

Модель парной линейной регрессии.
Коэффициент корреляции показывает, что две переменные связаны друг с другом, однако он не дает представления о том, каким образом они связаны. Рассмотрим более подробно те случаи, для которых мы предполагаем, что одна переменная зависит от другой.
Сразу же отметим, что не следует ожидать получения точного соотношения между какими-либо двумя экономическими показателями, за исключением тех случаев, когда оно существует по определению. В учебниках по экономической теории эта проблема обычно решается путем приведения соотношения, как если бы оно было точным, и предупреждения читателя о том, что это аппроксимация. В статистическом анализе, однако, факт неточности соотношения признается путем явного включения в него случайного фактора, описываемого случайным остаточным членом. Начнем с рассмотрения простейшей модели:
y= + x+u (2.1)
Величина у, рассматриваемая как зависимая переменная, состоит из двух составляющих: 1) неслучайной составляющей + x , где x выступает как объясняющая (или независимая) переменная, а постоянные величины и — как параметры уравнения; 2) случайного члена и.
На рис. 2.2 (слайд) показано, как комбинация этих двух составляющих определяет величину у. Показатели х1, х2, х3, х4 - это четыре гипотетических значения объясняющей переменной. Если бы соотношение между у и х было точным, то соответствующие значения у были бы представлены точками Q1, Q2, Q3, Q4 на прямой. Наличие случайного члена приводит к тому, что в действительности значение у получается другим. Предполагалось, что случайный член возмущения положителен в первом и четвертом наблюдениях и отрицателен в двух других. Поэтому если отметить на графике реальные значения у при соответствующих значениях х, то мы получим точки P1, P2, P3, P4 .
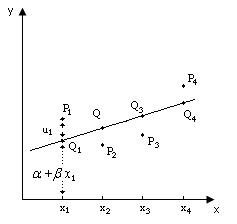
Рис. 2.2.
Следует подчеркнуть, что точки Р — это единственные точки, отражающие реальные значения переменных на рис. 2. Фактические значения и и, следовательно, положения точек Q неизвестны, так же как и фактические значения случайного члена. Задача регрессионного анализа состоит в получении оценок и и, следовательно, в определении положения прямой по точкам Р. Очевидно, что чем меньше значения и, тем легче эта задача. Действительно, если бы случайный член отсутствовал вовсе, то точки Р совпали бы с точками Q и точно показали бы положение прямой. В этом случае достаточно было бы просто построить эту прямую и определить значения и .
Почему же существует случайный член? Имеется несколько причин. 1. Невключение объясняющих переменных. Соотношение между у и х почти наверняка является очень большим упрощением. В действительности существуют другие факторы, влияющие на у, которые не учтены в формуле (2.1). Влияние этих факторов приводит к тому, что наблюдаемые точки лежат вне прямой. В результате мы получаем то, что обозначено как и. Если бы мы точно знали, какие переменные присутствуют здесь, и имели возможность точно их измерить, то могли бы включить их в уравнение и исключить соответствующий элемент из случайного члена..
2. Агрегирование переменных. Во многих случаях рассматриваемая зависимость — это попытка объединить вместе некоторое число микроэкономических соотношений. Например, функция суммарного потребления — это попытка общего выражения совокупности решений отдельных индивидов о расходах. Так как отдельные соотношения, вероятно, имеют разные параметры, любая попытка определить соотношение между совокупными расходами и доходом является лишь аппроксимацией. Наблюдаемое расхождение при этом приписывается наличию случайного члена.
3. Неправильное описание структуры модели. Структура модели может быть описана неправильно или не вполне правильно. Здесь можно привести один из многих возможных примеров. Если зависимость относится к данным о временном ряде, то значение у может зависеть не от фактического значения х, а от значения, которое ожидалось в предыдущем периоде. Если ожидаемое и фактическое значения тесно связаны, то будет казаться, что между у и х существует зависимость, но это будет лишь аппроксимация. Расхождение вновь будет связано с наличием случайного члена.
4. Неправильная функциональная спецификация. Функциональное соотношение между у и х математически может быть определено неправильно. Например, истинная зависимость может не являться линейной, а быть более сложной. Безусловно, надо постараться избежать возникновения этой проблемы, используя подходящую математическую формулу, но любая самая изощренная формула является лишь приближением, и существующее расхождение вносит вклад в остаточный член.
5. Ошибки измерения. Если в измерении одной или более взаимосвязанных переменных имеются ошибки, то наблюдаемые значения не будут соответствовать точному соотношению, и существующее расхождение будет вносить вклад в остаточный член.
