

2.1.2. Администрирование ms sql Server
Средства автоматического конфигурирования SQL Server
SQL Server содержит множество автоматических средств, предназначенных для снижения расходов, которые обычно связаны с конфигурированием и настройкой системы управления реляционными базами данных (RDBMS). В этом разделе вы ознакомитесь с некоторыми из этих средств. (Те, кто работал с Microsoft SQL Server 7, уже знают об этих средствах, поскольку они были введены именно в SQL Server 7.) Вы узнаете, как они действуют, как их использовать для облегчения вашей работы администратора баз данных (DBA) и как переопределять при необходимости эти автоматические средства.
Динамическое управление памятью
Динамическое управление памятью позволяет SQL Server динамически конфигурировать количество памяти, используемое для буферного кэша и кэша процедур, исходя из доступной памяти системы. Поскольку в SQL Server включено динамическое управление памятью, DBA не обязан вручную управлять размером каждого кэша. Но в определенных ситуациях вам может потребоваться ограничение количества памяти, используемой SQL Server, и такая возможность тоже существует.
Как действует динамическое управление памятью
Средство динамического управления памятью действует путем постоянного мониторинга доступной физической памяти в системе. SQL Server увеличивает или уменьшает пул памяти SQL Server (описан в следующем разделе), исходя из своих потребностей и количества доступной памяти. Это может оказаться очень полезным в системах, где количество используемой памяти относительно стабильно, но если количество памяти, используемое процессами, не связанными с SQL Server, варьируется, то SQL Server будет постоянно изменять свое распределение памяти, и это может создавать проблемы.
Компьютерная система, которая используется в основном как сервер базы данных SQL Server, вполне подходит для динамического управления памятью. В такой системе количество памяти, используемое процессами, отличными от SQL Server, стабильно, поэтому SQL Server будет автоматически выделять себе память, необходимую для своей эффективной работы вплоть до предела доступной физической памяти. Затем SQL Server будет поддерживать это количество, пока не потребуется память другим процессам. Если другому процессу действительно требуется память, SQL Server освобождает необходимое количество памяти, чтобы оно было доступно для другого процесса.
Компьютерная система, на которой выполняются процессы с постоянно изменяющимися требованиями памяти, причем количество процессов часто увеличивается или уменьшается, не слишком подходит для динамического управления памятью. На такой системе использование памяти постоянно изменяется, что требует от SQL Server постоянного закрепления и освобождения памяти, когда она требуется другим процессам, что может оказаться неэффективным из-за дополнительной нагрузки. В системе такого типа может оказаться более эффективным ручное выделение фиксированного количества памяти для SQL Server или задание минимального и максимального количества памяти, которое может получать SQL Server. Вы узнаете, как это сделать, ниже в этой лекции.
Таким образом, выбор между динамическим и ручным управлением памятью определяется степенью изменчивости использования памяти в системе. Применяя мониторинг использования памяти системой SQL Server, вы можете определить, изменяется ли количество используемой памяти каким-либо регулярным образом или остается достаточно стабильным. Для мониторинга использования памяти вы можете использовать Microsoft Windows 2000 Performance Monitor. Счетчик Total Server Memory (KB) внутри объекта SQLServer:Memory Manager показывает количество памяти в килобайтах (Кб), которое использует в данный момент SQL Server. Чтобы определить, как изменяется использование памяти в течение времени, следите за этим счетчиком в окне диаграмм (chart window).
Пул памяти
SQL Server динамически выделяет и освобождает память в пуле. Пул памяти содержит определенное количество памяти, которое разделяется между следующими компонентами:
Буферный кэш. Содержит страницы базы данных, считанные в память. Буферный кэш обычно забирает основную часть пула памяти.
Память для соединений. Используется каждым соединением с SQL Server. Память для соединений содержит структуры данных, с помощью которых отслеживается контекст каждого пользователя; это информация о позиционировании курсора, значения параметров очереди и информация хранимых процедур.
Структуры данных. Содержит глобальную информацию о блокировках и дескрипторах базы данных, включая информацию о владельцах блокировок, о типах захваченных блокировок, а также о различных файлах и группах файлов.
Кэш журнала. Используется для информации журнала, которая будет записана в журнал транзакций. Он также используется, когда происходит чтение последней информации, записанной в этот кэш. Использование кэша журнала повышает производительность операций записи в журналы. Кэш журнала не следует путать с буферным кэшем.
Кэш процедур. Используется для хранения планов исполнения операторов Transact-SQL (T-SQL) и хранимых процедур, когда происходит их выполнение.
Поскольку в случае использования динамического управления памятью распределение памяти динамически изменяется, пул памяти может все время увеличиваться или уменьшаться. Кроме того, указанные пять компонентов пула памяти тоже могут динамически изменять свои размеры. Это распределение недоступно для конфигурирования; управление осуществляет SQL Server. Например, когда требуется больше памяти, чтобы в кэше процедур можно было хранить больше операторов T-SQL, SQL Server может забирать часть памяти из буферного кэша и использовать ее для кэша процедур.
Использование дополнительной памяти
Количество памяти, доступной для SQL Server, зависит от используемой операционной системы Windows. Microsoft Windows NT Server 4 поддерживает 4 Гб памяти, 2 Гб из которых выделяется для пользовательских процессов и 2 Гб резервируется для использования системой. Это ограничение в 2 Гб представляет максимальное количество памяти, которое может быть выделено для SQL Server в NT 4.0. Но в системе Windows NT Server 4 Enterprise Edition количество виртуальной памяти, выделяемой для процесса, на 50 процентов больше – 3 Гб. Это увеличение стало возможным, так как память, выделенная для системы, была сокращена до 1 Гб. Такое увеличение виртуальной памяти, выделенной для процессов, позволяет вам увеличивать размер пула памяти до величины, близкой к 3 Гб. Чтобы активизировать эту поддержку в Windows NT 4 Enterprise Edition, вы должны добавить флаг /3GB к строке загрузки в файле Boot.ini, что можно сделать с помощью значка System (Система) в панели управления.
Имеется две версии операционной системы Windows 2000, в которых SQL Server 2000 Enterprise Edition может использовать интерфейс расширенной памяти Windows 2000 Address Windowing Extensions (AWE) API, поддерживающий адресные пространства большего размера. SQL Server поддерживает около 8 Гб в системе Windows 2000 Advanced Server и около 64 Гб в системе Windows 2000 Datacenter Server. AWE поддерживается только в этих двух операционных системах и не поддерживается в Windows 2000 Professional.
