

Состав nvidia cuda
CUDA включает два API: высокого уровня (CUDA Runtime API) и низкого (CUDA Driver API), хотя в одной программе одновременное использование обоих невозможно, нужно использовать или один или другой. Высокоуровневый работает «сверху» низкоуровневого, все вызовы runtime транслируются в простые инструкции, обрабатываемые низкоуровневым Driver API. Но даже «высокоуровневый» API предполагает знания об устройстве и работе видеочипов NVIDIA, слишком высокого уровня абстракции там нет.
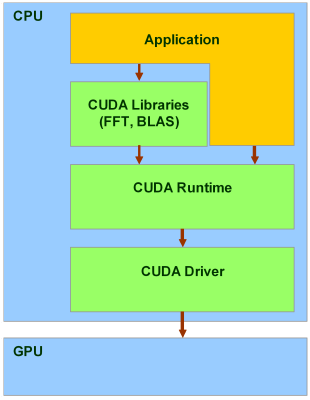
Есть и ещё один уровень, даже более высокий — две библиотеки:
CUBLAS — CUDA вариант BLAS (Basic Linear Algebra Subprograms), предназначенный для вычислений задач линейной алгебры и использующий прямой доступ к ресурсам GPU;
CUFFT — CUDA вариант библиотеки Fast Fourier Transform для расчёта быстрого преобразования Фурье, широко используемого при обработке сигналов. Поддерживаются следующие типы преобразований: complex-complex (C2C), real-complex (R2C) и complex-real (C2R).
Рассмотрим эти библиотеки подробнее. CUBLAS — это переведённые на язык CUDA стандартные алгоритмы линейной алгебры, на данный момент поддерживается только определённый набор основных функций CUBLAS. Библиотеку очень легко использовать: нужно создать матрицу и векторные объекты в памяти видеокарты, заполнить их данными, вызвать требуемые функции CUBLAS, и загрузить результаты из видеопамяти обратно в системную. CUBLAS содержит специальные функции для создания и уничтожения объектов в памяти GPU, а также для чтения и записи данных в эту память. Поддерживаемые функции BLAS: уровни 1, 2 и 3 для действительных чисел, уровень 1 CGEMM для комплексных. Уровень 1 — это векторно-векторные операции, уровень 2 — векторно-матричные операции, уровень 3 — матрично-матричные операции.
CUFFT — CUDA вариант функции быстрого преобразования Фурье — широко используемой и очень важной при анализе сигналов, фильтрации и т.п. CUFFT предоставляет простой интерфейс для эффективного вычисления FFT на видеочипах производства NVIDIA без необходимости в разработке собственного варианта FFT для GPU. CUDA вариант FFT поддерживает 1D, 2D, и 3D преобразования комплексных и действительных данных, пакетное исполнение для нескольких 1D трансформаций в параллели, размеры 2D и 3D трансформаций могут быть в пределах [2, 16384], для 1D поддерживается размер до 8 миллионов элементов.
Модель программирования cuda
Повторимся, что CUDA использует параллельную модель вычислений, когда каждый из SIMD процессоров выполняет ту же инструкцию над разными элементами данных параллельно. GPU является вычислительным устройством, сопроцессором (device) для центрального процессора (host), обладающим собственной памятью и обрабатывающим параллельно большое количество потоков. Ядром (kernel) называется функция для GPU, исполняемая потоками (аналогия из 3D графики — шейдер).
Мы говорили выше, что видеочип отличается от CPU тем, что может обрабатывать одновременно десятки тысяч потоков, что обычно для графики, которая хорошо распараллеливается. Каждый поток скалярен, не требует упаковки данных в 4-компонентные векторы, что удобнее для большинства задач. Количество логических потоков и блоков потоков превосходит количество физических исполнительных устройств, что даёт хорошую масштабируемость для всего модельного ряда решений компании.
Модель программирования в CUDA предполагает группирование потоков. Потоки объединяются в блоки потоков (thread block) — одномерные или двумерные сетки потоков, взаимодействующих между собой при помощи разделяемой памяти и точек синхронизации. Программа (ядро, kernel) исполняется над сеткой (grid) блоков потоков (thread blocks). Одновременно исполняется одна сетка. Каждый блок может быть одно-, двух- или трехмерным по форме, и может состоять из 512 потоков на текущем аппаратном обеспечении.
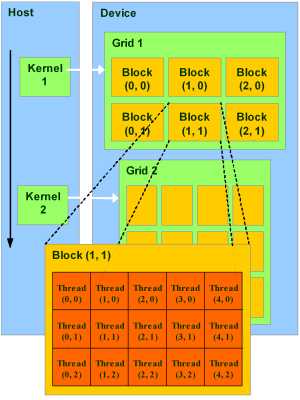
Блоки потоков выполняются в виде небольших групп, называемых варп (warp), размер которых — 32 потока. Это минимальный объём данных, которые могут обрабатываться в мультипроцессорах. И так как это не всегда удобно, CUDA позволяет работать и с блоками, содержащими от 64 до 512 потоков.
Группировка блоков в сетки позволяет уйти от ограничений и применить ядро к большему числу потоков за один вызов. Это помогает и при масштабировании. Если у GPU недостаточно ресурсов, он будет выполнять блоки последовательно. В обратном случае, блоки могут выполняться параллельно, что важно для оптимального распределения работы на видеочипах разного уровня, начиная от мобильных и интегрированных.