

Вопрос 13) Алгоритм Кнута, Мориса- Пратта
При построении конечного автомата для поиска подстроки в тексте легко построить переходы из начального состояния в конечное принимающее состояние: эти переходы помечены символами подстроки (см. рис. 1). Проблема возникает при попытке добавить другие символы, которые не переводят в конечное состояние.

Алгоритм Кнута-Морриса-Пратта основан на принципе конечного автомата, однако он использует более простой метод обработки неподходящих символов. В этом алгоритме состояния помечаются символами, совпадение с которыми должно в данный момент произойти. Из каждого состояния имеется два перехода: один соответствует успешному сравнению, другой - несовпадению. Успешное сравнение переводит нас в следующий узел автомата, а в случае несовпадения мы попадем в предыдущий узел, отвечающий образцу. Пример автомата Кнута-Морриса-Пратта для подстроки ababcb приведен на рисунке 2.
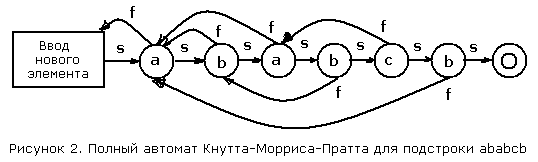
При всяком переходе по успешному сравнению в конечном автомате Кнутта-Морриса-Пратта происходит выборка нового символа из текста. Переходы, отвечающие неудачному сравнению, не приводят к выборке нового символа; вместо этого они повторно используют последний выбранный символ. Если мы перешли в конечное состояния, то это означает, что искомая подстрока найдена. Проверьте текст abababcbab на автомате, изображенном на рисунке 3, и посмотрите, как происходит успешный поиск подстроки. Вот полный алгоритм поиска:
subLoc = 1 // указатель текущего сравниваемого символа в подстроке
textLoc = 1 // указатель текущего сравниваемого символа в тексте
while textLoc <= length(text) and subLoc <= length(substring) do
if subLoc = 0 or text[textLoc] = substring[subLoc] then
textLoc = textLoc + 1
subLoc = subLoc + 1
else // совпадения нет; переход по несовпадению
subLoc = fail[subLoc]
end if
end while
if (subLoc > length(substring)) then
return textLoc - length(substring) + 1 //найденное совпадение
else
return 0 // искомая подстрока не найдена
end if
Прежде, чем перейти к анализу этого процесса, рассмотрим как задаются переходы по несовпадению. Заметим, что при совпадении ничего особенного делать не надо: происходит переход к следующему узлу. Напротив, переходы по несовпадению определяются тем, как искомая подстрока соотносится сама с собой. Например, при поиске подстроки ababcb нет необходимости возвращаться назад на четыре позиции при необнаружении символа c. Если уж мы добрались до пятого символа в образце, то мы знаем, что первые четыре символа совпали, и поэтому символы ab в тексте, отвечающие третьему и четвертому символам образца, совпадают также с первым и вторым символами образца. Вот как выглядит алгоритм, задающий эти соотношения в подстроке:
fail[1] = 0
for i = 2 to length(substring) do
temp = fail[i - 1]
while (temp > 0) and (substring[temp] /= substring[i - 1]) do
temp = fail[temp]
end while
fail[i] = temp + 1
end for
Вопрос 14) Хэширование данных
Методы поиска информации
Линейный
Линейный с барьером
Бинарный
Хеширование
Хеширование–этоспособхраненияданных,обеспечивающийбыстрыйпоискидобавлениеэлементов.
Из историиИдеяхешированиявпервыебылавысказанаГ.П.ЛаномприсозданиивнутреннегомеморандумаIBMвянваре1953г.спредложениемиспользоватьдляразрешенияколлизийхеш-адресовметодцепочек.
ВоткрытойпечатихешированиевпервыебылоописаноАрнольдомДуми(1956),указавшим,чтовкачествехеш-адресаудобноиспользоватьостатокотделениянапростоечисло.
Подходкхешированию,отличныйотметодацепочек,былпредложенА.П.Ершовым(1957),которыйразработалиописалметодлинейнойоткрытойадресации.
СредидругихисследованийможноотметитьработыПетерсона(1957)иМорриса(1968).Впервойреализовывалсяклассметодовсоткрытойадресациейприработесбольшимифайлами,авовторойдавалсяобширныйобзорпохешированиюивводилсятермин«рассеяннаяпамять»(scatterstorage).
Суть хешированияСведениеработысоднимбольшиммножествомкработесмассивомнебольшихмножеств.
Пример: записная книжка (абонент, телефон)
Методы поиска информации:
Линейный
Линейный с барьером
Бинарный
Хеширование. Страницы записной книжки помечены буквами алфавита; страница, помеченная некоторой буквой, содержит только фамилии, начинающиеся с этой буквы. Таким образом, все множество фамилий разбито на 28 подмножеств, соответствующих буквам русского алфавита. При поиске фамилии мы сразу открываем записную книжку на странице, помеченной первой буквой фамилии, и в результате поиск значительно убыстряется.
