

1.К числу основных устройств персонального компьютера, располагающихся в его системном блоке, относят материнскую плату, процессор, видеоадаптер (видеокарту), звуковую карту, средства обработки видеосигнала, оперативную память, TV-тюнер. В системном блоке располагаются также приводы и дисководы для накопителей информации различных типов: на гибких и жестких дисках, компакт-дисках типа CD-ROM, CD-R, CD-RW, DVD.
Устройства отображения информации служат для обработки видеоинформации и ее представления для визуального восприятия.
Звуковая и акустическая системы компьютера обеспечивают обработку и воспроизведение аудиоинформации.
Устройства ввода информации представляют собой совокупность устройств управления и ввода данных. Эти функции выполняют клавиатура, мышь, джойстик.
Печатающие устройства (принтеры) служат для вывода на твердые, как правило, бумажные носители текстовой информации.
Средства телекоммуникаций предназначены для дистанционной передачи информации. К ним относятся пейджеры, радиотелефоны, персональные терминалы для спутниковой связи, обеспечивающие передачу звуковой и текстовой информации.
Широко распространенными средствами работы с информацией на твердых носителях являются многочисленные устройства копировальной техники: электрографические, термографические, диазографические, фотографические, электронно-графические. Для уничтожения конфиденциальной информации на твердых носителях используются специальные устройства — шреддеры.
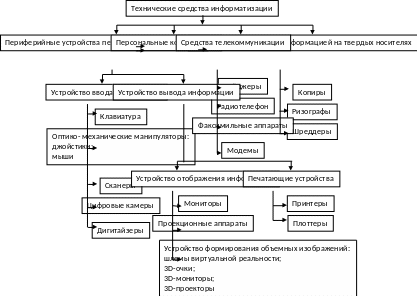
2. Внешние устройства предназначены для обеспечения нормального функционирования ЭВС и для коммуникации центральных устройств с внешними источниками и потребителями информации.
К внешним относятся вспомогательные устройства, такие как устройства электропитания и аппаратура интерфейса питания, стабилизаторы напряжения, устройства защиты от перегрузок, устройства кондиционирования и вентиляции, счетчики времени и электронные часы, а также сервисная аппаратура для автономной проверки работоспособности плат и блоков.
Основное назначение периферийных (внешних) устройств ЭВС — организация входных и выходных потоков управляющей информации, данных для обработки и результатов вычислений. Таким образом, периферийное устройство (ПУ) — это любое отличное от центрального процессора оборудование, обеспечивающее коммуникацию вычислительной системы с внешними источниками и потребителями информации. Для этого ПУ обеспечивают согласование информационных и физических характеристик внешних объектов и сигналов, используемых в ЭВС.
По назначению ПУ могут быть разбиты на три группы: регистрирующие, оперативные и автоматические.
3Регистрирующие УВыв — устройства, использующие промежуточные носители (например, магнитоносители) для длительного хранения информации в виде, пригодном для последующего использования в ЭВС или в виде, удобном для использования человеком (графики, таблицы, печатный текст, чертежи).
Оперативные УВв — устройства непосредственного, оперативного взаимодействия оператора с ЭВМ, предназначенные для организации диалога между ЭВМ и человеком в процессе отладки программ и решения задач. Это оперативные УВв (клавиатура, световое перо, дигитайзеры, микрофон) и средства отображения, (СО) результатов — цифровые индикаторы, экраны, звуковые сигнализаторы.
Автоматические УВв — устройства связи с объектом, предназначенные для ввода в ЭВС данных непосредственно с объектов ; автоматизации и выдачи управляющих воздействий на объекты. Это аналого-цифровые преобразователи (АЦП) и цифроаналоговые преобразователи (ЦАП). Сюда же можно отнести и читающие автоматы — сканеры.
Модемы — устройства, модулирующие и демодулирующие сигналы, передаваемые с помощью средств связи в случае использования каналов связи для коммутации ЭВС в вычислительных сетях, занимают промежуточное значение между низкоскоростными и среднескоростными УВв.
Внешние устройства предназначены для обеспечения нормального функционирования ЭВС и для коммуникации центральных устройств с внешними источниками и потребителями информации.
К внешним относятся вспомогательные устройства, такие как устройства электропитания и аппаратура интерфейса питания, стабилизаторы напряжения, устройства защиты от перегрузок, устройства кондиционирования и вентиляции, счетчики времени и электронные часы, а также сервисная аппаратура для автономной проверки работоспособности плат и блоков.
Основное назначение периферийных (внешних) устройств ЭВС — организация входных и выходных потоков управляющей информации, данных для обработки и результатов вычислений. Таким образом, периферийное устройство (ПУ) — это любое отличное от центрального процессора оборудование, обеспечивающее коммуникацию вычислительной системы с внешними источниками и потребителями информации. Для этого ПУ обеспечивают согласование информационных и физических характеристик внешних объектов и сигналов, используемых в ЭВС.
По назначению ПУ могут быть разбиты на три группы: регистрирующие, оперативные и автоматические.
4.Регистрирующие УВыв — устройства, использующие промежуточные носители (например, магнитоносители) для длительного хранения информации в виде, пригодном для последующего использования в ЭВС или в виде, удобном для использования человеком (графики, таблицы, печатный текст, чертежи).
Оперативные УВв — устройства непосредственного, оперативного взаимодействия оператора с ЭВМ, предназначенные для организации диалога между ЭВМ и человеком в процессе отладки программ и решения задач. Это оперативные УВв (клавиатура, световое перо, дигитайзеры, микрофон) и средства отображения, (СО) результатов — цифровые индикаторы, экраны, звуковые сигнализаторы.
Автоматические УВв — устройства связи с объектом, предназначенные для ввода в ЭВС данных непосредственно с объектов ; автоматизации и выдачи управляющих воздействий на объекты. Это аналого-цифровые преобразователи (АЦП) и цифроаналоговые преобразователи (ЦАП). Сюда же можно отнести и читающие автоматы — сканеры.
Модемы — устройства, модулирующие и демодулирующие сигналы, передаваемые с помощью средств связи в случае использования каналов связи для коммутации ЭВС в вычислительных сетях, занимают промежуточное значение между низкоскоростными и среднескоростными УВв.
5.Шины в ПК различаются по своему функциональному назначению:
системная шина (или шина CPU) используется микросхемами Cipset для пересылки информации к CPU и обратно;
шина кэш-памяти предназначена для обмена информацией между CPU и кэш-памятью;
шина памяти используется для обмена информацией между оперативной памятью RAM и CPU;
шины ввода/вывода информации подразделяются на стандартные и локальные.
Разрядность шины определяется числом параллельных проводников, входящих в нее.
Пропускная способность шины определяется количеством байт информации, передаваемых по шине за секунду. Для определения пропускной способности шины необходимо умножить тактовую частоту шины на ее разрядность.
Внешние устройства к шинам подключаются посредством интерфейса (Interface — сопряжение), представляющего собой совокупность различных характеристик какого-либо периферийного устройства ПК, определяющих организацию обмена информацией между ним и центральным процессором Шина EISA стала дальнейшим развитием шины ISA в направлении повышения производительности системы и совместимости ее компонентов. Шина не получила широкого распространения в связи с ее высокой стоимостью и пропускной способностью, уступающей пропускной способности появившейся на рынке шины VESA.
Шина VESA, или VLB, предназначена для связи CPU с быстрыми периферийными устройствами и представляет собой расширение шины ISA для обмена видеоданными. Во времена преобладания на компьютерном рынке процессора CPU 80486 шина VLB была достаточно популярна, однако в настоящее время ее вытеснила более производительная шина PCI.
Шина PCI была разработана фирмой Intel для процессора Pentium и представляет собой совершенно новую шину. Основополагающим принципом, положенным в основу шины PCI, является применение так называемых мостов (Bridges), которые осуществляют связь между шиной PCI и другими типами шин.
Шина AGP — высокоскоростная локальная шина ввода/вывода, предназначенная исключительно для нужд видеосистемы. Она связывает видеоадаптер (ЗD-акселератор) с системной памятью
Шина SCSI (Small Computer System Interface) обеспечивает скорость передачи данных до 320 Мбайт/с и предусматривает подключение к одному адаптеру до восьми устройств: винчестеры, приводы CD-ROM, сканеры, фото- и видеокамеры. Отличительной особенностью шины SCSI является то, что она представляет собой кабельный шлейф. С шинами PC (ISA или PCI) шина SCSI связана через хост-адаптер (Host Adapter). Каждое устройство, подключенное к шине, имеет свой идентификационный номер (ID). Любое устройство, подключенное к шине SCSI, может инициировать обмен с другим устройством.
