

Структурная схема сау.
Как правило, САУ используется в тех системах где в качестве УО используется компьютер, к-рый с помощью программы (Iвх) выдает результат обработки инф-ии, обычно физический сигнал. Это сигнал управления УО, к-рый ч/з преобразователь (ПР1) приводит в действие ИО, возвращающий ОУ в заданное программой компьютера состояние. Состояние, меняющиеся под внешним воздействием (V), определяет значение сигнала обратной связи (Iос), к-рое ч/з преобразователь (ПР2)поступает в компьютер. Преобразователи необходимы для изменения уровней или природы, проходящих ч/з них сигналов, т.к. элементы системы могут быть различны по своей физической сути.
С ростом и усложнением производства ОУ приобретает характер сложных и больших систем, имеющих большое число элементов и подсистем связи, м/у к-рыми невсегда ясны, а критерии функционирования не обладает четкостью. В этом случае использовать работы теории автоматизированного управления (ТАУ) не удается в полной мереи в контур управления включается лицо, принимающее решения (ЛПР). Наличие ЛПР в контуре управления является отличительной чертой АСУ, к-рые в случае применения организационно-экономическом управлении называют экономическими инф-ными системами (ЭИС).
Автоматизированное управление применяется в том случае, когда нельзя реализовать автоматическое управление.
Л П Р
Iвых
Iу
ИО
ПО
ЭВМ
U

ОУ
Iос
Iвх
V
Структурная схема
ЭИС
Как видно из рисунка, ЛПР получает Iос осведомляющую его о состоянии ОУ, обращается к ЭВМ (поток Iвх), имеющее определенное ПО и выбирающая рекомендации к принятию решения (поток Iвых). На основе анализа предложенных ЭВМ альтернатив, ЛПР принимает решение, к-рое в виде упарвляющей инф-ии Iу поступает в ИО переводя его в необходимое состояние. Например, министр (ЛПР), получив инф-ию о состоянии отрасли (ОУ), после обработки инф-ии на ЭВМ и просчета набора вариантов поведения в сложившейся ситуации, принимает решение, к-рое реализуется аппаратом министерства (ИО) в управляемой отрасли производства.
ИНФОРМАЦИОННЫЕ МОДЕЛИ.
Важным инструментом исследования систем является метод моделирования. Суть метода состоит в том, что исслндуемый объект заменяется моделью, т.е. некоторым другим объектом, сохраняющим свойства реального объекта, но более удобным для исследования и использования. Различают физические и абстрактные модели. При изучение АИС наиболее распространены абстрактные модели.
Инф-ная модель – это отражение предметной области в виде инф-ии.
Предметная область в ИТ представляет собой часть реального мира, к-рая исследуется или используется. Отражение предметной области в ИТ представляется моделями нескольких уровней: концептуальная (КМ) обеспечивает интегрированное представление о предметной области (техническое задание, план производства и т.д.) и имеет слабо формализованный характер, логическая (ЛМ) формируется из КМ путем выделения конкретной части, подлежащей, например, дестабилизации или формализации, ЛМ, формализующаяся на языке математической взаимосвязи в предметной области, называют математической (ММ); с помощью математических методов ММ преобразуется в алгоритмическую модель (АМ), задающую последовательность действий, реализующих достижения поставленной цели управления, на основе АМ создается машинная программа (П) являющаяся той же АМ только представленной в форме, понятной ЭВМ.
Предметная область
КМ
ЛМ
ММ
АМ
П
Выделение ИМ разных уровней абстракции позволяет разделить сложный процесс отображения "предметная область - программа" на несколько итеративных более простых отображений.
ЧЕЛОВЕК И ИТ.
При производство продуктов труда человек всегда управляет орудием труда в процессе их взаимодействия на предмет труда. При воздействии орудия труда на предмет человек подсознательно сравнивает результат с хранимой в памяти концептуальной моделью в зависимости от результата происходит управление орудием труда. Например, система управления: объект управления – земля, ИО – лопата, УО – мозг, т.е. действует классическая модель системы управления.
С усложнением производства, т.е. объекта управления(ОУ) и их КМ объемы инф-ии и Iос возрастают и человеческая возможность в их переработке исчерпывается. На помощь приходят технические средства, ускоряющие обработку инф-ии, это так называемые средства вычислительной техники (СВТ). Возникает, таким образом, самостоятельный, дополнительный, инф-ный контур, помогающий человеку обрабатывать инф-ию и вырабатывать управляющую инф-ию (Iу).
ИО
Iу
Iвых
Ч
СВТ
U

ОУ
Iос
Iвх
Появление контура дополнительной обработки инф-ии и есть начало возникновения ИТ. Совершенствование ВМ, ПО, математических моделей и методов позволило создать автоматизированные экономико-инф-ные системы, в к-рых четко обозначается контур инф-ных технологий.


ИО
Iу
Iвых
ЭВМ
Ч
U
ЧММ

АМ
ОУ
Iос
Iвх

КМ
ОМУ
ПО
ИТ
ИТ в экономических
и технических системах.
Из рисунка видно, что ИТ состоит из инф-ных моделей разного уровня абстракции и ЭВМ. На вход ИТ поступает инф-ия от человека Iвх, формирующаяся на основе инф-ии Iос от ОУ. Инф-ия сравнивается с концептуальной моделью (КМ) ОУ, реакция на результат сравнения определяется общей моделью управления (ОМУ), к-рая делится на частные математические модели (ЧММ). Набор ЧММ описывает возможные состояния ОУ и тактику управления в экономической системе. Эта тактика реализуется ч/з алгоритмическую модель (АМ), характерную в программах для ЭВМ. В результате ЭВМ выдает инф-ию Iвых, представляющую собой рекомендации по управлению ОУ в данной ситуации. Таким образом человек в АСУ является центральным м объединенным звеном двух контуров, а именно управления (Ч – ИО - ОУ) и ИТ.
ПРОЦЕСС ПРИНЯТИЯ РЕШЕНИЯ.
В АСУ, не смотря на наличие контура ИТ, ответственность за принятие решений возлагается на человека, т.е. решение принимает человек, а ИТ помогает ему в этом. Процесс принятия решения человеком очень сложный, иногда в этот процесс включаются такие механизмы, к-рые невозможно предусмотреть и реализовать. При принятии решения человек может учитывать и моральные традиции, и человеческие взаимоотношения, вот почему при управлении социально-экономическими системами, т.е. при организационно-экономическом управлении, процесс принятия решения не может быть осуществлен без решения человека.
Iвх
Iу



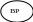
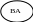
ПЗ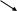
Iос
Фазы процесса
принятия решений
Здесь показана взаимосвязь фаз процесса принятия решения. Человек на основе анализа (АИ) осведомляющей инф-ии и обратной связи, инф-ии Iвх от КМ ОУ производит постановку задач (ПЗ), решение к-рых должно позволить наилучшим образом управлять объектом. Однако решений или альтернатив всегда несколько, следовательно далее идет стадия генерации альтернатив (ГА), т.е. выдвижений возможных решений и задач. Управление ведется всегда с определенной целью, поэтому решение определенной задачи должно согласовываться с общей и частной целью в данной ситуации, следовательно, выбрать альтернативу невозможно если нет критерия выбора, таким образом, следующая фаза выбор критерия (ВК) поставленной задачи. На этом этапе происходит анализ альтернатив (АА), производиться их исследование по выбранному критерию, а далее окончательный выбор одной из них (ВА), наилучшим образом удовлетворяющая критерию выбора. Выбранная альтернатива анализируется и выдается окончательное решение (ВР), принимающее в организационных системах вид потока управляющей инф-ии (Iу).
Если рассматривать фазы принятия решения относительно возможности их автоматизации на ИТ, то только АИ, ГА и АА по выбранному критерию удается автоматизировать в достаточной мере. Для этого необходимо, чтобы в ЭВМ находились модели поставленной задачи, с помощью к-рых возможно было быстро посчитать результаты решений по различным альтернативам исходных данных и критериев. Желательно, чтобы ЛПР умел использовать средства ИТ. Большое значение для принятия верного решения имеет автоматизация базы обработки и анализа инф-ии, поступающей с потоками Iос и Iвх. Для принятия решения всегда может потребоваться дополнительная инф-ия, несодержащаяся в этих потоках, в этом случае имеет значение исполнительный орган ЛПР, к-рое в целях оперативности должно быть организовано с помощью средств ИТ (базы и банки данных).
ИНФОРМАТИКА И ИТ.
Информатика как наука занимается изучением инф-ных процессов и методов их автоматизации на основе программно-аппаратных средств и средств связи.. исторически информатика изучала инф-ию и способы ее структуризации, систематизации, хранения и распространения. Появление вычислительной техники (ВТ) позволило автоматизировать часть операций.
Дальнейшее изучение процессов возникновения инф-ии, ее структуризации, передачи, обработки и представления потребовало создания специального аппарата, позволяющего описывать, анализировать, систематизировать различные фазы инф-ных процессов (ИП). Так возник аппарат инф-ного моделирования. Наличие частных моделей ИП позволило целенаправленно использовать средства ВТ и связи, к-рые совершенствовались для большего удовлетворения потребностей инф-ии.
Начиная с 80-х гг. ХХ в. различные фазы преобразования инф-ии стали рассматриваться как единый ИП, направленный на удовлетворение инф-ных потребностей человека. В этом проявляется выход инф-ии на глобальный уровень, позволяющий понять, что человечество осознало инф-ию как ресурс общества, а информатику как науку развитие к-рой позволяет полное использование ресурса.
С информатикой связано решение новых проблем человечества:
создание инф-ной модели мира
расширение творческого аспекта человечества
переход к безбумажной информатике
доступность инф-ного ресурса каждому члену общества
В настоящее время информатика приобрела многоаспектных характер в ней соединены глобальность и конкретность применения, методов формализации и физической реализации.
При моделировании ИП и его фаз выделяют 3 уровня:
Концептуальный, определяющий содержание и структуру предметной области.
Логический, на к-ром производится формализация модели
Физический, обеспечивающий способ реализации инф-ной модели в техническом устройстве.
Такой подход применяется при изучении информатики, в этом случае можно выделить следующие уровни инф-ии: физический, логический, прикладной (пользовательский). На физическом уровне инф-ка занимается аппаратно-программными средствами ВТ средствами связи, к-рые представляют ее фундамент и позволяет физически реализовать ее логический и прикладные уровни. На логическом изучается технология переработки инф-ных ресурсов в целях получения новой инф-ии на базе ВТ и средств связи, т.е. логический уровень – это ИТ. Прикладной уровень посвящен изучению использования инф-ной технологии при создании и эксплуатации систем, в к-рых преобладающие процессы это инф-ные. Таким образом, ИТ – это логический и прикладные уровни инф-ки.
АИТ имеет свои цели, методы и средства реализации, их содержание состоит в следующем. Цель АИТ является создание из инф-ного ресурса качественного инф-ного продукта, удовлетворяющего требованиям пользователя. Методы АИТ – методы обработки и передачи данных. Средства АИТ – это математические, программные, инф-ные, технические и другие.
При таком определении целей средств и методов под АИТ понимают целостную технологическую систему, обеспечивающую целенаправленное создание, передачу, хранение и отображение инф-ного продукта (данных, идей, знаний) с наименьшими затратами и в соответствии с закономерностями той инф-ной среды, где развивается технология. Практическое приложение методов и средств обработки может быть различна, поэтому выделяют глобальную, базовую и конкретные ИТ. Глобальная ИТ включает модели, методы и средства, формализующие и позволяющие использовать инф-ный ресурс общества. Базовая ИТ предназначена для определенной области применения (производство, научное исследования и т.д.). конкретные ИТ реализуют обработку данных при решении функциональных задач пользователя.
СТРУКТУРА БАЗОВОЙ ИТ.
Базовой называется ИТ, ориентированная на определенную область применения. Любая ИТ слагается из взаимосвязанных ИП, каждый из к-рых содержит определенной набор процедур, реализуемых с помощью инф-ных операций. ИТ выступает как система каждый элемент которой подчиняется общей цели – получение качественного инф-ного продукта из исходного инф-ного ресурса в соответствии с поставленной задачей. Как и базовая ИТ в целом так и отдельный ИП может быть представлен тремя уровнями: концептуальным, логическим, физическим. Концептуальный определяет содержательный аспект ИТ или процесса. Логический отображается в формализованном (модельном) описании. Физический раскрывает программно- аппаратную реализацию ИТ и ИП.
Концептуальный уровень.
При производстве инф-ного продукта исходный инф-ный ресурс в соответствии с поставленной задачей подвергается в определенной последовательности различным преобразованиям. Динамика этих преобразований отображается в протекающих инф-ных процессах таким образом, ИП – это процесс преобразования инф-ии. В результате инф-ия может изменить и содержание и форму представления, причем как в пространстве, так и во времени. Фазы преобразования инф-ии ИТ достаточно многочисленны, однако если провести структуризацию, выделив крупные структуры такие как процессы и процедуры, то концептуальная модель базовой ИТ может быть представлена следующей схемой.
Процессы
Процедуры

