

1 Введение
Управление процессами добычи нефти характеризуется наличием значительного числа рассредоточенного технологического оборудования. Рассредоточенность и удаленность основных объектов, отсутствие надежных коммуникационных каналов существенно затрудняет оперативный контроль и управление технологическим процессом добычи нефти на конкретной скважине. В настоящее время в ОАО Татнефть задача обеспечения надежности эксплуатации нефтяных скважин решается в рамках использования SCADA-системы диспетчеризации событий и управления АРМИТС.
Недостатком использования SCADA систем с точки зрения обеспечения технологической безопасности является то, что они фиксируют только возникшие на текущий момент сбои и аварии оборудования. Контроллеры, обеспечивающие безопасность оборудования на местах фиксируют аварию только в момент ее критического развития, когда что-либо предпринять, как правило, довольно сложно. Это приводит к существенным финансовым потерям при эксплуатации оборудования нефтяных скважин, связанными с необходимостью восстановления и ремонта разрушенного оборудования.
В настоящее время регистрация и контроль показателей состояния эксплуатации нефтяных скважин 3-блока Березовской площади происходит с использованием контроллеров OPC «Мега» в реальном времени с диспетчеризацией управления, передачей оперативной информации СУБД программного комплекса АСУТП НГДУ XSPROC в сервер интеграции и далее, после соответствующей обработки, в АРМИТС, и накоплением в Едином хранилище данных.
Показатели эксплуатации скважины, параметры пласта и оборудования являются взаимозависимыми, и, как правило, для них аналитический вид функций отсутствует. Поэтому определение статистических моделей для таких основных показателей, как дебит жидкости и коэффициент подачи насоса, нагрузка на штангу (ШГН) для каждой скважины, совместно с существующими методиками в реальном времени позволит более точно диагностировать состояние скважины:
работает по режиму
тенденция изменения параметров к внештатному
внештатная ситуация
сбойная или предаварийная ситуация.
В связи с этим, актуальным является создание методики прогнозирования возможных в будущем сбоев и аварий оборудования нефтяных скважин, распознавания их на более ранних стадиях развития, а также выработки рекомендаций по проведению профилактических мер с целью недопущения этих аварий.
Прогноз сбоев и аварий технологического оборудования с привлечением средств статистического анализа и моделирования процессов позволяет прогнозировать нежелательные тенденции и сценарии развития в работе оборудования нефтяных скважин с использованием хорошо разработанного математического аппарата, на базе накопленной статистики данных. Использование данной методики позволит выявить скрытые нежелательные тенденции, плохо формализуемые с помощью аналитических методов.
1. Характеристики случайных величин и статистические методы прогнозирования
1.1. Характеристики случайных величин
Первым шагом к статистическому анализу результатов замеров дебита скважины является использование описательной статистики, то определение таких величин, как объем совокупности, среднее значение, дисперсия и среднее квадратическое отклонение, мода, медиана, размах варьирования, наибольшее и наименьшее значения, отклонение случайного распределения от нормального [1, 2].
Выборочным средним называют среднее арифметическое значение результатов наблюдения. Стандартное отклонение характеризует разброс данных около выборочного среднего. Коэффициент асимметрии указывает степень асимметричности плотности вероятности относительно выборочного среднего. Коэффициент асимметрии определяется третьим центральным моментом распределения. В любом симметричном распределении с нулевым математическим ожиданием, например нормальным, все нечетные моменты, в том числе и третий, равны нулю, поэтому коэффициент асимметрии тоже равен нулю. Степень сглаженности плотности вероятности в окрестности главного максимума задается еще одной величиной — коэффициентом эксцесса. Он показывает, насколько острую вершину имеет плотность вероятности по сравнению с нормальным распределением. Если коэффициент эксцесса больше нуля, то распределение имеет более острую вершину, чем нормальное распределение, если меньше нуля, то более плоскую.
Мода – это значение признака, которое чаще других встречается в совокупности данных. Медиана – это значение признака, которое разделяет совокупность на две равные по числу элементов части. Размах варьирования R – это разность между наибольшим xmax и наименьшим xmin значениями признака совокупности (генеральной или выборочной): R=xmax–xmin. .
Для оценки отклонения распределения данных эксперимента от нормального распределения используются такие характеристики как асимметрия А и эксцесс Е. Для нормального распределения А=0 и Е=0. Асимметрия показывает, на сколько распределение данных несимметрично относительно нормального распределения. Эксцесс оценивает «крутость», т.е. величину большего или меньшего подъема максимума распределения экспериментальных данных по сравнению с максимумом нормального распределения.
