

Интервальное оценивание. Доверительный интервал для дисперсии.
Доверительный
интервал для мат.ожидания m
![]()


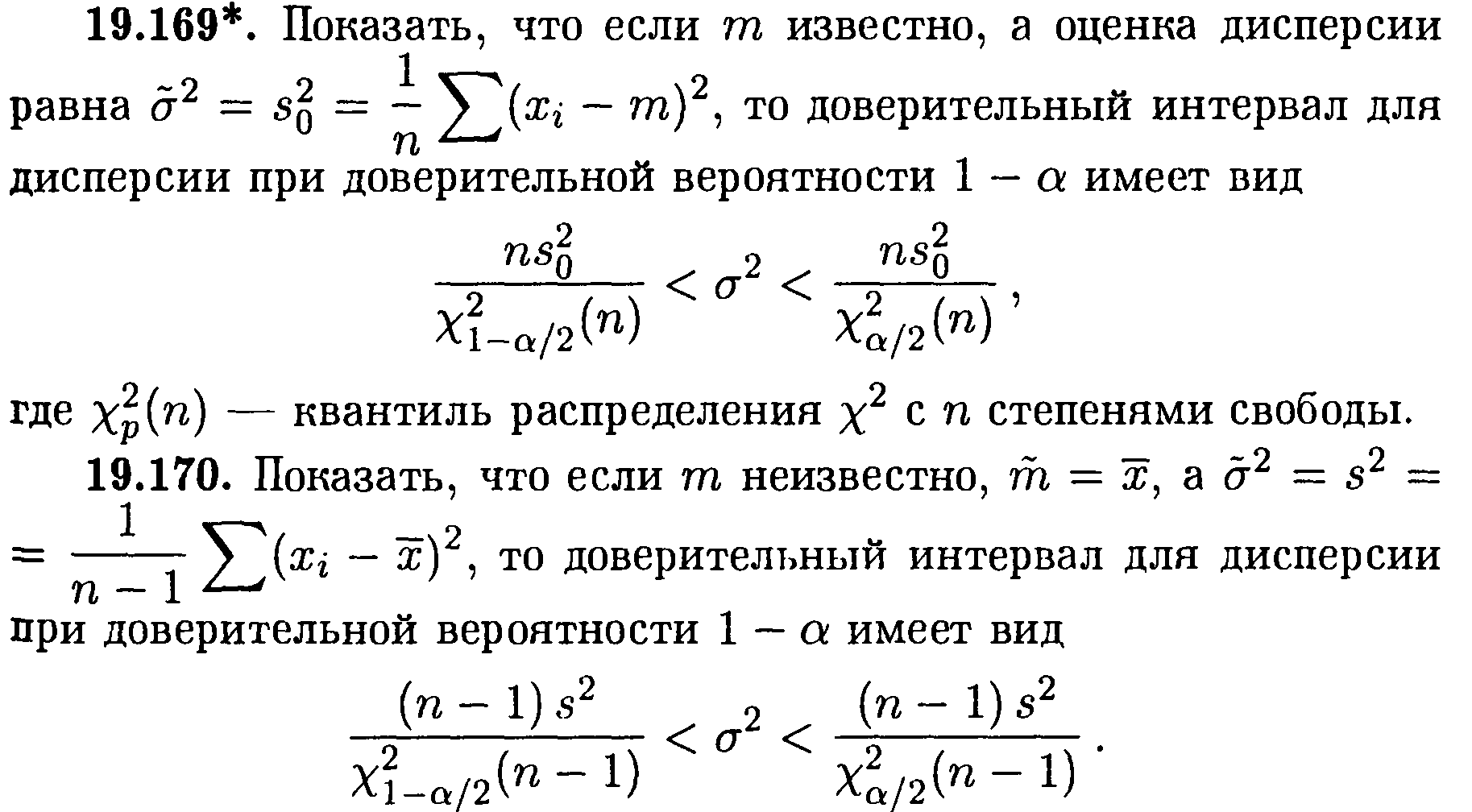
Известно,
что величина (п-1)(![]() )2
распределена по закону
)2
распределена по закону
![]() ,
которым и нужно воспользоваться для
построения доверительного интервала.
Этот закон не симметричный, поэтому
нужно определять левую и правую границы
отдельно. Допустим, что доверительная
вероятность равна
,
которым и нужно воспользоваться для
построения доверительного интервала.