Сбор
Подготовка
Телефон
Почта
Курьер


Передача
Ввод

Инф-ия

Данные



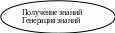
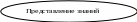

В этой схеме в левой части находится блок ИП, а в правой блоки процедур. Блок в виде прямоугольника отображает процесс или процедуру, в к-рой протекают ручные и традиционные операции. Овальная форма соответствует автоматическим операциям, производимым с помощью технических средств. В верхней части схемыИП и процедуры осуществляют преобразование инф-ии, имеющей яркое смысловое содержание, синтаксический аспект находиться на втором месте. В этом сдучае говорят о преобразовании собственной инф-ии. В нижней части происходит преобразование данных, т.е. инф-ии представленной в машинном виде виде, на этом уровне преобладает синтаксический аспект инф-ии. Технология переработки инф-ии начинается с формирования инф-ного ресурса, к-рый после определенных преобразований должен превратится в инф-ный продукт. Формирование инф-ного ресурса (получение исходной инф-ии) начинается с процесса сбора инф-ии, к-рая должна в инф-ном плане отобразить предметную область, т.е. объект управления и исследования (его характеристики, параметры, состояния и т.п.). Для ее оценки по полноте, непротиворечивости, достоверности и ее последующих преобразований должна быть соответствующим образом подготовлена (осмыслена и структурирована). Инф-ия может быть передана после подготовки для дальнейшего преобразования традиционными способами, а может быть подвергнута процессу преобразования в машинном виде, т.е. процессу ввода. Процессы сбора, подготовки, ввода в ИТ организационно- экономических систем (ОЭС) по своей организации являются ручными.
Процесс ввода преобразует инф-ию в данные, имеющие формы цифровых кодов, реализуемых на физическом уровне с помощью различных физических представлений (магнитный, электрический и т.д.). следующие за вводом инф-ные процессы производят уже преобразование данных в соответствии с задачей. Эти процессы протекают в ЭВМ или организуются ЭВМ под управлением различных программ, к-рые и позволяют так организовать данные, что после вывода из ЭВМ результат обработки представляет собой наполненную смыслом инф-ию о результате решения задачи. При преобразовании данных можно выделить четыре инф-ных процесса и соответствующие им процедуры: процесс обработки, процесс обмена, процесс накопления, процесс представления данных.
Процесс обработки данных связан с преобразованием значений и структур данных, а также преобразование в форму удобную для человеческого восприятия, т.е. отображения. Процедура преобразования данных осуществляется по определенному алгоритму ЭВМ с помощью набора машинных операций. Процедуры отображения переводят данные из цифровых кодов в изображение (текстовое, графическое, звуковое).
Инф-ный процесс обмена предполагает обмен данными м/у процессами ИТ. Процесс обмена связан взаимными потоками данных со всеми ИП на уровне переработки данных. При обмене можно выделить следующие процедуры: процедуры передачи данных по каналам связи, сетевые процедуры, позволяющие осуществить организацию вычислительной системы. Процедура передачи данных реализуется с помощью кодирования, декодирования, модуляции, демодуляции, согласования и усиления. Процедуры организации сети включают в себя в качестве основных процедуры по коммуникации и маршрутизации потоков данных. Процесс обмена позволяет, с одной стороны, подавать данные м/у источником и получателем, а с другой стороны, объединять инф-ию многих ее источников.
Процесс накопления позволяет так организовать инф-ию в форме данных, что позволяет ее долго хранить постоянно обновляя и при необходимости извлекать в заданном объеме и по заданным признакам. Процедуры процесса накопления состоят в хранении и актуализации данных. Хранение предполагает существование такой структуры расположения в памяти ЭВМ, к-рое позволило бы быстро накапливать данные по заданным признакам и осуществлять их поиск. В настоящее время ЭВМ имеет два вида запоминающих устройств: оперативное, внешнее. Их физическая природа различна, поэтому их различают по организации структур хранения данных. Можно выделить операции по организации хранения данных и их поиска в оперативной и внешней памяти ЭВМ. В процессе накопления важной процедурой является их актуализация. Под актуализацией понимается поддержание хранящихся данных на уровне соответствующем инф-ным потребностям решаемых задач в системе где организована ИТ. Актуализация осуществляется с помощью добавления новых данных к уже хранимым, корректировки, изменении значения элементов данных и их уничтожении если данные устарели и не могут быть использованы в функционировании задач системы.
Процесс представления знаний включен в базовую ИТ как основной, т.к. высшим продуктом ИТ являются знания. Формирование знаний как высшего инф-ного продукта до недавнего времени являлось прерогативой человека. Однако оказать помощь человеку при решении трудно реализуемых задач может автоматизированный процесс представления знаний. В процессе объединяются процедуры формализации знаний их накоплении в формализованном виде и генерации,( т.е. вывода новых знаний) в соответствии с поставленной задачей на основе накопленных. Вывод новых знаний это эквивалент решения задачи, к-рую нельзя представить в формализованном виде. Процесс представления знаний состоит из процедур получения формализованных знаний и процедур генерации новых знаний из полученных. Практическая реализация процессов представления знаний с помощью ЭВМ еще не достигла широкого применения в ИТ, это связано как с поисками форм представления знаний теории искусственного интеллекта так и практическими трудностями при создании баз знаний.
В зависимости от решаемых задач удельный вес ИП различен.
Логический уровень.
Логический уровень ИТ представляет собой комплекс взаимосвязанных операций, формализующих ИП при технических преобразованиях инф-ии и данных. Формализуется в виде моделей представления ИТ, позволяет связать параметры ИП, а это обозначает возможность реализации управления ИП и процедурами.
Пояснения к схеме.
МПО – модель предметной области
ОМУ – общая модель управления
МРЗ – модель решаемых задач
Л - логическая
А - алгоритмическая
С - семантическая
Ф - фреймовая
И - интегральная
ОВП – организация вычислительного процесса
ПД – преобразование данных
ОД – отображение данных
М - маршрутизация
К - коммутация
П - передача
КСБ – концептуальная схема инф-ной базы
ЛСБ – логическая схема инф-ной базы
ФСБ – физическая схема инф-ной базы
Л
С
А
Ф
И
МПО