Более точную информацию о форме распределения можно получить с помощью критериев нормальности (например, критерия Колмогорова-Смирнова или W-критерия Шапиро-Уилка). Однако ни один из этих критериев не может заменить визуальную проверку с помощью гистограммы (рис. 1.1).
|
|
Рисунок 1.1 – Пример гистограммы |
|
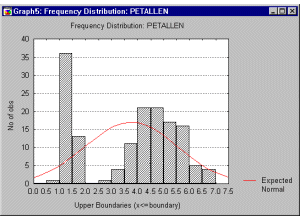
Гистограмма позволяет качественно оценить различные характеристики распределения. Например, на ней можно увидеть, что распределение бимодально (имеет 2 пика). Это может быть вызвано, например, тем, что выборка неоднородна, возможно, извлечена из двух разных наборов, распределение в каждом из которых более или менее нормально. В таких ситуациях, чтобы понять природу наблюдаемых переменных, можно попытаться найти качественный способ разделения выборки на две части.
Корреляция представляет собой меру зависимости переменных. Наиболее известна корреляция Пирсона r, которая называется также линейной корреляцией, т.к. измеряет степень линейных связей между переменными. Коэффициенты корреляции изменяются в пределах от -1.00 до +1.00. Значение -1.00 означает, что переменные имеют строгую отрицательную корреляцию. Значение +1.00 означает, что переменные имеют строгую положительную корреляцию. Значение 0.00 означает отсутствие корреляции.
Значение коэффициента корреляции не зависит от масштаба измерения. Корреляция высокая, если на графике зависимость "можно представить" прямой линией с положительным или отрицательным углом наклона. Проведенная прямая называется прямой регрессии или прямой, построенной методом наименьших квадратов (рис. 1.2).
Квадрат коэффициента корреляции Пирсона (r2) называется коэффициентом детерминации и представляет собой долю вариации, общую для двух переменных (иными словами, "степень" зависимости или связанности двух переменных).
|
|
Рисунок 1.2 – Пример прямых регрессии |
|

Чтобы оценить зависимость между переменными, нужно знать не только коэффициент корреляции, но и его значимость. Критерий значимости основывается на предположении, что распределение остатков (т.е. отклонений наблюдений от регрессионной прямой) для зависимой переменной y является нормальным (с постоянной дисперсией для всех значений независимой переменной x).
При вычислении корреляции необходимо принимать во внимание влияние выбросов - нетипичных, резко выделяющихся наблюдений. Выбросы могут существенно повлиять на значение коэффициента корреляции. Обычно считается, что выбросы представляют собой случайную ошибку, которую следует контролировать. Чтобы не быть введенными в заблуждение полученными значениями, необходимо проверить на диаграмме рассеяния (рис. 1.3) каждый важный случай значимой корреляции.
Для удаления выбросов в ряде случаев применяются численные методы. Например, исключаются значения, которые выходят за границы ±2 стандартных отклонений вокруг выборочного среднего. Однако, в некоторых случаях относительная частота выбросов к численности групп может быть исследована и разумно проинтерпретирована с точки зрения самой организации эксперимента.
Отсутствие однородности в выборке также является фактором, смещающим (в ту или иную сторону) выборочную корреляцию. Высокая корреляция может быть следствием разбиения данных на две группы, а вовсе не отражать "истинную" зависимость между двумя переменными, которая может практически отсутствовать. Для определения однородных подмножеств применяются многомерные методы разведочного анализа, такие как, например, кластерный анализ.
|
|
Рисунок 1.3 – Пример диаграммы рассеяния |
|
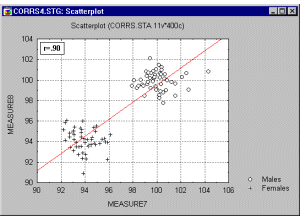
Другим возможным источником трудностей, связанным с линейной корреляцией Пирсона r, является форма зависимости. Корреляция Пирсона r хорошо подходит для описания линейной зависимости. Естественного обобщения коэффициента корреляции Пирсона r на случай нелинейных зависимостей нет. Однако, если кривая монотонна (монотонно возрастает или, напротив, монотонно убывает), то можно преобразовать одну или обе переменные, чтобы сделать зависимость линейной, а затем уже вычислить корреляцию между преобразованными величинами. Для этого часто используется логарифмическое преобразование. Другой подход состоит в использовании непараметрической корреляции (например, корреляции Спирмена).
