

Новые уязвимости доступа к файлам в php
Какой-нибудь
год назад все просто с ума сходили от
Error-based MySQL, а unserialize казался чем-то сложным
и не встречающимся в реальной жизни.
Теперь это уже классические техники.
Что уж говорить о таких динозаврах как
нуль-байт в инклудах, на смену которому
пришел file name truncated. Исследователи
постоянно что-то раскапывают, придумывают,
а тем временем уже выходят новые версии
интерпретаторов, движков, а с ними –
новые баги разработчиков.
По сути,
есть три метода найти уязвимость:
смекалка (когда исследователь придумывает
какой-нибудь трюк и проверяет, работает
ли он на практике), анализ исходного
кода и фаззинг. Об одном интересном
китайском фаззинге и его развитии с
моей стороны я и хочу рассказать.
Fuzzing — это не только ценный мех...
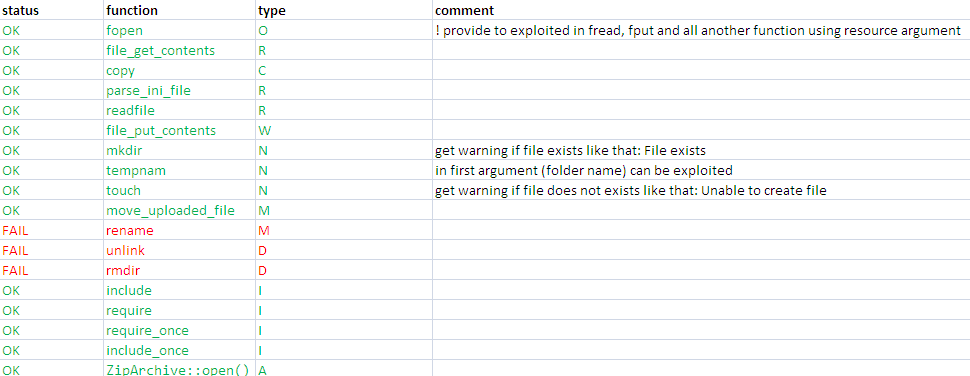
Началось все с того, что Гугл распорядился выдачей уже не помню на какой запрос и показал сайт на китайском языке: http://code.google.com/p/pasc2at/wiki/SimplifiedChinese, где было собрано множество интересных находок китайских фаззеров. Интересно, что в списке были совсем свежие находки, которые только-только публиковались в статьях. Среди них нашелся и привлекший мое внимание код следующего содержания:
<?php
for($i=0;$i<255;$i++) {
$url = '1.ph'.chr($i);
$tmp = @file_get_contents($url);
if(!empty($tmp)) echo chr($i)."\r\n";
}
?>
Привлек он меня потому, что смысла я не понял, но разобрал в описании знакомые символы «win32» :). Переводить китайскую письменность было странным развлечением даже с помощью google.translate, поэтому я тупо выполнил этот код под виндой и посмотрел на результат. Каково же было мое удивление, когда обнаружилось, что у файла в винде существовали как минимум 4 имени: 1.phP, 1.php, 1.ph>, 1.ph<. Теперь уже китайская письменность не казалась мне такой далекой, и переводчик Гугла помог понять ее смысл. Собственно, в этом самом «смысле» не было ничего больше, чем описание кода и результата его работы. Не то чтобы не густо — вообще никак! Такое положение дел меня не устраивало. До сих пор не понимаю этих китайцев — неужели им не интересно было понять, какие функции еще уязвимы, какие особенности у этого бага при эксплуатации, а конце концов, почему это вообще работает?
Требую продолжения банкета!
Первым делом я добавил второй итератор и запустил код с фаззингом уже по двум последним байтам. Результаты были непредсказуемы:
1.p<0 (нуль-байт на конце)
1.p< (пробел на конце)
1.p<"
1.p<.
1.p<<
1.p>>
1.p<>
1.p><
1.p<(p/P)
1.p>(p/P)
1.p(h/H)<
1.p(h/H)>
1.p(h/H)(p/P)
Отсюда явно проглядывались закономерности — на конце имени файла могли идти символы: точка, двойная кавычка, пробел, нуль-байт. Чтобы проверить эту догадку, я запустил следующий код:
<?php
if (file_get_contents("test.php".str_repeat("\"",10).str_repeat(" ",10).str_repeat(".",10))) echo 1337;
?>
Как нетрудно догадаться, он вернул 1337, то есть все работало так, как и было предсказано. Это само по себе было уже расширение по символам популярной уязвимости, альтернативы нуль-байту в инклудах. После продолжения издевательств над интерпретатором были найдены конструкции имени файла со слэшами на концах, которые тоже читались без проблем:
file\./.\.
file////.
file\\\.
file\\.//\/\/\/.
Думаю, здесь все ясно: если использовать слэши после имени файла, то на конце всегда должна стоять точка. При этом слэши можно миксовать, и между ними можно втыкать одну точку. При всем при этом оставалось неясным главное — что скрывают символы < и >?