Шина IEEE 1394 — это стандарт высокоскоростной локальной последовательной шины, разработанный фирмами Apple и Texas Instruments. Шина IEEE 1394 предназначена для обмена цифровой информацией между ПК и другими электронными устройствами, особенно для подключения жестких дисков и устройств обработки аудио- и видеоинформации, а также работы мультимедийных приложений. Она способна передавать данные со скоростью до 1600 Мбит/с, работать одновременно с несколькими устройствами, передающими данные с разными скоростями, как и SCSI. Как и USB, шина IEEE 1394 полностью поддерживает технологию Plug & Play, включая возможность установки компонентов без отключения питания ПК.
-
5
Классификация интерфейсов. Архитектура шины и ее основные характеристики
Задача объединения в один комплекс различных блоков ЭВМ, устройств хранения и отображения информации, периферийной аппаратуры, решается с помощью унифицированных систем сопряжения – интерфейсов. Под интерфейсом понимают совокупность схемо-технических средств,обеспечивающих непосредственное взаимодействие составных элементов вычислительной системы. Основным назначением интерфейса является унификация внутрисистемных и межсистемных связей и устройств.
Классификация интерфейсов:
1) Машинные интерфейсы предназначены для организации связей между составными элементами ЭВМ, т.е. непосредственно для их построения и связи с внешней средой.
2) Интерфейсы периферийного оборудования выполняют функции сопряжения процессоров,контроллеров,запоминающих устройств и аппаратурой передачи данных.
3) Интерфейсы мультипроцессорных систем представляют собой в основном магистральные системы сопряжения, ориентированные в единый комплекс нескольких процессоров,модулей памяти, контроллеров запоминающих устройств, ограничено размещенных в пространстве.
Характеристики шин ПК
Системные интерфейсы материнской платы (система шин), которые имеют разъемы (слоты) для подключения адаптеров периферийных устройств (интерфейсных карт), получили название шин расширения. Шины расширения ПК начали свою историю с 8-битной шины ISA. Ее открытость обеспечила появление широкого спектра плат расширений, позволяющих использовать ПК в различных сферах.
Шины расширения системного уровня дают возможность устанавливаемым на них модулям максимально использовать такие системные ресурсы как пространства памяти и ввода/вывода, прерывания, каналы прямого доступа к памяти. За получение этих возможностей разработчикам и изготовителям модулей расширения приходится расплачиваться необходимостью обеспечения точного соответствия протоколам шины, включая и довольно жесткие частотные и нагрузочные параметры, а также временные диаграммы. Отклонения от этих требований могут приводить к проблемам совместимости с разными системными платами. Если при подключении к внешним интерфейсам эти проблемы приведут к неработоспособности только этого устройства, то некорректное подключение к системной шине может блокировать работу всего компьютера. Рассмотрим основные характеристики шин расширения системного уровня.
ISA-8 и ISA-16(IndustryStandardArchitecture) - является самой распространенной и самой простой шиной, основы которой были заложены в ПК ЮМ PC/XT(ISA-8) и после ее усовершенствования (ISA-16) она широко используется в ШМ PC/AT практически для всех современных микропроцессоров. ISA-8 имеет разрядность 8 бит данных и 20 бит адреса (максимальное адресное пространство -1 Мбайт). В ISA-16 шину расширили до 16 бит данных и 24 бит адреса. В таком виде она существует и поныне как самая распространенная шина для периферийных адаптеров. Шина обеспечивает своим абонентам возможность отображения 8- или 16-битных регистров на пространство ввода/вывода и памяти. Предельная скорость передачи данных достигает 16 Мбайт/с.
Диапазон адресов ввода/вывода сверху ограничен количеством используемых для дешифрации бит адреса, при этом традиционно используется 10-битная адресация пространства ввода/вывода, а в настоящее время в интеллектуальных устройствах стали применять и 12-битную адресацию, но при ее использовании всегда необходимо учитывать возможность присутствия на шине и старых 10-битных адаптеров, которые "отзовутся" на адрес с подходящими ему битами А(9 - 0) во всей допустимой области 12-битного адреса четыре раза. В распоряжении абонентов ISA-8 может быть до 6 линий запросов прерываний IRQ(для ISA-16 их число достигает 11) и до трех 8-битных каналов DMA(для ISA-16 быть доступными еще три 16-битных канала). Все перечисленные ресурсы системной шины должны быть бесконфликтно распределены между абонентами. Задача распределения ресурсов в старых адаптерах решалась с помощью джамперов, затем появились программно конфигурируемые устройства, которые вытесняются автоматически конфигурируемыми платами РпР. С появлением 32-битных процессоров делались попытки расширения разрядности шины, но все 32-битные шины ISAне являются стандартизованными, кроме шины EISA.
Конструктивно слот шины ISAвыполнена в виде двух щелевых разъемов с шагом выводов 2,54 мм (0,1 дюйма). Подмножество 1SA-8 использует только 62-контактный слот (ряды А, В), в ISA-16 применяется дополнительный 36-контактный слот (ряды С, D).
EISA(ExtendedISA)- расширенная шина ISA, реализует 32-разрядную архитектуру (32-разрядные шины адреса и данных) и является более производительной, применяется для подключения высокоскоростных адаптеров, обеспечивающих эффективную работу с файлами или для надлежащей работы серверов.
Шина EISAимеет:
- развитую систему прерываний, кроме прерывания по фронту сигнала предусмотрена система прерывания по уровню сигнала с возможностью программного выбора схемы прерывания;
развитую систему работы каналов ДМ А, допускающую циклы обмена за 8, 6, 4 и 1 тактов. Циклы поддерживают работу с 8-/16-/32- разрядными устройствами;
автоматическую конфигурацию системы и плат расширения с разделением ресурсов компьютера между отдельными платами;
средства реализации мультипроцессорной архитектуры;
развитую систему арбитража, используется системный арбитр, участвующий в реализации центрального управления;
выделенный адресный диапазон до 4 Кбайт для каждого разъема для устранения конфликтов между слотами. Адресное пространство шины до 4<3байт. Предельная скорость передачи данных в пакетном режиме 33 Мбайта/с.
EISA- дорогая, но оправдывающая себя архитектура, применяющаяся в многозадачных системах, на файл-серверах и везде, где требуетря высокоэффективное расширение шины ввода/вывода. Перед шиной PCIу нее есть некоторое преимущество в количестве слотов, которое для одной шины PCIне превышает четырех, а у EISAможет достигать восьми.
Конструктивное исполнение обеспечивает совместимость с ней и обычных ISA-адаптеров (Рис. 2.5). Узкие дополнительные контакты расширения (ряды Е, F, G, Н) расположены между ламелями разъема ISAи ниже ламелей А, В, С, Dтаким образом, что адаптер ISA, не имеющий дополнительных ключевых прорезей в краевом разъеме, не достает до них. Установка карт EISAв слоты ISAнедопустима, поскольку ее специфические цепи попадут на контакты цепей ISA, в результате чего системная плата окажется неработоспособной.
MCA(MicroChannelArchitecture) - микроканальная архитектура была разработана фирмой IBMдля своих компьютеров PS/2, начиная с модели 50. Шина МСА абсолютно несовместима с ISA/EISA. Шина более быстродействующая чем шина ISA. Для микропроцессоров, которые применяют 32-/64- разрядные шины данных может использоваться 32- разрядная шина МСА, которая в 2,5 раза более производительная, чем используемые шины ISAв ШМ PC/AT. Архитектура МСА приспособлена для выполнения пакетной процедуры обмена. Реализация пакетного режима обмена обеспечивает предельную скорость 40 Мбайт/сек, в то время как обычный (4-байтный) обмен по шине МСА обеспечивает скорость 20 Мбайт/сек. МСА обладает более совершенной защитой, уменьшающей конфликтные ситуации при одновременном обращении к шине устройств, подобных DMA.
В отличие от других шин МСА допускает обработку последовательности прерываний сигналов, распределяя их среди нескольких выделенных карт (featurecards), которые могут работать одновременно без взаимодействия друг с другом. Арбитражный механизм, называемый управляющим шины (busmaster), обеспечивает полный контроль работы шины без участия процессора, при этом ускоряет обмен информации с памятью, что важно для работы DMA.
МСА поддерживает архитектуру блока управления системы (SCB- systemcontrolbloc), при которой для микропроцессора создаются небольшие программы (называемые SCB), содержащие специальные программируемые инструкции и данные. Микропроцессор может заказать управляющему шиной (busmaster) выполнить работу, определенную SCBи вернуть ему результат. При этом процессор может установить более подходящий момент для выполнения своей задачи. Этот подход используется для реализации мультипроцессорной архитектуры больших компьютеров.
При всей прогрессивности архитектуры (относительно ISA) шина МСА не пользуется популярностью из-за узости круга производителей МСА- устройств и полной их несовместимости с массовыми ISA-системами. Однако МСА еще находит применение в мощных файл-серверах, где требуется обеспечение высоконадежного производительного ввода/вывода.
PCMCIA(PersonalComputer, CardInternationalAssociation) - шина расширения, используемая для портативных компьютеров, так как по габаритным и другим причинам шины ISA, EISAи МСА здесь не приемлемы. Технически PCMCIAэто не шина в рассмотренном выше смысле, а более похожа на параллельный или последовательный порт. Наиболее важные характеристики шины- малые размеры, вес, низкое потребление энергии адаптерными картами.
Шина PCMCIAимеет такие же слоты как и компьютеры семейств PS/2 и ШМ/РС и имеет дополнительно адаптеры для связи с ISAи МСА. Стандарты PCMCIAпредусматривают реализацию совместимости с различными аппаратными и операционными системами. В настоящее время стандарт PCMCIAдопускает использование карт памяти, ввода-вывода для модемов, сетевых коммуникаций, жестких дисков, радиосвязи, различных адаптеров эмуляции. Количество и функциональное разнообразие этих карт непрерывно растет.
VLB(VideoEquipmentStandardAssociation/VESA/ LocalBus) - локальная шина для подключения высокопроизводительных подсистем, таких как видеографические подсистемы, подсистемы сетевых коммуникаций и др., к локальной шине микропроцессора. Эта шина используется одновременно с шиной ISAкак основной для остальной периферии. Стандарт VLBориентирован на 486 процессор и ограничивается добавлением к локальной шине микропроцессора нескольких контрольных сигналов. Однако непосредственный выход на процессор высокоскоростных устройств из-за возможных системных нарушений ограничивает количество подключаемых устройств к такой шине. К VLBможно подключать до 3-х контроллеров высокоскоростных периферийных устройств. Конструктивно VLBэто короткий соединитель типа МСА (112 контактов), который имеет 32 линии для передачи данных и 30 линий адреса.
Для МП Pentiumразработан новый стандарт VLB, который предусматривает использование 64-разрядной шины данных и допускает до пяти разъемов расширения. Максимальная скорость обмена составляет 132 Мбайт/с в пакетном режиме.
PCI(PeripheralComponentInterconnect) localbus- шина соединения периферийных компонентов. Называясь локальной, эта шина занимает особое место в современной PC-архитектуре, являясь мостом между системной шиной процессора и шиной ввода/вывода ISA/EISAили МСА. Эта шина разрабатывалась в расчете на Pentium-системы, имеет 32-разрядную шину адреса и 32 (в спецификации PCI2.1 64) - разрядную шину данных. При частоте шины 33(66 в версии 2.1) МГц теоретическая максимальная скорость достигает 132/264 Мбайт/с для 32/64 бит в пакетном режиме.
PCIимеет мультиплексированную шину адреса/данных ADи некоторые линии управления используются для различных целей, что позволило уменьшить число этих линий и упростить шину.
Протокол квитирования обеспечивает надежность обмена - инициатор всегда получает информацию об отработке пакета целевым устройством. Средством повышения надежности (достоверности) является применение контроля паритета: линии AD(31 - 0) и С/ВЕ#(3 - 0) и в фазе адреса, и в фазе данных защищены битом паритета PAR.
Арбитражем запросов на использование шины занимается специальный функциональный узел, входящий в состав чипсета системной платы. Каждое устройство-инициатор имеет пару сигналов - REQ# для запроса на управление шиной и GNT# - подтверждение предоставления управления шиной. Схема приоритетов (фиксированный, циклический, комбинированный) определяется программированием арбитра.
Адресация памяти, портов и конфигурационных регистров различна. Байты шины AD, несущие действительную информацию, выбираются сигналами С/ВЕ(3 - 0) в фазах данных (внутри пакета эти сигналы могут менять состояние). В циклах обращения к памяти адрес, выровненный по границе двойного слова, передается по линиям AD(31 - 2), линии AD(1 - 0) задают порядок чередования адресов в пакете (00 - линейное инкрементирование, 01 - чередование адресов с учетом длины строки кэшпамяти, 1х - зарезервировано).
В циклах обращения к портам ввода/вывода для адресации любого байта используются все линии AD(31 - 0). В циклах конфигурационной записи/считывания устройство выбирается индивидуальным сигналом EDSEL#, конфигурационные регистры выбираются двойными словами, используя линии AD(7 - 2), при этом AD(1 - 0)=00.
Команды шины PCI(типы циклов) определяются значениями бит С/ВЕ# в фазе адреса следующие:.
-подтверждение прерывания (PICконтроллер передает вектор прерывания по шине AD);
специальный цикл декодируется содержимым линий AD(15 - 0) и используется для указания на отключение (Shutdown), останов (Halt) процессора или специфические функции процессора, связанные с кэшем и трассировкой;
чтение и запись ввода/вывода. Порты PCIмогут быть 8- или 16- битными. Для адресации портов на шине РС1 доступны все 32 бита адреса, но процессоры х86 могут использовать только младшие 16 бит. Кроме того, на адресное пространство PCIвлияет и 10-битное декодирование адреса, принятое в традиционной шине ISA, в результате чего каждый адрес порта на шине ISAимеет 64 псевдонима, смещенных друг от друга на 1 К. Порты с адресами 0CF8hи OCFChзарезервированы под регистры адреса и данных для доступа к конфигурационному пространству. Обращение к порту данных приведет к генерации шинного цикла конфигурационного чтения или записи по предварительно записанному адресу;
чтение и запись памяти. Шина ADсодержит адреса двойных слов, и линии ADO, AD1 не должны декодироваться;
конфигурационное чтения и запись. Эти команды адресуются к конфигурационному пространству (не отражается ни на пространство памяти ни на пространство ввода/вывода) и обеспечивают доступ к 256-байтным структурам. Обращение идет двойными словами. Структура содержит идентификатор устройства и производителя, состояние и команду, информацию об используемых ресурсах и ограничения на использование шины;
множественное чтение памяти используется для чтения больших блоков памяти без кэширования.
двухадресный цикл применяется, когда физическая шина имеет всего 32 бита адреса, а требуется передача с 64-битной адресацией. В этом случае младшие 32 бита адреса передаются в цикле данного типа, а за ним следует обычный цикл, определяющий тип обмена и несущий старшие 32 бита адреса;
чтение строки памяти используется для чтения более чем двух 32- битных блоков данных (обычно чтение до конца строки кэша). В таком случае этот цикл обеспечивает обмен, более эффективный, чем цепочка обычных пакетных чтений.
запись с инвалидацией применяется при передачи как минимум одной строки кэша и позволяет обновлять содержимое основной памяти, экономя циклы обратной записи.
Слоты PCIс шагом 0,05 дюйма имеют для 32-разрядных данных 124 контакта (А1-А62, В1-В62) и 188 контактов (А1-А94, В1-В94) для 64- разрядные данных.
На одной шине РС1 может быть не более четырех устройств (следовательно, и слотов). Для подключения шины PCIк другим шинам применяются специальные аппаратные средства -мосты мины PCI(PCIBridge).Главный мост(HostBridge) используется для подключения PCIк системной шине (шине процессора или процессоров).Одноранговый мост (Peer-to-PeerBridge) используется для соединения двух шин PCI. Две и более шины PCIприменяются в мощных серверных платформах ~ дополнительные шины PCIпозволяют увеличить количество подключаемых устройств. Для подключения шин ISA/EISAиспользуются специальные мосты, входящие в чипсеты большинства системных плат. Каждый мост программируется - ему указываются диапазоны адресов пространств памяти и ввода/вывода, отведенные абонентам его шин. Если адрес целевого устройства текущей транзакции на одной шине (стороне) моста относится к шине противоположной стороны, мост перенаправляет транзакцию на соответствующую шину и выполняет действия по согласованию протоколов этих шин. Таким образом, совокупность мостов, расположенных вокруг шины PCI, выполняет маршрутизацию (routing) обращений по всем связанным шинам.
Автоконфигурирование устройств (выбор адресов, запросов прерываний) поддерживается средствами BIOSи ориентировано на технологию PlugandPlay. Стандарт PCIопределяет для каждого слота конфигурационное пространство размером до 256 однобайтных регистров, не приписанных ни к пространству памяти, ни к пространству ввода/вывода. Доступ к ним осуществляется по специальным циклам шины ConfigurationReadи ConfigurationWrite, вырабатываемым контроллером при обращении процессора к регистрам контроллера шины PCI, расположенным в его пространстве ввода/вывода. После аппаратного сброса (или по включении питания) устройства PCIне отвечают на обращения к пространству памяти и ввода/вывода, они доступны только для операций конфигурационного считывания и записи. В этих операциях устройства выбираются по индивидуальным сигналам IDSEL#, устройства сообщают о потребностях в ресурсах и возможных диапазонах их перемещения. После распределения ресурсов, выполняемого программой конфигурирования (во время POST), в устройства записываются параметры конфигурирования, и только после этого к ним становится возможным доступ по командам обращения к памяти и портам ввода/вывода.
AGP(AcceleratedGraphicPort) - ускоренный графический порт, разработанный на базе шины PCI2.1. Этот порт представляет собой 32- разрядную шину с тактовой частотой 66 МГц (точнее, 66,66...), по составу сигналов напоминающую шину PCI. Место AGPв архитектуре компьютера иллюстрирует рис. 2.1. Чипсет связывает AGPс памятью и системной шиной процессора, не натыкаясь на ставшую уже «узким местом» шину PCI. Повышение быстродействия порта обеспечивается следующими тремя факторами:
Конвейеризация операций обращения к памяти. Спецификация AGPпредусматривает возможность постановки в очередь до 256 запросов, но при конфигурировании РпР уточняются реальные возможности конкретной системы. AGPподдерживает две пары очередей для операций записи и чтения памяти с высоким и низким приоритетом. В процесс передачи данных любого запроса может вмешаться следующий запрос, в том числе и запрос в режиме PCI.
Сдвоенная передача данных, которая обеспечивает при частоте тактирования шины в 66 МГц пропускную способность до 532 Мбайт/с (режим «х2»), за счет того, что 4-байтные блоки данных передаются как по фронту, так и по спаду сигнала синхронизации. Заказать режим х2 может только графическая карта, если, конечно, она его поддерживает.
Демультиплексирование (разделение) ший адреса и данных. Демультиплексирование подразумевает наличие двух полноразрядных шин адреса и данных. Однако реализация такого варианта была бы слишком дорогой. Поэтому в AGPшину адреса в демультиплексированном режиме представляют 8 линий SBA(SideBandAddress), по которым за три такта синхронизации передаются 6 байт (4 байта адреса, 1 байт - длина запроса и 1 байт - команда). За каждый такт передаются по два байта - один по фронту, другой по спаду тактового сигнала. Поддержка демультиплексированной адресации не является обязательной для карты с портом AGP, но хост- контроллер, естественно, должен ее поддерживать. Альтернативой такому способу подачи адреса является обычный - по мультиплексированной 32-х разрядной шине AD.
Порт AGPможет работать как в своем «естественном» режиме с конвейеризацией и сдвоенными передачами, так и в режиме шины PCI. В конвейеризированном режиме, в котором начало цикла отмечается сигналом РГРЕ#, возможны только обращения к памяти. В режиме PCIциклы начинаются с сигнала FRAME# и обращения возможны как к пространству памяти, так и пространству ввода/вывода и конфигурационному пространству. Слот AGPявляется достаточным для подключения дисплейного адаптера, так как кроме собственно AGP, в него заложены и сигналы шины USB, которую предполагается заводить в монитор. Внешне карты с портом AGPпохожи на PCI, но у них используется разъем повышенной плотности с «двухэтажным» (как у EISA) расположением ламелей, и сам разъем располагается несколько дальше от задней кромки платы, чем разъем PCI.
Кроме шин, реализованных щелевыми разъемами-слотами, имеется ряд шин, в которых устройства соединяются кабелями. К ним относятся следующие:
SCSI- интерфейсная шина системного уровня, предназначенная для подключения широкого спектра внутренних и внешних периферийных устройств, требующих высокой производительности обмена данными. Системная плата со встроенным SCSI-адаптером имеет разъем одного из типов, принятых для этого интерфейса, который со внутренними и внешними устройствами соединяется обычно ленточным кабелем-шлейфом.
USB- последовательная шина среднего быстродействия для подключения разнообразных внешних устройств, включая принтеры, сканеры, диски (разные), цифровые акустические системы и многие другие. Системная плата может иметь два порта USB, выведенных на 4-штырьковые разъемы. Внешние разъемы устанавливаются на задней или лицевой панели корпуса компьютера.
FireWire(он же IEEE1394) - высокопроизводительная последовательная шина подключения внешних устройств, предназначенная в основном для подключения видеоаппаратуры. С помощью этой же шины возможно и объединение нескольких компьютеров в локальную сеть. Системные платы с этой шиной пока еще редкость.
Кроме шин расширения, современные системные платы могут иметь и вспомогательные шины, используемые для тестирования и передачи конфигурационной информации. К ним относятся следующие:
JTAG- последовательный интерфейс тестирования, реализованный в большинстве процессоров старших поколений, а также входящий в спецификацию разъема шины PCI.
JC- последовательная шина, используемая для передачи конфигурационной информации новых модулей памяти DIMM, а также в цифровом канале связи с монитором (DDC).
На системных платах распространено сочетания слотов: ISA+PCI, ISA+VLB, EISA+PCI, EISA+VLB. Шина МСА обычно держится особняком. Слот «MediaBUS», дополняющий слот PCIсигналами шины ISA, применяется, пожалуй, только фирмой ASUSTek.
6 |
Аппаратные средства поддержки работы периферийных устройств. (Системная плата, чипсеты, карты расширения.) |
Материнская плата (англ. motherboard, MB, также используется название англ. mainboard — главная плата; сленг. мама, мать,материнка) — сложная многослойная печатная плата, на которой устанавливаются основные компоненты персонального компьютера либосервера начального уровня (центральный процессор, контроллер оперативной памяти и собственно ОЗУ, загрузочное ПЗУ, контроллеры базовых интерфейсов ввода-вывода). Именно материнская плата объединяет и координирует работу таких различных по своей сути и функциональности комплектующих, как процессор, оперативная память, платы расширения и всевозможные накопители...
Основные компоненты, устанавливаемые на материнской плате:
Основная статья: Центральный процессор
Центральный процессор (ЦПУ).
Основная статья: Чипсет
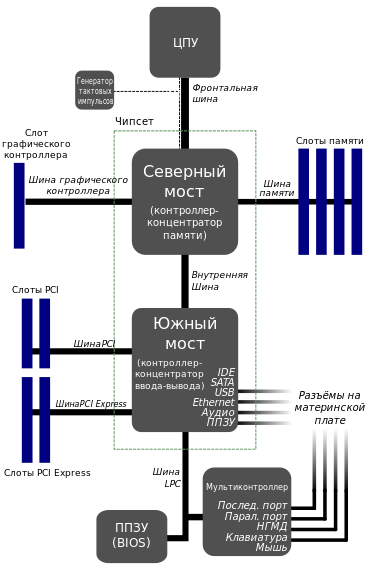
Набор системной логики (англ. chipset) — набор микросхем, обеспечивающих подключение ЦПУ к ОЗУ иконтроллерам периферийных устройств. Как правило, современные наборы системной логики строятся на базе двух СБИС: «северного» и «южного мостов».
Северный мост (англ. Northbridge), MCH (Memory controller hub), системный контроллер — обеспечивает подключение ЦПУ к узлам, использующим высокопроизводительные шины: ОЗУ, графический контроллер.
Для подключения ЦПУ к системному контроллеру могут использоваться такие FSB-шины, какHyperTransport и SCI.
Обычно к системному контроллеру подключается ОЗУ. В таком случае он содержит в себе контроллер памяти. Таким образом, от типа применённого системного контроллера обычно зависит максимальный объём ОЗУ, а также пропускная способность шины памяти персонального компьютера. Но в настоящее время имеется тенденция встраивания контроллера ОЗУ непосредственно в ЦПУ (например, контроллер памяти встроен в процессор в AMD K8 и Intel Core i7), что упрощает функции системного контроллера и снижает тепловыделение.
В качестве шины для подключения графического контроллера на современных материнских платах используется PCI Express. Ранее использовались общие шины (ISA, VLB, PCI) и шина AGP.
Южный мост (англ. Southbridge), ICH (I/O controller hub), периферийный контроллер — содержит контроллеры периферийных устройств (жёсткого диска, Ethernet, аудио), контроллеры шин для подключения периферийных устройств (шины PCI, PCI Express и USB), а также контроллеры шин, к которым подключаются устройства, не требующие высокой пропускной способности (LPC — используется для подключения загрузочного ПЗУ; также шина LPC используется для подключения мультиконтроллера (англ. Super I/O) — микросхемы, обеспечивающей поддержку «устаревших» низкопроизводительных интерфейсов передачи данных: последовательного и параллельного интерфейсов, контроллера клавиатуры и мыши).
Как правило, северный и южный мосты реализуются в виде отдельных СБИС, однако существуют и одночиповые решения. Именно набор системной логики определяет все ключевые особенности материнской платы и то, какие устройства могут подключаться к ней.
Чипсет (англ. chipset) — набор микросхем, спроектированных для совместной работы с целью выполнения набора каких-либо функций. Так, в компьютерах чипсет, размещаемый на материнской плате, выполняет роль связующего компонента, обеспечивающего совместное функционирование подсистем памяти, центрального процессора (ЦП), ввода-вывода и других. Чипсеты встречаются и в других устройствах, например, в сотовых телефонах.
Карта расширения (адаптер) в информатике — печатная плата, которую помещают в слот расширения материнской платы компьютерной системы с целью добавления дополнительных функций. Один край карты расширения оснащён контактами, точно соответствующими разъёму гнезда материнской платы. Контакты обеспечивают электрическое соединение между компонентами карты и материнской платы.
Плата расширения предназначена для расширения функций персонального компьютера. Может содержать оперативную память и устройства ввода-вывода. Могут обмениваться данными с другими устройствами на шине.
К платам расширения относятся:
видеокарта — устройство, преобразующее изображение, находящееся в памяти компьютера в видеосигнал для монитора. Современные видеокарты не ограничиваются простым выводом изображений. Они имеют графический микропроцессор, который может производить дополнительную обработку, разгружая ЦПУ.
звуковая карта — плата расширения, которая производит преобразование звука из аналоговой формы в цифровую. Главная возможность звуковой карты — воспроизведение аудио и видеофайлов, хранящихся на компьютере. Аудиоадаптер позволяет записывать звук, воспроизводить его; содержит в себе АЦП, ЦАП и цифровой сигнальный процессор, который производит вычисления. Профессиональные звуковые платы позволяют производить сложную обработку звука, имеют собственное ПЗУ.
Сетевая карта — плата расширения, позволяющая ПК взаимодействовать с другими устройствами сети (в настоящее время интегрированы на материнской плате). Сетевой адаптер вместе со своим драйвером выполняет две функции: прием и передача кадра. В клиентских ПК обычно, значительная часть работы перекладывается на драйвер, что позволяет удешевить адаптер, но загрузить ЦПУ. Адаптеры, предназначенные для серверов, обычно оснащены собственными процессорами, которые выполняют большую часть работы по передаче кадров из оперативной памяти в сеть и обратно. В общем виде цепочка передачи кадров: оперативная память — адаптер — физический канал — адаптер — оперативная память.
7 |
Программная поддержка работы периферийных устройств ПК (Функции BIOS. Прерывания. Прямой доступ к памяти. Драйверы. Спецификация Рn Р). |
BIOS (англ. basic input/output system — «базовая система ввода-вывода») — реализованная в виде микропрограмм часть системногопрограммного обеспечения, которая предназначается для предоставления операционной системе API для доступа к аппаратуре компьютера и подключенным к нему устройствам.
В персональных IBM PC-совместимых компьютерах, использующих микроархитектуру x86, BIOS представляет собой набор записанных вмикросхему EEPROM (ПЗУ) персонального компьютера микропрограмм (образующих системное программное обеспечение), обеспечивающих начальную загрузку компьютера и последующий запуск операционной системы.
При включении компьютера BIOS выполняет несколько операций. Вот их обычный порядок: 1. Проверка установок КМОП на предмет наличия пользовательских настроек 2. Загрузка обработчиков прерываний и драйверов устройств 3. Инициализация регистров и управления электропитанием 4. Выполнение самотестирования при включении питания (power-on self-test, POST). 5. Отображение на экране системных настроек 6. Определение загружаемых устройств 7. Инициализация программы самозагрузки
Прерывание (англ. interrupt) — сигнал, сообщающий процессору о наступлении какого-либо события. При этом выполнение текущей последовательности команд приостанавливается и управление передаётся обработчику прерывания, который реагирует на событие и обслуживает его, после чего возвращает управление в прерванный код.[1]
В зависимости от источника возникновения сигнала прерывания делятся на:
асинхронные или внешние (аппаратные) — события, которые исходят от внешних источников (например, периферийных устройств) и могут произойти в любой произвольный момент: сигнал от таймера, сетевой карты или дискового накопителя, нажатие клавиш клавиатуры, движение мыши. Факт возникновения в системе такого прерывания трактуется как запрос на прерывание (англ. Interrupt request, IRQ);
синхронные или внутренние — события в самом процессоре как результат нарушения каких-то условий при исполнении машинного кода: деление на ноль или переполнение, обращение к недопустимым адресам или недопустимый код операции;
программные (частный случай внутреннего прерывания) — инициируются исполнением специальной инструкции в коде программы. Программные прерывания как правило используются для обращения к функциям встроенного программного обеспечения (firmware), драйверов и операционной системы.
Прямой доступ к памяти (англ. Direct Memory Access, DMA) — режим обмена данными между устройствами или же между устройством и основной памятью (RAM) без участияЦентрального Процессора (ЦП). В результате скорость передачи увеличивается, так как данные не пересылаются в ЦП и обратно.
Дра́йвер (англ. driver, мн. ч. дра́йверы[1]) — компьютерная программа, с помощью которой другие программы (обычно операционная система) получают доступ к аппаратному обеспечению некоторого устройства. Обычно с операционными системами поставляются драйверы для ключевых компонентов аппаратного обеспечения, без которых система не сможет работать. Однако для некоторых устройств (таких, как видеокарта илипринтер) могут потребоваться специальные драйверы, обычно предоставляемые производителем устройства.
Plug and Play (сокр. PnP), дословно переводится как «включил и играй (работай)» — технология, предназначенная для быстрого определения и конфигурирования устройств вкомпьютере и других технических устройствах. Разработана фирмой Microsoft[источник не указан 576 дней] при содействии других компаний. Технология PnP основана на использовании объектно-ориентированной архитектуры, ее объектами являются внешние устройства и программы. Операционная система автоматически распознает объекты и вносит изменения в конфигурацию абонентской системы.
Основные знания о PnP:
PNP BIOS — расширения BIOS для работы с PnP устройствами.
Plug and Play Device ID — идентификатор PnP устройства имеет вид PNPXXXX, где XXXX — специальный код.
8 |
Интерфейсное подключение периферийных устройств ПК. |
9 |
Шина PCI (рабочие станции и серверные платформы). Назначение и технические характеристики. Конструкции разъемов. |
PCI (англ. Peripheral component interconnect, дословно — взаимосвязь периферийных компонентов) — шина ввода/вывода для подключения периферийных устройств к материнской плате компьютера.
Стандарт на шину PCI определяет:
физические параметры (например, разъёмы и разводку сигнальных линий);
электрические параметры (например, напряжения);
логическую модель (например, типы циклов шины, адресацию на шине).
