

Методы кодирования параметров сигнала. Вокодеры и полувокодеры.
Изначально вокодеры (voice coder — устройство синтеза речи на основе произвольного сигнала при передаче речевых сообщений) были разработаны в целях экономии частотных ресурсов радиолинии системы связи при передачи речевых сообщений. Экономия достигалась за счёт того, что вместо собственно речевого сигнала передают только значения его определённых параметров, которые на приемной стороне управляют синтезатором речи. Основу синтезатора речи составляют три элемента: генератор тонального сигнала для формирования гласных звуков, генератор шума для формирования согласных и система формантных фильтров для воссоздания индивидуальных особенностей голоса. После всех преобразований голос человека становится похожим на голос робота, что вполне терпимо для средств связи и интересно для музыкальной сферы.
Формантный фильтр — это система резонансных фильтров, предназначенная для генерации речевого сигнала с заданной фонетической структурой. В основу структуры формантного фильтра заложена упрощённая модель голосового тракта. Основные параметры формант – центральная частота, амплитуда и ширина.
В полосных вокодерах же спектр речи делится на 7 - 20 полос (каналов) аналоговыми или цифровыми полосовыми фильтрами. Большее число каналов в вокодере дает большую натуральность и разборчивость. С каждого полосового фильтра сигнал поступает на детектор и фильтр низких частот с частотой среза 25 Гц. Таким образом, сигналы на выходе каждого канала изменяются с частотой менее 25 Гц.
В основе вокодеров с линейным предсказанием лежит теория вероятности и статистические особенности звуков речи.
Кодирование источников дискретных сообщений
Под дискретным источником сообщений обычно подразумевают некоторое устройство, которые через определённые интервалы времени выдаёт (детерминированным или случайным образом) очередной символ сообщения, принадлежащий заданному конечному алфавиту. В теории информации под под D-ичным кодированием понимают следующее определение:
Пусть
даны два конечных множества
 алфавит источника сообщений,
алфавит источника сообщений,
 кодовый алфавит. Алфавитное
D-ичное кодирование
– произвольное отображение
кодовый алфавит. Алфавитное
D-ичное кодирование
– произвольное отображение
 кодовое слово. Набор кодовых слов
кодовое слово. Набор кодовых слов
 D-ичный
код алфавита
D-ичный
код алфавита
 .
Если при этом все кодовые слова имеют
одинаковую длину, кодирование
.
Если при этом все кодовые слова имеют
одинаковую длину, кодирование
 равномерное,
иначе – неравномерное.
равномерное,
иначе – неравномерное.
Алфавитное
кодирование
 однозначно
декодируемо,
если отображение
однозначно
декодируемо,
если отображение
 отображение множества всех конечных
последовательностей алфавита
отображение множества всех конечных
последовательностей алфавита
 на множество конечных последовательностей
кодовых слов (правилом конкатенации) –
инъективно.
на множество конечных последовательностей
кодовых слов (правилом конкатенации) –
инъективно.
Если
заданы алфавит источника
 кодовый алфавит
кодовый алфавит
 и распределение
и распределение
 то средней
длинной кодового
слова при алфавитном кодировании
то средней
длинной кодового
слова при алфавитном кодировании
 (
( )
называется величина
)
называется величина

Алфавитное
кодирование
 называется оптимальным,
если
называется оптимальным,
если
 однозначно
декодируемо и средняя длина
однозначно
декодируемо и средняя длина
 минимальна.
минимальна.
Важно
то, что оптимальное кодирование
 существует, обоснование этому утверждению
дано в [2]. Рассмотрим примеры оптимальных
кодов.
существует, обоснование этому утверждению
дано в [2]. Рассмотрим примеры оптимальных
кодов.
Код Шеннона-Фано.
Кодирование
Шеннона - Фано – алгоритм префиксного
кодирования (т.е. никакое кодовое слово
 не является началом какого-либо другого
кодового слова), относится
к вероятностным методам
сжатия. Ниже приведен алгоритм
не является началом какого-либо другого
кодового слова), относится
к вероятностным методам
сжатия. Ниже приведен алгоритм
-
Символы первичного алфавита
 выписывают
в порядке убывания вероятностей.
выписывают
в порядке убывания вероятностей. -
Символы полученного алфавита делят на две части, суммарные вероятности символов которых максимально близки друг другу.
-
В префиксном коде для первой части алфавита присваивается цифра «0», второй части — «1».
-
Полученные части рекурсивно делятся и их частям назначаются соответствующие двоичные цифры в префиксном коде.
Пример.
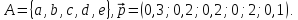 Тогда последовательно разбиение
подмножеств можно наглядно представить
как:
Тогда последовательно разбиение
подмножеств можно наглядно представить
как:
|
a |
0,3 |
0 |
0 |
|
|
|
b |
0,2 |
0 |
1 |
|
|
|
c |
0,2 |
1 |
0 |
|
|
|
d |
0,2 |
1 |
1 |
0 |
|
|
e |
0,1 |
1 |
1 |
1 |
|





Алгоритм Хаффмана
Алгоритм Хаффмана — жадный алгоритм оптимального префиксного кодирования с минимальной избыточностью.
Этот метод кодирования состоит из двух основных этапов:
1. Построение оптимального кодового дерева.
2. Построение отображения код-символ на основе построенного дерева.
Алгоритм:
1. Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, равный вероятности символа
2. Выбираются два свободных узла дерева с наименьшими весами.
3. Создается их родитель с весом, равным их суммарному весу.
4. Родитель добавляется в список свободных узлов, а два его потомка удаляются из этого списка.
5. Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0.
6. Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
На том же примере код Хаффмана будет выглядеть так:
