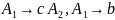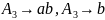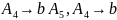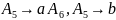Теория
Алфавит
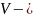 любое конечное множество. Элементами
алфавита служат символы
или буквы.
любое конечное множество. Элементами
алфавита служат символы
или буквы.
Цепочка (слово, предложение, строка) в алфавите произвольная конечная последовательность символов. Цепочки обозначают малыми греческими буквами.
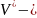 множество
всех цепочек в алфавите
множество
всех цепочек в алфавите
 .
.
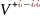 множество всех непустых цепочек в
алфавите
.
множество всех непустых цепочек в
алфавите
.
Конкатенация
двух строк
 есть
есть
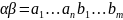 .
.
Языком
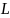 в алфавите
называется произвольное подмножество
множества
в алфавите
называется произвольное подмножество
множества
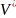 (не обязательно конечное).
(не обязательно конечное).
Язык, порождаемый грамматикой G и обозначенный L(G),— это множество цепочек, удовлетворяющих двум условиям:
1) каждая цепочка составлена только из терминальных символов (т. е., является терминальным предложением), 2) каждая цепочка может быть выведена из S путем соответствующего применения правил подстановки из множества Р.
Формальная
грамматика
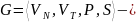 это упорядоченная четверка, в которой
это упорядоченная четверка, в которой
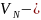 конечное
множество нетерминальных символов
(нетерминалов, переменных);
конечное
множество нетерминальных символов
(нетерминалов, переменных);
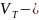 конечное
множество терминальных символов-
непроизводные символы
(терминалы, константы);
конечное
множество терминальных символов-
непроизводные символы
(терминалы, константы);
 конечное
множество правил вывода
(продукций, подстановок);
конечное
множество правил вывода
(продукций, подстановок);
 стартовый
нетерминал.
стартовый
нетерминал.
Продукция
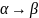 построена из
построена из
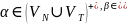 .
.
Дополнительно
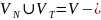 алфавит грамматики;
алфавит грамматики;
 .
.
Нетерминалы обозначаются заглавными латинскими буквами S, А, В, С,, терминалы – строчными латинскими буквами а, Ь, с. Смешанные цепочки из терминалов и нетерминалов обозначаются греческими буквами α, β, γ, δ,.
 цепочка
цепочка
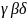 непосредственно
выводима
в грамматике
непосредственно
выводима
в грамматике
 из цепочки
из цепочки
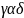 .
.
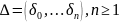 называется
выводом
цепочки
называется
выводом
цепочки
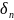 из
из
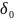 грамматики
,
если
грамматики
,
если
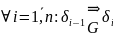 .
Также говорят, что цепочка
выводима
и обозначают этот факт
.
Также говорят, что цепочка
выводима
и обозначают этот факт
 .
.
Если
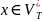 и
и
 ,
то цепочку
,
то цепочку
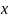 называют сентенцией
грамматики
.
называют сентенцией
грамматики
.
Языком
грамматики
называют множество
всех сентенций
данной грамматики и обозначают
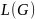 .
Возможно, что две различные грамматики
порождают один и тот же язык; тогда их
называют эквивалентными.
.
Возможно, что две различные грамматики
порождают один и тот же язык; тогда их
называют эквивалентными.
Грамматики классифицируют по структуре их множества продукций.
Обобщенные грамматики (неограниченная грамматика) с правилами вида
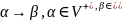 .
.Грамматики непосредственно составляющих(контекстная грамматика грамматика составляющих, НС-грамматика) с правилами вида
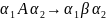
α1 и α2—элементы алфавита V*, β принадлежит V+, а А принадлежит VN. Эта грамматика допускает замещение нетерминального символа А цепочкой β только в том случае, если А появляется в контексте α1Aα2, составленном из цепочек α1 и α2.
Контекстно-свободные грамматики(бесконтекстные) с правилами вида
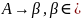 .
Само
название «бесконтекстная» указывает
на то, что переменная A
может замещаться цепочкой β независимо
от контекста, в котором появляется А.
.
Само
название «бесконтекстная» указывает
на то, что переменная A
может замещаться цепочкой β независимо
от контекста, в котором появляется А.