В мае 1999 года появилась спецификация 2.2 стандарта PCI и в это же время фирма Intel выпустила первый chipset с поддержкой версии 2.2 - i810. Поддержка версии 2.2 также появилась в некоторых платах на наборе 440BX. В соответствии с новой спецификацией появились следующие новые возможности:
Поддержка "горячей" замены PCI устройств, называемой в стандарте как PCI Hot-Plug. Ввод этой функции позволит добавлять/изымать PCI платы без выключения компьютера. Такая возможность особенно необходима для серверных платформ
10 |
Порот AGP. Назначение и технические характеристики. Конструкция разъемов. Шина PСI-Express.Концепция последовательной шины. Уровни. |
AGP (от англ. Accelerated Graphics Port, ускоренный графический порт) — разработанная в 1996 году компанией Intel, специализированная 32-битная системная шина для видеокарты. Появилась одновременно с чипсетами для процессора IntelPentium MMX. Её отличия от предшественницы, шины PCI:
работа на тактовой частоте 66 МГц;
увеличенная пропускная способность;
режим работы с памятью DMA и DME;
разделение запросов на операцию и передачу данных;
возможность использования видеокарт с большим энергопотреблением, нежели PCI.
Доступ к памяти
DMA (англ. Direct Memory Access) — доступ к памяти, в этом режиме основной памятью считается встроенная видеопамять на карте,текстуры копируются туда перед использованием из системной памяти компьютера. Этот режим работы не был новым, по тому же принципу работают звуковые карты, некоторые контроллеры и т. п.
DME (англ. Direct in Memory Execute) — в этом режиме основная и видеопамять находятся как бы в общем адресном пространстве. Общее пространство эмулируется с помощью таблицы отображения адресов (англ. Graphic Address Remapping Table, GART) блоками по 4 Кб. Таким образом копировать данные из основной памяти в видеопамять уже не требуется, этот процесс называют AGP-текстурированием.
На данный момент материнские платы со слотами AGP практически не выпускаются; стандарт AGP был повсеместно вытеснен на рынке более быстрым и универсальным PCI Express. Последние массовые материнские платы с AGP производились примерно в 2004-2005 годы для процессора Pentium 4 Prescott и чипсетов поколения Intel 865.
Видеокарты стандарта AGP выпускаются в малом количестве и стоят дороже аналогичных PCI-E карт (из-за использования «микросхемы-переходника» PCI-E → AGP).
[править] PCI Express, или PCIe, или PCI-E (также известная как 3GIO for 3rd Generation I/O; не путать с PCI-X и PXI) — компьютерная шина, использующая программную модель шины PCI и высокопроизводительный физический протокол, основанный на последовательной передаче данных.
Развитием стандарта PCI Express занимается организация PCI Special Interest Group.
В отличие от шины PCI, использовавшей для передачи данных общую шину, PCI Express, в общем случае, является пакетной сетью с топологией типа звезда, устройства PCI Express взаимодействуют между собой через среду, образованную коммутаторами, при этом каждое устройство напрямую связано соединением типа точка-точка с коммутатором.
Кроме того, шиной PCI Express поддерживается:
горячая замена карт;
гарантированная полоса пропускания (QoS);
управление энергопотреблением;
контроль целостности передаваемых данных.
Разработка стандарта PCI Express была начата фирмой Intel после отказа от шины InfiniBand. Официально первая базовая спецификация PCI Express появилась в июле 2002 года.
Шина PCI Express нацелена на использование только в качестве локальной шины. Так как программная модель PCI Express во многом унаследована от PCI, то существующие системы и контроллеры могут быть доработаны для использования шины PCI Express заменой только физического уровня, без доработки программного обеспечения. Высокая пиковая производительность шины PCI Express позволяет использовать её вместо шин AGP и тем более PCI и PCI-X. Де-факто PCI Express заменила эти шины в персональных компьютерах.
10-11 вопросы Express.Концепция последовательной шины. Уровни
Шина PCI Express

Шина PCI Express разрабатывается корпорацией Intel совместно с многочисленными ведущими компаниями, такими как Dell, Hewlett-Packard, IBM и т.д. Она относится уже к третьему поколению архитектуры ввода-вывода и называется также 3GIO (Third Generation Input Output). Особенно важно, что новая архитектура PCI Express будет совместима на программном уровне с шиной PCI. Концептуальные идеи, заложенные в архитектуре PCI Express, таковы.
В современных компьютерах имеется достаточно большое количество самых разнообразных шин: шина памяти, процессорная шина, PCI-шина, шина связи северного и южного мостов чипсета, шина AGP. Все они являются параллельными, что накладывает определенные ограничения на увеличение их тактовой частоты. Кроме того, появление более высокоскоростных процессоров, типов памяти, графических адаптеров и периферийных устройств требует и увеличения полосы пропускания соответствующих шин, что создает определенные трудности при разработке чипсетов, так как каждый раз приходится перерабатывать интерфейс взаимодействия чипсета с соответствующим устройством. Конечно, хорошо было бы иметь некую универсальную шину, которая бы связывала устройства друг с другом внутри компьютера и в то же время имела достаточно большой запас по масштабируемости, то есть обеспечивала требуемую полосу пропускания.
Итак, масштабируемость и универсальность — вот две основные концепции, заложенные в архитектуре новой шины PCI Express.
Универсальность шины PCI Express должна заключаться в том, чтобы она заменила шину, связывающую северный мост чипсета с графическим адаптером, шину, объединяющую северный и южный мосты чипсета, а также PCI-шину.
Масштабируемость шины PCI Express состоит в том, что шина позволяет наращивать пропускную способность от 2,5 Гбит/с вплоть до 10 Гбайт/с (80 Гбит/с). Для сравнения отметим, что пропускная способность шины PCI-X c частотой 133 МГц составляет 1,06 Гбит/с.
О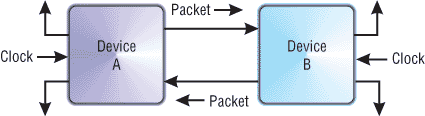 сновная
особенность новой шины PCI Express заключается
в том, что это не традиционная параллельная,
а последовательная (!) шина, работающая
по принципу «точка-точка» (peer-to-peer). На
физическом уровне шина образована двумя
парами проводников: одна пара служит
для передачи данных, а вторая — для их
приема. Две такие пары позволяют
организовать полосу пропускания 2,5
Гбит/с в одном направлении.
сновная
особенность новой шины PCI Express заключается
в том, что это не традиционная параллельная,
а последовательная (!) шина, работающая
по принципу «точка-точка» (peer-to-peer). На
физическом уровне шина образована двумя
парами проводников: одна пара служит
для передачи данных, а вторая — для их
приема. Две такие пары позволяют
организовать полосу пропускания 2,5
Гбит/с в одном направлении.
Для того чтобы обеспечить большую пропускную способность, поддерживается не одна, а несколько рассмотренных линий. Ширина одной линии с пропускной способностью 2,5 Гбит/с обозначается как x1; если используются две линии, то ширина линии будет х2. Первоначально на физическом уровне будет поддерживаться ширина линий х1, х2, х4, х8, х16 и х32. При этом при ширине линии х32 пропускная способность составит 80 Гбит/с или 10 Гбайт/с в одном направлении. Кроме того, 2,5 Гбит/с — это только начало. В дальнейшем скорость передачи по одной магистрали предполагается увеличить вплоть до 10 Гбит/с, что является теоретическим пределом для «медной пары».
Физический уровень шины PCI Express можно разделить на два подуровня: подуровень физического доступа к среде передачи данных (Physical Media Attachment Layer, PMA) и подуровень физического кодирования (Physical Coding Sublayer, PCS).
|
|
|
|
Физический уровень шины PCI Express |
|
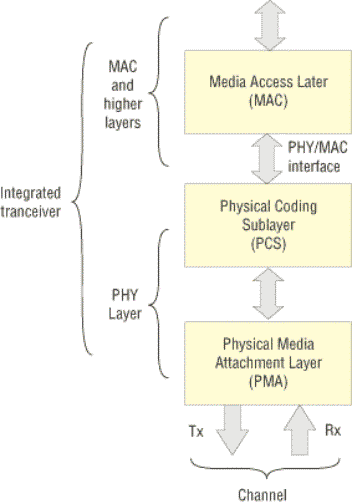
На физическом уровне линия PCI Express представляет собой две низковольтные дифференциальные пары проводов. Использование именно низковольтных дифференциальных сигналов (когда уровень сигнала в одном проводе измеряется относительно уровня сигнала в другом проводе) позволяет уменьшить влияние электромагнитных помех. Кроме того, с целью увеличения помехоустойчивости при передаче используется кодирование 8b/10b, которое производится на подуровне PCS.