Остаточный член является суммарным проявлением всех этих факторов. Очевидно, что если бы нас интересовало только измерение влияния х на у, то было бы значительно удобнее, если бы остаточного члена не было. Если бы он отсутствовал, мы бы знали, что любое изменение у от наблюдения к наблюдению вызвано изменением х, и смогли бы точно вычислить b. Однако в действительности каждое изменение у отчасти вызвано изменением и, и это значительно усложняет жизнь.
Оценка достоверности уравнения регрессии в целом
В корреляционно-регрессионном анализе наиболее точные характеристики связи можно получить лишь в том случае, если исследователь опирается на всю совокупность фактов и событий определенного рода, то есть если удалось провести сплошное наблюдение генеральной совокупности. Многие экономические совокупности являются бесконечными по своей численности (это совокупности фактов купли-продажи товаров, совокупность решений покупателей и т.д.), что делает сплошное наблюдение невозможным или труднореализуемым.
Если же уравнение регрессии определено по выборочным данным, то важно помнить о том, что вся интерпретация уравнения в действительности представляет собой лишь оценку реальных соотношений взаимосвязанных признаков в генеральной совокупности. Кроме того, уравнение регрессии отражает только общую закономерность для выборки. При этом каждое отдельное наблюдение подвержено воздействию случайностей. Поэтому, если выборочные характеристики связи необходимо распространить на генеральную совокупность, то следует провести статистическую оценку их достоверности или существенности.
Определение.
Достоверным (существенным) показателем связи называют тот, величина которого сформировалась под действием закономерности, имеющей место в генеральной совокупности; под достоверностью в математической статистике понимают вероятность того, что значение проверяемого показателя связи не равно нулю и не включает в себя величины противоположных знаков. Недостоверный (несущественный) показатель формируется под влиянием случайных причин.
Статистическую оценку достоверности выборочных показателей связи обычно проводят в определенной последовательности. Первая процедура проводится на основе дисперсионного анализа с помощью F-критерия Фишера. Данная процедура получила название F-теста уравнения регрессии. Ее назначение - сделать вывод о правильности выбора вида взаимосвязи и дать характеристику достоверности всего уравнения регрессии в целом.
Рассмотрим
данную процедуру более подробно.
Непосредственному расчету F-критерия
предшествует анализ вариации зависимой
переменной. Центральное место в нем
занимает разложение общей суммы квадратов
отклонений переменной у
от среднего значения
![]() на две части – «воспроизведенную
регрессией» и «остаточную»:
на две части – «воспроизведенную
регрессией» и «остаточную»:
![]() =
=
![]() +
+
![]() 3.1.
3.1.
↓ ↓ ↓
Общая сумма Сумма квадратов Остаточная сумма
квадратов отклонений, квадратов
отклонений воспроизведенная отклонений
регрессией
Пригодность линии регрессии для прогноза зависит от того, какая часть общей вариации признака у приходится на объясненную вариацию. Очевидно, что если сумма квадратов отклонений, обусловленная регрессией, будет больше остаточной суммы квадратов, то уравнение регрессии статистически значимо и фактор х оказывает существенное воздействие на результат у.
Любая
сумма квадратов отклонений связана с
числом степеней свободы (df
– degrees
of
freedom),
то есть с числом свободы независимого
варьирования признака. Число степеней
свободы связано с числом единиц
совокупности п
и с числом определяемых по ней констант.
Число степеней свободы показывает,
сколько независимых отклонений из п
возможных
![]() требуется для образования данной суммы
квадратов отклонений. Так, для общей
суммы квадратов
требуется для образования данной суммы
квадратов отклонений. Так, для общей
суммы квадратов
![]() требуется
(п
–1) независимых отклонений, ибо по
совокупности из п
единиц после расчета среднего уровня
свободно варьируют лишь (п
–1) число отклонений.
требуется
(п
–1) независимых отклонений, ибо по
совокупности из п
единиц после расчета среднего уровня
свободно варьируют лишь (п
–1) число отклонений.
При
расчете «объясненной» суммы квадратов
![]() используются
теоретические (расчетные) значения
результативного признака, найденные
по линии регрессии
используются
теоретические (расчетные) значения
результативного признака, найденные
по линии регрессии
![]() = а + вх.
Параметр а
можно определить как
= а + вх.
Параметр а
можно определить как
![]() .
Подставив выражение параметра а
в линейную
модель, получим:
.
