

19. Проверка равенства двух коэффициентов детерминации
Важным направлением использования статистики Фишера является проверка гипотезы о равенстве нулю не всех коэффициентов регрессии одновременно, а только некоторой части этих коэффициентов.
Пусть первоначально построенное по n наблюдениям уравнение регрессии имеет вид:
Y=b0+b1X1+b2X2+…+bm-kXm-k+…+bmXm
И коэффициент детерминации для этой модели равен R12. Исключим из рассмотрения k объясняющих переменных. По первоначальным n наблюдениям для оставшихся факторов построим другое уравнение регрессии:
Y=c0+c1X1+c2X2+…+cm-kXm-k
Для которого коэф. Детерминации равен R22. Очевидно, R22≤R12, т.к. каждая дополнительная переменная объясняет часть рассеивания зависимой переменной. Возникает вопрос: существенно ли ухудшилось качество описания поведения зависимой переменной Y? На него можно ответить, проверяя гипотезу H0: R12-R22=0 и используя статистику F=[(R12-R22)/(1-R12)][(n-m-1)/k] (1). В случае справедливости H0 приведенная статистика имеет распределение Фишера с числами степеней свободы v1=k, v2=n-m-1. Действительно, соотношение (1) может быть переписано в виде F=[(R12-R22)/k]/[(1-R12)/(n-m-1)]. Здесь (R12-R22) – потеря качества уравнения в результате отбрасывания k объясняющих переменных; k – число дополнительно появившихся степеней свободы; (1-R12)/(n-m-1) – необъясненная дисперсия первоначального уравнения.
По таблицам критических точек распределения Фишера находят Fкр=Fα;m;n-m-1 (α – требуемый уровень значимости). Если рассчитанное значение Fнабл статистики превосходит Fкр, то нулевая гипотеза о равенстве коэффициентов детерминации должна быть отклонена. В этом случае одновременное исключение из рассмотрения k объясняющих переменных некорректно, т.к. существенно превышает R22. Если же наоборот наблюдаемая F-статистика невелика, то это означает, что разность R12-R22 незначительна. Следовательно, можно сделать вывод, что в этом случае одновременное отбрасывание k объясняющих переменных не привело к существенному ухудшению общего качества уравнения регрессии, и оно вполне допустимо.
Аналогичные рассуждения могут быть использованы и по поводу обоснованности включения новых k объясняющих переменных. В этом случае рассчитывается F-статистика F=[(R22-R12)/(1-R22)][(n-m-1)/k].
Добавлять переменные целесообразно, как правило, по одной. Кроме того, при добавлении объясняющих переменных в уравнение регрессии логично использовать скорректированный коэф. детерминации.
20. Проверка гипотезы о совпадении уравнений регрессии для двух выборок. Распространенным тестом проверки данной гипотезы является тест Чоу, суть которого состоит в следующем.
Пусть
имеются две выборки объемами n1,
n2
соответственно. Для каждой из этих
выборок оценено уравнение регрессии
вида: Y=b0k+b1kX1+b2kX2+…+bmkXm+ek,
k= .
Проверяется
нулевая гипотеза о равенстве друг другу
соответствующих коэффициентов регрессии
H0=bj1=bj2,
j=0,1,…,m.
.
Проверяется
нулевая гипотеза о равенстве друг другу
соответствующих коэффициентов регрессии
H0=bj1=bj2,
j=0,1,…,m.
Другими словами будет ли уравнение регрессии одним и тем же для обеих выборок?
Пусть суммы ∑eik2 (k=1,2) квадратов отклонений значений yi от линий регрессии равны S1, S2 соответственно для первого и второго уравнений регрессии. Пусть по объединенной выборке объема (n1+n2) оценено еще одно уравнение регрессии, для которого сумма квадратов отклонений yi от уравнения регрессии равнаS0.
Для проверки H0 в этом случае строится следующая F-статистика: F=[(S0-S1-S2)/(S1+S2)][(n1+n2-2m-2)/(m+1)]
В случае справедливости H0 построенная F-статистика имеет распределение Фишера с числами степеней свободы v1=m+1; v2=n1+n2-2m-2. Очевидно, F-статистика близка к нулю, если S0≈S1+S2, и это фактически означает, что уравнения регрессии для обеих выборок практически одинаковы. В этом случае F>Fкр=Fα;v1;v2. Если же F>Fкр, то нулевая гипотеза отклоняется.