Параметры конфигурирования памяти SQL Server
Следующие параметры конфигурирования SQL Server связаны с конкретными аспектами распределения памяти. Вы можете задать эти параметры с помощью SQL Server Enterprise Manager или с помощью хранимой процедуры sp_configure. Для просмотра всех этих параметров с помощью sp_configure у вас должно быть задано значение 1 для параметра show advanced options (показать дополнительные параметры).
awe enabled (активизирована awe). Разрешает SQL Server использовать расширенную память (AWE-память, о которой говорилось выше). Значение 1 для этого параметра активизирует эту память. Данный параметр доступен только в SQL Server Enterprise Edition, и его можно задать только с помощью процедуры sp_configure.
index create memory (память для создания индекса). Ограничивает количество памяти, используемое для сортировок при создании индекса. Параметр index create memory является самоконфигурируемым. Он не требует изменений в большинстве случаев. Но если вы испытываете трудности при создании индексов, то можете попытаться увеличить значение этого параметра по сравнению с его значением по умолчанию.
max server memory (максимальная память для сервера). Задает максимальное количество памяти, которое может захватить для пула памяти SQL Server. Оставьте значение по умолчанию, если хотите, чтобы SQL Server динамически захватывал и освобождал память. Если вы хотите выделить память статически (чтобы используемое количество памяти не изменялось), задайте одинаковые значения для этого параметра и параметра min server memory.
min memory per query (минимальная память на один запрос). Задает минимальное количество памяти (в килобайтах), которое будет выделяться для выполнения одного запроса.
min server memory (минимальная память для сервера). Задает минимальное количество памяти, которое может захватить для пула памяти SQL Server. Оставьте значение по умолчанию, чтобы использовалось динамическое распределение памяти. Если вы хотите выделить память статически, задайте одинаковые значения для этого параметра и параметра max server memory.
set working set size (размер рабочего набора). Указывает, что для памяти, которую занял SQL Server, не допускается свопинг, даже если эта память может более эффективно использоваться другим процессом. Параметр set working set size не должен использоваться, если для SQL Server задано динамическое использование памяти. Его следует использовать, только когда для параметров min server memory и max server memory задано одинаковое значение. В этом случае SQL Server захватит определенное статическое количество памяти, не подлежащей страничному обмену.
Примечание. Для использования возможностей AWE-памяти у вас должна использовать система Windows 2000 Advanced Server или Windows 2000 Datacenter Server в сочетании с SQL Server 2000 Enterprise Edition.
Другие параметры динамического конфигурирования
В SQL Server имеется несколько параметров динамического конфигурирования или SQL Server Enterprise Manager (но не все параметры можно задать через Enterprise Manager). Чтобы задать какой-либо параметр через sp_configure, откройте Query Analyzer (Анализатор очередей) или osql-соединение в окне командной строки и запустите эту хранимую процедуру со следующими параметрами:
sp_configure "имя параметра", значение
Имя параметра – это имя параметра конфигурирования, а значение – это значение, которое вы хотите ему присвоить. Если запустить эту команду, не указывая значение , то SQL Server возвратит текущее значение указанного параметра. Чтобы увидеть список всех параметров и их значений, запустите sp_configure без какого-либо параметра. Несколько параметров считаются дополнительными. Для просмотра и конфигурирования этих параметров с помощью sp_configure вы должны сначала задать для параметра show advanced options (показать дополнительные параметры) значение 1, как это показано ниже:
sp_configure "show advanced options", 1
Параметр show advanced options не оказывает влияния на параметры, которые можно конфигурировать через Enterprise Manager.
Чтобы задать значение какого-либо параметра с помощью Enterprise Manager, сначала откройте в Enterprise Manager окно Properties (Свойства) для сервера, щелкнув правой кнопкой мыши на имени этого сервера и выбрав из контекстного меню пункт Properties (см. рисунок).

Рисунок 2.1.2.1 – Вкладка General окна Properties в Enterprise Manager
Вы можете затем осуществлять доступ к определенным динамическим параметрам во вкладках этого окна. В следующих разделах описываются динамические параметры SQL Server, не связанные с памятью; в каждом разделе указывается, можно ли задавать соответствующий параметр в Enterprise Manager, и если да, то указывается местоположение этого параметра в окне Properties.
Параметр locks (блокировки)
SQL Server динамически конфигурирует количество используемых в системе блокировок в соответствии с текущими потребностями. Вы можете задать значение параметра locks для указания максимального количества блокировок, ограничив тем самым количество памяти, которое использует для блокировок SQL Server. По умолчанию задано значение 0, что позволяет SQL Server динамически захватывать и освобождать блокировки в зависимости от изменяющихся требований системы. В SQL Server разрешается использовать для блокировок до 40 процентов всей его памяти. Вам следует оставить для этого параметра принятое по умолчанию значение 0, чтобы SQL Server захватывал блокировки по необходимости. Этот параметр входит в группу дополнительных параметров, и его можно задать только с помощью sp_configure.
Параметр recovery interval (интервал восстановления)
Параметр recovery interval указывает максимальное количество минут, которое может потратить SQL Server для восстановления после аварии. (См. ниже в этой лекции раздел "Контрольные точки" с более подробным описанием того, как действуют контрольные точки.) Время, которое требуется SQL Server для восстановления базы данных, зависит от момента, когда была создана последняя контрольная точка. Поэтому значение recovery interval используется в SQL Server для динамического определения моментов автоматического применения контрольных точек.
Например, когда происходит "чистое" закрытие SQL Server, контрольные точки создаются по всем базам данных, поэтому при перезапуске SQL Server восстановление занимает немного времени. Но если происходит вынужденная остановка SQL Server без "чистого" отключения (из-за отказа источника питания или аварии другого типа), то при повторном запуске SQL Server должен восстанавливать каждую базу данных путем отката всех транзакций, которые не были фиксированы, и повторного выполнения транзакций, которые были фиксированы, но их изменения еще не были записаны на диск к моменту аварии. Если последняя контрольная точка была создана незадолго до аварии системы, то на восстановление уйдет немного времени. Если последняя контрольная точка была создана задолго до аварии системы, это потребует более длительного времени восстановления.
SQL Server определяет, насколько часто нужно создавать контрольные точки, согласно встроенному алгоритму и, как уже говорилось, в соответствии со значением recovery interval. Например, если вы зададите для recovery interval значение 5, то SQL Server будет создавать контрольные точки по каждой базе данных с такой частотой, чтобы восстановление после аварии занимало бы примерно 5 минут. По умолчанию значение recovery interval равно 0, указывая на автоматическое конфигурирование интервала в SQL Server. Если используется это значение по умолчанию, то время восстановления меньше 1 минуты и контрольные точки создаются для активных баз данных приблизительно каждую минуту. Во многих случаях преимущества частого создания контрольных точек теряются за счет снижения производительности, вызываемого созданием контрольных точек. Со временем вам придется снизить количество создаваемых контрольных точек, увеличив значение recovery interval. Выбираемое вами значение будет зависеть от деловых требований, связанных с тем, сколько времени могут ждать пользователи в случае восстановления системы после аварии. Обычно следует использовать значение в интервале от 5 до 15 минут, соответствующее времени восстановления от 5 до 15 минут.