Подставив выражение параметра а
в линейную
модель, получим:
![]() .
Отсюда видно, что при заданном наборе
переменных у
и х
расчетное значение
является в линейной регрессии функцией
только одного параметра – коэффициента
регрессии. Соответственно и регрессионная
сумма квадратов отклонений имеет число
степеней свободы, равное 1. В общем случае
для воспроизведенного (регрессионного,
факторного) объема вариации число
степеней свободы определяется как число
неизвестных параметров уравнения при
объясняющих переменных. Так, в случае
двухфакторной линейной регрессии (
.
Отсюда видно, что при заданном наборе
переменных у
и х
расчетное значение
является в линейной регрессии функцией
только одного параметра – коэффициента
регрессии. Соответственно и регрессионная
сумма квадратов отклонений имеет число
степеней свободы, равное 1. В общем случае
для воспроизведенного (регрессионного,
факторного) объема вариации число
степеней свободы определяется как число
неизвестных параметров уравнения при
объясняющих переменных. Так, в случае
двухфакторной линейной регрессии (![]() =
а + вх1+сх2
) dfрегр.=2.
=
а + вх1+сх2
) dfрегр.=2.
Число
степеней свободы для остаточной вариации![]() находят по остаточному принципу, то
есть как разность между общим и
регрессионным числом степеней свободы:
dfост.
= dfобщ.
–
dfрегр..
Для парной линейной регрессии
dfост=
(п-1)
– 1 = п
– 2.
находят по остаточному принципу, то
есть как разность между общим и
регрессионным числом степеней свободы:
dfост.
= dfобщ.
–
dfрегр..
Для парной линейной регрессии
dfост=
(п-1)
– 1 = п
– 2.
Итак, имеем два равенства:
=
![]() +
+
![]()
dfобщ = dfрегр + dfост 3.2.
Разделив каждую сумму квадратов на соответствующее ей число степеней свободы, получим средний квадрат отклонений, или что тоже самое, дисперсию на одну степень свободы s2:
![]() ;
;
![]() ;
;
![]() 3.3
3.3
Определение дисперсии на одну степень свободы приводит дисперсии к сопоставимому виду. Общая дисперсия s2общ. дает количественную оценку средней изменчивости результативного признака под влиянием всех факторов; s2регр. – под влиянием фактора (факторов), включенных в уравнение связи; s2ост. – под влиянием всех прочих неучтенных в уравнении (случайных) причин.
Если уравнение регрессии построено по выборочным данным, то вполне логичным является опасение: не является ли «объясненная» вариация в действительности мнимым объяснением, то есть следствием случайной выборки, а не влиянием изучаемого фактора? Для того чтобы ответить на этот вопрос, необходимо сопоставить регрессионную и остаточную дисперсии. Отношение этих дисперсий дает фактическое значение критерия Фишера (F-критерия):
 3.4.
3.4.
где
F- это критерий для проверки нулевой гипотезы Н0: s2регр.= s2ост.
Если нулевая гипотеза справедлива, то регрессионная и остаточная дисперсии не отличаются друг от друга. Для опровержения нулевой гипотезы необходимо, чтобы регрессионная дисперсия превышала остаточную в несколько раз. Английским статистиком Снедекором разработаны таблицы критических значений F-отношений (Fтабл.) при разном уровне существенности нулевой гипотезы и различном числе степеней свободы. Табличное значение F-критерия – это максимальная величина отношения дисперсий, которая может иметь место при случайном их расхождении для данного уровня вероятности суждения. Фактическое (вычисленное) значение F-критерия признается достоверным (отличным от единицы), если оно больше табличного. В этом случае нулевая гипотеза о случайном характере связи изучаемых признаков отклоняется и делается вывод о достоверности такой связи Fфакт.> Fтабл., , Н0 отклоняется.
Если же величина окажется меньше табличной Fфакт.≤ Fтабл, то вероятность нулевой гипотезы выше заданного уровня (например, 0,05) и она не может быть отклонена без серьезного риска сделать неправильный вывод о наличии связи. В этом случае уравнение регрессии считается статистически недостоверным, Н0 не отклоняется.
Основное применение – прогнозирование по уравнению регрессии. Ограничением
при прогнозировании служат условия стабильности других факторов и условий
процесса. Если резко измениться в нем среда протекающего процесса, то данное
уравнение регрессии не будет иметь места.
Точечный прогноз получается подстановкой в уравнение регрессии ожидаемого
значения фактора. Вероятность точной реализации такого прогноза крайне мала.