ОМУ

МРЗ





КСБ
ОВП
М

ЛСБ
ПД
К
ОД
ФСБ
П

В зависимости от области применения и назначения модели, ИП конкретизируются, а некоторые могут и отсутствовать. Если ИТ проектируется не на объединенную сеть АРМ процесс обмена данными и соответственно его модели будут отсутствовать. Наибольший эффект ИТ дает тогда когда в его составе используется весь набор ИП.
На основе модели предметной области (МПО), характеризующей ОУ создается общая модель управления (ОМУ), а из нее вытекает модели решаемых задач (МРЗ). Т.к. решенные задачи ИТ имеют в своей основе имеют различные ИП, то на передний план выходит модель организации ИП, призванная на логическом уровне увязать эти процессы и решение задач управления. При обработке данных формируется четыре основных ИП: обработка, обмен, накопление представление знаний.
Модель обработки данных включает в себя формализованное описание процедур организации вычислительного процесса (ОВП), преобразование данных (ПД) и их отображение (ОД).
Под ОВП понимается управление ресурсами компьютера (память, процессор, внешние устройства) при решении задач обработки данных. Эта процедура формализуется в виде программ и алгоритмов системы управления компьютером. Комплексы таких алгоритмов и программ получили название ОС. ОС выступает посредником м/у ресурсами компьютера и прикладными программами, организуя их работу.
Процедуры преобразования данных (ПД) на логическом уровне представляет собой алгоритмы и программы обработки данных и их структур. Сюда включаются стандартные процедуры такие как сортировка, поиск, создание и преобразование структур данных, а также нестандартные, обусловленные алгоритмами и программами ПД при решении конкретных инф-ных задач.
Моделями процедуры отображения данных (ОД) являются компьютерные программы преобразования данных, представляющих машинными кодами воспринимаемую человеком инф-ию, несущую смысловое содержание. Данные могут быть отображены в виде текстовой инф-ии, звука, графиков с использованием средств мультимедия, к-рые интегрируют в компьютере все основные способы отображения.
Модель обмена данными включают в себя формальное описание процедур, выполняемых вычислительной сетью: передачи (П), маршрутизации (М), коммуникации (К). Именно они и составляют инф-ный процесс обмена. Для качественной работы сети необходимо формальное соглашение м/у пользователями, что реализуется в виде протоколов сетевого обмена. В свою очередь передача данных осуществляется при помощи кодирования. На основе модели обмена производится синтез обмена данными, при к-ром оптимизируется типология и структура вычислительной сети, методы коммуникации протоколы и процедуры доступа, адресации и маршрутизации.
Модель накопления данных формирует описание инф-ной базы, к-рая в компьютерном виде представляет БД.
Процесс перехода от инф-ного (смыслового) уровня к физическому отличается трехуровневой системой моделей представления инф-ной базы: концептуальной, логической, физической. КСБ описывает инф-ное содержание предметной области, т.е. какя и каком объеме инф-ия должна накапливаться при реализации инф-ной технологии. ЛСБ должна формализовано описать ее структуру и взаимосвязь элементов инф-ии при этом используются различные подходы: реляционный, иерархический, сетевой. Выбор подхода и определяет СУБД, к-рая в свою очередь определяет физическую модель данных – физическую схему инф-ной базы (ФСБ), описывающую методы размещения данных и доступа к ним на машинных носителях инф-ии.
В современных ИТ формирование модели предметной области и МРЗ производится человеком, что связано с трудностями формализации этих процессов. По мере развития теории и практики интеллектуальных систем становиться возможным формализовать человеческие знания. Модель представления знаний включается в систему моделей, позволяющих проектировщику в автоматическом режиме формировать МПО, а также МРЗ. Наличие этих моделей поможет пользователю выбрать необходимую модель задачи и решить ее с помощью ИТ. Модель представления знаний может быть выбрана в зависимости от предметной области и вида решаемых задач. Сейчас используются такие модели как: логические (Л), алгоритмические (А), фреймовые (Ф), семантические (С), интегральные (И).
Взаимная увязка базовых ИП их синхронизация осуществляется ч/з модель управления данными, т.к. базовые ИП оперируют данными, то управление данными – это управление процессами обработки, обмена и накопления.
Управление процессами обработки данных означает управление организацией вычислительного процесса, преобразования и отображения данных в соответствии с моделью ИП, основанной на МРЗ.
При управлении процессом обмена управлению подлежат процедуры маршрутизации и коммутации инф-ной сети, а также передачи сообщения по каналам связи.
Управление данными в процессе накопления означает организацию физического хранения данных в базе и ее актуализацию, т.е. добавление, корректировка и уничтожение данных, кроме того должны быть подчинены управлению процедуры поиска, группирования, выбора и т.д.. На логическом уровне управление процессами накопления – это комплекс программ управления БД называемых СУБД. С увеличением объема инф-ии, хранимой в БД, при переходе к распределенным БД и банкам данных управление процессом накопления усложняется и невсегда поддается формализации, поэтому в АИТ при реализации программ возникает необходимость в человеке – администраторе БД, к-рый формирует и ведет модель накопления данных, определяя содержание и актуальное состояние.
Физический уровень.
Физический уровень ИТ представляет ее программно-аппаратную реализацию. При этом используют максимально типовые средства, что существенно сокращает затраты на создание и эксплуатацию объекта. С помощью программно-аппаратных средств осуществляются базовые инф-ные процессы и процедуры в их взаимосвязи и подчинении единой цели функционирования. Таким образом, на физическом уровне АИТ рассматривается как большая система, в к-рой выделяется несколько крупных подсистем. Это подсистема, реализующая на физическом уровне ИП: подсистема обработки данных, подсистема обмена данных, подсистема накопления данных, подсистема управления данными, подсистема представления знаний. с системой ИТ взаимодействует пользователь и проектировщик.


Подсистема
представления знаний
Подсистема
управления
Пользователь
Проектировщик



Подсистема
обработки
Подсистема обмена
Подсистема
накопления




Взаимосвязь
подсистем и базовой ИТ.
В настоящее время для создания АИТ применяется три основные фазы ЭВМ: на верхнем уровне большие универсальные ЭВМ (mainframe), способные обрабатывать и накапливать большие объемы инф-ии и используемые как главные ЭВМ; на среднем уровне абонентские вычислительные машины (server); на нижнем – ПК либо управляющие ЭВМ.
Обработка данных, т.е. их преобразование и отображение производится с помощью программ решения задач той предметной области для к-рой создана ИТ. В подсистему обмена данными входит комплекс программ устройств, позволяющих реализовать вычислительную сеть и передачу по ней сообщения с необходимой скоростью и качеством. Физическими компонентами подсистем обмена служат устройства приема и передачи (модем, усилители, кабели, специальные программные комплексы, осуществляющие компиляцию, маршрутизацию, доступ к сетям). Программным компонентом подсистемы являются программы сетевого обмена, реализующие сетевые протоколы, кодирование, декодирование сообщений.
Подсистема накопления данных реализуется с помощью БД и банков данных, организованных на внешних устройствах компьютера. В вычислительных сетях помимо локальных баз и банков используется организация распределенных банков данных и распределенной обработки данных. Аппаратно-программными средствами являются компьютеры различной классов соответствующих ПО. Для автоматического формирования моделей предметной области из ее фрагментов и МРЗ создается подсистема представления знаний. На стадии проектирования ИТ проектировщик формирует в памяти компьютера модель заданной предметной области, а также комплекс МРЗ. На стадии эксплуатации пользователь обращается к подсистеме знаний и, исходя из поставленной задачи, выбирает в автоматическом режиме соответствующую модель решений, после чего ч/з подсистему управления данными включает другие подсистемы ИТ. Реализация подсистем в представлении знаний производится на ПК, программирование к-рых осуществляется с помощью алголоподобных, прологоподобных языков. При больших объемах, накапливаемой на компьютере инф-ии и циркуляции в сетях, инф-ии на предприятии где внедрена ИТ, могут создаваться специальная служба (администратор БД, администратор сети и т.п.). Таким образом, ИТ имеет три уровня представления: концептуальный, логический, физический. Последовательное рассмотрение этих уровней позволяет облегчить восприятие при переходе от содержания цели в ИТ к ее физическому достижению.
ПРЕОБРАЗОВАНИЕ ИНФОРМАЦИИ В ДАННЫЕ.
Базовыми инф-ными процессами в ИТ называют процессы обработки, накопления данных, обмена и представления знаний, т.е. те процессы к-рые поддаются формализации последовательно и автоматизации с помощью ЭВМ и средств связи. Автоматизированные инф-ные процессы оперируют машинным представлением инф-ии – данными, и как ИТ в целом могут быть представлены тремя уровнями: концептуальным, логическим, физическим. Однако перед превращением в данные инф-ия должна быть собрана, соответствующим образом подготовлена и только после этого введена в ЭВМ, представленная в виде данных на машинном носителе инф-ии. Процесс перевода инф-ии в данные в технологических системах может быть полностью автоматизирован, т.к. для сбора инф-ии о состоянии производственной линии применяются различные электрические датчики, к-рые уже по своей природе позволяют преобразование физических параметров вплоть до превращения их в данные, записываемые на машинные носители инф-ии. В организационно-экономических системах управления (ОЭСУ) осведомляющая о состоянии объекта управления инф-ия семантически сложна, разнообразна и ее сбор не удается автоматизировать, следовательно, в таких системах ИТ на этапе превращения исходной инф-ии в данные в основе своей остается ручной.