Составляющие метода хеширования
построение хеш-функции;
схема разрешения коллизий.
Понятие хеш-функции
Разбиение множества на подмножества осуществляется с помощью хеш-функции.
Хеш-функция определена на элементах множества и принимает целые неотрицательные значения.
Она должна быть подобрана таким образом, чтобы
ее можно было легко вычислять;
она должна принимать всевозможные различные значения приблизительно с равной вероятностью;
желательно, чтобы на близких значениях аргумента она принимала далекие друг от друга значения (свойство, противоположное математическому понятию непрерывности).
Значение хеш-функции для данной фамилии равно номеру первой буквы фамилии в русском алфавите.
Требования к выбору хеш-функции
а) ее вычисление должно быть очень быстрым
б) она должна минимизировать число коллизий
Понятие хеш-таблицы
Параметром реализации является число подмножеств, которое называют размером хеш-таблицы.
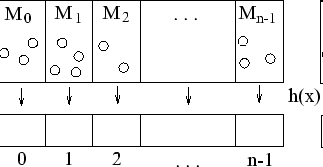
Пусть параметр равен N. Тогда хеш-функция должна принимать значения 0, 1, 2, ... , N - 1. Если изначально у нас есть некоторая функция H(x), принимающая произвольные целые неотрицательные значения, то в качестве хеш-функции можно использовать функцию h(x), равную остатку от деления H(x) на N.
Множество M разбивается на N непересекающихся подмножеств, занумерованных индексами от 0 до N-1. Подмножество Mi с индексом i содержит все элементы x из M, значения хеш-функции для которых равняются i:
Mi = {x € M : h(x) = i}
При поиске элемента x сначала вычисляется значение его хеш-функции: t = h(x). Затем мы ищем x в подмножестве Mt. Поскольку это подмножество небольшое, то поиск осуществляется быстро.
Для эффективной реализации каждое подмножество должно в большинстве случаев содержать не больше одного элемента. Следовательно, размер хеш-таблицы N должен быть больше, чем среднее число элементов множества. Обычно N выбирают превышающим число элементов множества примерно в три раза.
Сравнение бинарного поиска и хэш
Пусть N=1001 и в каждом списке максимум 3 элемента, а во всей хеш-таблице – 2048 элементов.
Тогда после вычисления хеш-значения элемента последовательный поиск в списке с этим номером потребует максимум три итерации.
Бинарный поиск потребует 11 итераций (211=2048).
Если количество элементов в разных списках отличается значительно, то эффективность хеширования падает. Самый плохой случай – если один список содержит все элементы, а остальные списки – пустые. Для поиска в этом случае может потребоваться 2048 итераций. Поэтому следует стремиться к тому, чтобы хеш-функция хорошо перемешивала элементы, заполняя хеш-таблицу как можно более равномерно для любых значений
Коллизией хеш-функции H называется ситуация, при которой для двух различных входов T1 и T2 выполняется условие:
H(T1)=H(T2), T1<>T2.
Совершенная хеш-функция - эта функция, которая не порождает коллизий.
Разрешить коллизии при хешировании можно двумя методами:
методом открытой адресации
методом цепочек
Разрешение коллизий при хешировании методом открытой адресации
Что произойдет, если необходимо ввести в таблицу некоторый новый номер изделия 0596397.
Используя хеш-функцию
h(key):=key mod 1000, h (0596397) =397 и запись для этого изделия должна находиться в позиции 397 в массиве. Однако позиция 397 уже занята, поскольку там находится запись с ключом 4957397. Следовательно, запись с ключом 0596397 должна быть вставлена в таблицу в другом месте.
Самым простым методом разрешения коллизий при хешировании является помещение данной записи в следующую свободную позицию в массиве.
Например, запись с ключом 0596397 помещается в ячейку 398, которая пока свободна, поскольку 397 уже занята. Когда эта запись будет вставлена, другая запись, которая хешируется в позицию 397 (с таким ключом, как 8764397) или в позицию 398 (с таким ключом, как 2194398), вставляется в следующую свободную позицию, которая в данном случае равна 400.
Если ячейка массива h(key) уже занята некоторой записью с другим ключом, то функция rh применяется к значению h(key) для того, чтобы найти другую ячейку, куда может быть помещена эта запись.
Если ячейка rh(h(key)) также занята, то хеширование выполняется еще раз и проверяется ячейка rh(rh(h(key))).
Этот процесс продолжается до тех пор, пока не будет найдена пустая ячейка.
Rh - это функция повторного хеширования, которая воспринимает один индекс в массиве и выдает другой индекс.