21. Статистика Дарбина-Уотсона. Для анализа коррелированности случайных отклонений используется статистика Дарбина-Уотсона (DW), которая определяется по следующей формуле: DW=∑(ei-ei-1)2/∑ ei2.
Для больших значений n считается, что ∑ei2≈∑ei-12. Тогда ∑(ei-ei-1)2=∑(ei2-2eiei-1+ei-12)=2(∑ei2-∑eiei-1).
Тогда DW=2(∑ei2-∑eiei-1)/∑ei2=2(1-rei,ei-1). Если ei≈ei-1, то rei,ei-1=1, DW=0; если ei≈-ei-1, то rei,ei-1=-1. DW=4; 0<DW<4.
Понятно, что при случайном поведении случайных отклонений в одной половине случаев знаки последовательных отклонений совпадают, а в другом противоположны. А абсолютные значения случайных отклонений в среднем одинаковы DW=∑1/2(2ei)2/∑ei2=2. Следовательно, необходимым условием независимости случайных отклонений является близость к 2 значения DW. Грубым правилом можно считать отсутствие автокорреляции и остатков, если 1,5<DW<2,5
22.
Логарифмические модели.Пусть
некот. эконом. зависимость моделируется
формулой Y=A* , (7.1) где А и β – параметры модели (т. е.
константы, подлежащие определению).
Эта функция может отражать зависимость
спроса Y на благо от его цены X (в данном
случае β < 0) или от дохода Х (в данном
случае β > 0; при такой интерпретации
переменных Х и Y функция (7.1) назыв.
функцией Энгеля). Функция (7.1) может
отражать также зависимость объема
выпуска Y от использования ресурса Х
(производ- ственная функция), в которой
0 < β < 1, а также ряд других зависимостей.
Для упрощения выкладок случайное
отклонение ε введем в соотношение
позднее. Модель (7.1) не является линейной
функцией относительно Х. Стандартным
и широко исп-м подходом к анализу функцией
данного рода в эконометрике является
лога-рифмирование по экспоненте (по
основанию e = 2.71828…). Такие логарифмы
назыв. натур. логарифмами и обозначаются
lnY, lnX. Прологарифмировав обе части
(7.1), имеем:
, (7.1) где А и β – параметры модели (т. е.
константы, подлежащие определению).
Эта функция может отражать зависимость
спроса Y на благо от его цены X (в данном
случае β < 0) или от дохода Х (в данном
случае β > 0; при такой интерпретации
переменных Х и Y функция (7.1) назыв.
функцией Энгеля). Функция (7.1) может
отражать также зависимость объема
выпуска Y от использования ресурса Х
(производ- ственная функция), в которой
0 < β < 1, а также ряд других зависимостей.
Для упрощения выкладок случайное
отклонение ε введем в соотношение
позднее. Модель (7.1) не является линейной
функцией относительно Х. Стандартным
и широко исп-м подходом к анализу функцией
данного рода в эконометрике является
лога-рифмирование по экспоненте (по
основанию e = 2.71828…). Такие логарифмы
назыв. натур. логарифмами и обозначаются
lnY, lnX. Прологарифмировав обе части
(7.1), имеем:
lnY= lnA+ вlnX . (7.2) После замены lnA = β 0 , (7.2) примет вид: вlnY =в0+ вlnX . (7.3) С целью статистической оценки коэф-тов добавим в м-ль случайную погрешность ε и получим так называемую двойную логар-ю м-ль (и зависимая переменная и объясняющая переменная заданы в логарифмическом виде): lnY=в0+ вlnX+е. (7.4) Не являясь линейным относительно X и Y, данное ур-е явл. линейным относительно lnX и lnY, а также относительно параметров β 0 и β 1. Вводя замены и Y*= lnY и X*= lnX, (7.4) можно перепис. в виде: Y*=в0+ вX*+е. (7.5)
Модель (7.5) является лин. м-лью. Если все необх. предпосылки классич. ли н. регрессионной модели для (7.5) выполнены, то по МНК можно определить наилучшие линейные несмещенные оценки коэфф-в β 0 и β. Отметим, что коэфф-т β определяет эластичность перемен-ной Y по переменной Х, т. е. процентное изменение Y для данного процентного изменения Х. Действительно, продифференцировав ле-вую и правую части (7.4) по Х, получим:
 )
(7.6) Отметим, что в дан. случае коэфф. β
является константой, указывая на пост.