Поток, осведомляющей
инф-ии

Сбор инф-ии
Подготовка и
контроль
Ввод инф-ии
Схема процесса
преобразования инф-ии в данные.
Данные
На рисунке представлена последовательность фаз преобразования инф-ии в данные в ИТ ОЭСУ.
Сбор инф-ии состоит в том, что поток осведомляющей инф-ии, поступающей от объекта управления, воспринимается человеком и передается в документную форму (бумажный носителей). Составляющими этого потока могут быть показания приборов, накладных, акты и т.п.. Для перевода осведомляющей инф-ии в автоматический контур ИТ необходимо собранную инф-ию передать в место ее ввода на компьютере. Передача осуществляется традиционно с помощью курьера или телефона. Собранная инф-ия для ввода должна быть предварительно подготовлена, т.к. модель предметной области заложенной в компьютере накапливает свои ограничения на состав и организацию вводимой инф-ии. В современных инф-ных системах ввод инф-ии осуществляется по запросам программы, отображенной на экране. Дальнейший ввод останавливается если был проигнорирован важный запрос.
Важной на этапах подготовки инф-ии и ввода является программа контроля. Контроль подготовленной и вводимой инф-ии направлен на предупреждение, выявление и устранение ошибок, к-рые неизбежны из-за человеческого фактора. Человек устает его внимание может ослабнуть в результате возникают ошибки, ошибки при сборе могут быть и преднамеренные. При контроле к собранной и подготовленной инф-ии применяется совокупность приемов как ручных, так и формализованных, направленных на обнаружение ошибки. Процедуры контроля полноты и достоверности инф-иии данных используются при реализации ИП повсеместно и могут быть подразделены на визуальные, логические и арифметические. Визуальные метод используется на этапе сбора и подготовки инф-ии и является ручным. Логический и арифметический, являясь автоматизированными методами, применяются на последних этапах преобразования данных. При визуальном происходит зрительный просмотр документа в целях проверки полноты, актуальности, юридической законности и т.д. Логический метод контроля предполагает сопоставление фактических данных с нормативными или с данными предыдущих периодов обработки, проверку логической непротиворечивости функционально-зависимых показателей и их групп. Арифметический метод контроля включает расчет контрольных сумм по строкам и столбцам, имеющим табличную форму, контроль по формулам, признакам делимости или четности, балансовый метод, повторный ввод и т.п. Для предотвращения случайного или намеренного искажения инф-ии служат организационные и специальные мероприятия. Это и четкое распределение прав и обязанностей лиц ответственных за сбор, подготовку, передачу и ввод инф-ии в системах ИТ, это и автоматическое протоколирование ввода и обеспечение санкционированного доступа к контуру АИТ. Ввод инф-ии при создании ИТ в организационно-экономической системе, в конечном итоге, является ручным – пользователь ЭВМ набирает алфавитно-цифровую инф-ию на клавиатуре, визуально контролируя правильность набора. Этап ввода это заключительный этап процесса преобразования данных. Помимо клавиатуры существуют другие устройства ввода, позволяющие убыстрить и упростить этот трудоемкий и изобилующий ошибками этап, например, сканеры или устройства ввода с голоса. Для решения задач ИТ помимо ввода осведомляющей инф-ии об объекте управления необходимо также вводить и подготавливать инф-ию о структуре и содержании предметной области, т.е. модель объекта управления, а также инф-ию о последовательности и содержании процедур технических преобразований для решения поставленной задачи, т.е. алгоритмическую модель. Суть подготовки такого рода инф-ии состоит в написании программ и описании структур и данных на специальных формальных языках программирования. Этап разработки и ввода программ в настоящее время автоматичен благодаря использованию многофункциональных систем программирования, тем не менее, сам процесс моделирования, т.е. разработки моделей предметной области решаемых задачи их алгоритмическая реализация остается творческим и на этапе разработки ИТ в своей основе практически не автоматическим. Таким образом, после сбора, ввода, контроля инф-ия (документы, программы, модели) превращается в данные, представленные машинными (двоичными) кодами, к-рые хранятся на машинных носителях и обрабатываются техническими средствами ИТ.
АИС. СИСТЕМА УПРАВЛЕНИЯ БД (СУБД).
В своем развитии АИС различает две ступени:
ИС, базирующаяся на автономных файлах. Это система с простой структурой и ограниченным кругом возможностей, они состоят из набора автономных файлов и прикладных программ, предназначенных для обработки файлов и выдачи документов. Недостатком этой системы является высокая избыточность, сложность введения и совместной обработки файлов, зависимость программы от данных.
Банки данных - это система в высокой степенью интеграции данных и автоматизацией управления ими, ориентированные на коллективное пользование. Они в основном лишены недостатков АИС первого поколения. Инф-ия, вводимая в АИС и выдаваемая пользователям, представляется в виде документов. Документ - материальный объект, содержащий в зафиксированном виде инф-ию, оформленную в установленном порядке, имеющую в соответствии с действующем законодательством правовое значение и предназначенную для передачи и использования.
Источником инф-ии АИС являются люди и датчики.
Потребителем – пользователь, т.е. люди. Пользователи делятся на три категории: 1) администраторы систем, отвечающие за ее эксплуатацию; 2) прикладные программисты, разрабатывающие прикладные программы для решения различных задач; 3) конечные пользователи, т.е. те, кто обращается к подсистеме за получением данных.
Обращение пользователей в АИС осуществляется в виде запросов. Запрос - это формализованное сообщение, поступающее на вход системы и содержащее условия на поиск данных и указание о том, что делать с найденными данными.
Интерпретация введенных запросов, выполнения действий указанных в них, формирование и вывод сообщения и документов составляют основные этапы работы АИС. В целом под АТС понимают совокупность инф-ных массивов технических, программных и языковых средств, предназначенных для сбора, хранения, поиска, обработки и выдачи данных по запросам пользователя. Использование АИС может осуществляться двумя способами. 1) Автономное функционирование, когда АИС не входит в состав других систем. Примером может служить библиотечно-поисковая система и системы резервирования, в к-рых ответом на запрос является документ в виде билета или сообщение об отсутствии свободного места. 2) использование АИС в качестве составной части других систем. В этом случае выходные данные могут применятся не только конечным пользователем, но и другими компонентами этой АИС с целью дальнейшей обработки и применения в производственных процессах. Так в обучающих системах АИС содержится изучаемый материал, набор вопросов, задач и ответов, САПР – нормативно-справочная инф-ию, сведения о ГОСТах и другие данные, в АСУ – всю инф-ию необходимую для управления предприятием, т.е. для анализа, оценки, планирования, контроля, исполнения.
ИС классифицируются по четырем признакам:
по типу хранения данных
по характеру обработки данных
по степени интеграции данных и автоматизации управления
по степени распределенности
По типу хранения данных АИС разделяется на документально-инф-ные поисковые системы (ДИПС) и фактографические инф-но-поисковые системы (ФИПС). ДИПС предназначены для хранения и обработки документов, описаний, рефератов и текстовых документов. Такие данные представляются в неструктурированном виде, пример – библиотечная АИС. В ФИПС хранят и обрабатывают фактографическую инф-ию – структурированные данные в виде чисел и текста, над такими данными можно выполнять различные операции.
По характеру обработки данных АИС делят на: инф-но-справочную систему, называемую часто запрос на ответ, к-рые выполняют поиск инф-ии без обработки; АИС обработки данных, они сочетают в себе инф-но-справочную систему с системой обработки данных, обработка найденных данных выполняется комплексом предусмотренных в системе прикладных программ. Большинство АИС построена по этому принципу.
По степени интеграции данных и автоматизации управления ИС делят: АИС на автономных файлах, где принцип интеграции почти не используется, а уровень автоматизации сравнительно низкий. Эти системы эффективны в случае узкого специального использования небольшим кругом лиц. По сравнению с АИС на автономных файлах в банках данных степень интеграции данных выше и используется для коллективного пользования, а процесс манипулирования данными автоматичен.
По степени распределенности АИС делят на: локальную, когда система расположена на одном компьютере; распределенную, функционирующую в сети, а компоненты распределены по узлам сети.
Основные требования при проектировании банка данных (БнД).
адекватность инф-ии состоянию предметной области
надежность функционирования
быстродействие и производительность
простота и удобство использования
массовость испоьзования
защита инф-ии
возможность расширения
в основе построения БнД лежат определенные научные принципы из к-рых наиболее существенные это принцип интеграции данных, принцип централизации управления ими. Оба принципа отражают суть БнД. Интеграция является основой организации БД, а централизация основа организации СУБД.
Суть принципа интеграции данных состоит в объединении отдельных несвязанных данных в единое целое, в роли к-рого выступает БД. В результате пользователю и его прикладным программам представляются единым инф-ным массивом. Интеграцию данных надо рассматривать на двух уровнях физическом и логическом. На логическом уровне множество структур данных отображается в единую структуру данных.. На физическом автономные файлы объединяются в БД.
Принцип централизации управления состоит в передаче всех функций управления единому комплексу управляющих программ – СУБД, т.е. все операции, связанные с доступом к БД, выполняются не прикладными программами, а централизованным ядром СУБД на основе инф-ии получаемой из этих программ. Соблюдение этого принципа позволяет автоматизировать работу с БД и повысить эффективность применения БД.
Состав БнД.
Состав ИС выбирается исходя из возлагаемых на нее функций и особенностей решаемых задач. Основными функциями БнД являются хранение инф-ии и организация ее защиты, периодическое изменение хранимых данных (обновление, добавление, удаление), поиск и отбор данных по запросам пользователей и прикладных программ, обработка данных и вывод результатов.
Хранимая инф-ия размещается в БД. БД – поименованная совокупность, организованных по определенным правилам, предусматривающим общие принципы описания, хранения и манипуляции данными независимо от прикладных программ. Как и в случае любого файла БД состоит из записей. Записи делятся на поля. Запись является наименьшей единицей обмена данными м/у ОП и внешней памятью. Поле является наименьшей единицей обработки данных.
В ОС, в среде к-рой функционирует БнД, специальных средств для обработки БД не предусмотрено, поэтому необходим комплекс программ, к-рый обеспечивал бы автоматизацию всех операций с решением этих задач. СУБД – это совокупность программ и языковых средств, предназначенных для создания, использования, введения БД. По схеме классификации ПО СУБД представляет собой пакет прикладных программ, расширяющих ее возможности по обработки БД. Основной составной частью СУБД является ядро - управляющая программа, предназначенная для автоматизированных всех процессов, связанных с обращением к БД. После запуска СУБД ее ядро постоянно находится в ОП и организует обработку поступающих запросов, управляет их очередностью управления, взаимодействует с прикладными программами и ОС. Другой частью СУБД является набор обрабатывающих программ – транслятор с языков описания данных, языков запросов и языков программирования, редакторов, отладчиков. Таким образом, типовой состав БнД можно представить как совокупность БД, СУБД и прикладных программ. В БнД может быть больше одной БД.
Обеспечение БнД.
Для выполнения функций ИС существует комплекс средств называемый обеспечивающим составом или обеспечением БнД. Он включает:
Техническое обеспечение - комплекс средств, все аппаратные средства необходимые для функционирования системы.
Математическое обеспечение – совокупность методов, математических моделей и алгоритмов управления БД и решения прикладных задач.
Программное – это программа в среде к-рой функционирует БД (ОС, оболочка NC) и набор сервисных программных средств, необходимых для выполнения вспомогательных операций и решения пользовательских задач.
Инф-ное представляет собой совокупность систем классификации и кодирования инф-ии, входных документов и вспомогательных инф-ных массивов, в к-рых размещается клавиатура, таблицы кодирования и т.д.
Лингвистическое – это множество языков, используемых СУБД и набор словарей, образующих словарный состав ИС.
Организационное – это комплекс мероприятий и руководящих документов, определяющий организации, повседневное эксплуатацию БнД и эффективность обслуживания.
ОРГАНИЗАЦИЯ БД.
Логическая организация БД.
Процесс создания БД включает два этапа: разработку логической БД и разработку БД на носителе.
Логическая организация БД это представление пользователя о той предметной области инф-ия о к-рой должна хранится в БД, т.е. логическая модель предметной области. Такая модель отражает три вида инф-ии: сведения об объектах предметной области, их свойствах и отношениях м/у объектами. Объекты на схеме представляются типами знаний, свойства объектов элементами или групповыми данными в виде полей. Отношения представляются связями м/у типами записей и полями. Такая модель не зависит от физической среды, типа компьютера, ОС и СУБД, т.е. абстрагируется от смыслового содержания данных, отражая только формы представления инф-ии и связи м/у данными.
Логическая модель можно представить несколькими способами. Для ИС характерно два способа схем представления данных: графический и табличный.
Графический способ основан на изображении моделей данных в виде ориентированного графа, вершины к-рого служат для отображения типа записи, а дуги связей м/у записями. Табличный способ состоит в представлении инф-ии предметной области в виде одной или нескольких таблиц, заголовок каждой из к-рой соответствует типу записи графической модели.
В настоящее время известно три типа логической модели: иерархическая, сетевая, реляционная (применяется на ПК).
Иерархическая модель данных основана на графическом способе. Она представляет дерево, в вершинах к-рого располагаются типы записей, каждая из вершин связана только с одной вершиной вышележащего уровня.
Факультет
Деканат
Кафедра
Курс
Преподаватель
Группа
Дисциплина
Студент
Поиск данных в такой структуре выполняется по одной из ветвей начиная с корневого элемента, т.е. должен быть указан полный путь движения. Так поиск и выборка одного из экземпляров записи типа "студент" необходимо указать корневой элемент "факультет", элементы "курс" и "группа".
Сетевая модель данных также использует графический способ представления данных и схема отображается в виде графа. Однако по сравнению с иерархической моделью никаких ограничений на количество связей, входящих в каждую вершину не накладывается, что позволяет отражать связи м/у объектами предметной области почти любой сложности, в частности кольцевые структуры.
Факультет
Деканат
Кафедра
Курс
Преподаватель
Группа

