

Проверка однородности дисперсий
П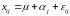 ри
использовании стандартных методов
дисперсионного анализа должно
удовлетворяться условие равенства
дисперсий остаточных случайных величин.
Если нет уверенности в том, что данное
условие выполняется, следует проводить
проверку однородности дисперсий.
Например, в модели однофакторного
дисперсионного анализа
ри
использовании стандартных методов
дисперсионного анализа должно
удовлетворяться условие равенства
дисперсий остаточных случайных величин.
Если нет уверенности в том, что данное
условие выполняется, следует проводить
проверку однородности дисперсий.
Например, в модели однофакторного
дисперсионного анализа
может понадобиться проверить, изменяется ли D[εij] = σi2 в различных группах, т. е. проверить гипотезу
σ12 = σ22 = … = σk2
Критерий Бартлетта
П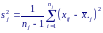 усть
из k
совокупностей взяты выборки объемами
n1,
n2,
...nk
и получены оценки дисперсии:
усть
из k
совокупностей взяты выборки объемами
n1,
n2,
...nk
и получены оценки дисперсии:
Т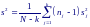 огда
для объединенной оценки дисперсии при
справедливости нулевой гипотезы H0:
σ12
= σ22
= … = σk2
получим:
огда
для объединенной оценки дисперсии при
справедливости нулевой гипотезы H0:
σ12
= σ22
= … = σk2
получим:

Бартлетт доказал, что, если справедлива нулевая гипотеза, то статистика
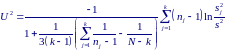
при N → ∞ асимптотически имеет распределение χ2 с k−1 степенями свободы.
Однако этот критерий слишком чувствителен к отклонению распределений совокупностей от нормальности, поэтому значимость статистики U2 может указывать не на отсутствие однородности дисперсий, а просто на отклонение от нормальности.
Критерий Кочрена основан на статистике:
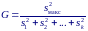
при этом объемы выборок, по которым рассчитаны sj2, должны быть одинаковы.
Распределение этой статистики известно точно и зависит только от числа степеней свободы n−1 и количества выборок. Нулевая гипотеза H0: все σj2 равны отвергается с уровнем значимости α, если значение статистики G > Gкр. Критическое значение статистики находят по таблицам процентных точек распределения Кочрена.
Непараметрические методы факторного анализа. Ранговый однофакторный анализ.
В ряде случаев предположение о нормальности закона распределения остаточных случайных величин в моделях, описанных в дисперсионном анализе, не выполняется. Более того, этот закон оказывается неизвестным. Тогда используют различные непараметрические методы проверки однородности нескольких выборок, из которых наиболее разработаны ранговые методы.
Обозначив через rij ранг значения xij, который получит это значение при упорядочении всей совокупности данных в порядке возрастания, придем к следующей таблице данных.

В рамках ранговых критериев нулевая гипотеза формулируется как гипотеза о том, что все k выборок (столбцов таблицы) являются выборками из одного и того же распределения.
Строго говоря, если нулевая гипотеза отвергается, то можно только утверждать, что распределения совокупностей различны. Это, однако, не означает, что их средние не равны между собой. Для вывода о том, что выборки производились из совокупностей с различными математическими ожиданиями, необходимо предположить, что эти совокупности одинаковы по всем другим параметрам.
Критерий Краскела-Уолллиса.
В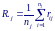 ычислим
при каждом значении фактора Aj,
т. е. для j-го
столбца таблицы рангов, значения средних
рангов R.j
ычислим
при каждом значении фактора Aj,
т. е. для j-го
столбца таблицы рангов, значения средних
рангов R.j
Если между столбцами нет систематических различий, то средние ранги R.j не должны значительно отличаться от среднего ранга, рассчитанного по всей совокупности рангов.
Общее число наблюдений N = n1 + n2 + … nk. Для объединенной группы рангами являются числа 1, 2, ..., N и общая сумма рангов равна:
![]()
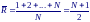
Тогда средний ранг для объединенной группы равен:
Далее найдем величину, аналогичную межгрупповой сумме квадратов отклонений
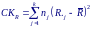
Величина СКR зависит от размеров групп. Чтобы получить показатель, отражающий их различия, следует поделить СКR на N(N +1)/12. Полученная величина
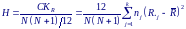
является значением критерия Краскела-Уолллиса.
Д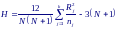 ругая
форма записи этой статистики, удобная
для вычислений, имеет вид
ругая
форма записи этой статистики, удобная
для вычислений, имеет вид

где – сумма рангов j-го столбца.
При больших объемах выборок, которые находятся за пределами таблиц, случайная величина H при справедливости нулевой гипотезы приближенно распределена по закону χ2 с k − 1 степенями свободы. Поэтому в этом приближении нулевая гипотеза отвергается на уровне значимости α, если вычисленное по данным значение статистики H больше χ2k−1;α – α процентной точки распределения χ2 с k−1 степенями свободы.
Е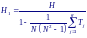 сли
в таблице данных есть совпадающие
значения, необходимо при их ранжировании
и переходе к таблице рангов использовать
средние ранги. Если совпадений много,
то рекомендуется применять модифицированную
форму статистики H:
сли
в таблице данных есть совпадающие
значения, необходимо при их ранжировании
и переходе к таблице рангов использовать
средние ранги. Если совпадений много,
то рекомендуется применять модифицированную
форму статистики H:
где g – число групп совпадающих наблюдений; Tj = (tj3 − tj ); tj – число совпадающих наблюдений в группе с номером j.