Параметр recovery interval входит в группу дополнительных параметров. Вы можете задать его в Enterprise Manager во вкладке Database Settings (Параметры базы данных) окна Properties в поле Recovery Interval (min) (см. рисунок).
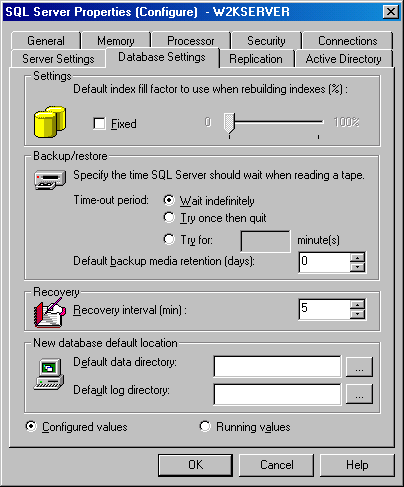
Рисунок 2.1.2.2 – Задание параметра recovery interval
Параметр user connections (количество соединений с пользователями)
SQL Server динамически конфигурирует допустимое количество соединений пользователей с SQL Server. В SQL Server допускается до 32767 соединений с пользователями Задавая значение user connections, отличное от 0, вы указываете максимально допустимое количество одновременных подсоединений пользователей к SQL Server. (Количество допустимых подсоединений пользователей также зависит от ограничений ваших приложений и оборудования.) Количество подсоединений пользователей будет также динамически конфигурироваться вплоть до указанного максимума.
Например, если подсоединяются только 10 пользователей, будет выделено только 10 объектов-соединений с пользователями (user connection). Если достигнуто максимальное значение, а SQL Server требуются новые соединения с пользователями, то вы получите сообщение об ошибке, где указывается, что достигнуто максимальное значение по количеству соединений с пользователями.
В большинстве случаев принятое по умолчанию значение параметра user connections изменять не требуется. Отметим, что для каждого соединения требуется порядка 40 Кб памяти.
Чтобы определить максимальное количество соединений с пользователями, допустимое в вашей системе, вы можете использовать SQL Server Query Analyzer или следующий оператор T-SQL:
SELECT @@MAX_CONNECTIONS
Параметр user connections входит в группу дополнительных параметров. Вы можете задать его в Enterprise Manager во вкладке Connections (Соединения) окна Properties в поле-счетчике Maximum Concurrent User Connections (Максимальное число одновременных соединений с пользователями) (см. рисунок).

Рисунок 2.1.2.3 – Задание параметра user connections
Параметр open objects (количество открытых объектов)
Параметр open objects входит в группу дополнительных параметров; его можно задать только с помощью процедуры sp_configure. Этот параметр определяет максимально допустимое количество одновременно открытых объектов базы данных, таких как таблицы, представления, хранимые процедуры, триггеры, правила и значения по умолчанию. Принятое по умолчанию значение 0 указывает, что SQL Server будет динамически регулировать допустимое количество одновременно открытых объектов в данной системе. Вам следует оставить это значение по умолчанию без изменений. Если вы все же измените его, а SQL Server потребуется больше открытых объектов, чем вы сконфигурировали, то появится сообщение об ошибке от SQL Server, где указывается, что вы превысили допустимое количество открытых объектов. Кроме того, для каждого открытого объекта требуется некоторое количество памяти, поэтому вашей системе может потребоваться большее количество физической памяти, чтобы поддерживать необходимое количество открытых объектов.
Статистика
Статистика по колонкам необходима для повышения производительности запросов в вашей системе. SQL Server может собирать статистическую информацию, касающуюся распределения значений в колонке таблицы. Оптимизатор запросов Query Optimizer затем использует эту информацию для определения оптимального плана исполнения запроса. Статистику можно собирать по двум типам колонок: по тем, что являются частью индекса, и по тем, что не входят в индекс, но используются в предикате запроса (в предложении WHERE). Оставив принятые по умолчанию значения SQL Server для базы данных, вы разрешаете автоматическое создание обоих типов статистики в SQL Server. Статистика по индексированным колонкам создается при создании соответствующего индекса. Статистика по неиндексированным колонкам создается, когда она требуется для какого-либо запроса (только по одной колонке, а не по нескольким, как вы увидите в подразделе "Команда CREATE STATISTICS" этого раздела). Если статистика устарела (не использовалась в течение определенного периода времени), то SQL Server автоматически удаляет ее.
Чтобы создать статистику и по индексированным, и по неиндексированным колонкам, SQL Server использует только выборку данных таблицы, но не все строки таблицы. Это снижает дополнительную нагрузку, связанную с этой операцией, но в некоторых случаях выборка недостаточно хорошо характеризует данные и статистика оказывается не совсем точной.
В Enterprise Manager вы можете активизировать или отключать автоматическое создание статистики по базе данных. Для этого сначала откройте окно Properties этой базы данных. Во вкладке Options вы увидите флажок Auto Create Statistics (Автоматическое создание статистики). (На рисунке этот флажок установлен для базы данных MyDB.) Этот флажок установлен (активизирован) по умолчанию.
В окне Properties соответствующей базы данных вы также увидите флажок Auto Update Statistics (Автоматическое обновление статистики). Этот флажок, который установлен по умолчанию для каждой базы данных, указывает, что SQL Server при необходимости будет автоматически обновлять статистику по колонкам таблицы. Статистику требуется обновлять в тех случаях, когда изменилось большое количество (или большой процент) строк таблицы (посредством операций обновления, вставки и удаления). При большом числе изменений в данных текущая статистика становится менее точной. SQL Server автоматически определяет, когда требуется обновить статистику. Если вы решили отключить автоматическое создание статистики, сбросив этот флажок, то вы должны выполнять эти задачи вручную, чтобы убедиться в нормальной работе вашей базы данных. В следующих разделах описывается, как создавать и обновлять статистику вручную.