Дисциплина
Студент

Реляционная модель данных строится на использовании табличных методов и средств представления данных и манипулирования ими. В РМД инф-ия отражается в таблице – отношение. Строка называется кортеж, столбец – атрибут. Каждый атрибут может принимать некоторое подмножество значений из предметной области – домен. Домен, таким боразом, является областью определения одного или нескольких атрибутов. Отношениям, атрибутам и доменам присваиваются имена. Отношение характеризуется числом кортежей (m) и числом атрибутов (n), составляющих арность отношений: унарный (n=1), бинарный (n=2), и т.д.. К отношениям предъявляется ряд требований: 1) значение атрибутов, т.е. данные, расположенные на пересечении строки и столбца, являются неделимыми, элементарными (атомарными); 2) в отношении не может быть двух одинаковых кортежей, т.е. двух одинаковых строк; 3) порядок следования атрибутов фиксированный, т.е. нельзя переставить столбцы местами; 4) порядок следования кортежей нефиксированный. Эти требования создали предпосылки к применению в РМД математического аппарата реляционной алгебры. Существует определенная аналогия м/у структурой отношения и организацией данных предусмотренных в ОС. Атрибут отождествляется с полями записи, кортеж с экземпляром записи, а отношения с файлом. В состав РМД может входить несколько отношений, каждое из к-рых имеет свою схему, поэтому под РМД понимается набор отношений, удовлетворяющих указанным выше требованиям.
"Сотрудник"
Фамилия |
Год |
Телефон |
Должность |
Борисов |
1970 |
45-66-60 |
Инженер |
Иванов |
1969 |
23-14-79 |
Техник |
Квитко |
1969 |
39-18-25 |
Инженер |
"Финансы"
Должность |
Оклад |
Пример реляционных
отношений. |
2500 |
Техник |
1800 |
Секретарь |
2000 |
Для поиска данных по ключу отдельные атрибуты объявляются в качестве возможных ключей, один из к-рых назначается первичным. Форма отношений, удовлетворяющая требованиям, предъявленным к РМД, называется нормальной формой, а процесс приведения отношений к нормальной форме называется нормализацией. В настоящее время используется шесть нормальных форм и шесть этапов нормализации, приведение к первой НФ (1НФ), ко второй, третей. Отношение называется нормальным, если оно находится в одной из этих форм. На каждую из форм распространяется принцип вложенности, если отношение находиться в форме с номером n , то оно находиться и форме с номером n-1. Обязательным условием работы с РМД является нахождение всех отношений в 1НФ. Преобразование таблицы в другие формы необходимо в том случае, если предполагается добавление, удаление кортежей либо атрибутов, в результате чего в таблице могут возникать искажение инф-ии. Отношения находятся в 1НФ , если значения всех атрибутов атомарны. Одним из способов приведения к 1НФ является декомпозиция, т.е. разложение на два или более новых отношения в совокупности эквивалентных исходным. Основной недостаток РМД – большая инф-ная избыточность как логическом, так и на физическом уровнях, трудоемким является также процесс нормализации отношений.
Кроме рассмотренных моделей иногда используется и простейшая организация данных - модель на плоских файлах. Плоскими называют файлы, в к-рых не предусматривается не прямых, не косвенных связей м/у типами данных. Так если в структуре иерархической и сетевой моделей данных убрать все связи, а таблице РМД не использовать атрибут "должность" в качестве связи, то эти модели превратятся в модель БД на плоских файлах.
Физическая организация БД.
Под физической организацией понимается совокупность методов и средств размещения во внешней памяти данных и создания на их основе внутренней (физической) модели данных. Внутренняя модель является средством отображения логической модели в физическую среду хранения. В отличие от логической модели физическая модель данных связана со способами организации данных на носителях, методами доступа к данным. Она указывает каким образом записи размещаются в БД, как они упорядочиваются, как организуется связи, каким путем можно локализовать записи и осуществить их выбор. Внутренняя модель разрабатывается средствами СУБД. Очевидно, что любая модель может быть отображена множеством внутренних моделей данных, подобно тому как один и тот же алгоритм может быть представлен множеством эквивалентных программ, составленных на одном или разных языках программирования, одна из моделей будут оптимальна. В качестве критерия оптимальности используется минимальное время ответа системы, минимальный объем памяти, минимальные затраты на введение БД и другие. Основными средствами физического моделирования БД являются: структура хранения данных, поисковая структура, язык описания данных. В простейшем случае структуру хранения данных можно представить в виде структуры записи файла БД, включающие поля, записи, порядок их размещения, типы и длины полей. Если структура хранения данных в основном предназначена для указания способа размещения записи и полей, то поисковые структуры определяют способ быстрого нахождения этих записей. Поэтому различают два принципа физической организации БД: организация на основе структуры хранения данных, организация, сочетающая структуру хранения данных с одной или несколькими поисковыми структурами. Конечным итогом разработки физической организации БД являются файлы данных – файлы БД и файлы поисковой структуры. В ПК файлы могут быть прямого или последовательного доступа, т.е. прямые или последовательные. Из множества типов поисковых структур в СУБД на ПК чаще всего используются линейные и цепные списки, инвертированные и индексные файлы. Линейный список самой простой способ организации физической БД. В отличие от остальных трех способов он не требует создания дополнительных файлов. В соответствии с этим способом файл БД рассматривается как последовательность невзаимосвязанных записей. Поиск любой из них выполняется путем вычисления адреса записи по некоторому алгоритму. По критерию минимальности памяти это самый экономичный способ, но проигрывает в быстродействии. Цепной список представляет собой файл записи к-рого имеют ссылки на другие записи, образуя связанную (ассоциативную) организацию данных. Средством связи (ссылками) к элементам списка являются указатели, встраиваемые в записи в виде дополнительных полей. С помощью указателей устанавливается любой порядок выборки записи. Поле выделяемое для хранения указателя называют адресом связи. Чтобы войти в список надо указать точку входа, т.е. адрес начала списка такой адрес хранится в отдельной записи (заголовок или фиксатор списка).
АС - адрес списка
КС – конец списка
Графическое
представление
-