Этот закон не симметричный, поэтому
нужно определять левую и правую границы
отдельно. Допустим, что доверительная
вероятность равна
![]() .
Тогда вероятность того, что величина
будет
лежать правее левой границы доверительного
интервала можно взять равной
.
Тогда вероятность того, что величина
будет
лежать правее левой границы доверительного
интервала можно взять равной
![]() ,
а вероятность того, что она окажется
больше правой границы, будет равна
1-
,
а вероятность того, что она окажется
больше правой границы, будет равна
1-![]() /2.
Зададим доверительную вероятность
равной 0,9. Тогда
/2.
Зададим доверительную вероятность
равной 0,9. Тогда
![]() .
Вероятность «левой границы» будет 0,95
, а правой 0,05. Допустим, что объём выборки
равен п=10,
следовательно число степеней свободы
при вычислении оценки дисперсии равно
т=9.
Из таблицы
- распределения, помещённой в справочнике
И.Н. Бронштейна и К.А.Семендяева, находим
.
Вероятность «левой границы» будет 0,95
, а правой 0,05. Допустим, что объём выборки
равен п=10,
следовательно число степеней свободы
при вычислении оценки дисперсии равно
т=9.
Из таблицы
- распределения, помещённой в справочнике
И.Н. Бронштейна и К.А.Семендяева, находим
![]() ,
,
![]() .
Следовательно 3,32
.
Следовательно 3,32![]() .
После пересчёта окончательно будем
иметь 0.72
.
После пересчёта окончательно будем
иметь 0.72![]() .
Это и есть доверительный интервал для
дисперсии.
.
Это и есть доверительный интервал для
дисперсии.
Доверительный интервал для среднего и разности средних.
Доверительные интервалы для среднего задают область вокруг среднего, в которой с заданным уровнем доверия содержится "истинное" среднее популяции. В Основных статистиках вы можете построить доверительные интервалы для любого p-уровня; например, если среднее в вашей выборке равно 23, а нижняя и верхняя границы для p=.05 равны 19 и 27 соответственно, то вы можете заключить, что с 95% вероятностью среднее выборки больше 19 и меньше 27.

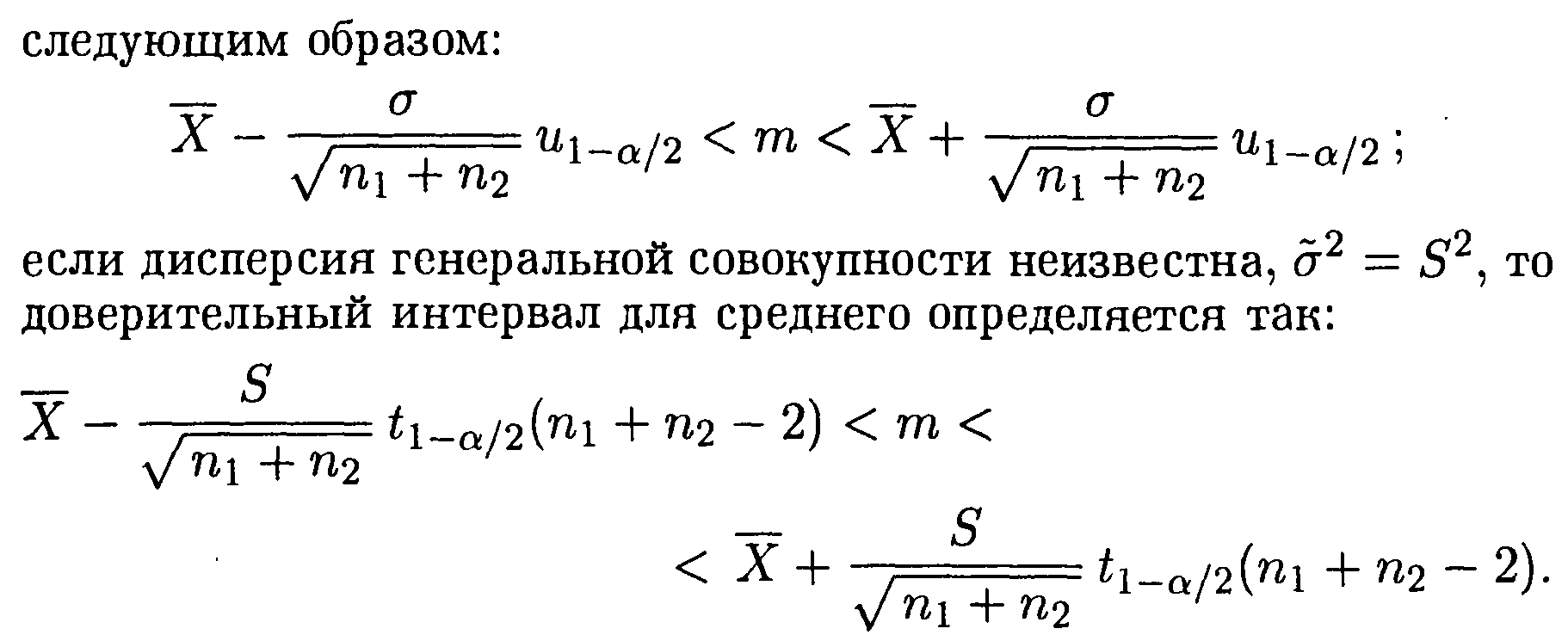
Говоря более точно, если вы последовательно вычисляете этот по большому количеству независимых случайных выборок одинакового размера, то 95% этих интервалов будут, действительно, включать в себя истинные значения среднего, т. е. в 95% случаев вы окажетесь правы, утверждая, что истинное значение среднего содержится внутри данного доверительного интервала. Таким образом, выражаясь технически, значение 95% относится к процедуре построения статистического интервала, а не к самому наблюдаемому интервалу.