Регулярные грамматики (автоматные) с правилами вида
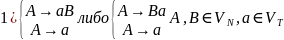 .
2) S->
.
2) S->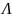 в этом случае дополнительное ограничение-S
не должно встречаться в правых частях
никаких продукций.
в этом случае дополнительное ограничение-S
не должно встречаться в правых частях
никаких продукций.
Лингвистический подход к распознаванию образов.
Этот подход часто называют синтаксическим распознаванием образов, хотя в литературе часто встречаются как лингвистическое распознавание.
Предположим, у нас имеются два класса образов ω1 и ω2 и пусть образы этих классов могут быть построены из признаков, принадлежащих некоторому конечному множеству. Назовем эти признаки треминалами и обозначим множество терминалов символом VТ. В синтаксическом распознавании образов терминалы называются также непроизводными символами (элементами). Каждый образ может рассматриваться как цепочка или предложение, поскольку он составлен из терминалов множества VТ. Допустим, что существует грамматика G, такая, что порождаемый ею язык состоит из предложений (образов), принадлежащих исключительно одному из классов, скажем ω1 . Очевидно, что эта грамматика может быть использована в целях классификации образов, так как заданный образ неизвестной природы может быть отнесен к ω1, если он является предложением языка L{G}. В противном случае образ приписывается классу ω2.Процедура, используемая для определения, является или не является цепочка предложением, грамматически правильным для данного языка, называется грамматическим разбором (то есть решается задача распознавания).
Основным отличием синтаксического распознавания образов от всех рассмотренных ранее является непосредственное использование структуры образов в процессе распознавания.
Задача распознавания образов 3 подхода:
Имеем эталонные цепочки, каждая из которых принадлежит некоторому языку. Тогда x относится к тому классу с эталоном которого он наилучшим образом совпадает.
Каждому языку ставится в соответствие мн-во синтаксических правил данного языка, каждое такое правило устанавливает степень допуска/запрета соответствий между цепочек данного языка.
Классифицируемый образ относится к тому классу набору синтаксических правил которого он не противоречит.
Основана на использовании формальной грамматики.
Если сущ. алгоритм , который определяет принадлежность цепочки, за конечное число шагов, то соответствующий язык называется рекурсивным, а соответствующую грамматику которая порождает этот язык будем называть разрешенной.
Обучение распознавания лингвистических образов:
Задача обучения распознавания лингвистических образов заключается в восстановлении грамматики G, по маркированной обучающей выборке цепочек, некоторые из которых принадлежат языку этой грамматики, а некоторые не принадлежат, т.е. получения грамматики из множества выборочных предложений. Эта процедура, обычно называемая грамматическим выводом.
Иначе задачу обучения распознавания лингвистических образов называют восстановлением грамматики.
Vt - алфавит
St={x1,…..xt} обучающая выборка
St+
- часть выборки, содержащая цепочки
 L(G*)
, то есть выводимых из G
L(G*)
, то есть выводимых из G
St-
- часть выборки, содержащая цепочки
 L(G*),
не выводимых их G
L(G*),
не выводимых их G
St-
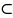 Vt*
\ L(G*)
Vt*
\ L(G*)
St=
St+
 St-
St-
Имеем
алгоритм А, который делает следующее:
для St
формирует грамматику Gt
, которая порождает язык, который выводит
цепочку из St+
и которая не выводит цепочку из St-
.Пусть множество
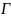 мн-во всех грамматик, которые может
формировать алгоритм А. и пусть Gt
.
Предположим, что грамматики, которые
нас интересуют, тоже находятся в этом
мн-ве.
мн-во всех грамматик, которые может
формировать алгоритм А. и пусть Gt
.
Предположим, что грамматики, которые
нас интересуют, тоже находятся в этом
мн-ве.
Задача восстановления грамматики G называется разрешимой, если существует такой алгоритм А, который на некотором шаге формирует грамматику Gt эквивалентную G. за конечное число шагов
Восстановленная грамматика разрешима если она существует алгоритм А, который на некотором шаге формирует грамматику Gt эквивалентную G, за конечное число шагов.

