

Контрольные вопросы и задания
Изложите методические приемы аппроксимации рядов распределения случайной величины.
В чем заключается сущность закона нормального распределения случайной величины ?
Изложите особенности логнормального распределения случайной величины.
Опишите статистические модели гамма- и бета- распределения случайной величины.
Изложите методику выравнивания частот по функции распределения Пуассона.
Изложите методику расчета теоретических частот по типам кривых распределения Джонсона и Пирсона.
Глава 4.
Критерии оценки статистических гипотез
4.1. Постановка задачи
Понятие статистической гипотезы предполагает проведение статистической оценки для объективного подтверждения или отклонения рассматриваемого предположения. Статистические гипотезы подразделяют на виды:
параметрические (требуется вычисление параметров распределения - среднего, дисперсии и т.д.);
непараметрические (не требуется вычисление параметров распределений).
Пример 4.1. Параметрическими гипотезами являются утверждения: средние значения диаметров деревьев в двух выборках равны между собой, дисперсии значений высот деревьев в двух выборках не равны между собой и т.д. Непараметрическими гипотезами являются утверждения: распределение деревьев по диаметру в древостое подчиняется закону нормального распределения, рост древостоя по высоте описывается экспоненциальной кривой и т.д.
На основании статистической оценки решается вопрос: принять или опровергнуть гипотезу. Для решения этого вопроса необходимо выполнить следующее:
рассмотреть не только проверяемую гипотезу, но и исключающую ее альтернативную гипотезу;
выбрать статистический критерий - показатель, разделяющий доверительные зоны, каждая из которых свидетельствует о наличии проверяемой или альтернативной гипотезы.
Более подробно остановимся на критериях, позволяющих ответить на следующие наиболее часто возникающие в лесохозяйственной практике вопросы:
относится ли та или иная варианта к данной статистической совокупности?
соответствует ли данное эмпирическое распределение тому или иному теоретическому распределению?
являются ли данные эмпирические совокупности выборками из одной и той же генеральной совокупности?
Первый вопрос в общем ставится так. Имеется некоторая выборочная статистическая совокупность. Некоторые варианты очень далеко отстоят от среднего значения, и возникает сомнение, является ли это результатом маловероятных, но все же возможных больших отклонений от центра соответствующей генеральной совокупности, или же результатом того, что в рассматриваемую выборку почему-то оказались включенными варианты, принадлежащие в действительности к другой генеральной совокупности.
Второй вопрос возникает в связи с тем, что из-за случайности в образовании выборки распределение вариант в выборке всегда отличается от их распределения в генеральной совокупности; поэтому если в генеральной совокупности варианты распределены по определенному теоретическому закону, то распределение в выборке будет заведомо отклоняться от этого закона. (Отсюда следует, что сам факт отклонения выборочного распределения от того или иного теоретического распределения еще не дает основания утверждать, что и в генеральной совокупности распределение не подчиняется данному теоретическому закону.) Таким образом, вопрос сводится к тому, можно ли расхождение между выборочным и предположенным теоретическим распределениями отнести за счет расхождения между выборкой и генеральной совокупностью или же оно является результатом того, что сама генеральная совокупность отклоняется от данного теоретического распределения.
Сущность третьего вопроса совершенно аналогична: расхождение между эмпирическими распределениями может быть просто расхождением между разными выборками из одной и той генеральной совокупности, но может также объясняться тем, что они выбраны из разных генеральных совокупностей.
Во всех трех случаях приходится ответить на вопрос о том, является ли наблюдаемое различие между объектами отражением какого-то реального различия или же оно есть результат случайности, сопровождающей попадание вариант в выборку. Это позволяет сформулировать общий подход к решению всех этих задач. В любом случае задача может быть сведена к проверке гипотезы об отсутствии реального различия. Эту гипотезу называют нулевой гипотезой; обычно для нее применяется специальное обозначение Нo. Ее сущность сводится к предположению, что разница между генеральными параметрами сравниваемых групп равна нулю и что различия, наблюдаемые между выборочными характеристиками, носят не систематический, а исключительно случайный характер. Так, если одна выборка извлечена из нормально распределенной совокупности с параметрами x и x, а другая из совокупности с параметрами y и y, то нулевая гипотеза исходит из того, что x = y и x = y . Противоположная нулевой - альтернативная гипотеза Нa - исходит из предположения, что x y и x y .
В первой задаче нулевая гипотеза гласит о том, что сомнительная варианта принадлежит к той же генеральной совокупности, что и данная эмпирическая совокупность. Во второй задаче проверке подлежит нулевая гипотеза о том, что различие между выборочным распределением и теоретическим является случайным, то есть, что нет реального различия между распределением в генеральной совокупности, из которой взята выборка, и предположенным теоретическим распределением. В третьей задаче нулевая гипотеза состоит в том, что данные эмпирические совокупности являются выборками из одной и той же генеральной совокупности, так что между генеральными совокупностями, выборками из которых являются данные эмпирические совокупности, нет реального различия.