Если вы установите меньшее значение p-уровня, то интервал будет шире, и увеличится "уверенность" в оценке, и наоборот; как мы знаем из прогнозов погоды, чем "неопределеннее" прогноз (т.е. шире доверительный интервал), тем скорее он сбудется. Заметим, что ширина доверительного интервала зависит от размера выборки и дисперсии наблюдений. Вычисление доверительных интервалов основывается на предположении, что переменная в совокупности нормально распределена. Эта оценка может быть неверной, если это предположение не выполнено, и пока размер выборки мал, например, n меньше 100.
Доверительный
интервал для разности средних ![]() .
Оценка
.
Оценка ![]() вычисляется:
вычисляется: ![]() .
.
![]() < m1-m2<
< m1-m2<
![]()
![]() < m1-m2<
< m1-m2<
![]()
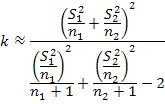
Проверка стат. Гипотез. Классификация гипотез. Критерий. Статистика критерия. Уровень значимости. Критическая область. Ошибки 1-го в 2-го рода.
Статистическая гипотеза представляет собой некоторое предположение о законе распределения случайной величины или о параметрах этого закона, формулируемое на основе выборки. Статистическая гипотеза Н называется простой, если она однозначно определяет распределение случайной величины Х, в противном случае гипотеза Н называется сложной. Примерами статистических гипотез являются предположения: о виде закона распределения и параметрах двух распределений. Гипотезу, утверждающую, что различие между сравниваемыми характеристиками отсутствует, а наблюдаемые отклонения объясняются лишь случайными колебаниями в выборках, на основании которых производится сравнение, называют нулевой (основной) гипотезой и обозначают Н0. Наряду с основной гипотезой рассматривают и альтернативную (конкурирующую, противоречащую) ей гипотезу Н1. И если нулевая гипотеза будет отвергнута, то будет иметь место альтернативная гипотеза. Принятие или отклонение гипотезы Н0 по случайной выборке соответствует истине с некоторой вероятностью и, соответственно, возможны два рода ошибок. Ошибка первого рода возникает с вероятностью a тогда, когда отвергается верная гипотеза Н0 и принимается конкурирующая гипотеза Н1. Ошибка второго рода возникает с вероятностью b в том случае, когда принимается неверная гипотеза Н0, в то время как справедлива конкурирующая гипотеза Н1. Множество S0 называется областью принятия гипотезы или областью допустимых значений, а множество S1 – областью отклонения гипотезы или критической областью. При проверке гипотез широкое применение находит ряд теоретических законов распределения. Наиболее важным из них является нормальное распределение. С ним связаны распределения хи-квадрат, Стьюдента, Фишера.