Если точечный прогноз сопровождается значением средней ошибки прогноза, то
такой прогноз называется интервальным.
Средняя ошибка прогноза образуется из двух видов ошибок:
1. ошибок 1 рода – ошибка линии регрессии
2. ошибка 2 рода – ошибка связанная с ошибкой вариации.
Средняя ошибка прогноза.

![]() -
ошибка положения линии регрессии в
генеральной совокупности
-
ошибка положения линии регрессии в
генеральной совокупности
n - объем выборки
xk – ошибочное значение фактора
![]() - СКО результативного
признака от линии регрессии в генеральной
совокупности
- СКО результативного
признака от линии регрессии в генеральной
совокупности
Построение точечного и интервального прогноза для модели парной линейной регрессии
Для модели парной линейной регрессии точечный прогноз зависимой переменной у при заданном значении независимой переменной хp
![]() будет
выглядеть следующим образом:
будет
выглядеть следующим образом:
![]() .
.
Чтобы получить интервальный прогноз, определим стандартную ошибку предсказываемого значения
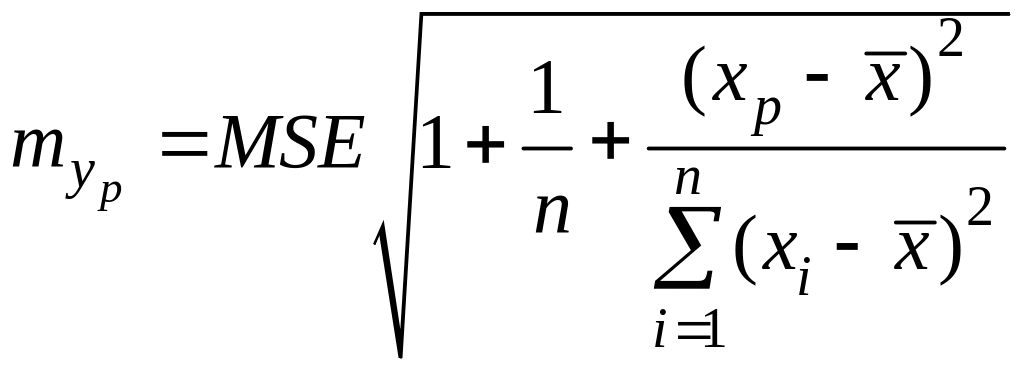 .
.
С доверительной вероятностью γ или (1–α) точечная оценка прогноза результативного признака yp попадает в интервал прогноза, который определяется по формуле:
![]() ,
,
Где tкрит – t-критерий Стьюдента, который определяется в зависимости от заданного уровня значимости α и числа степеней свободы (п – 2) (в случае парной регрессионной модели);
MSE – стандартная ошибка линейного уравнения парной регрессии, вычисляемая по формуле
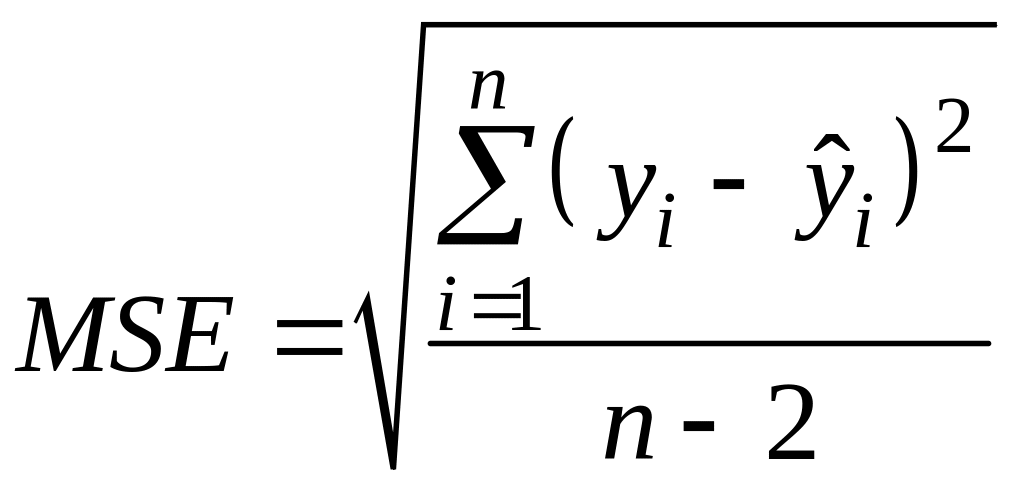 .
.