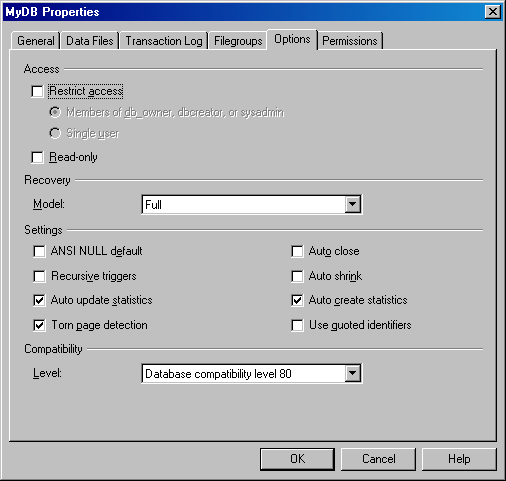
Рисунок 2.1.2.4 – Окно Properties для базы данных MyDB
Команда CREATE STATISTICS
Вы можете создавать статистику по определенным колонкам таблицы вручную с помощью оператора T-SQL CREATE STATISTICS. Создание статистики вручную отличается от автоматического создания в том, что оно позволяет вам объединять несколько колонок, генерируя для комбинации колонок такую информацию, как среднее количество дублированных значений и отличающихся значений. Команда CREATE STATISTICS имеет следующий синтаксис:
CREATE STATISTICS имя_статистики ON
имя_таблицы ( колонка [ , колонка... ] )
[ [WITH [ FULLSCAN | SAMPLE размер PERCENT ]
[ , NORECOMPUTE ]
Вам следует ввести имя для набора статистики, который вы создаете, имя таблицы, а также имя хотя бы одной колонки. Вы можете указать несколько имен колонок для сбора статистики по комбинации колонок. Отметим, что вы не можете указывать для статистики расчетные колонки или колонки с типом данных ntext, text или image. Для сбора статистики можно указывать полное сканирование (FULLSCAN) или выборку данных (SAMPLE). Для полного сканирования требуется больше времени, чем для выборки, поскольку сканируется каждая строка таблицы, но результаты могут оказаться более точными. Используя выборку, вы должны указать процент данных, включаемых в выборку. Ключевое слово NORECOMPUTE указывает, что автоматическое обновление этой статистики отключено, что позволяет использовать статистику, которая уже не отражает текущее состояние данных.
Вам может потребоваться создание статистики по колонкам, которые совместно используются в предикате запроса. Например, вы можете создать статистику по колонкам FirstName (Имя) и LastName (Фамилия) таблицы Employees (Сотрудники) базы данных Northwind для поиска сотрудника по имени и фамилии. Для этого используется следующая последовательность T-SQL:
CREATE STATISTICS name
ON Northwind..Employees (FirstName, LastName)
WITH FULLSCAN, NORECOMPUTE
Этот оператор рассчитывает статистику для всех строк колонок FirstName и LastName и отключает автоматический перерасчет статистики.
Если вы хотите запустить статистику для всех колонок всех таблиц базы данных вручную без ввода операторов CREATE STATISTICS для каждой колонки каждой таблицы, то можете использовать хранимую процедуру sp_createstats. Эта хранимая процедура описана в следующем разделе.
Процедура sp_createstats
Вы можете запустить статистику для всех допустимых колонок всех таблиц пользовательских базы данных с помощью хранимой процедуры sp_createstats. Статистика будет создана для всех колонок, по которым еще не создана статистика. Каждый набор статистики будет создан по какой-либо одной колонке. Процедура sp_createstats имеет следующий синтаксис:
sp_createstats [ 'indexonly' ] [ , 'fullscan' ] [ , 'norecompute' ]
Параметр indexonly указывает, что статистика будет создана только по колонкам, включаемым в индекс. Параметр fullscan указывает, что будет выполнено полное сканирование всех строк, а не случайная выборка; иначе говоря, будет использована выборка 100 процентов данных. Параметр norecompute указывает, что по этой новой статистике будет отключено автоматическое обновление статистики. Новой статистике присваивается имя колонки, по которой она создается.
Команда UPDATE STATISTICS
По умолчанию SQL Server автоматически обновляет статистику. Вы можете отключить эту возможность с помощью команды UPDATE STATISTICS и затем обновлять статистику вручную, чтобы она соответствовала текущему состоянию данных. Эта команда позволяет вам обновлять статистику по индексированным колонкам и неиндексированным колонкам. Возможно, вы создадите сценарий, который будет выполнять команду UPDATE STATISTICS для наиболее часто модифицируемых таблиц, и затем будете периодически запускать этот сценарий как задание SQL Server. Это позволит поддерживать статистику в соответствии с текущим состоянием данных и поддерживать более высокую производительность запросов. Чтобы активизировать или отключить автоматическое обновление для определенной статистики, вы можете использовать хранимую процедуру sp_autostats, которая описывается далее.
Процедура sp_autostats
Используя системную хранимую процедуру sp_autostats, вы можете активизировать или отключить автоматическое обновление определенной статистики. Запуск этой процедуры не приводит к обновлению данной статистики; она просто определяет, должно ли происходить автоматическое обновление статистики. Вызов этой хранимой процедуры происходит с одним, двумя или тремя параметрами: имя таблицы и – дополнительно – флаг и имя статистики. Флаг указывает состояние автоматического обновления и может принимать значения ON (включено) или OFF (отключено). Чтобы вывести текущий статус обновления для всех наборов статистики по определенной таблице (статистика по индексированным колонкам и неиндексированным колонкам), запустите эту команду с именем этой таблицы. Следующая команда выводит этот статус для наборов статистики по таблице Customers:
USE Northwind
GO
sp_autostats Customers
GO
Будет выведено имя каждого набора статистики независимо от значения флага автоматического обновления (ON или OFF) и время последнего обновления. Не обращайте внимания на заголовок первой колонки Index Name (Имя индекса). Он относится ко всем наборам статистики, а не только к индексам. Если вы не отключили вручную обновление для этих наборов статистики, то они будут представлены со статусом ON, поскольку это принятое по умолчанию состояние в SQL Server.
Чтобы отключить автоматическое обновление всех наборов статистики в таблице Customers базы данных Northwind, используйте следующую команду:
USE Northwind
GO
sp_autostats Customers, 'OFF'
GO
Вы можете снова активизировать автоматическое обновление статистики, задав для флага значение ON. Чтобы изменить статус определенного набора статистики или статистики для индекса, включите в обращение соответственно имя набора статистики или имя индекса. Например, следующая команда задает автоматическое обновление статистики для индекса PK_Customers:
USE Northwind
GO
sp_autostats Customers, 'ON', 'PK_Customers'
GO
Статус всех других наборов статистики по таблице Customers не изменится.
Рост файлов
Работая с SQL Server 2000, вы можете конфигурировать файлы данных для их автоматического увеличения по мере необходимости. Это средство полезно, поскольку оно препятствует случайному выходу файлов за пределы допустимого дискового пространства. Однако использование это средства не освобождает вас от обязанности мониторинга размера ваших баз данных и выполнения время от времени процедур планирования мощности. Вы также должны следить за тем, как быстро происходит рост таблиц, чтобы вы могли определить, нужно ли вам выполнять регулярное удаление ненужных, возможно, устаревших данных в некоторых таблицах, чтобы сдерживать рост ваших таблиц. По мере роста количества данных в таблице запросы могут занимать больше времени, что приводит к снижению уровня производительности.
Параметры автоматического роста файлов можно сконфигурировать в Enterprise Manager. Для этого выполните следующие шаги.