4
*
АС
Иванов
*
Петров
*
Сидоров
КС
Ясин
*



ФС – фиксатор списка АНС
– адрес начало списика
ФС
АНС
-
Табличное представление
4
а+1
А+0 |
Иванов |
А+3 |
А+1 |
Петров |
А+0 |
А+2 |
Сидоров |
КС |
А+3 |
Ясин |
А+2 |
В этом примере элементы размещены в памяти в последовательном порядке (Иванов, Петров, Сидоров, Ясин), а выборка элементов заданная указателями осуществляется следующим образом (Петров, Иваном, Яисн, Сидоров) в поле адресе последнего читаемого в последовательном порядке указан признак конца списка (КС), если вместо адреса КС указать ФС, то структура станет кольцевым списком. Добавление еще одного указателя позволяет список двунаправленным. В записи можно предусмотреть любое требуемое кол-во указателей и , следовательно, иметь k вариантов записи файлов. Цепные списки наиболее удобны для представления во внешней памяти сетевой модели данных.
В БД записи , как правило, упорядочены по одному из полей (основному ключу) что позволяет сократить перебор записи при чтении. Для уменьшение времени поиска данных по неключевым полям, создается инвертированные файлы. Инвертированным называется файл записи, к-рого упорядочены по неключевому полю. Процесс создания инвертированного файла состоит в переупорядочивании исходного файла по значению неключевого поля, т.е. получение копии основного файла с иным порядком следования записи. Инвертирование основного файла будет полным если созданы инвертированные файлы для каждого из его неключевых полей, и частичным если созданы лишь для их части.
ОСНОВНОЙ ФАЙЛ
Фамилия |
Год |
Борисов |
1970 |
Ярин |
1969 |
Иванов |
1969 |
ИНВЕРТИРОВАННЫЙ ФАЙЛ
Фамилия |
Год |
Иванов |
1969 |
Ярин |
1969 |
Борисов |
1970 |
Здесь приведена БД в составе основного файла где записи упорядочены по ключевому полю "Фамилия" и инвертированного файла И.Ф_год, записи к-рого упорядочены по неключевому файлу "год" основного файла. При вводе запроса "Найти сотрудника с годом рождения <1970" поиск данных надо вести не в основном файле, где потребуется полный перебор записи, а в инвертированном, в к-ром для приведенного примера надо прочитать первые две записи, и этого будет достаточно. Инвертированный файл обеспечивает быстрый поиск данных по неключевому полю. По отношению к основному файлу БД он является поисковой структурой. Однако применение инвертированного файла приводит к очень большому дублированию инф-ии, т.е. перерасходу памяти.
В связи с этим целесообразно создавать не инвертированные файлы, а инвертированные файлы адресов записей основного файла, содержащие вместо записи БД адреса этих записей такие файлы называются индексными файлами или индексами. Они занимают малый объем памяти. Каждая запись индекса содержит значение одного неключевого поля и список адресов основного файла, в к-рых встречаются указанные значения неключевого поля. Файл БД, для обработки к-рого используется хотя бы один индекс, называется индексированным файлом. Построение индекса выполняется автоматически самой СУБД.
ОСНОВНОЙ ФАЙЛ
|
Фамилия |
Год |
001 |
Борисов |
1970 |
002 |
Ярин |
1969 |
003 |
Иванов |
1969 |
004 |
Петров |
1959 |
ИНДЕКСИРОВАННЫЙ ФАЙЛ
Год |
Адреса |
1959 |
004 |
1969 |
002, 003 |
1970 |
001 |
Поиск записи в БД с помощью индекса заключается в выборе индекса соответствующего признаку поиска, в поиске индекса строки с заданным значением признака , выборки их этой строки списка адресов искомой записи и чтения этих их в основном файле по указанным адресам, методом прямого доступа. Таким образом, БД может включать один основной и несколько вспомогательных файлов.
ОСНОВНЫЕ ФУНКЦИИ И ОСОБЕННОСТИ РАБОТЫ СУБД.
СУБД представляет собой совокупность программных и языковых средств, предназначенных для создания, введения и использования БД. Являясь специальным пакетом прикладных программ, СУБД расширяет возможности ОС в области управления БД. В БнД СУБД является необходимой частью ИС по следующим причинам:
Логическая и физическая организация БД является нестандартной для ОС и языков программирования.
Описание БД и ее фрагментов отделено от прикладных программ и должно создаваться и обрабатываться специальными средствами.
Доступ к данным, включающим вычисление адресов, маршрутизацию в БД, локализацию записей основывается на специальных методах и требует разработку специальных алгоритмов и управляющих программ.
Обработка реляционной БД базируется на определениях реляционной алгебр, непредусмотренной в ОС и системах программирования.
Специальная обработка БД, такая как поддержание целостности и непротиворечивости, неизбыточности данных не реализована в ОС.
СУБД берет на себя все указанные операции на каждом из трех этапов жизненного цикла БД – процессы создания, введения, и использования. Все функции СУБД можно разделить на три группы: 1) управление БД; 2) разработка, отладка и выполнение прикладных программ; 3) выполнение вспомогательных операций – сервис.
В СУБД предусмотрено три уровня управления: 1) управление файлами, осуществляемое в процессе их генерации и эксплуатации. Основными операциями являются операции открытия и закрытия, переименования, реорганизации, восстановления БД, снятие отчетов по БД. 2) управление записями (кортежами), к-рое включает чтение, добавление, удаление и упорядочивание записи. 3) управление полями записи (атрибутами). Такие операции как ввод данных с клавиатуры, вычисление, организация циклов, вывод данных на экран и принтер не является сферой деятельности СУБД, а определяется в прикладных программах. Для разработки прикладных программ в СУБД предусмотрен специальный язык программирования. В соответствии с указанным набором функций в СУБД входят программы трех типов: управляющие, обрабатывающие (трансляторы), сервисные. Программы функционально взаимосвязаны и взаимодействуют друг с другом и ОС.
Основным признаком классификации СУБД является логическая модель БД, поэтому различают сетевые СУБД, иерархические СУБД, реляционные СУБД. К числу наиболее распространенных реляционных СУБД относят: dBase, FoxBase, FoxPro, Paradox, Oracle, Informix.
ЯЗЫКИ ЗАПРОСОВ (QBE, SQL).
Хранимые данные модно рассматривать и редактировать с помощью имеющихся в каждой СУБД средств просмотра и редактирования данных в таблице. Однако для повышения эффективности редактирования и выбора данных из таблиц создаются и выполняются запросы. Запрос представляет собой специальным образом сформулированное требование, определяющее состав производимых над БД операций по выборке или модификации хранимых данных. Для подготовки запросов с помощью различных СУБД используется два основных языка описания запросов: QBE (Query By Example – язык запросов по образцу), SQL (Structured Query Language – структурный язык запросов). По возможности манипуляции данными языки почти эквивалентны. Главное отличие в формировании запросов - язык QBE предполагает ручное или визуальное формирование запросов, а использование SQL означает программирование запросов. Язык QBE позволяет создавать запросы БД путем заполнения предлагаемой СУБД запросной формы. Этот способ обеспечивает высокую наглядность и не требует указания алгоритма выполнения операций, достаточно указать образец ожидаемого результата. При создании запроса с помощью QBE допустимы следующие операции: выборка, вычисление и модификация данных, вставка и удаление записи. Результат запроса новая таблица или обновленная исходная. Выборка, вставка, удаление и модификация данных из записей может выполнятся с использованием условий, задаваемых с помощью логических выражений. Вычисления над данными задаются с помощью арифметических выражений и порождают в ответ табличных новые вычисляемые поля. В многих современных СУБД Access и VFP, многие действия по подготовке запросов языкаQBE выполняются визуально при помощи мыши.
Структурированный язык SQL основан на реляционных отношениях. Язык имеет несколько стандартов. SQL предназначен для выполнения операций над таблицами (создание, удаление, изменение структуры) и над данными таблицы (выборка, изменение, добавление, удаление). SQL не является процедурным языком и не содержит имеющихся в обычных языках программирования операторов управления организацией подпрограмм вв/в. В связи с этим SQL автономно не используется, а обычно погружен в среду встроенного программирования в СУБД. В современных СУБД с интерактивным интерфейсом можно создавать запросы не применяя SQL, однако его применение в некоторых случаях позволяет расширить возможности использования СУБД.
АРХИТЕКТУРА ИС.
Эффективность функционирования ИСИ во многом зависит от ее архитектуры, в настоящее время широко используется архитектура "клиент-сервер". Она предполагает наличие компьютерной сети и распределенной БД, включающей БД корпоративную (БДК) и БД персональную (БДП). БДК размещается на компьютере – сервере, а БДП размещается на компьютерах сотрудников подразделений, являющиеся клиентами БДК. Сервером определенного ресурса компьютерной сети называется компьютер (программа), управляющий этими ресурсами. Клиент – компьютер (программа), использующий этот ресурс. В качестве ресурса компьютерной сети могут выступать БД, ФС, службы печати, почтовые службы. Тип сервиса определяется видом ресурса к-рым он управляет, если управляемым ресурсом является БД, то соответствующий сервер называется сервером БД. Достоинством организации ИС по архитектуре "клиент - сервер" является удачное сочетание централизованного хранения, обслуживания и коллективного доступа к общей корпоративной инф-ии с индивидуальной работой над персональной инф-ей.
Структура распределенной БД построенная по архитектуре клиент – сервер показана на схеме.
Сетевое ПО
ПК1


Сервер БД
СУБД


СУБД

ПК2

БДК создается, поддерживается и функционирует под управлением сервера БД, например, Microsoft SQL Server, Oracle Server. Для создания, управления и функционирования БДП и приложений работающих с ним используется СУБД – Access, VFP, Paradox (Borland). В зависимости от размеров организации и особенностей решаемых задач ИС могут иметь одну из следующих конфигураций: компьютер – сервер, содержащий БДК и БДП; компьютер сервер и ПК с БДП; несколько компьютеров – серверов и ПК с БДП.
Исследование архитектуры клиент – сервера дает возможность посменного наращивания ИС предприятий, во-первых, по мере развития самого предприятия, во-вторых, по мере развития самой ИС. Разделение общей БД на БДП и БДК позволяет уменьшить сложность проектирования БД по сравнению с централизованным вариантом, а значит снизить вероятность ошибок при проектировании и стоимость проектирования.
ОРГАНИЗАЦИЯ ИТ НА ПРЕДПРИЯТИИ.
Основной целью ИТ на предприятии является создание инф-ного продукта, позволяющее формировать управляющее воздействие на производство. Целью производства является создание конкурентоспособной продукции с минимальными затратами, обеспечивающими наибольшую прибыль. Для реализации этой цели разрабатывается модель выпускаемой продукции, отражающая различные аспекты – от маркетинговых до технологических. Организуется производство и система управления этим производством. Последнее необходимо чтобы удерживать производство в рамках разработанной модели продукции при неизбежных внешних возмущениях. Для повышения эффективности управления создается АИС управления предприятием, в к-рой основным контуром является контур ИТ. ИТ в управлении предприятием учитывает сложившиеся инф-ные потоки и их содержание в его организационной структуре. На любом крупном предприятии где имеет смысл создавать АСУП можно выделить типовые блоки организационной структуры.
Директор


Бухгалтерия

ПЭО
Хранения и сбыт
продукции

АСУП
Администратор

СГП
СТПП
Основное производство
Производственные
подразделения
Цехи
Производственные бригады
Производственные участки
Во главе предприятия стоит директор, решения к-рого реализуются администрацией. Обычно в администрации входят заместитель директора по экономике, руководитель плановой экономики и бухгалтерия, служба главных специалистов (СГС), включающая и главного инженера под чьим руководством находиться служба технической подготовки производства (СТПП). Также заместитель директора по общим вопросам, в функции к-рого входит решение различных вопросов, не отнесенных к перечисленным службам, а также руководство службы хранения и сбыта продукции. Организация со своими службами управления организует, планирует и регулирует основное производство, к-рое состоит из производственных подразделений, таких как производственные бригады, участки, цехи. Контур автоматического инф-ного управления предприятием может быть включен в контур АСУТП – АСУ технологическими процессами, охватывающий основное производство и службы главных специалистов. При АУП (автоматизированном управлении предприятием) выполняется несколько основных фаз управления, позволяющих выдерживать сформулированную общей математической моделью управления траекторию достижения цели, а именно производство запланированной продукции.
Планирование
U
Учет
Анализ
Регулирование
Фазы управления
производством
Производство организуется в соответствии с планом разработанным в фазе планирования и отражающим модель выпускаемой продукции. В процессе функционирования производства на него оказывают влияния возмущающие воздействия (U), что приводит к отклонению от параметров заданных планом. Фиксация текущего состояния производства происходит в фазе учета, на следующей фазе, фазе анализа определяется степень отклонения производства от заданного плана и выбирается стратегия восстановления. Регулирование производства происходит на фазе регулирования, к-рое позволяет вернуть производство на заданную траекторию.
На различных фазах приходится решать многие функциональные задачи (ФЗ) управления, к-рые образуют комплексы функциональных задач (КФЗ). При решении ФЗ средствами ИТ (СИТ), они должны быть преобразованы в вычислительные задачи, алгоритмизированы и введены в ЭВМ. ФЗ формируются на основе инф-ной модели. Общая математическая модель управления дает комплексы взаимосвязанных ФЗ, определяющих проблематику фаз управления. Частные математические модели управления (ЧММУ), вытекающие из общей, порождают ФЗ, выделяемые из комплекса. На основе концептуальной модели (КМ) решения из функциональной модели формируется вычислительная задача (ВЗ), пригодная к решению СИТ. Для решения задач управления на ЭВМ надо иметь алгоритм ее решения (А), к-рый разрабатывается на основе логической модели (ЛМ).
Взаимосвязь модели и задач управления показана на следующей схеме.
ОММУ
КФЗ

