

Быстродействие памяти
Извечная проблема большинства вычислительных систем заключена в том, что память работает медленнее процессора. Производители CPU решают ее путем введения кэшей. Наиболее часто используемые участки памяти помещается в сверхоперативную или кэш-память, работающую на частоте процессора. Это позволяет сэкономить время при обращении к наиболее часто используемым данным и загрузить процессор собственно вычислениями.
Заметим, что кэши для программиста фактически прозрачны. Как при чтении, так и при записи данные не попадают сразу в оперативную память, а проходят через кэши. Это позволяет, в частности, быстро считывать некоторое значение сразу же после записи.
На GPU (здесь подразумевается видеокарты GF восьмой серии) кэши тоже есть, и они тоже важны, но этот механизм не такой мощный, как на CPU. Во-первых, кэшируется не все типы памяти, а во-вторых, кэши работают только на чтение.
На GPU медленные обращения к памяти скрывают, используя параллельные вычисления. Пока одни задачи ждут данных, работают другие, готовые к вычислениям. Это один из основных принципов CUDA, позволяющих сильно поднять производительность системы в целом
Области применения параллельных расчётов на gpu
Чтобы понять, какие преимущества приносит перенос расчётов на видеочипы, приведём усреднённые цифры, полученные исследователями по всему миру. В среднем, при переносе вычислений на GPU, во многих задачах достигается ускорение в 5-30 раз, по сравнению с быстрыми универсальными процессорами. Самые большие цифры (порядка 100-кратного ускорения и даже более!) достигаются на коде, который не очень хорошо подходит для расчётов при помощи блоков SSE, но вполне удобен для GPU.
Это лишь некоторые примеры ускорений синтетического кода на GPU против SSE-векторизованного кода на CPU (по данным NVIDIA):
Флуоресцентная микроскопия: 12x;
Молекулярная динамика (non-bonded force calc): 8-16x;
Электростатика (прямое и многоуровневое суммирование Кулона): 40-120x и 7x.
А это табличка, которую очень любит NVIDIA, показывая её на всех презентациях, на которой мы подробнее остановимся во второй части статьи, посвящённой конкретным примерам практических применений CUDA вычислений:
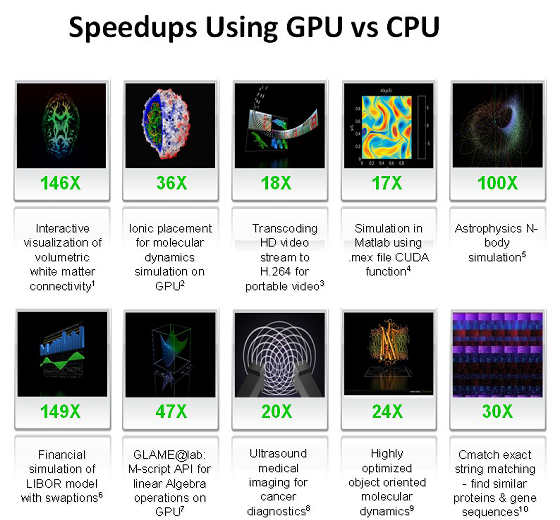
Как видите, цифры весьма привлекательные, особенно впечатляют 100-150-кратные приросты. В следующей статье, посвящённой CUDA, мы подробно разберём некоторые из этих цифр. А сейчас перечислим основные приложения, в которых сейчас применяются вычисления на GPU: анализ и обработка изображений и сигналов, симуляция физики, вычислительная математика, вычислительная биология, финансовые расчёты, базы данных, динамика газов и жидкостей, криптография, адаптивная лучевая терапия, астрономия, обработка звука, биоинформатика, биологические симуляции, компьютерное зрение, анализ данных (data mining), цифровое кино и телевидение, электромагнитные симуляции, геоинформационные системы, военные применения, горное планирование, молекулярная динамика, магнитно-резонансная томография (MRI), нейросети, океанографические исследования, физика частиц, симуляция свёртывания молекул белка, квантовая химия, трассировка лучей, визуализация, радары, гидродинамическое моделирование (reservoir simulation), искусственный интеллект, анализ спутниковых данных, сейсмическая разведка, хирургия, ультразвук, видеоконференции.
Подробности о многих применениях можно найти на сайте компании NVIDIA в разделе по технологии CUDA. Как видите, список довольно большой, но и это ещё не всё! Его можно продолжать, и наверняка можно предположить, что в будущем будут найдены и другие области применения параллельных расчётов на видеочипах, о которых мы пока не догадываемся.