Правильность нулевой гипотезы можно проверить следующим образом. Предположив справедливость нулевой гипотезы, т. е. отсутствие реального различия, мы вычисляем вероятность того, что из-за случайности выборки расхождение может достигнуть фактически наблюденной величины; если эта вероятность окажется очень малой, то нулевая гипотеза отвергается (т. е. маловероятно, что расхождение вызвано случайными причинами, а не реальным различием).
Предельно допустимое значение вероятности, начиная с которого вероятность можно считать малой, называют уровнем значимости. Различие считается значимым (т. е. реальным), если вероятность того, что нулевая гипотеза верна, меньше уровня значимости (его обозначают буквой ).
Очевидно, уровень значимости характеризует, в какой мере мы рискуем ошибиться, отвергая нулевую гипотезу. Этот выбор в значительной мере определяется конкретными задачами исследования. Например, если исследуется новый лечебный препарат и нужно показать, что его побочное действие не опасно для жизни, то даже уровень значимости 0,1% должен считаться не слишком высоким. Наоборот, если речь идет об улучшении продуктивности древостоя за счет недорогого внесения удобрений, то достаточно и небольшой уверенности о положительном результате. При этом, разумеется, не исключаются дальнейшие уточнения экспериментальных данных (например, путем постановки дополнительных опытов, последующих наблюдений и т. д.). В лесохозяйственных исследованиях часто считают достаточным 5%-й уровень значимости (вероятность ошибочной оценки P=0,05). При этом нулевую гипотезу не отвергают, если P>0,05. Если же P<0,05, то нулевую гипотезу следует отвергнуть на принятом уровне значимости .
В общем виде использование статистических критериев (К) в области лесного дела при строгом доказательстве нулевой гипотезы можно представить схематически:
K05 > Kф > K01
 Не
отвергается
Отвергается
Не
отвергается
Отвергается


Н у л е в а я г и п о т е з а
где
Kф – значение фактически полученного критерия;
K05, K01 - значения критериев на 5% -ном и 1% -ном уровнях зна - чимости.
Необходимо всегда иметь в виду, что утверждение о том, что нет достаточных оснований отвергать гипотезу об отсутствии различия, вовсе не равносильно утверждению, что отсутствие различия доказано. Иными словами, можно лишь утверждать, что данные наблюдений не противоречат предположению об отсутствии различия, но нельзя утверждать, что эти данные доказывают отсутствие такого различия. Ошибка, которая допускается, когда не отвергают гипотезу Hо, в действительности неверную, носит название ошибки II рода, в отличие от рассмотренной выше ошибки I рода, когда отвергают гипотезу Hо, на самом деле верную. Вероятность ошибки II рода обозначается β.
В лесном хозяйстве применяют два вида статистических критериев:
параметрические, построенные на основании параметров данной выборки (например, M, s и т.д.);
непараметрические, представляющие собой функции, зависящие непосредственно от вариант данной выборки с их частотами.
При нормальном распределении признака параметрические критерии обладают большей мощностью, чем непараметрические критерии. Они способны безошибочно отвергать нулевую гипотезу, если она не верна. В случае очень больших отличий распределений признака от нормального вида следует применять непараметрические критерии, которые в этой ситуации оказываются часто более мощными. В случаях, когда варьирующие признаки выражаются условными знаками, применение непараметрических критериев оказывается единственно возможным.
4.2. Проверка гипотезы о принадлежности варианты к совокупности
При статистической обработке биологического материала часто сталкиваются с наличием в исследуемой совокупности некоторого количества вариант, значения которых довольно резко отличаются от основной массы наблюдений. Появление таких вариант может объясняться естественной вариабильностью случайной величины, вследствие которой большие отклонения от центра распределения не исключены. Они могут также свидетельствовать о неоднородности статистической совокупности. Если вариантами являются значения какого-либо показателя для разных особей некоторой популяции, то неоднородность будет следствием попадания в совокупность особей из другой биологической популяции; если вариантами являются результаты каких-то повторных замеров на одном и том же объекте, то неоднородность будет следствием спорадических нарушений стандартных условий эксперимента.
Конечно, появление резко выделяющихся вариант указывает прежде всего на необходимость тщательной проверки исследуемой популяции или обстановки эксперимента. При этом варианты, условия получения которых противоречили стандарту, должны отбрасываться независимо от их значений. Однако во многих случаях не удается получить прямых указаний о неоднородности изучаемой совокупности. Тогда приходится прибегать к статистическим критериям.
