

Режимы передачи данных mpi.
Реализуется в стандартном режиме, т.е. процесс –отправитель блокируется, после завершения можно использовать буфер опять, возможные состояния сообщения:
п ринадлежность
процессу-отправителю;
ринадлежность
процессу-отправителю;
состояние передачи;
принадлежность процессу-получателю;
принято, завершится после Recv;
Синхронный вызов:
MPI_Send Стандартный(Standart)–обеспечивается функциейMPI_Send, на время выполнения функции процесс-отправитель сообщения блокируется, после завершения функции буфер может быть использован повторно, состояние отправленного сообщения может быть различным сообщение может располагаться в процессе-отправителе, может находиться в процессе передачи, может храниться в процессе-получателе или же может быть принято процессом-получателем при помощи функции MPI_Recv.
MPI_Ssend Синхронный (Synchronous) режим–завершение функции отправки сообщения происходит только при получении от процесса-получателя подтверждения о начале приема отправленного сообщения.
MPI_Rsend – самый быстрый вариант обмена, выполнится, если к моменту вызова инициирована операция приема сообщения ( если Recv не вызван, то Rsend считается ошибкой)
MPI_Bsend – завершится во всех случаях, если неинициирована, в буфер помещает сообщение и завершается, если инициирована операция приема - просто завершится, так как сообщение передано. Для его использования нужно создать буфер:
int MPI_Buffer_attach (void*buf, int size)

выделить память
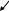 int
MPI_Buffer_detech (void*buf, int size)
int
MPI_Buffer_detech (void*buf, int size)
очистить память
Режимы передачи данных
Режим передачи по готовности формально является наиболее быстрым, но используется остаточно редко, т.к. обычно сложно гарантировать готовность операции приема.
Стандартный и буферизованный режимы также выполняются достаточно быстро, но могут приводить к большим расходам ресурсов (памяти), могут быть рекомендованы для передачи коротких сообщений.
Синхронный режим является наиболее медленным, т.к. требует подтверждения приема. В тоже время, этот режим наиболее надежен – можно рекомендовать его для передачи длинных сообщений.
Лекция 5
Всегда используется буфер и должны быть выполнены следующие операции:
int MPI_Pac_size(int count, MPI_Datatype type, MPI_Comm comm, int *size ); - функция возвращает размер буфера.
+ предопределенная константа (к длине буфера)
MPI_BSEND_OVERHEAD – служебная область сообщений.
Необходимо учесть: в буфере могут располагаться несколько сообщений.
Распределение памяти под буфер.
malloc, calloc.
Для применения буферизованного режима передачи может быть создан и передан MPI буфер памяти, используемая для этого функция имеет вид:
int MPI_Buffer_attach(void *buf, int size),
где
buf — адрес буфера памяти;
size — размер буфера.
Перессылки (использование буфера).
После завершения работы с буфером он должен быть отключен от MPI при помощи функции:
int MPI_Buffer_detach(void *buf, int *size),
где
buf — адрес буфера памяти;
size — возвращаемый размер буфера.
Освобождение памяти.
free();
Используя соответствующие режимы Bsend, Rsend можно исключить задержки, блокировки процесса-отправителя не будет.
Если запрос на прием выполнен, а сообщение не передано, то процесс получателя блокируется – MPI_Recv.