

Зависимость между признаками, измеренными в номинальной или порядковой шкалах
Часто возникает задача проверки независимости двух признаков, измеренных в номинальной или порядковой шкалах.
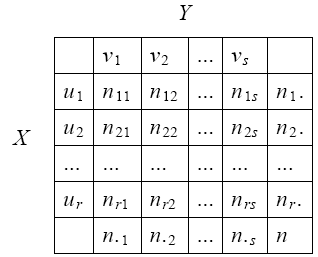
Пусть у каких-то объектов измеряются два признака X и Y с числом уровней r и s соответственно. Результаты таких наблюдений удобно представлять в виде таблицы, называемой таблицей сопряженности признаков.
В таблице ui (i = 1, ..., r) и vj (j= 1, ..., s) – значения, принимаемые признаками, величина nij – число объектов из общего числа объектов, у которых признак X принял значение ui, а признак Y – значение vj
В ведем
следующие случайные величины:
ведем
следующие случайные величины:
– количество объектов, у которых встретилось значение ui
– количество объектов, у которых встретилось значение vj

Кроме того, имеют место очевидные равенства
Пусть далее



Дискретные случайные величины X и Y независимы тогда и только тогда, когда

для всех пар i, j
Поэтому гипотезу о независимости дискретных случайных величин X и Y можно записать так:
В качестве альтернативной, как правило, используют гипотезу

С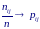 удить
о справедливости гипотезы H0
следует на основании выборочных частот
nij
таблицы сопряженности. В соответствии
с законом больших чисел при n→∞
относительные частоты близки к
соответствующим вероятностям:
удить
о справедливости гипотезы H0
следует на основании выборочных частот
nij
таблицы сопряженности. В соответствии
с законом больших чисел при n→∞
относительные частоты близки к
соответствующим вероятностям:
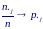
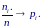
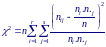
Для проверки гипотезы H0 используется статистика
которая при справедливости гипотезы имеет распределение χ2 с rs − (r + s − 1) степенями свободы.
Критерий независимости χ2 отклоняет гипотезу H0 с уровнем значимости α, если:
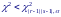
Регрессионный анализ. Основные понятия регрессионного анализа
Для математического описания статистических связей между изучаемыми переменными величинами следует решить следующие задачи:
подобрать класс функций, в котором целесообразно искать наилучшую (в определенном смысле) аппроксимацию интересующей зависимости;
найти оценки неизвестных значений параметров, входящих в уравнения искомой зависимости;
установить адекватность полученного уравнения искомой зависимости;
выявить наиболее информативные входные переменные.
Совокупность перечисленных задач и составляет предмет исследований регрессионного анализа.
Функцией регрессии (или регрессией) называется зависимость математического ожидания одной случайной величины от значения, принимаемого другой случайной величиной, образующей с первой двумерную систему случайных величин.
П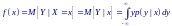 усть
имеется система случайных величин
(X,Y),
то функция регрессии Y
на X
усть
имеется система случайных величин
(X,Y),
то функция регрессии Y
на X
а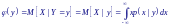 функция регрессии X
на Y
функция регрессии X
на Y
Функции регрессии f(x) и φ(y), не являются взаимно обратимыми, если только зависимость между X и Y не является функциональной.
В случае n-мерного вектора с координатами X1, X2,…, Xn можно рассматривать условное математическое ожидание для любой компоненты. Например, для X1
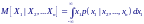
называется регрессией X1 на X2, …, Xn.
Для полного определения функции регрессии необходимо знать условное распределение выходной переменной при фиксированных значениях входной переменной.
Поскольку в реальной ситуации такой информацией не располагают, то обычно ограничиваются поиском подходящей аппроксимирующей функции fa(x) для f(x), основываясь на статистических данных вида (xi, yi), i = 1,…, n. Эти данные являются результатом n независимых наблюдений y1,…, yn случайной величины Y при значениях входной переменной x1,…, xn, при этом в регрессионном анализе предполагается, что значения входной переменной задаются точно.
Проблема выбора наилучшей аппроксимирующей функции fa(x), являясь основной в регрессионном анализе, и не имеет формализованных процедур для своего решения. Иногда выбор определяется на основе анализа экспериментальных данных, чаще из теоретических соображений.
Если предполагается, что функция регрессии является достаточно гладкой, то аппроксимирующая ее функция fa(x) может быть представлена в виде линейной комбинации некоторого набора линейно независимых базисных функций ψk(x), k = 0, 1,…, m−1, т. е. в виде
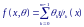
где m – число неизвестных параметров θk (в общем случае величина неизвестная, уточняемая в ходе построения модели).
Такая функция является линейной по параметрам, поэтому в рассматриваемом случае говорят о модели функции регрессии, линейной по параметрам.
Тогда задача отыскания наилучшей аппроксимации для линии регрессии f(x) сводится к нахождению таких значений параметров, при которых fa(x;θ) наиболее адекватна имеющимся данным. Одним из методов позволяющем решить эту задачу является метод наименьших квадратов.