

Введение
Термины
NVIDIA - американская компания, один из крупнейших разработчиков графических ускорителей и процессоров для них, а также наборов системной логики.
CUDA (Compute Unified Device Architecture) - это технология от компании NVidia, предназначенная для разработки приложений для массивно-параллельных вычислительных устройств (в первую очередь для GPU начиная с серии G80).
GPGPU (англ. General-purpose graphics processing units — «GPU общего назначения») — техника использования графического процессора видеокарты, который обычно имеет дело с вычислениями только для компьютерной графики, чтобы выполнять расчёты в приложениях для общих вычислений, которые обычно проводит центральный процессор.
Графический процессор (англ. graphics processing unit, GPU) — отдельное устройство персонального компьютера или игровой приставки, выполняющее графический рендеринг.
????ЧТО ЕЩЕ МОЖНО????
Глава 1. Неграфические вычисления с применением cuda
Развитие
вычислительных технологий последние
десятки лет шло быстрыми темпами.
Настолько быстрыми, что уже сейчас
разработчики процессоров практически
подошли к так называемому "кремниевому
тупику". Безудержный рост тактовой
частоты стал невозможен в силу целого
ряда серьезных технологических причин.
Отчасти поэтому все производители
современных вычислительных систем идут
в сторону увеличения числа процессоров
и ядер, а не увеличивают частоту одного
процессора. Количество ядер центрального
процессора (CPU) в передовых системах
сейчас уже равняется 8. Другая причина
- относительно невысокая скорость работы
оперативной памяти. Как бы быстро не
работал процессор, узкими местами, как
показывает практика, являются вовсе не
арифметические операции, а именно
неудачные обращения к памяти - кэш-промахи.
Однако если посмотреть в сторону
графических процессоров GPU (Graphics
Processing Unit), то там по пути параллелизма
пошли гораздо раньше. В сегодняшних
видеокартах, например в GF8800GTX, число
процессоров может достигать 128.
Производительность подобных систем
при умелом их программировании может
быть весьма значительной (рис. 1)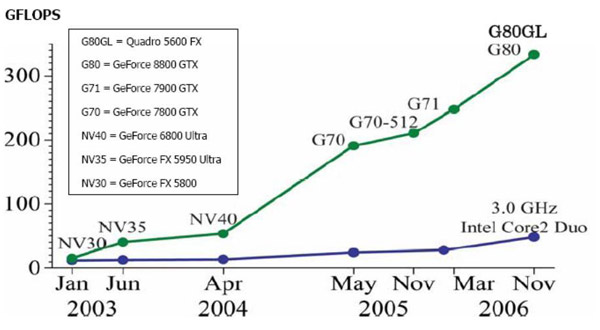 .
.
Когда первые видеокарты только появились в продаже, они представляли собой достаточно простые (по сравнению с центральным процессором) узкоспециализированные устройства, предназначенные для того чтобы снять с процессора нагрузку по визуализации двухмерных данных. С развитием игровой индустрии и появлением таких трехмерных игр как Doom (рис. 2) и Wolfenstein 3D (рис. 3) возникла необходимость в 3D визуализации.
 Рис.
2. Игра Doom
Рис.
2. Игра Doom
 Рис.
3. Игра Wolfenstein 3D
Рис.
3. Игра Wolfenstein 3D
Со времени создания компанией 3Dfx первых видеокарт Voodoo (1996 год) и вплоть до 2001 года в GPU был реализован только фиксированный набор операций над входными данными.
У программистов не было никакого выбора в алгоритме визуализации, и для повышения гибкости появились шейдеры - небольшие программы, выполняющиеся видеокартой для каждой вершины либо для каждого пиксела. В их задачи входили преобразования над вершинами и затенение - расчет освещения в точке, например по модели Фонга.
Хотя в настоящий момент шейдеры получили очень сильное развитие, следует понимать, что они были разработаны для узкоспециализированных задач трехмерных преобразований и растеризации.
В то время как GPU развиваются в сторону универсальных многопроцессорных систем, языки шейдеров остаются узкоспециализированными. Их можно сравнить с языком FORTRAN в том смысле, что они, как и FORTRAN, были первыми, но предназначенными для решения лишь одного типа задач. Шейдеры малопригодны для решения каких-либо других задач, кроме трехмерных преобразований и растеризации, как и FORTRAN не удобен для решения задач, не связанных с численными расчетами.
Сегодня появилась тенденция нетрадиционного использования видеокарт для решения задач в областях квантовой механики, искусственного интеллекта, физических расчетов, криптографии, физически корректной визуализации, реконструкции по фотографиям, распознавания и т.п. Эти задачи неудобно решать в рамках графических API (DirectX, OpenGL), так как эти API создавались совсем для других применений.
Развитие программирования общего назначения на GPU (General Programming on GPU, GPGPU) логически привело к возникновению технологий, нацеленных на более широкий круг задач, чем растеризация. В результате компанией Nvidia была создана технология CUDA, а конкурирующей компанией ATI - технология STREAM.