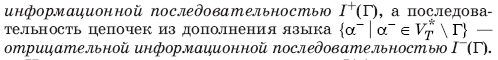


![]()

Будем говорить, что St={x1,…xt} задана в текстуальном представлении, если выполняются два условия:
Для любого t St=St+ (состоит из примеров языка)
Для любой цепочки x , x L(G*) существует t, x St+
Будем говорить ,что St дана в информативном представлении, если выполняются следующие условия:
St= St+ St ,где St+=
 и
St-=
и
St-=
а) x L(G*) существует t’, x St’+
б) y Vt*\ L’(G*) существует t’’ и y St’-
Существуют два класса алгоритмов восстановления грамматик:
1.алгоритм восстановления грамматик индукцией.
2.алгоритм восстановления грамматик перечислением

В восстановлении методом индукции используется эвристический подход.
эвристика — это не полностью математически обоснованный (или даже «не совсем корректный»), но при этом практически полезный алгоритм.
Эвристический подход основывается на трудно формализуемых знаниях и интуиции исследователя. В этом подходе исследователь сам определяет, какую информацию и каким образом нужно использовать для достижения требуемого эффекта распознавания.

Теорема о разрешимости для информативного представления
Пусть
произвольное множество разрешимых
грамматик, тогда задача восстановления
грамматики (при информативном
представлении) разрешима для любой
грамматики из множества
,
G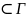 .(
индукцией)
.(
индукцией)



Теорема о неразрешимости для текстуального представления грамматик
(алгоритм восстановления грамматик перечислением):
Пусть произвольное множество грамматик, содержащее все грамматики, которые порождают конечные я зыки + одна грамматика порождает бесконечный язык, тогда при текстуальном представлении задача восстановления грамматики неразрешима для произвольной грамматики из этого мн-ва.
Приведенные теоремы важны по следующим причинам:
1.они указывают ограничения на решение задачи распознавания лингвистических образов.
2.они указывают возможный способ решения задачи распознавания линг.образов, а именно: перечисление грамматик в определенном порядке.

Если находится несколько грамматик, совместных с такой последовательностью, то размер подпоследовательности увеличивается и происходит дальнейший отсев грамматик. При таком переборе истинная грамматика находится гарантированно.
Существуем множество видов перебора грамматик. Одним из них является оккамовское перечисление, при котором грамматики рассматриваются в порядке увеличения сложности.
Вывод цепочечных грамматик:

К сожалению, ни одна из известных схем не в состоянии решить эту задачу в общем виде, представленном на рис. Вместо этого предлагаются многочисленные алгоритмы для вывода ограниченных грамматик.
Алгоритм, рассматриваемый далее, является во многих отношениях типичным отражением результатов, полученных в данной области. Этот алгоритм, являющийся модификацией процедуры, разработанной Фельдманом, для заданного множества терминальных цепочек выводит автоматную грамматику.
Алгоритмы лингвистического подхода применяются в области распознавания изображений, характеризующихся хорошо различимыми формами, в частности символов, хромосом, фотоснимков столкновений частиц.
Алгоритм Фельдмана.
Постановка задачи:
Дано: множество выборочных цепочек {xi}.
Требуется: подвергнуть {xi} обработке с помощью адаптивного (Адаптивный алгоритм — алгоритм, который пытается выдать лучшие результаты путём постоянной подстройки под входные данные). обучающегося алгоритма, на выходе которого воспроизводится грамматика G, согласованная с данными цепочками.
Иными словами, множество цепочек {xi} является подмножеством языка L(G), порождаемого грамматикой G.
Суть метода:
сначала построить нерекурсивную грамматику, порождающую в точности заданные цепочки,
затем, сращивая нетерминальные элементы, получить более простую рекурсивную грамматику, порождающую бесконечное число цепочек.
Алгоритм + пример, чтобы понятнее было.
Сам алгоритм:
Алгоритм можно разделить на три части.
Первая часть формирует нерекурсивную грамматику.
Вторая часть преобразует её в рекурсивную грамматику.
Затем, в третьей части, происходит упрощение этой грамматики.
Рассмотрим
выборочное множество терминальных
цепочек
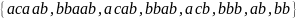 .
Требуется получить автоматную грамматику,
способную порождать эти цепочки. Алгоритм
построения грамматики состоит из
следующих этапов.
.
Требуется получить автоматную грамматику,
способную порождать эти цепочки. Алгоритм
построения грамматики состоит из
следующих этапов.
Часть 1.
Строится нерекурсивная грамматика, порождающая в точности заданное множество выборочных цепочек. Выборочные цепочки обрабатываются в порядке уменьшения длины.
Правила подстановки строятся и
прибавляются к грамматике по мере того,
как они становятся нужны для построения
соответствующей цепочки из выборки.
Заключительное правило подстановки,
используемое для порождения самой
длинной выборочной цепочки, называется
остаточным правилом, а длина его правой
части равна 2. Остаточное правило длины
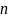 имеет вид
имеет вид
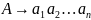 ,
где
,
где
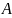 — нетерминальный символ, а
— нетерминальный символ, а
 —терминальные элементы.
—терминальные элементы.
Предполагается, что остаток каждой цепочки максимальной длины является суффиксом (хвостовым концом) некоторой более короткой цепочки. Если какой-либо остаток не отвечает этому условию, цепочка, равная остатку, добавляется к обучающей выборке.
Из последующих рассуждений будет ясно, что выбор остатка длины 2 не связан с ограничением на алгоритм. Можно выбрать и более длинный остаток, но тогда потребуется более полная обучающая выборка в связи с условием, что каждый остаток является суффиксом некоторой более короткой цепочки.
В нашем примере первой цепочкой
максимальной длины в обучающей выборке
является цепочка
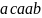 .
Для порождения этой цепочки строятся
следующие правила подстановки:
.
Для порождения этой цепочки строятся
следующие правила подстановки:


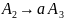
 ,
,
где —правило остатка.
Вторая цепочка —
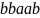 .
Для порождения этой цепочки к грамматике
добавляются следующие правила:
.
Для порождения этой цепочки к грамматике
добавляются следующие правила:

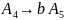
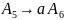
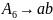
Поскольку цепочка и предыдущая цепочка имеют одинаковую длину, требуется остаточное правило длины 2. Заметим также, что работа первой части алгоритма приводит к некоторой избыточности правил подстановки. Например, вторая цепочка может быть с равным успехом получена введением следующих правил подстановки:
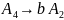
Но в первой части мы занимаемся лишь определением множества правил подстановки, которое способно в точности порождать обучающую выборку, и не касаемся вопроса избыточности. В сложных ситуациях трудно соблюдать выполнение этого условия и одновременно уменьшать число необходимых правил подстановки. Значительно проще просматривать введенные правила слева направо, чтобы определить, будут ли они порождать новую цепочку, не стремясь при этом минимизировать число правил подстановки. Об устранении избыточности речь пойдет в третьей части алгоритма.
Для порождения третьей цепочки
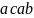 требуется добавление к грамматике
только одного правила:
требуется добавление к грамматике
только одного правила:
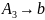 .
.
Для порождения четвертой цепочки
 требуется добавление к грамматике
только одного правила:
требуется добавление к грамматике
только одного правила:
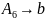 .
.
Для порождения пятой цепочки
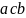 требуется добавление к грамматике
только одного правила:
требуется добавление к грамматике
только одного правила:
 .
.
Для порождения шестой цепочки
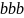 требуется добавление к грамматике
только одного правила:
требуется добавление к грамматике
только одного правила:
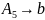 .
.
Для порождения седьмой цепочки
 требуется добавление к грамматике
только одного правила:
требуется добавление к грамматике
только одного правила:
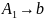 .
.
Для порождения восьмой цепочки
 требуется добавление к грамматике
только одного правила:
требуется добавление к грамматике
только одного правила:
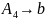 .
.
Окончательно множество правил подстановки, построенных для порождения обучающей выборки, выглядит следующим образом: