата. Для второго используется метод разбора Jacc.
1 Описания языка
Язык Модула-2 — структурный, модульный язык программирования, с синтаксисом, основанным на языке Паскаль, но заметно переработанным и улучшенным.
Программа представляет собой набор модулей — самостоятельных единиц компиляции, которые могут компилироваться раздельно. При этом программный модуль может быть (но не обязан) разделён на две части: модуль определений и модуль реализации. Модуль определений — это внешний интерфейс модуля, то есть набор экспортируемых им имён констант, переменных, типов, заголовков процедур и функций, которые доступны внешним модулям. Модуль реализации содержит программный код, в частности, конкретизацию описаний всего, что перечислено в модуле определений. Например, некоторый тип «запись» может быть объявлен в модуле определений с указанием лишь его имени, а в модуле реализации — с полной структурой. В этом случае внешние модули могут создавать значения данного типа, вызывать процедуры и функции, работающие с ним, выполнять присваивание переменных, но не имеют прямого доступа к структуре значений, поскольку эта структура не описана в модуле определений. Если для этого же типа описать в модуле определений структуру, то она станет доступна. Помимо модулей глобального уровня в Модуле-2 допускается создавать локальные модули.
Импорт определений, описанных в прочих модулях, полностью контролируется. Можно импортировать модули определений целиком, но синтаксис позволяет существенно уточнять списки импорта, например, импортировать из модуля конкретные константы, переменные, процедуры и функции, только те, которые необходимы.
Все средства ввода-вывода исключены из языка. Вместо них используются библиотечные модули, на которые возложена задача реализации ввода-вывода на конкретных системах. Однако имеется набор стандартизованных библиотек ввода-вывода, предоставляющих необходимые функции для типичных случаев (ввод-вывод основных типов данных с использованием текстового терминала, файловый ввод-вывод).
В язык введён минимум понятий и примитивов для многопоточного программирования, добавлена также стандартная библиотека, поддерживающая параллельные программы.
Включены средства прямого доступа к аппаратуре компьютера, в частности, реализовано прямое отображение структур данных на память, в том числе с прямым заданием адреса.
Язык прост по структуре - в нём имеется только 40 ключевых слов (для сравнения - в Аде их 63), официальное "Сообщение о языке", содержащее исчерпывающее описание Модулы-2, занимает 40 страниц (полное описание сокращённого варианта PL/1 занимает около 200 страниц).
Описать особенности Модулы-2 проще всего путём сравнения с языком Паскаль. Наиболее важные отличия, помимо введения модулей и механизмов управляемого экспорта описаний, состоят в следующем:
Язык регистро-зависимый — прописные и строчные буквы в идентификаторах различаются. Все ключевые слова пишутся в верхнем регистре.
Циклы WHILE и FOR также предусматривают тело из набора операторов и заканчиваются ключевым словом END.
Добавлен безусловный цикл LOOP-END.
И процедуры, и функции объявляются с ключевым словом PROCEDURE.
Добавлен предопределённый тип BITSET — битовое множество.
Из языка исключён оператор безусловного перехода GOTO.
Добавлен процедурный тип, дающий возможность присваивать процедуры и функции переменным. Позже эта возможность была включена и в Паскаль, где она изначально отсутствовала.
Можно определённо сказать, что язык Модула-2, сохранив все положительные черты Паскаля, прежде всего, простоту и логичность синтаксиса, имеет, по сравнению с языком-предком, массу дополнительных положительных черт, делающих его гораздо более мощным и лучше приспособленным как для системного, так и для прикладного программирования (что, в общем, неудивительно, так как Паскаль создавался как учебный язык, а Модула-2 — как язык системного программирования). Все или почти все вышеперечисленные изменения синтаксиса и дополнительные возможности можно рассматривать как достоинства языка. Свойственная всем языкам Вирта лаконичность, стремление к созданию минимального достаточного для решения поставленных задач инструментария проявились в полной мере.
2. Лексический анализатор
Для лексического анализа был построен детерминированный конечный автомат. Для этого сначала были построены регулярные выражения:
Идентификатор: (буква)(буква|цифра)*
Число: (цифра)+(( , | .)(цифра)+)?
Точка: .
Запятая: ,
Знак сложения: +
Знак вычитания: -
Знак умножения: *
Знак деления: /
Открывающая скобка: (
Закрывающая скобка: )
Знаки сравнения: >|<|=
Точка с запятой: ;
Знак двоеточие: :
Знак присваивания: :=
Лексический анализатор проверят каждый идентификатор на совпадение с ключевым словом. Если совпадение найдено, то идентификатор распознается как ключевое слово, в противном случае, он распознается как идентификатором. В данном подмножестве языка Паскаль ключевыми словами являются:
var
begin
end
read
write
while
do
if
then
else
or
and
Все регулярные выражения были преобразованы в недетерминированные конечные автоматы. Основные из них представлены на рисунках 2.1–2.7.

Рисунок 2.1 – НКА для точки

Рисунок 2.2 – НКА для запятой

Рисунок 2.3 – НКА для точки с запятой

Рисунок 2.4 – НКА для знаков сравнения

Рисунок 2.5 – НКА для знака присваивания
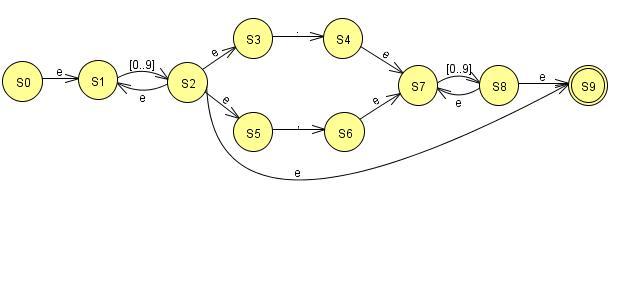
Рисунок 2.6 – НКА для числа

Рисунок 2.7 – НКА для идентификатора
Далее недетерминированные конечные автоматы были детерминированы. Основные из полученных детерминированных конечных автоматов представлены на рисунках 2.8–2.9. Шаги преобразования представлены в таблицах 1–2.
Таблица 1– Преобразование идентификатора
|
|
Буква |
Цифра |
|
{0} |
{1,2,4,6,7} |
– |
|
{1,2,4,6,7} |
{3,6,7,1,2,4} |
{5,6,7,1,2,4} |
|
{3,6,7,1,2,4} |
{3,6,7,1,2,4} |
{5,6,7,1,2,4} |
|
{5,6,7,1,2,4} |
{3,6,7,1,2,4} |
{5,6,7,1,2,4} |

Рисунок 2.8 – ДКА для идентификатора
Таблица 2 – Преобразование числа
|
|
Цифра |
. |
, |
|
{1} |
{2,3,5,1,9} |
– |
– |
|
{2,3,5,1,9} |
{2,3,5,1,9} |
{4,7} |
{6,7} |
|
{4,7} |
{8,9,7} |
– |
– |
|
{6,7} |
{8,9,7} |
– |
– |
|
{8,9,7} |
{8,9,7} |
– |
– |

Рисунок 2.9 – ДКА для числа
Следующим шагом построения конечного автомата является минимизация. При минимизации конечного автомата все состояния делятся на две группы: финальные и нефинальные. Затем выполняется следующая процедура. Рассматриваем группу {S1, S2, …, Sk} и некоторый входной символ а. Если по этому входному символу есть переходы в разные группы, то исходную группу разбивают на части. Принадлежность Si к той или иной части зависит от того, в какую группу существует переход из состояния Si по входному символу а. Эта процедура продолжается до тех пор, пока не останется ни одной группы, которую можно было бы разбить по какому-либо входному сигналу. Результаты минимизации представлены на рисунках 2.10-2.11

Рисунок 2.10 – МКА для идентификатора
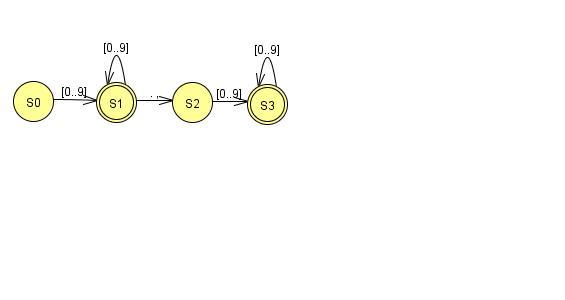
Рисунок 2.11 – МКА для числа
Все минимизированные ДКА были объединены в один автомат. Результат объединения представлен на рисунке 2.12. Это автомат далее используется в лексическом анализе.

Рисунок 2.12 – ДКА для подмножества языка Паскаль
Код лексического анализатора представлен в приложении А.
3 Синтаксический анализатор
Одним из средств автоматизированного построения трансляторов является генератор компиляторов Yacc.
Yacc строит синтаксический анализатор, работающий на основе метода “сдвиг - приведение”.
Этот генератор работает с атрибутными грамматиками. Атрибутные грамматики характеризуются тем, что с каждым грамматическим символом связывается множество атрибутов.
Атрибуты в атрибутных грамматиках могут быть двух видов: синтезируемые и наследуемые. Синтезируемые атрибуты вычисляют свои значения, используя только значения атрибутов потомков. Наследуемые атрибуты при вычислении значений используют значения атрибутов соседей и родителей.
С каждой продукцией атрибутной грамматики связывается семантическое правило. Такие правила выполняются в тот момент, когда происходит приведение по соответствующей продукции.
Исходный текст для yacc состоит из трех частей: определения, продукции и вспомогательные процедуры. Части разделяются символами %%.
В части определений можно указать код, который должен быть перенесен в текст результирующего транслятора без изменения. Для этого он помещается между символами %{ и %}.
Часть определений включает следующие разделы.
1 Задание стартового символа.
%start символ
Если такое определение отсутствует, то в качестве стартового символа используется нетерминал левой части первой продукции.
2 Определение атрибутов терминалов грамматики.
%token <тип атрибута> терминал
При наличии такого определения в исходном тексте, в модуле, содержащем транслятор, декларируется константа указанного типа с именем, соответствующим терминалу. Эти константы используются в исходном файле Lex без дополнительных объявлений..
3 Задание ассоциативности операций.
%left символ – лево ассоциативная операция
%right символ – право ассоциативная операция
%noassoc символ – неассоциативная операция
Приоритет операции определяется ее положением при определении. Чем ниже задана операция при определении, тем выше ее приоритет.
4 Задание типов атрибутов нетерминалов
%type <тип атрибута> нетерминал.
Вторая часть Yacc-программы содержит продукции и связанные с ними семантические правила. Левая часть продукции отделяется от правой символом “:”.
Семантические правила записываются на языке Pascal и следуют за продукцией, заключенные между символами “{” и “}”. Для обращения в семантических правилах к атрибуту нетерминала левой части продукции используют символы $$. Для обращения к атрибутам грамматических символов правой части продукций используются символы $i, где i – номер грамматического символа в продукции.
Если для одного и того же нетерминала левой части существует несколько продукций, то это записывается следующим образом.
нетерминал : продукция 1 {семантическое правило 1}
…
| продукция n {семантическое правило n}
Третья часть Yacc-программы содержит вспомогательные процедуры. Эта часть переносится в результирующий код без изменения.
Код синтаксического анализатора представлен в приложении Б.
Семантические правила строились на основе следующей грамматики:
GOAL → VARZONE PROGZONE
VARZONE → key_var id LIST_ID dp typ tz VARZONE1
|ε
VARZONE1→ id LIST_ID dp typ tz VARZONE1
|ε
LIST_ID → zpt id LIST_ID
|ε
PROGZONE → key_begin COMMANDS key_end tchk
COMMANDS →COMMAND tz COMMANDS
|ε
COMMAND → BLOCK
|PRISVCOM
|READCOM
|WRITECOM
|WHILECOM
|IFCOM
PRISVCOM → id prisv EXPR
READCOM → key_read os id zs
WRITECOM → key_write os id zs
WHILECOM → key_while BOOL key_do BLOCK
IFCOM → key_if BOOL key_ then IF_INSTR ELSECOM
ELSECOM → key_else IF_INSTR
|ε
IF_INSTR → IFCOM
|BLOCK
BOOL → BOOL_FACTOR BOOL_TERM
|BOOL_FACTOR BOOL_EXPR
BOOL_TERM → key_and BOOL
|ε
BOOL_EXPR → key_or BOOL
|ε
BOOL_FACTOR → os BOOL_FACTOR1 zs
BOOL_FACTOR1 → FACTOR sign FACTOR
BLOCK → key_begin COMMANDS key_end
EXPR → TERM EXPR1
TERM → FACTOR TERM1
TERM1 → mult FACTOR TERM1
|division FACTOR TERM1
|ε
EXPR1 → plus TERM EXPR1
|minus TERM EXPR1
|ε
FACTOR → num
|id