Применение последних основано на том, что если распределение вариант в генеральной совокупности нормально или близко к нормальному, то появление в выборке вариант, далеко отклоняющихся от центра распределения, хотя и возможно, но очень маловероятно.
Очевидно, при построении критерия исключения (соответствующее критическое значение обозначим τ) надо исходить из условия, что в выборке данного объема n из нормальной генеральной совокупности не должно содержаться, с определенной вероятностью Р, ни одной варианты, отклоняющейся от x больше, чем на τ. Выбранный уровень значимости
= 1 - Р имеет здесь тот смысл, что если выбрать из нормальной генеральной совокупности большое число выборок объема n каждая, то в среднем лишь в 100 процентах из них будут попадаться варианты вне пределов х , а 100 (1 — ) = 100Р процентов выборок не будут содержать вариант вне этих пределов. Из сказанного ясно, что критические значения τ должны зависеть как от принятого уровня значимости , так и от объема выборки n.
Табл. 4.1 содержит некоторые критические значения τ(n). При построении критерия принято во внимание то, что значения μ и σ обычно неизвестны и заменяются их оценками M и s, так что
τmax = (xmax - M)/s; τmin = (M-xmin)/s. (4.1)
Таблица 4.1
τα |
5% |
1,92 |
2,41 |
2,78 |
2,96 |
3,08 |
3,16 |
3,22 |
3,40 |
3,61 |
1% |
1,97 |
2,62 |
3,08 |
3,29 |
3,42 |
3,52 |
3,58 |
3,77 |
3,98 |
|
n |
5 |
10 |
20 |
30 |
40 |
50 |
60 |
100 |
200 |
|
Пример 4.2. На рис 4.1 в среде пакета MS Excel дано распределение по весу семян определенной древесной породы, взятых из семенного фонда. Обращает на себя внимание присутствие в этой совокупности трех семян с весом 22 мг, очень сильно отклоняющимся от среднего для данного сорта веса 31,74 мг. Объяснение может быть двояким. С одной стороны, это может быть следствием естественной вариабильности веса семян древесной породы - ведь при нормальном распределении отклонения могут быть довольно большие. С другой стороны, появление в выборке х трех семян с весом 22 мг может являться следствием того, что в рассматриваемый семенной фонд по какой-то причине попало некоторое количество семян, не соответствующих кондиционным нормам.
Так как в данном случае отклонение сомнительных вариант от среднего значения составляет 31,74 - 22,0 = 9,74, а s = 3,343, то
τmin = (M-xmin)/s = 9,74/3,343 = 2,914.
В табл. 4.1 находим, что критическое значение τ05(100) составляет 3,40. Поскольку τmin < τ05, нулевая гипотеза о принадлежности рассматриваемых трех вариант к данной совокупности не может быть отвергнута. Если нулевая гипотеза отвергается, то это значит, что сомнительные варианты квалифицируются как «артефакты». В таком случае их следует выбрасывать из дальнейшей обработки.
При большом объеме выборки вопрос об исключении «артефактов» не стоит особенно остро, так как относительный «вес» нескольких сомнительных вариант при вычислении усредненных параметров сравнительно невелик. Если же выборка мала, то даже одно неправильное значение может заметно исказить результат усреднения.
Р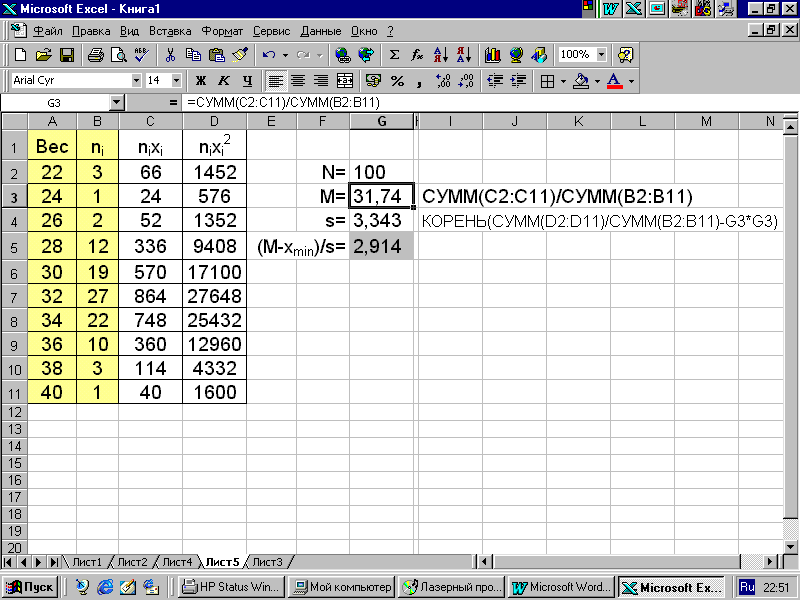 ис.
4.1
ис.
4.1