В левой панели Enterprise Manager раскройте сервер и затем щелкните на папке Databases (Базы данных). Щелкните правой кнопкой мыши на базе данных, которую вы хотите модифицировать (в данном примере мы будем модифицировать базу данных MyDB), и выберите из контекстного меню пункт Properties, чтобы открыть окно свойств базы данных Properties.
Щелкните на вкладке Data Files (Файлы данных) (см. рисунок), чтобы увидеть свойства файлов данных для этой базы данных. Параметры секции File properties (Свойства файлов) предназначены для того, чтобы вы могли контролировать рост файла данных. Чтобы разрешить автоматический контроль роста файла, установите флажок Automatically grow file (Автоматический рост файла). Используя средство автоматического увеличения файла, вы должны задать ограничения, чтобы воспрепятствовать неконтролируемому росту файла.
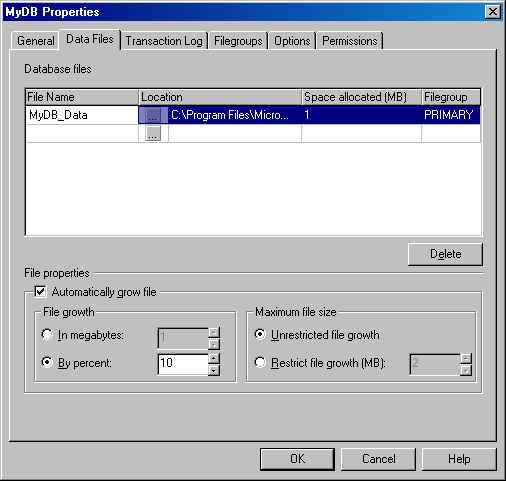
Рисунок 2.1.2.5 – Вкладка Data Files (Файлы данных) окна Properties базы данных MyDB
Максимальный размер файла указывается с помощью параметров секции Maximum file size (Максимальный размер файла). Щелкните на кнопке выбора Restrict file growth (Ограничить рост файла) и введите максимально допустимый размер в прокручиваемом поле-счетчике. Если щелкнуть на кнопке выбора Unrestricted file growth (Неограниченный рост файла), то в дальнейшем вы можете столкнуться с тем, что вся ваша дисковая подсистема заполнена до конца без какого-либо предупреждения, создавая проблемы как для работы, так и производительности.
Степень роста файла задается с помощью параметров секции File growth (Рост файла). Если щелкнуть на кнопке выбора In megabytes (Мегабайты), то после заполнения этого файла данных SQL Server увеличит его размер на указанную величину. Если щелкнуть на кнопке выбора By percent (Проценты), то SQL Server увеличит размер файла данных на указанную величину в процентах от текущего размера.
Щелкните на вкладке Transaction Log (Журнал транзакций) (см. рисунок), чтобы задать параметры автоматического роста для журнала транзакций. Параметры этой вкладки используются так же, как и соответствующие параметры вкладки Data Files. Вы должны задать пределы для файлов журнала транзакций, чтобы воспрепятствовать их неконтролируемому росту.
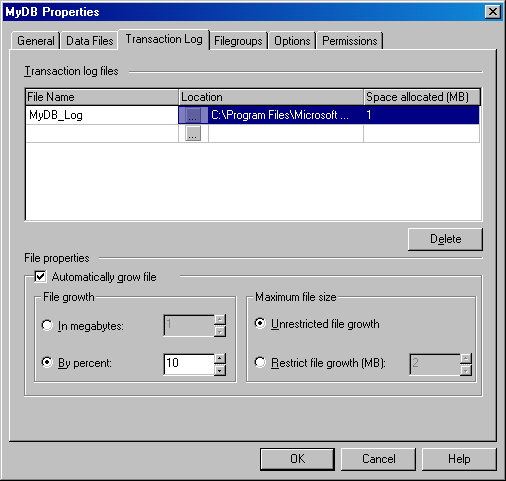
Рисунок 2.1.2.6 – Вкладка Transaction Log (Журнал транзакций) для окна Properties базы данных MyDB
Средство контроля автоматического роста файлов удобно использовать во многих случаях. Просто убедитесь в том, что вы не задали случайно неконтролируемый рост файла, что может привести к использованию этим файлом всего дискового пространства вашей системы.
Контрольные точки
SQL Server выполняет операции с контрольными точками автоматически. Частота создания контрольных точек автоматически рассчитывается в соответствии со значением, которые вы задали для параметра конфигурирования SQL Server recovery interval. Этот параметр указывает длительность вашего ожидания в минутах при восстановлении базы данных после аварии системы. Контрольные точки создаются достаточно часто, чтобы время восстановления системы не превысило указанного вами значения в минутах. Кроме того, контрольные точки автоматически создаются при отключении SQL Server с помощью оператора SHUTDOWN или Service Control Manager (Диспетчер управления службами). Вы можете также создавать контрольные точки вручную с помощью оператора CHECKPOINT.
Если вы хотите, чтобы система работала оптимальным образом и если вы готовы подождать подольше, то можете задать для параметра recovery interval достаточно большое значение, например, 60. Это означает, что при аварии вашей системы автоматическое восстановление будет занимать до 60 минут. При создании контрольных точек выполняется большое количество операций записи на диск, а они могут отбирать часть ресурсов обработки у пользовательских транзакций, увеличивая время отклика на запросы пользователей. Вот почему менее частое создание контрольных точек может помочь в повышении производительности по транзакциям в целом. Конечно, слишком большое значение параметра может приводить к слишком длительному простою после аварии. Обычно для recovery intervalзадают значение от 5 до 15 (минут).
По умолчанию для recovery interval задано значение 0. Это значение указывает, что SQL Server будет определять наилучшие моменты создания контрольных точек, исходя из загруженности системы. Обычно при использовании этого значения по умолчанию контрольные точки создаются приблизительно раз в минуту. Если вы считаете, что они создаются слишком часто, то можете изменить значение recovery interval. Чтобы определить, не слишком ли часто SQL Server создает контрольные точки, используйте флаг трассировки SQL Server -T3502. Это флаг указывает запись информации по контрольным точкам в журнал ошибок SQL Server. Отметим, что контрольные точки создаются по каждой базе данных.
Планы обслуживания баз данных
План обслуживания – это набор задач, которые SQL Server будет автоматически выполнять по вашим базам данных согласно заданному вами расписанию. Целью плана обслуживания является автоматизация важных административных задач и снижение объема ручной работы DBA. Вы можете создавать отдельный план для каждой базы данных, несколько планов для одной базы данных или один план для нескольких баз данных.
Имеются четыре следующие основные категории административных задач, которые вы можете планировать путем создания плана обслуживания.
Оптимизации.
Проверки целостности.
Резервное копирование баз данных.
Резервное копирование журнала транзакций.