Смысл такого кодирования достаточно прост — каждая последовательность 8 бит при передаче заменяется последовательностью 10 бит в соответствии со специальной таблицей замены. При этом в исходной последовательности 8 бит содержится 256 различных комбинаций нулей и единиц, а в результирующей — 1024. Данный подход позволяет избежать нежелательных последовательностей бит при передаче. Например, длинные последовательности логических нулей или единиц приводят к потере синхронизации. В результирующей последовательности можно отобрать комбинации (всего потребуется 256 комбинаций из 1024), в которых не встречаются длинные последовательности нулей и единиц — это приведет к улучшению самосинхронизирующих свойств кода. Кроме того, не все комбинации считаются разрешенными при передаче — обнаружение запрещенной последовательности при приеме трактуется как наличие ошибки. Таким образом, избыточное кодирование позволяет приемнику распознавать ошибки.
|
|
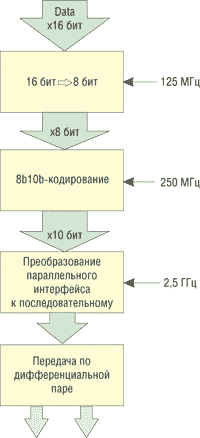
Подуровень физического кодирования связан по 16-битному интерфейсу с верхним уровнем доступа к среде передачи данных (Media Access Level, MAC). Поэтому первоначально полученные по параллельному 16-битному интерфейсу данные разбиваются на группы по 8 бит, то есть частично сериализуются. Частота параллельного 16-битного интерфейса составляет 125 МГц, а после преобразования к 8-битному параллельному интерфейсу частота шины становится уже 250 МГц. После этого данные подвергаются кодированию 8b/10b и уже по 10-битному параллельному интерфейсу поступают на подуровень PMA, где преобразуются к последовательному типу и передаются непосредственно по линии связи, но уже на частоте 2,5 ГГц. |
Преобразование данных на физическом уровне при передаче |
|
|
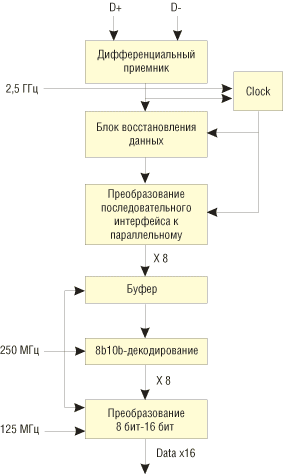
При приеме данные на физическом уровне претерпевают обратный порядок преобразования, то есть первоначально данные с частотой 2,5 ГГц поступают в дифференциальный приемник, после чего преобразуются к параллельному 10-битному интерфейсу. По этому интерфейсу данные, уже с частотой 250 МГц, подвергаются декодированию 10b/8b и по 8-битному интерфейсу поступают в блок преобразования к параллельному 16-битному типу. По 16-битной шине с частотой 125 МГц данные передаются на верхние уровни. |
|
|
|
|
Преобразование данных на физическом уровне при приеме |
Конечно, такое представление о преобразовании данных является весьма упрощенным. К примеру, мы не рассматривали промежуточные буферы и блоки контроля за возникновением ошибок. Впрочем, даже такой упрощенный подход позволяет понять принцип действия шины PCI Express.
|
|
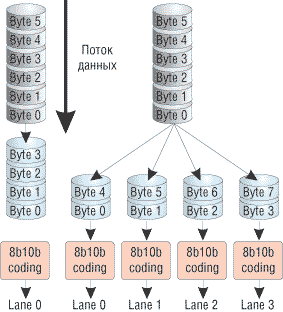
В случае когда используется не одна линия для передачи данных, то есть при организации многомагистральной шины PCI Express (шины с шириной линий х1, х2, х4, х8, х16 или х32), управлением потока данных занимается специальный агент PCI Express, который распределяет поток данных перед тем, как отправить его по различным физическим линиям, а при приеме аналогичный агент собирает разные потоки данных в один. |
Организация шины PCI Express при наличии нескольких магистральных линий передачи |
|
|
Мы рассмотрели только физический уровень архитектуры PCI Express. Конечно, полное описание архитектуры этим не ограничивается. Кроме физического уровня, есть также уровень представления данных (Data Link Layer), уровень транзакций (Transaction Layer) и программный уровень (Software layer).
|
|
|
|
Обработка данных на различных уровнях в архитектуре PCI Express |
|

Уровень представления данных отвечает за достоверность получаемых данных. На этом уровне каждому пакету присваивается свой порядковый номер и добавляется контрольная сумма CRC. При приеме данных на уровне представления контрольная сумма проверяется и, если пакет данных регистрируется как битый, формируется запрос на повторную передачу пакета.
Уровень транзакций получает запросы на запись или чтение от программного уровня и формирует пакеты запросов на передачу. Некоторые запросы требуют подтверждения, и уровень транзакций также получает ответные пакеты от уровня представления данных.
На уровне транзакций каждый пакет данных снабжается заголовком, в котором содержится уникальный идентификатор пакета, а также степень приоритета пакета.
Всего предусматривается три уровня приоритета: no-snoop, relaxedordering и priority.
Первый уровень приоритета (no-snoop) означает отсутствие всякого приоритета. Пакеты с такой меткой передаются в последнюю очередь.
Второй уровень приоритета (relaxedordering) — это уровень промежуточного приоритета, то есть пакеты с таким уровнем будут обрабатываться во вторую очередь.
Ну и последний уровень приоритета (priority) — это наивысший уровень приоритета. Пакеты с данным уровнем обрабатываются в первую очередь. Такое деление пакетов данных по уровням приоритета позволяет организовать сложные алгоритмы обработки, чтобы потоки данных, требовательные к пропускной способности (например, потоки данных мультимедийных приложений), обрабатывались в первую очередь.
12 Вопрос Интерфейс HyperTransport Принцип передачи информации по дифференциальной линии. Уровни. Характеристики.
Этот
стандарт продвигается на рынок
HyperTransport Technology Consortium, который в настоящий
момент насчитывает около 150 участников,
больших и малых фирм, занимающихся
разработкой программного и аппаратного
обеспечения. Консорциум был организован
в 1997 году с целью развития архитектуры
системной шины компьютера. Большое
число фирм объявили о своем участии в
проекте после того, как один из участников
консорциума, NVIDIA, заявил о поддержке
HyperTransport в своем чипcете nForce. Наиболее
яркие представители являются известными
сторонниками открытой архитектуры.
Кроме
выпуска первых десктопных 64 битных
процессоров, чем АМД конечно годится,(
причем гордится настолько, что решила
отказаться от магических циферок 64 в
названии процессора -мол если написано
Athlon, то и так ясно, что процессор 64 битный)
у компании есть еще один мощный предмет
для гордости.
Шина HyperTransport (HT),
ранее известная как Lightning Data Transport (LDT),
- это двунаправленная последовательно/параллельная
компьютерная шина, с высокой пропускной
способностью и малыми задержками.
Исторически
HyperTransport разрабатывался AMD в качестве
процессорной шины нового поколения
специально для чипов с интегрированным
контроллером памяти (архитектура AMD64).
В многопроцессорных системах на основе
AMD Opteron подсистема памяти “размазана”
по всем процессорам - у каждого есть
своя локальная память, подключенная
через интегрированный контроллер, и
каждый может обращаться к памяти любого
другого процессора. Локальная память
“быстрая”, а память соседа - “медленная”,
причем чем “дальше” расположен сосед,
тем медленнее память. Медлительность
является следствием того, что для
обращения к соседу требуется проделать
целый ряд операций - переслать по
межпроцессорной шине запрос, дождаться
его выполнения контроллером памяти
адресата, вернуть данные по шине обратно.
Очевидно, что чем быстрее при этом шина,
тем более “однородна” память.
Исходя
из этих соображений и проектировалась
новая шина, призванная обеспечить
пропускную способность не меньшую, чем
у оперативной памяти, и минимальные
задержки на передачу данных и сообщений.