ЧММУ
ФЗ

КМ
ВЗ
ЛМ
А

Решение
Таким образом, от концептуальной модели управления, определяющей фазу управления и их содержание ч/з системы математических и алгоритмических моделей и ФЗ, составляющих логический уровень управления, переходят к физическому уровню решения задач управления средствами вычислительной техники. Каждая фаза управления производством включает ряд комплексов задач, описываемых соответствующими математическими моделями, решение этих задач дает необходимую инф-ию для данной фазы.
Фаза планирования.
На этой фазе управления в различных временных режимах решается несколько КФЗ планирования: перспективное планирование (3-5 лет), годовое, оперативное. Математические модели перспективного планирования призваны описывать состояние и стратегию развития предприятия ч/з 3-5 лет. Такие планы являются прогнозными и для их создания привлекаются модели и методы, позволяющие проигрывать поведение объекта при различных прогнозируемых параметрах самого объекта и окружающей среды.
Производственные
функции
производство
Перспективный
план производства
Перспективное

Имитационные
модели
Годовое
Модели
производственного баланса


Бизнес-планы
Оптимизация модели
Оперативное
Модели календарного
планирования


Планы и графики
подразделений
Модели управления
запасами
Модели массового
обслуживания
Сетевые модели
В фазе планирования в качестве внутренних параметров прогнозируются ресурсы производства его организационная структура. На разработку перспективного плана большое влияние оказывает прогноз состояния внешней среды: спрос на производимую продукцию, рынки сбыта, состояние конкуренции, политическая и экономическая ситуация в стране и регионе, изменение вкусов и обеспеченности потребителей и т.п. Точно спрогнозировать значение всех параметров на 3-5 лет невозможно, поэтому используется вероятностные методы и методы математической статистики, позволяющие выявить предполагаемую тенденцию изменения параметров внешней среды, влияющих на состояние предприятия. При этом широко пользуются производственными функциями как аппаратом моделирования и имитационными моделями.
Комплекс задач годового планирования более конкретен, поэтому для моделирования производственной деятельности предприятия используются детерминированные модели, т.к. определить значение производственных параметров внешней среды на ближайшую перспективу можно с достаточной точностью. Для разработки годового плана используется модели производственного баланса и линейного программирования. Результатом решения комплекса задач годового планирования является бизнес – план предприятия, в к-ром должны быть представлены в сбалансированном виде ресурсные, производственные и маркетинговые возможности предприятия, объединенные сквозной целью. Если комплекс задач перспективного планирования решается в основном для предприятия в целом, то комплекс задач годового планирования решается как для предприятия в целом, так и для его производственных подразделений.
На оперативном уровне планирования используются модели календарного планирования, управления запасами, теории массового обслуживания, сетевые модели, модели оптимального программирования. Результатом решения задач этого комплекса являются планы и графики работ производственных подразделений.
Инф-ия фазы планирования является входной инф-ей для объекта управления, т.е. производства и в соответствии с ним организуется технологический производственный процесс. Параметры производства, заданные в фазе планирования испытывают возмущающее воздействие окружающей среды и отклоняется от запланированных значений. Для того чтобы возвратить производство в прежние рамки, очерченные планом, необходимо оперативное регулирование. Регулирование возможно лишь при наличии резервов. Содержание резервов, т.е. запас ресурсов приводит к издержкам, увеличивая себестоимость продукции, поэтому точность решения комплекса задач годового и особенно оперативного планирования имеют большое значение. Для эффективного регулирования производства требуются знания направления и степени воздействия на производство, т.к. недорегулирование как и перерегулирование приводит к неустойчивости производственного процесса. Поэтому в управлении предприятием важное значение приобретают фазы учета и анализа. Фаза учета необходима для констатации истинного состояния параметров производства. Фаза анализа позволяет определить размер и направление отклонений значений этих параметров, а также предугадать тенденции изменений.
Фаза учета.
Комплекс задач, решаемых в этой фазе относятся в основном к задачам бухгалтерского учета и имеют в своем составе такие задачи как учет основных средств и материальных ценностей, учет труда и его оплаты, учет себестоимости продукции, учет денежных и расчетных операций и т.д. Математические модели этой фазы достаточно просты, а выходной инф-ей являются бухгалтерские регистры (ведомости) учета и отчетности, характеризующие состояние производства.
Основные средства

К анализу
Модели бухгалтерского
учета
Ведомости учета
и отчетности
Труд
Себестоимость


Финансы
..................
Выходная инф-ия фазы учета используется фазой анализа, на вход моделей к-рой поступает выходная инф-ия фазы планирования как эталон состояния производства.
Фаза анализа.
Здесь решаются задачи по анализу отдельных параметров производственного процесса по отношению к заданным значениям, т.е. плану. Это задачи по анализу выпускаемой продукции и ее себестоимости, трудовых ресурсов и трудозатрат, состояний материальных и финансовых ресурсов. На логическом уровне эти задачи описываются математическими моделями одно- и многофакторного анализа аналитических и оптимизационных расчетов.
От планирования
От анализа

Продукция,
себестоимость
Модели одно-
многофакторного анализа
Аналитические
таблицы и графики, экспертные оценки.
Труд
Модели аналитических
расчетов
Материальные
ресурсы
Фаза регулирования
Оптимизационные
модели
Финансы

Модели представления
знаний
В фазе анализа в результате решения функциональной задачи получают аналитические таблицы и графики, рекомендации по регулированию производства. Выходная инф-ия фазы поступает к ЛПР, к-рое с учетом дополнительных факторов принимает решение о размерах и направлениях регулирования производства, в сложных ситуациях в фазе анализа используется инф-ия экспертов, в качестве к-рых могут выступать как опытные специалисты, так и комплекс экспертных систем. Использование в фазе анализа моделей формализации и представления знаний повышает обоснованность и корректность принимаемых решений.
Фазы регулирования.
От анализа
К п р и з в о д
с т в у
Транспортные,
календарные модели
Компьютерные
сетевые графики и маршруты
Календарное


Модели оперативного
управления
Диспетчирование
Алгоритмы
диспечирования

На фазе регулирования решаются задачи календарного планирования и диспетчирования производства, т.е. на основе инф-ии и принятых решений в фазе анализа оперативное воздействие на параметры производственного процесса. Для формального описание задач регулирования привлекаются методы и модели календарного и сетевого планирования, транспортные модели и модели оперативного управления. Выходной инф-ей этой фазы являются календарные, сетевые графики производства продукции, маршруты, алгоритмы диспетчирования.
Комплексы задач различных фаз управления производственным предприятием имеют периодичность решений и различные объемы переработанной инф-ии. В фазе планирования периодичность наибольшая, особенно для задач перспективного планирования, объемы наименьшие по сравнению с другими фазами. Наибольшая нагрузка ложится на фазу учета, где некоторые задачи решаются ежедневно. Фаза анализа оперирует более комплексной инф-ей и с большим периодом решения задач. В фазе регулирования номенклатура функциональных задач существенно меньше, но решаются они ежедневно и на всех уровнях производства. Математические модели и методы решения функциональных задач тесно переплетаются в различных фазах управления, поэтому естественно что алгоритмическое и программное обеспечении фаз управления являются общим и составляет общую алгоритмическую модель процесса обработки данных.
Целью ИТ на предприятии является создание инф-ии, позволяющей определить образ и осуществить управление производством конкурентоспособной продукции.
Фаза управления.
Фаза управления производством реализуется на концептуальном уровне ИТ совокупности базовых инф-ных процессов.
ВЗ1



ВЗn



Взаимодействие
процессов ИТ на производстве
В настоящее время все большая часть производственной инф-ии необходимой для управления предприятием обрабатываются на уровне данных. Тем не менее постановка и накопление инф-ии ФЗ (функциональных задач) (ФЗ1,…,ФЗn) производится, как правило, на основе документообработки, обмена производственной инф-ей м/у ФЗ. С помощью частных математических моделей (ЧММ) ФЗ преобразуется в вычислительные (ВЗ1,…,ВЗn) и таким образом, выполнение инф-нвх функций управления переходит на уровень данных. При решении ВЗ основной технологией управления инф-ным процессом является процесс обработки данных, управляемых процедурой называемой организацией вычислительного процесса (ОВП). Инф-ное взаимодействие ВЗ с другими инф-ными процессами осуществляется процессом обмена данных, необходимость такого взаимодействия обеспечивается тесной связью алгоритмов решений ВЗ и общностью внутримашинной инф-ной базы для всех задач управления. Процесс обработки данных реализуется с помощью процедур планирования и организации вычислительных работ. А необходимое инф-ное отображение результатов решения задач с помощью процедуры отображения.
При обработке из первичных данных получают промежуточные и выходные данные, к-рые с помощью процессов обмена и накопления поступают в БД, к-рая организуется процедурой организации инф-ной базы (ОИБ). Эта процедура позволяет перевести концептуальное представление БД ч/з ее логическую схему к физическому представлению. Процесс накопления, описываемый на логическом уровне моделей выбора, хранения и актуализации данных, позволяет создать БД, необходимую для решения задач управления на предприятии. Особое место среди процессов ИТ управления предприятием занимает процесс представления данных, не нашедший пока широкого распространения в АИТ. Но именно в производстве задачи управления характеризуются большим числом взаимосвязанных трудноформализуемых факторов, позволяющих получить решение либо в достаточной общей либо в приближенной форме, поэтому при решении задач управления на предприятии часто требуется мнение экспертов, что в АИТ может быть реализовано при помощью экспертных систем, являющихся одной из форм реализации процессов представления знаний. На физическом уровне ИТ реализуется с помощью программно-аппаратных средств ИТ, объединенных в соответствующие подсистемы: управления, обмена, накопления, обработки, представления знаний. Широкое распространение ПК, быстрое увеличение функциональных возможностей и их основных параметров, снизившаяся стоимость сетевого программного обеспечения и оборудования позволяет создать распределенные системы обработки и накопления данных. В этом случае решение частных задач управления возлагается специалистами на АРМ. Под АРМ понимают рабочие места специалиста управленца, укомплектованное ПК с ПО, позволяющее в автоматическом режиме решать возлагаемые на специалиста задачи. Для повышения эффективности, степени автоматизации ИТ, реализуемые с помощью АРМ, последние должны быть объединены в локальные сети с выходом в корпоративную и глобальную сети. Физическая реализация ИТ в управлении предприятием, как правило, содержит черты организационной структуры, и для административного задания может представлять шину, клиент-серверную сеть, разбитую на сегменты, обмен м/у к-рыми осуществляется ч/з устройства коммутации – мост.
АВТОМАТИЗВЦИЯ ПРОЕКТИРОВАНИЯ ИТ (АПИТ).
Этапы создания АС позволяет выявить три стадии проектирования:
предпроектный анализ (ПА), позволяющий разработать технико-экономического обоснования и техническое задание.
технический проект (ТП)
рабочий проект (РП)
АС появились с первыми вычислительными машинами и прошли долгий этап развития, опыт их создания показал, что все стадии проектирования являются трудоемкими , поэтому продолжаются работы по созданию методов и средств автоматизации проектирования ИТ (АПИТ).
Сформировались четыре подхода к автоматизации процессов создания проектных решений: элементарный, подсистемный, объектный, модельный. Элементарный подход предполагает использование типовых проектных решений по отдельным функциональным задачам управления. Подсистемный подход использует накопленный опыт по проектированию функциональных подсистем. При объектном подходе используется типовое решение для целого класса объектов, например ИС консервного комбината. Однако подходы оказались малоэффективными, т.к. требуют значительных доработок, связанных с непохожестью данного конкретного предприятия на типовое, к к-рому привязывают типовое решение. Кроме того первые три подхода позволяют ускорить только третью стадию создания ИС – рабочее проектирование. Самыми трудоемкими являются ПА и ТП.
Модельный подход.
Модельный подход к АПИТ является наиболее перспективным и базируется на тех же принципах что и АИТ, это позволяет модельный подход рассматривать как инф-ную технологию автоматизации проектирования ИС (АПИС), поскольку автоматизация любого процесса, будь то проектирование или управление предполагает наличие контура ИТ. Сутью модельного подхода является последовательное преобразование управления: от общей математической модели управления до алгоритмической модели решаемой функциональной задачи.
Укрупненная схема такой последовательной композиции и преобразования моделей в процессе АПИС приведена на рисунке.