Выполнение этих задач имеет важное значение для поддержки хорошо работающей и восстанавливаемой базы данных. Типы оптимизационных задач, которые вы включите в ваш план, будут зависеть от производительности и степени использования вашей базы данных. Выполнение проверок целостности является хорошим средством, чтобы обеспечить согласованность и сохранность базы данных. А регулярное резервное копирование требуется для того, чтобы обеспечить восстанавливаемость базы данных в случае аварии системы или пользовательских ошибок. В силу особой важности операций резервного копирования вам следует разработать стратегию автоматизированного резервного копирования. Мы подробно рассмотрим каждую из этих категорий задач в данном разделе.
Для создания плана обслуживания используется мастер Database Maintenance Plan Wizard. В данном разделе вы узнаете, как использовать этот мастер, а затем узнаете, как выводить на экран задания плана обслуживания и как редактировать этот план.
Использование мастера Database Maintenance Plan Wizard для создания плана обслуживания
Для использования мастера Database Maintenance Plan Wizard выполните следующие шаги.
Запустите этот мастер из Enterprise Manager с помощью одного из следующих методов.
Выберите из меню Tools пункт Database Maintenance Planner (Планировщик обслуживания баз данных).
Щелкните на имени базы данных в левой панели и затем щелкните на New Maintenance Plan (Новый план обслуживания) под заголовком Maintenance (Обслуживание) в правой панели. Если вы не видите заголовка Maintenance, убедитесь в том, что у вас выбран пункт Taskpad (Панель задач) в меню View (Вид) Enterprise Manager. Возможно, вам придется также выполнить прокрутку, чтобы увидеть заголовок Maintenance.
Щелкните на имени базы данных, выберите пункт Wizards (Мастера) из меню Tools, раскройте в появившемся диалоговом окне Select Wizard (Выбор мастера) папку Management (Управление) и затем выберите Database Maintenance Plan Wizard.
Раскройте сервер в левой панели, раскройте папку Management, щелкните правой кнопкой мыши на Database Maintenance Plans (Планы обслуживания баз данных) и затем выберите из появившегося контекстного меню пункт New Maintenance Plan.
Щелкните правой кнопкой мыши на имени соответствующей базы данных, выберите пункт All Tasks (Все задачи) и затем выберите из этого меню Maintenance Plan.
Открыв мастер, вы увидите начальное окно мастера Database Maintenance Plan Wizard (см. рисунок).
Рисунок 2.1.2.7 – Начальное окно мастера Database Maintenance Plan Wizard
Щелкните на кнопке Next (Далее), чтобы появилось окно Select Databases (Выбор баз данных) (см. рисунок). Здесь вы можете выбрать базу или базы данных, для которых хотите создать план обслуживания.

Рисунок 2.1.2.8 – Окно Select Databases (Выбор баз данных)
Щелкните на кнопке Next, чтобы появилось окно Update Data Optimization Information (Обновление информации по оптимизации данных) (см. рисунок). Вы можете выбирать следующие типы оптимизации для базы или баз данных, выбранных на предыдущем шаге.
Reorganize data and index pages (Реорганизация страниц данных и индексов). Этот флажок указывает, что все индексы и все таблицы базы данных будут удалены и воссозданы с использованием указанного коэффициента заполнения (или количества свободного места на каждой странице), что может повысить производительность обновлений. В случае таблиц, предназначенных только для чтения, реорганизация страниц не является необходимостью. В случае таблиц, для которых часто выполняются вставки или изменения, свободное место, которое первоначально было доступно на ваших индексных страницах, постепенно заполняется, и начинает происходить фрагментация страниц. Установите этот флажок, чтобы выполнить повторное создание ваших индексов и образовать свободное место для будущего роста во избежание задержек и нагрузок, вызываемых фрагментацией страниц.
Вы можете выбрать между повторным созданием индексов с исходным количеством свободного места или указать новый процент свободного места на одну страницу. Если задать слишком большой процент, то вы рискуете снизить производительность операций чтения. Установив этот флажок, вы не можете установить следующий флажок – Update statistics used by query optimizer.
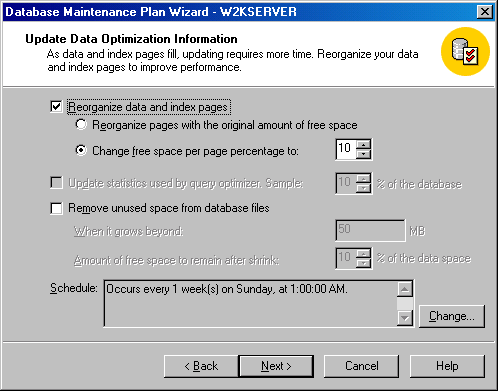
Рисунок 2.1.2.9 – Окно Update Data Optimization Information (Реорганизация страниц данных и индексов)
Update statistics used by query optimizer (Обновление статистики, используемой оптимизатором запросов) При установке этого флажка SQL Server выполнит перерасчет статистики распределения по всем индексам в соответствующей базе данных. SQL Server использует эту информацию для выбора оптимального плана исполнения для запросов. Если вы не изменили принятый по умолчанию параметр для обновления статистики (рассмотренный выше в этой лекции), то SQL Server автоматически генерирует статистику путем выборки небольшого процента данных в таблице, соответствующей каждому индексу.
Флажок этого окна можно использовать для того, чтобы SQL Server выполнял выборку с использованием большего процента данных (указанного вами) или чтобы задать частоту, с которой SQL Server должен обновлять эту статистику, вместо автоматического выбора частоты в SQL Server. Чем больше процент выборки данных, тем точнее будет статистика, но при этом SQL Server потратит больше времени. Эта информация может помочь в повышении производительности при интенсивном изменении данных в индексируемых колонках. Вы можете проверить используемый план исполнения для ваших запросов с помощью анализатора запросов SQL Query Analyzer, чтобы определить, насколько эффективно используются индексы и насколько необходима установка данного флажка. Установив этот флажок, вы не сможете установить предыдущий флажок.
Remove unused space prom database files (Удалить неиспользуемое пространство из файлов базы данных) Этот флажок применяется для удаления неиспользуемого пространства; этот процесс также известен как уплотнение (сжатие) файла (file shrink). Вы можете задать, насколько большим должно стать неиспользуемое пространство, чтобы произошло сжатие файла, а также процент пространства, которое должно остаться свободным после сжатия. Удалив свободное пространство, вы можете использовать DBCC SHRINKFILE для снижения размера данного файла. Если нужно, вы можете сделать его меньше, чем при первоначальном создании. Это позволит использовать для других целей дисковое пространство, которое раньше было занято файлом. Кроме того, сжатие файла за счет удаления неиспользуемого пространства может повысить производительность. В случае таблиц, предназначенных только для чтения, реорганизация страниц не является необходимостью.