Два самых точных метода исследования нелинейных зависимостей непросты и состоят в следующем:
а) Нужно попытаться найти функцию, которая наилучшим способом описывает данные. После того как функцию определена, можно проверить ее "степень согласия" с данными.
б) Определить группирующую переменную, которая разбитывает данные группы (например, на 4 или 5 групп). а затем применить дисперсионный анализ.
Во многих исследованиях первый шаг анализа состоит в вычислении корреляционной матрицы всех переменных и проверке значимых (ожидаемых и неожиданных) корреляций. После того как это сделано, следует понять общую природу обнаруженной статистической значимости. Однако, если используется несколько критериев, то значимые результаты могут появляться "удивительно часто", и это будет происходить чисто случайным образом.
Основываясь на коэффициентах корреляции невозможно строго доказать причинную зависимость между переменными, однако можно определить ложные корреляции, т.е. корреляции, которые обусловлены влияниями "других", остающихся вне поля зрения переменных. Для контроля (частично исключенного) влияния определенных переменных можно воспользоваться частными корреляциями.
Наиболее часто используемым методом обнаружения различия между средними двух выборок является t-критерий. Теоретически, t-критерий может применяться, даже если размеры выборок очень небольшие, и если переменные нормально распределены (внутри групп), а дисперсии наблюдений в группах не слишком различны. Предположение о нормальности можно проверить, исследуя распределение (например, визуально с помощью гистограммы) или применяя какой-либо критерий нормальности. Равенство дисперсий в двух группах можно проверить с помощью F-критерия или использовать более устойчивый критерий Левена. Если условия применимости t-критерия не выполнены, следует использовать непараметрические альтернативы t-критерия.
Чтобы применить t-критерий для независимых выборок, требуется, по крайней мере, одна независимая (группирующая) переменная и одна зависимая переменная. С помощью специальных значений независимой переменной (эти значения называются кодами) данные разбиваются на две группы.
Анализ данных с помощью t-критерия, сравнения средних и меры отклонения от среднего в группах можно производить с помощью диаграмм размаха (рис. 3). Эти графики позволяют визуально оценить степень зависимости между группирующей и зависимой переменными.
На практике часто приходится сравнивать более двух групп данных или сравнивать группы, созданные более чем одной независимой переменной. В таких более сложных исследованиях следует использовать дисперсионный анализ, который можно рассматривать как обобщение t-критерия.
Степень различия между средними в двух группах зависит от внутригрупповой вариации (дисперсии) переменных. В зависимости от того, насколько различны эти значения для каждой группы, "грубая разность" между групповыми средними показывает более сильную или более слабую степень зависимости между независимой (группирующей) и зависимой переменными.
Теоретические предположения t-критерия для независимых выборок относятся также к критерию для зависимых выборок. Это означает, что попарные разности должны быть нормально распределены. Если это не выполняется, то можно воспользоваться одним из альтернативных непараметрических критериев. Если имеется более двух "зависимых выборок", то можно использовать дисперсионный анализ с повторными измерениями.
Группировка часто используется как средство разведочного анализа данных. При нахождении различий средних подходящим тестом является однофакторный дисперсионный анализ (F-критерий). Если интерес представляет различие дисперсий, то можно воспользоваться критерием однородности дисперсий.
Обычно после получения статистически значимого результата в дисперсионном анализе желательно знать, какие средние вызвали наблюдаемый эффект (например, какие группы особенно сильно отличаются друг от друга). Процедуры апостериорного сравнения специально рассчитаны так, чтобы учитывать более двух выборок.
Дискриминантный анализ исследует различия между группами, построенными с помощью значений (кодов) независимой (группирующей) переменной. В дискриминантном анализе, как правило, одновременно рассматривается более одной независимой переменной и определяются "типы" (классы) значений этих переменных. С помощью дискриминантного анализа находят такие линейные комбинации зависимых переменных, которые наилучшим образом определяют принадлежность наблюдения к определенному классу, причем число классов известно заранее.
Другой вид анализа, который не может быть непосредственно проведен с помощью группировки – это сравнения частот (n) в различных группах. Часто значения n в различных ячейках не равны между собой, потому что отнесение субъекта к определенной группе является следствием некоторых субъективных установок экспериментатора, а не результатом случайного выбора. Однако если случайный выбор имеет место, то неравенство частот n в различных группах заставляет предположить, что независимые переменные на самом деле связаны между собой.