ОММУ
ЧММУ
КМ
АМ
ПА
ЛП
ФП
КП
ТП
РП
Основой здесь является общая математическая модель управления (ОММУ), отражающая целевую функцию и критерии с учетом налагаемых на ОУ ограничений. В результате предпроектного анализа (ПА) общая модель управления декомпозируется на частные математические модели управления объектом (ЧММУ), отражающие частные задачи управления и их цели. Технический проект включает в себя концептуальное (КП) и логическое проектирование (ЛП). Концептуальное проектирование позволяет из частных моделей управления создать содержательный образ - концептуальную модель (КМ), проектируемой АС, а результатом логического проектирования является алгоритмическая модель (АМ), решаемых в системе задач управления. Физическое проектирование (ФП) дает рабочий проект (РП) программно-аппаратных реализаций ИТ в ИС. Такая последовательность может быть реализована процессами и средствами ИТ. На физическом уровне автоматизация проектирование инф-ной системы производится проектировщиками с помощью АРМ, включающего компьютер с соответствующими базовыми и проблемноориентированным ПО.
Последовательность АПИТ в ИС показана на следующем рисунке.
ПА
ТП
ОММУ
РП





ТЭО
ТЗ
КП
ЛП
ФП
ОПС



КФЗ
ФЗ
КОП
МИП
Решение задачи
управления
ВЗ
А
МПО
ЧММУ
КМ
МРЗ
АМ
Общая математическая модель управления объектом является базой модели предметной области (МПО), отражаемой комплексом функциональных задач (КФЗ). Выделенные из общей модели, частные модели представляются отдельными задачами, что является основным результатом предпроектного анализа. Концептуальное проектирование (КП) осуществляется на основе созданных частных моделей управления (ЧММУ), содержание к-рых позволяет разработать концепции организации инф-ного процесса (КОП) и создать концептуальную модель (КМ) системы в процессе управления. Концептуальная модель системы в процессе логического проектирования формализуется моделями инф-ного процесса (МИП) и моделями решаемых задач (МРЗ), преобразуемые затем в алгоритмические модели. Заключительным этапом логического проектирования является разработка алгоритмов (А) решения вычислительных задач (ВЗ), являющихся отображением функциональных задач (ФЗ) на уровне данных. Физическое проектирование результирующим документом является рабочий документ, к-рый состоит в разработке обеспечивающих систем (ОПС) программного, технического, организационного обеспечении. Изложенный модельный подход к автоматизации проектирования организационных систем управления нашел отражение в технологиях проектирования, названных CASE–технологией.
CASE-технология.
Она явилась ответом на ряд трудностей, возникших при разработке и эксплуатации компьютерных систем. Учитывая неудачу многих проектов, заказщики стремились получить хорошо проработанное обоснование проекта с тестируемым ПО. Однако они невсегда предоставляли разработчикам необходимую инф-ию, относя ее к разряду коммерческой тайны. Сама организация инф-ных потоков менялась по мере расширения деятельности предприятия.. в результате осуществление проекта затягивалось и созданные программно-аппаратные комплексы начинали работать в условиях, когда требования предприятия изменились. Применялся и иной подход. Компьютерный комплекс разрабатывался и вводился в эксплуатацию в короткие сроки специальной фирмой при полном взаимодействии с заказчиком. Это обеспечивало создание работоспособного комплекса, но из-за отсутствия необходимой документации происходили задержки с обучением персонала и выявлялись недоделки, особенно в ПО. Эксплуатация комплекса попадала в зависимость от разработчика и происходила в условиях сбоя и потребности дополнительных затрат на переделки и усовершенствование. Для выхода из этой ситуации была разработана CASE-технология, поддерживающая проектирование, выбор технологий, архитектуры и написания ПО (Computed Aided Software Engineering).
Разработчик с ее помощью описывает предметную область, входящие в нее объекты, их свойства, связи м/у объектами и их свойствами. В результате формируется модель, описывающая основных участников системы, их полномочия, потоки финансовых и иных документов м/у ними. В ходе описания создается электронная версия проекта, к-рая распечатывается и оперативно передается для согласования всем участникам проекта как рабочая документация.
В процессе создания проекта выделяются этапы:
Формирование требований разработчика и выбор варианта концепции системы.
Разработка и утверждение технического задания на систему.
Эскизы и технические проекты с описанием всех компонентов и архитектуры структуры.
Рабочее проектирование, предполагающее разработку и отладку программы, описание структуры БД, создание документации на поставку и установку технических средств.
Ввод действия, предусматривающий установку и включение аппаратных средств, инсталлирующее ПО, загрузку БД, тестирование системы, обучение персонала.
Эксплуатация системы, включающая сопровождение программных средств и всего проекта, поддержку и замену аппаратных средств.
CASE-технология сформировалась в процессе интеграции опыта и новых технологий, появившихся у разработчиков компьютерных систем. Начало этому процессу положили компиляторы и интерпретаторы с алгоритмических языков, затем добавились средства тестирования программ и их отладка, средства генерации отчета. Для обмена инф-ей в проектных организациях и обеспечение оперативного доступа к создаваемой документации, были разработаны средства инф-ной поддержки и управления объектом. В результате была создана система проектирования, к-рая поддерживает все технологические этапы проекта, обеспечивает его документирование и согласованную работу групп разработчиков, как со стороны заказчика так и со стороны исполнителя. В настоящее время существует много CASE-систем, различающиеся по степени компьютерной поддержки, этапов разработки проекта, часть из обеспечивает только графическое представление функций учреждения и потоков инф-ии м/у ними. В других автоматичен процесс описания БД и составление некоторых программ или их частей. В основе CASE-технологии лежит процесс выявления функций отдельных элементов систем и инф-ных потоков, каждое рабочее место описывается как технологический модуль, в к-ром происходит преобразование инф-ии. Каждому модулю устанавливается механизм, в соответствии с к-рым он изменяет находящиеся в нем данные и функции в зависимости от управляющих параметров и инф-ии, полученной от оператора или других модулей. Модуль системы может передавать инф-ию, может управлять функциями с другого модуля. Для связанных м/у собой функциональных блоков устанавливается механизм, описывающий правила их взаимодействия. В конечном итоге составляется полная модель, к-рая может быть рассчитана на бумаге с внесением всех необходимых пояснений и модификаций.
Описание инф-ных потоков в учреждениях во многих CASE-системах производится с помощью ER-модели (Entity Relationship), сущность – отношения. Порядок построения такой модели и используемые при этом абстракции определяются CASE-методом, без освоения к-рого CASE-технология не может быть применена в полном объеме. В процессе построения ER-модели CASE-система проверяет соответствующие программы на непротиворечивость, что позволяет на разных этапах проектирования выявлять ошибки и не допускать некачественное моделирование БД и написание программ, исправление к-рых на последующих этапах затруднительно и требует значительных материальных затрат. С помощью средств описания ER-модели создаются графические изображение инф-ных потоков, а также словарь проекта, к-рый включает в себя упорядоченную инф-ию о функциях, связях и участниках системы. Проектировщик может использовать для описания своих объектов атрибуты уже содержащиеся в словаре. Инф-ия словаря может быть распечатана и превращена в часть документа проекта. Инструменты CASE-технологий на основе ER-модели могут генерировать описание (таблицы), диалоговые процедуры, а также средства вывода данных и довести проект до стадии тестирования и опытной эксплуатации. Этот инструмент применяется и для внесения изменений в дальнейшем.
Достоинства CASE-технологий.
Повышение производительности труда программиста на несколько порядков.
Возможность формализовать документирование и администрирование проекта.
Минимизация ошибок и несовершенства ПО конечного пользователя.
Ускорение обучения персонала и использования ПО в полном объеме.
Постоянное обновление и модернизация пользовательских программ.
Наиболее известной CASE-технологией в нашей стране является Oracle, позволяющей создать приложения на базе одноименной СУБД. В ее основе лежит CASE-метод проектирования "сверху - вниз" - от общих решений к частным.
Этапы Oracle:
Выработка стратегии.
Анализ объекта
Проектирование
Реализация
Внедрение
Эксплуатация
ER-модель строится на этапе анализа объекта, а СУБД на проектировании. Oracle состоит из инструментальных средств: CASE Dictionary. hip (для графического представления моделей), CASE Generator (автоматическое генерирование программных модулей).
Ожидается, что средства компьютерной поддержки в процессе проектирования будет быстро развиваться, обеспечивая генерацию все большего объема программ, и что повысится производительность труда программиста и качество самих продуктов.