Вы можете задать время, за которое должны выполняться эти задачи, щелкнув на кнопке Change (Изменить) и введя новое расписание в появившемся диалоговом окне Edit Recurring Job Schedule (Редактировать расписание повторяющихся заданий) (см. рисунок). Эти задачи следует выполнять в периоды небольшой загруженности системы, например, в выходные дни или ночью, поскольку это требует определенного времени и может увеличивать время отклика на запросы пользователей.
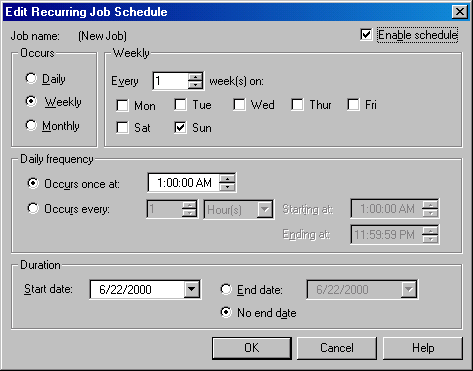
Рисунок 2.1.2.10 – Диалоговое окно Edit Recurring Job Schedule (Редактировать расписание повторяющихся заданий)
Щелкните на кнопке Next, чтобы появилось окно Database Integrity Check (Проверка целостности базы данных) (см. рисунок).
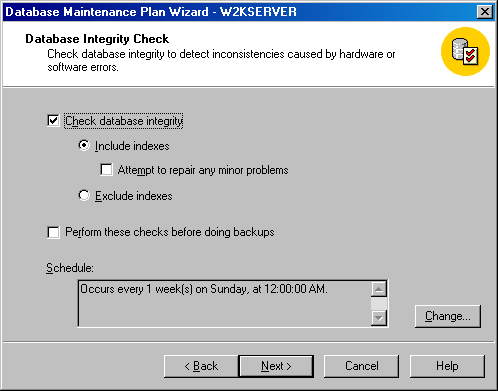
Рисунок 2.1.2.11 – Окно Database Integrity Check (Проверка целостности базы данных)
В этом окне вы можете указать, нужно ли выполнять проверку целостности. При проверке целостности проверяется размещение и структурная целостность таблиц и индексов (если индексы включены в проверку) с помощью команды DBCC CHECKDB. Вы можете указывать, будут ли включаться в проверку индексы, будет ли SQL Server пытаться устранить небольшие проблемы (рекомендуется устанавливать этот флажок) и должны ли все эти проверки целостности выполняться перед резервным копированием. Если вы указали, что выполнение проверок должно происходить перед резервным копированием, то в случае обнаружения какой-либо проблемы это резервное копирование выполняться не будет. Щелкните на кнопке Change, чтобы изменить время, когда будут выполняться эти задачи. Проверка целостности может занимать несколько часов в зависимости от размера ваших баз данных, поэтому следите за тем, чтобы они не планировались на периоды интенсивного использования баз данных. Проверки должны проводиться регулярно, возможно, ежемесячно или еженедельно, или перед резервным копированием баз данных.
Щелкните на кнопке Next, чтобы появилось окно Specify the Database Backup Plan (План резервного копирования баз данных) (см. рисунок). В этом окне вы указываете, будет ли создаваться план автоматизированного резервного копирования. (Рекомендуется создавать такой план.) Чтобы активизировать автоматическое резервное копирование, установите флажок Back up the database as part of the maintenance plan (Выполнять резервное копирование как часть плана обслуживания). Вы можете указать для SQL Server проверку целостности резервной копии по окончании копирования. SQL Server выполняет это для подтверждения того, что резервная копия создана полностью и все тома резервной копии доступны. Вы можете также указывать, где должна храниться резервная копия – на ленте или диске. Щелкните на кнопке Change, чтобы изменить время, когда будет выполняться резервное копирование.
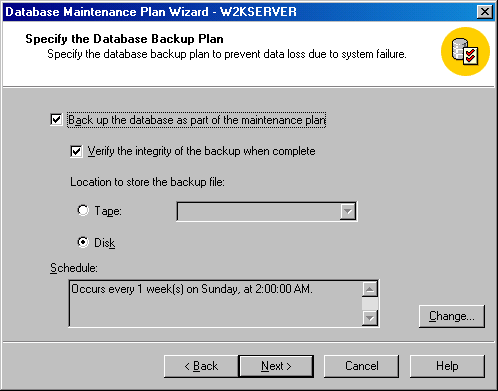
Рисунок 2.1.2.12 – Окно Specify the Database Backup Plan (План резервного копирования баз данных)
Щелкните на кнопке Next, чтобы появилось окно Specify Backup Disk Directory (Дисковая директория для резервной копии) (см. рисунок).
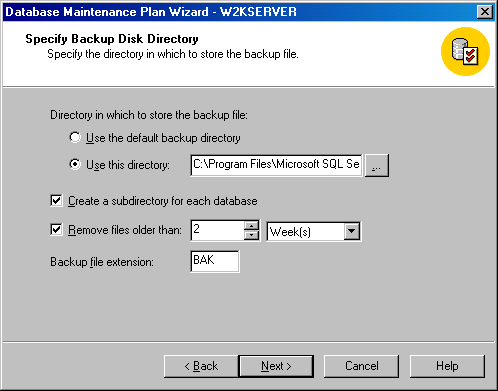
Рисунок 2.1.2.13 – Окно Specify Backup Disk Directory (Дисковая директория для резервной копии)
Это окно появляется, только если вы задали в предыдущем окне резервное копирование на диск; оно не появится, если вы задали резервное копирование на ленту. В этом окне вы можете задать местоположение файла резервной копии или использовать принятую по умолчанию директорию для резервной копии. Если у вас несколько баз данных, для которых выполняется резервное копирование (таких как master, model, msdb), то вы можете выбрать размещение резервной копии каждой базы данных в ее собственной поддиректории, чтобы поддерживать определенную организацию файлов резервных копий. Вы можете выбрать автоматическое удаление файлов резервных копий по истечении определенного срока хранения, чтобы освобождалось пространство на дисках, а также можете задавать расширение имен файлов, которое хотите использовать для файлов резервных копий.
Щелкните на кнопке Next, чтобы появилось окно Specify the Transaction Log Backup Plan (План резервного копирования журнала транзакций) (см. рисунок).