эластичность. Поэтому зачастую двойная
лог. м-ль наз. м-лью пост. эла- стичности.
)
(7.6) Отметим, что в дан. случае коэфф. β
является константой, указывая на пост.
эластичность. Поэтому зачастую двойная
лог. м-ль наз. м-лью пост. эла- стичности.
Заметим,
что в случае парной регрессии обоснованность
исполь- зования логарифмической модели
проверить достаточно просто. Вме- сто
наблюдений ( ,
)
рассм. наблюдения (ln
,
ln
),
i = 1, 2, …, n. Вновь полученные точки
наносятся на корреляционное поле. Если
их расположение соответствует прямой
линии, то произведенная замена удачна
и исп. лог. м-ли обосновано. Данная м-ль
легко обобщается на большее число
переменных. Например,
,
)
рассм. наблюдения (ln
,
ln
),
i = 1, 2, …, n. Вновь полученные точки
наносятся на корреляционное поле. Если
их расположение соответствует прямой
линии, то произведенная замена удачна
и исп. лог. м-ли обосновано. Данная м-ль
легко обобщается на большее число
переменных. Например,

23. Полулогарифмич-е модели. Модели вида lnY=b0+bX+e (лог-линейная) и Y=b0+blnX+e (линейно-логарифмич-ая) назыв-ся полулогарифмич-ми мод-ми. Такие модели обычно исп-ют в тех случаях, когда необх-мо опред-ть темп роста или прироста каких-либо эконом-их показателей. Напр-р, или при анализе банк-го вклада по первонач-ому вкладу и %-ой ставке, прироста объема выпуска от относит-го (%-го) увелич-я затрат ресурса, бюджетный дефицит от темпа роста ВНП, темп роста инфляции от объема денежной массы и т.д.
24.
Обратная модель.
Модель
вида
 азывается
обратной моделью. Эта модель сводится
к линейной заменой
азывается
обратной моделью. Эта модель сводится
к линейной заменой
 .
Данная модель обычно применяется в тех
случаях, когда неограниченное увеличение
объясняющей переменной Х асимптотически
приближает зависимую переменную Y
к некоторому пределу (в данном случае
к
.
В зависимости от знаков
и
.
Данная модель обычно применяется в тех
случаях, когда неограниченное увеличение
объясняющей переменной Х асимптотически
приближает зависимую переменную Y
к некоторому пределу (в данном случае
к
.
В зависимости от знаков
и
 характерны
следующие ситуации:
характерны
следующие ситуации:
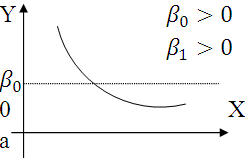


График
а может отражать зависимость между
объемом выпуска (Х) и средними фиксированными
издержками (У). График б может отражать
зависимость между доходом Х и спросом
на блага У так называемые функции
Торнквиста ( в этом случае
 - минимально необходимый уровень). Важным
приложением графика, изображенного на
рис. в является кривая Филлипса, отражающая
зависимость между уровнем безработицы
(Х) в процентах и процентным изменениям
заработной платы (У). При этом точка
пересечения кривой с осью 0Х определяет
естественный уровень безработицы.
- минимально необходимый уровень). Важным
приложением графика, изображенного на
рис. в является кривая Филлипса, отражающая
зависимость между уровнем безработицы
(Х) в процентах и процентным изменениям
заработной платы (У). При этом точка
пересечения кривой с осью 0Х определяет
естественный уровень безработицы.
25
Степенная модель.
 Степенная
функция вида при m=3 (кубическая функция)
в микроэкономике моделирует зависимость
общих издержек от объема выпуска;
квадратичная функция (m=2) отражает
зависимость между объемом выпуска и
средними или предельными издержками
(или между расходами на рекламу и
прибылью). Модель может быть сведена к
линейной модели множественной регрессии
с помощью замены . X→
Степенная
функция вида при m=3 (кубическая функция)
в микроэкономике моделирует зависимость
общих издержек от объема выпуска;
квадратичная функция (m=2) отражает
зависимость между объемом выпуска и
средними или предельными издержками
(или между расходами на рекламу и
прибылью). Модель может быть сведена к
линейной модели множественной регрессии
с помощью замены . X→ ,
, ….
…. Параметры модели ищут с помощью МНК.
Параметры модели ищут с помощью МНК.