Получилось действительно неплохо, что
даже дало AMD повод назвать свою архитектуру
не NUMA, а SUMA - Slightly Uniform Memory Architecture, то есть
“почти однородная” архитектура
памяти.(напомню NUMA -неоднородный доступ
к памяти).
Но разработчики не стали
делать типичную быструю узкоспециализированную
процессорную (системную) шину. Напротив,
в соответствии с веяниями времени они
соорудили очень быструю последовательную
шину данных и предусмотрели возможности
для ее “переноса” в более простые и
медленные варианты с уменьшенными
частотами и разрядностью (в отличие от
PCI Express, которая масштабируется “вверх”
- от x1 к х16 и x32).
Поэтому HT (минимальная
ширина которой - 2 бита) с полным правом
может называться последовательной
шиной - любые данные, передаваемые по
ней, упаковываются в пакеты стандартного
вида. Правда, требования скорости
наложили на протокол передачи данных
сильнейшие ограничения - столь изящной
“layered architecture”, как у Intel, мы здесь не
увидим, да и влияние физической реализации
линков HT на общую архитектуру шины очень
заметно.
^
2. Обзор, характеристики, принцип
работы
HyperTransport
работает на частотах от 200 МГц до 2,6 ГГц
(сравните с шиной PCI и её 33 или 66 МГц).
Кроме того, она использует DDR, что
означает, что данные посылаются как по
переднему, так и по заднему фронтам
сигнала синхронизации, что позволяет
осуществлять до 5200 миллионов посылок
в секунду при частоте сигнала синхронизации
2,6 ГГц; частота сигнала синхронизации
настраивается автоматически.
HyperTransport
поддерживает автоматическое определение
ширины шины, от 2-х битных линий до 32-х
битных линий. Полноразмерная,
полноскоростная, 32-х битная шина в
двунаправленном режиме способна
обеспечить пропускную способность до
41600 МБ/с (2[ddr]*2*(32/8)*2600) (20800 МБ/с - max в одном
направлении), являясь, таким образом,
самой быстрой шиной среди себе подобных.
Шина HyperTransport основана на передаче
пакетов. Каждый пакет состоит из 32
разрядных слов, вне зависимости от
физической ширины шины (количества
информационных линий). Первое слово в
пакете — всегда управляющее слово. Если
пакет содержит адрес, то последние 8 бит
управляющего слова сцеплены со следующим
32-битным словом, в результате образуя
40 битный адрес. Шина поддерживает 64
разрядную адресацию — в этом случае
пакет начинается со специального 32
разрядного управляющего слова,
указывающего на 64 разрядную адресацию,
и содержащего разряды адреса с 40 по 63
(разряды адреса нумеруются начиная с
0). Остальные 32-х битные слова пакета
содержат непосредственно передаваемые
данные. Данные всегда передаются 32-х
битными словами, вне зависимости от их
реальной длины (например, в ответ на
запрос на чтение одного байта по шине
будет передан пакет, содержащий 32 бита
данных и флагом-признаком того, что
значимыми из этих 32 бит являются только
8).
Пакеты HyperTransport передаются по
шине последовательно. Увеличение
пропускной способности влечёт за собой
увеличение ширины шины.
Операция
записи на шине бывает двух видов —
posted
и non-posted.
Posted-операция записи заключается в
передаче единственного пакета, содержащего
адрес, по которому необходимо произвести
запись, и данные. Эта операция обычно
используется для обмена данными с
высокоскоростными устройствами,
например, для DMA передачи. Non-posted операция
записи состоит из посылки двух пакетов:
устройство, инициирующее операцию
записи посылает устройству-адресату
пакет, содержащий адрес и данные.
Устройство-адресат, получив такой пакет,
проводит операцию записи и отсылает
устройству-инициатору пакет, содержащий
информацию о том, успешно ли произведена
запись.
Электрический интерфейс
HyperTransport/LDT — низковольтные дифференциальные
сигналы (Low Voltage Differential Signaling (LVDS)), с
напряжением 2,5 В.
^
3. Основные достоинства
Давайте
попробуем выделить основные
приемущества:
1). HyperTransport, ранее
носившая название, позиционируется как
дополнение к технологии InfiniBand на рынок
телекоммуникационных и встроенных
систем, что налагает свои требования
на спецификацию, реализующую преимущества
обоих направлений. По заявлению
руководства HTTC, технология может быть
с одинаковым успехом использована как
в серверных системах, так и в настольных
и мобильных устройствах. Результатом
этого станет некоторое изменение в
архитектуре компьютера: связь между
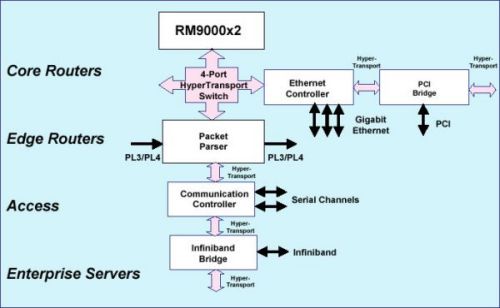
контроллерами периферийных устройств
будет обеспечивать шина HyperTransport.
 2).
Технология позволяет производителям
аппаратного обеспечения изменять
количество сигнальных линий, что влечет
за собой изменение количества выводов
на плате, если этого требует реализация,
а также изменение потребляемой мощности,
так как лишние выводы требуют
дополнительного питания. Этот факт
может повлиять на широкое распространение
технологии в мобильных системах. Кроме
того, HyperTransport— это peer-to-peer шина, позволяющая
обмениваться информацией между
периферийными устройствами без
задействования процессора и памяти.
Протокол использует пакетированную
передачу данных; за передачу данных
между устройствами отвечает контроллер
шины. Подключение контроллера в
двухпроцессорной системе показано на
рисунке:
2).
Технология позволяет производителям
аппаратного обеспечения изменять
количество сигнальных линий, что влечет
за собой изменение количества выводов
на плате, если этого требует реализация,
а также изменение потребляемой мощности,
так как лишние выводы требуют
дополнительного питания. Этот факт
может повлиять на широкое распространение
технологии в мобильных системах. Кроме
того, HyperTransport— это peer-to-peer шина, позволяющая
обмениваться информацией между
периферийными устройствами без
задействования процессора и памяти.
Протокол использует пакетированную
передачу данных; за передачу данных
между устройствами отвечает контроллер
шины. Подключение контроллера в
двухпроцессорной системе показано на
рисунке:
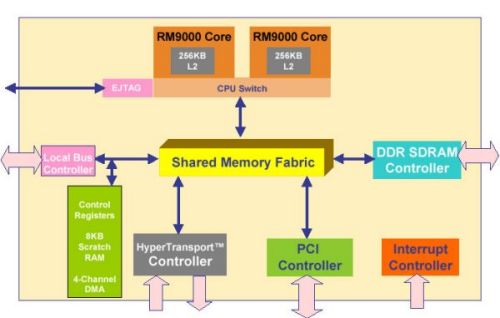 3).
Возможность передачи асимметричных
потоков данных от(к) периферийных(м)
устройств(ам). Симметричная, то есть
одинаковая в обоих направлениях,
пропускная способность не всегда нужна
в компьютере. Примером могут служить
системы, преимущественно отображающие
графическую информацию, или системы,
активно посылающие запросы в сеть для
получения больших объемов информации.
4).
Шина HyperTransport поддерживает технологии
энергосбережения, а именно ACPI. Это
значит, что при изменении состояния
процессора (C-state) на энергосберегающее,
изменяется также и состояние устройств
(D-state). Например, при отключении процессора
НЖМД также отключаются.
5). Высокая
скорость работы (до 12.8 ГБ/с).
4.
Применение. Реализации
^
3).
Возможность передачи асимметричных
потоков данных от(к) периферийных(м)
устройств(ам). Симметричная, то есть
одинаковая в обоих направлениях,
пропускная способность не всегда нужна
в компьютере. Примером могут служить
системы, преимущественно отображающие
графическую информацию, или системы,
активно посылающие запросы в сеть для
получения больших объемов информации.
4).
Шина HyperTransport поддерживает технологии
энергосбережения, а именно ACPI. Это
значит, что при изменении состояния
процессора (C-state) на энергосберегающее,
изменяется также и состояние устройств
(D-state). Например, при отключении процессора
НЖМД также отключаются.
5). Высокая
скорость работы (до 12.8 ГБ/с).
4.
Применение. Реализации
^