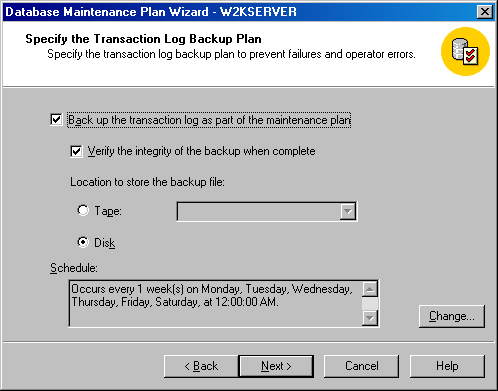
Рисунок 2.1.2.14 – Окно Specify the Transaction Log Backup Plan)
Это окно устроено аналогично окну Specify the Database Backup Plan, но параметры этого окна используются для создания плана резервного копирования журнала транзакций. Резервное копирование журнала транзакций должно происходить между резервными копированиями вашей базы данных. Для восстановления любых изменений, выполненных с момента последнего резервного копирования базы данных, используется резервная копия журнала транзакций. Иначе говоря, резервные копии журнала транзакций позволяют вам восстанавливать данные между резервными копированиями базы данных.
Если у вас выбрано сохранение резервных копий на диске, то следующим будет окно Specify Backup Disk Directory, в котором вы задаете информацию о местоположении файла резервной копии.
Щелкните на кнопке Next, чтобы появилось окно Reports to Generate (Генерируемые отчеты) (см. рисунок). В этом окне вы можете выбрать создание отчета, содержащего результаты выполнения задач плана обслуживания. Этот отчет содержит подробности выполненных шагов и любые возникшие ошибки. В этом окне вы также задаете местоположение для сохранения отчета, а также можете задать удаление отчетов через определенный период времени и отправку отчета по электронной почте указанным адресатам.
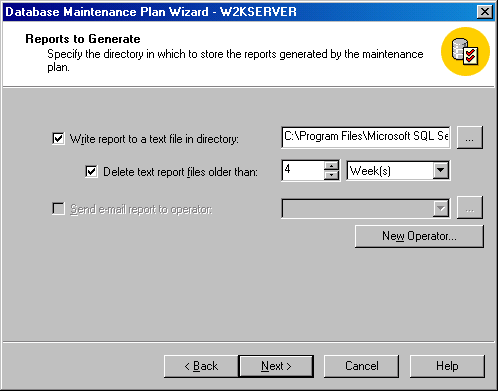
Рисунок 2.1.2.15 – Окно Reports to Generate (Генерируемые отчеты)
Щелкните на кнопке Next, чтобы появилось окно Maintenance History (Журнал обслуживания) (см. рисунок). Здесь вы можете выбрать запись отчета с журналом (историей) обслуживания в таблицу базы данных на локальном сервере и задать максимальный размер этого отчета. Вы можете также указать запись этого отчета на удаленный сервер и задать максимальный размер этого отчета.
Щелкните на кнопке Next, чтобы появилось окно Completing the Database Maintenance Plan Wizard (Завершение работы мастера создания плана обслуживания баз данных) (см. рисунок). В этом окне показана сводка вашего плана обслуживания. План получит имя по умолчанию, но вы можете задать другое имя, набрав его в текстовом поле Plan Name (Имя плана). Проверьте эту сводку и пройдите в обратном направлении, если хотите изменить какие-то параметры. Если план вас устраивает, щелкните на кнопке Finish (Готово).
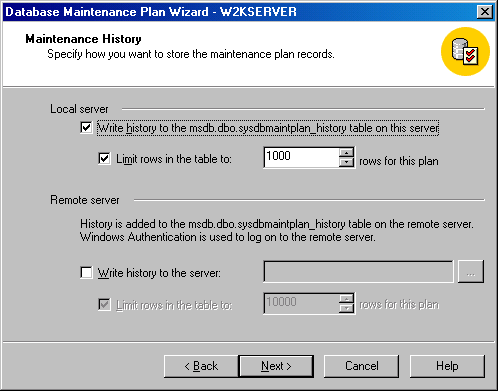
Рисунок 2.1.2.16 – Окно Maintenance History (Журнал обслуживания)
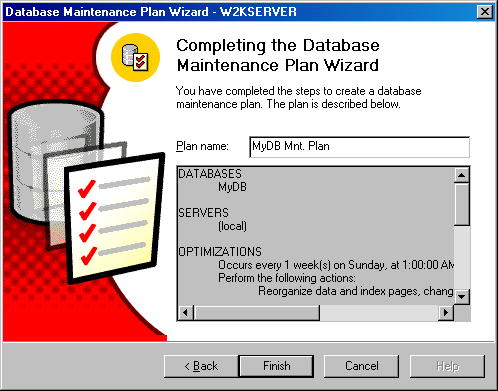
Рисунок 2.1.2.17 – Окно Completing the Database Maintenance Plan Wizard (Завершение работы мастера создания плана обслуживания баз данных)
Отображение заданий плана обслуживания
Для нашего примера плана обслуживания мы создали по одной задаче в каждой из четырех категорий. Чтобы увидеть список этих заданий (запланированных задач), раскройте папку Management в левой панели Enterprise Manager, раскройте агент SQL Server Agent и затем щелкните на строке Jobs (Задания) (см. рисунок).
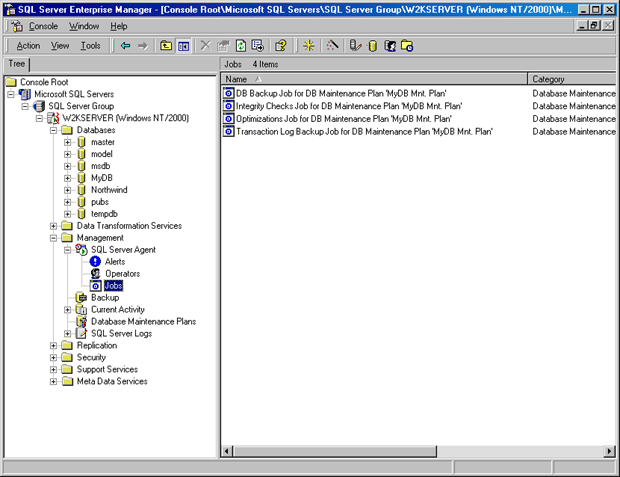
Рисунок 2.1.2.18 – Задания, созданные в нашем примере плана обслуживания
Редактирование плана обслуживания
Чтобы отредактировать план обслуживания, щелкните в левой панели Enterprise Manager на имени базы данных, для которой создан план обслуживания, и затем выберите имя этого плана под заголовком Maintenance в правой панели. Возможно, вам потребуется выполнить прокрутку, чтобы увидеть заголовок Maintenance. Появится диалоговое окно Database Maintenance Plan (см. рисунок).
Во вкладке General вы можете указывать, какие базы данных будет затрагивать ваш план обслуживания. В других вкладках вы можете изменять значения параметров, которые сконфигурировали с помощью мастера Database Maintenance Plan Wizard. Закончив редактирование плана, щелкните на кнопке OK. Ваш план теперь начнет выполняться в соответствии с указанным вами расписанием.

Рисунок 2.1.2.19 – Вкладка General диалогового окна Database Maintenance Plan