Графики часто позволяют обнаружить эффекты (как предполагаемые, так и неожиданные) быстрее, а иногда "лучше", чем численные методы. Категоризованные графики дают возможность строить графики средних, распределений, корреляций и т.д. "на пересечении" групп в соответствующих таблицах (например, категоризованные гистограммы, категоризованные вероятностные графики, категоризованные диаграммы размаха – см. рис. 1.4).
|
|
Рисунок 1.4 – Пример диаграммы размаха |
|
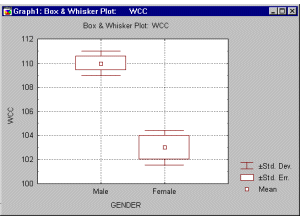
Простейшим методом анализа категориальных (номинальных) переменных являются таблицы частот или одновходовые таблицы. Часто их используют как одну из процедур разведочного анализа, чтобы просмотреть, каким образом различные группы данных распределены в выборке.
Кросстабуляция - это процесс объединения двух (или нескольких) таблиц частот так, что каждая ячейка (клетка) в построенной таблице представляется единственной комбинацией значений или уровней табулированных переменных. Таким образом, кросстабуляция позволяет совместить частоты появления наблюдений на разных уровнях рассматриваемых факторов. Исследуя эти частоты, можно определить связи между табулированными переменными. Обычно табулируются категориальные (номинальные) переменные или переменные с относительно небольшим числом значений. Если нужно табулировать непрерывную переменную, то вначале ее следует перекодировать, разбив диапазон изменения на небольшое число интервалов.
Простейшая форма кросстабуляции - это таблица сопряженности 2 x 2, в которой значения двух переменных "пересечены" (сопряжены) на разных уровнях и каждая переменная принимает только два значения, т.е. имеет два уровня.
Значения, расположенные по краям таблицы сопряженности - это обычные таблицы частот (с одним входом) для рассматриваемых переменных. Так как эти частоты располагаются на краях таблицы, то они называются маргинальными. Маргинальные значения важны, т.к. позволяют оценить распределение частот в отдельных столбцах и строках таблицы. Различие в распределении частот в строках (или столбцах) отдельных переменных и в соответствующих маргинальных частотах дают информацию о связи переменных.
Наиболее простой критерий проверки значимости связи между двумя категоризованными переменными - это хи-квадрат Пирсона. Критерий Пирсона основывается на том, что в двувходовой таблице ожидаемые частоты при гипотезе "между переменными нет зависимости" можно вычислить непосредственно. Имеется только одно существенное ограничение использования критерия хи-квадрат, которое состоит в том, что ожидаемые частоты не должны быть очень малы.
Максимум правдоподобия хи-квадрат предназначен для проверки той же самой гипотезы относительно связей в таблицах сопряженности, что и критерий хи-квадрат Пирсона. Однако его вычисление основано на методе максимального правдоподобия.
Точный критерий Фишера применим только для таблиц 2x2. Критерий Фишера вычисляет точную вероятность появления наблюдаемых частот при нулевой гипотезе (отсутствие связи между табулированными переменными). Критерий Хи-квадрат Макнемара применяется, когда частоты в таблице 2x2 представляют зависимые выборки.
Коэффициент сопряженности представляет собой основанную на статистике хи-квадрат меру связи признаков в таблице сопряженности (предложенную Пирсоном). Преимущество этого коэффициента перед обычной статистикой хи-квадрат в том, что он легче интерпретируется, т.к. диапазон его изменения находится в интервале от 0 до 1 (где 0соответствует случаю независимости признаков в таблице, а увеличение коэффициента показывает увеличение степени связи). Недостаток коэффициента сопряженности в том, что его максимальное значение "зависит" от размера таблицы. Этот коэффициент может достигать значения 1 только, если число классов не ограничено.
Для переменных, измеренных в порядковой шкале, имеются свои типы корреляции, позволяющие оценить зависимости. Статистику R Спирмена можно интерпретировать так же, как и корреляцию Пирсона (r-Пирсона) в терминах объясненной доли дисперсии (имея, однако, в виду, что статистика Спирмена вычислена по рангам). Статистика тау Кендалла эквивалентна статистике R Спирмена при выполнении некоторых основных предположений. Также эквивалентны их мощности. Однако обычно значения статистик R Спирмена и тау Кендалла различны, потому что они отличаются как своей внутренней логикой, так и способом вычисления.
Если в данных имеется много совпадающих значений, статистика γ предпочтительнее R Спирмена или тау Кендалла. Статистика γ представляет собой разность между вероятностью того, что ранговый порядок двух переменных совпадает, минус вероятность того, что он не совпадает, деленную на единицу минус вероятность совпадений. Коэффициенты неопределенности измеряют информационную связь между факторами (строками и столбцами таблицы).