

Лабораторна робота №6 нелінійна регресія
Завдання: На основі статистичних даних показника Y та фактора X (стовпчики уі та хі табл. 6.1) знайти:
1) оцінки параметрів лінії
регресії, якщо припустити, що статистична
залежність між фактором X
і показником Y
має вигляд:
![]() ;
;
2) використовуючи критерій Фішера, з надійністю Р=0,95 оцінити адекватність прийнятої моделі статистичним даним. Якщо із заданою надійністю прийнята математична модель адекватна експериментальним даним, то знайти:
а) з надійністю Р=0,95 довірчу зону базисних середніх;
б) точкову оцінку прогнозу для хр=110;
в) з надійністю Р=0,95 інтервальну оцінку прогнозу.
Таблиця 6.1 - Вихідні дані
№ |
хі |
уі |
1 |
96+N |
3,2 |
2 |
80 |
3,1+N |
3 |
104+N |
3,8+N |
4 |
86+N |
4,4 |
5 |
54 |
4,2+N |
6 |
34+N |
7,8+N |
7 |
65+N |
4,3 |
8 |
36 |
5,6+N |
9 |
25+N |
7+N |
10 |
58 |
3,5+N |
де N - порядковий номер по списку
Методичні рекомендації до виконання роботи
1) будуємо поле кореляції, емпіричну лінію регресії (у вигляді ламаної) та визначаємо форму зв'язку між ознаками X та Y (рисунок 6.1).
Зовнішній вигляд емпіричної лінії регресії нагадує графік гіперболи
Невідомі параметри економетричної моделі а0 і а1 знаходимо із системи нормальних рівнянь:
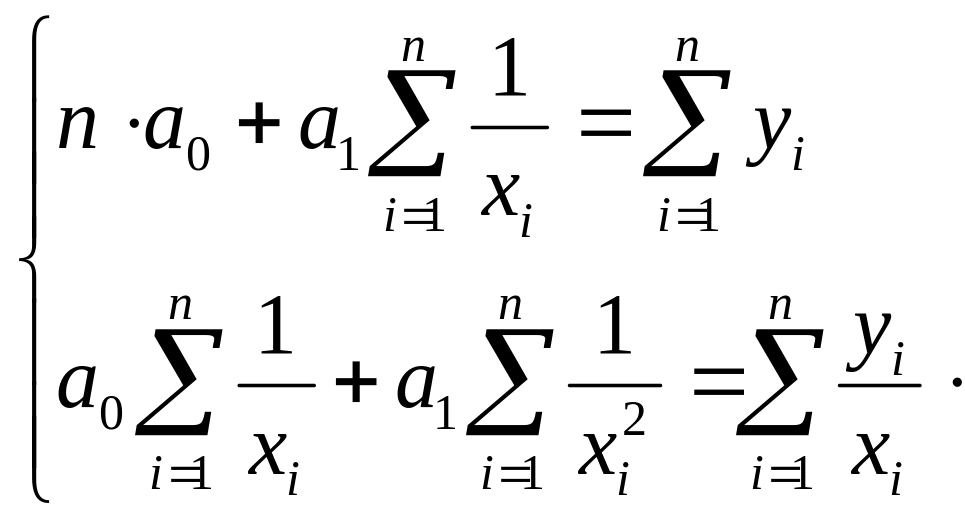
Для цього у робочій таблиці накопичуємо суми:
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
і підставляємо їх у систему нормальних рівнянь. Маємо
![]()
З останньої системи знаходимо: а0=1,38, а1=170,78.
Таким чином, економетрична модель має вигляд:
![]() .
.
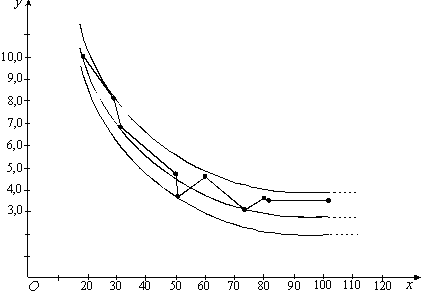
Рисунок 6.1 – Графік емпіричної, теоретичної лінії регресії та довірчих границь базисних середніх і прогнозу
Розраховуємо теоретичні
![]() та
прогнозне
та
прогнозне
![]() значення
результативного
показника і будуємо теоретичну лінію
регресії.
значення
результативного
показника і будуємо теоретичну лінію
регресії.
![]() ,
,
![]() ,
і т.д.
,
і т.д.
![]() .
.
Тіснотy зв’язку між ознаками X та Y оцінюємо кореляційним відношенням:
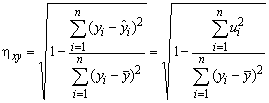 .
.
Для розрахунку
![]() у
робочій таблиці знайдемо суми
у
робочій таблиці знайдемо суми
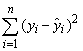 та
та
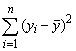 .
Тоді
.
Тоді
![]() .
.
Оцінимо значущість кореляційного відношення за t-критерієм Стюдента. Маємо
![]() ;
; 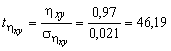 .
.
Табличне значення tα,k
критерію Стюдента для рівня значущості
α=0,05 і
степенів свободи k=8 становить
t0.05,8 =2,31.
Оскільки
![]() ,
то з ймовірністю р=1-0,05=0,95
можна стверджувати, що кореляційне
відношення значуще.
,
то з ймовірністю р=1-0,05=0,95
можна стверджувати, що кореляційне
відношення значуще.
Оцінимо значущість параметрів
економетричної моделі а0
та а1.
Спочатку обчислимо
![]() ,
,
![]() ,
,![]() .
Маємо
.
Маємо
![]() ;
;
 ;
;
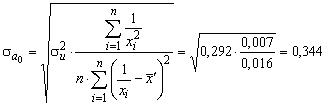 .
.
Тоді
Таблиця 6.2 – Приклад розрахунку нелінійної регресії
№ |
|
|
|
|
|
|
|
|
|
|
|
Довірчі
|
границі
|
1 |
80 |
3,6 |
0,013 |
0,0002 |
0,045 |
3,515 |
0,007 |
2,434 |
2,706 |
0,00009 |
0,406 |
3,109 |
3,921 |
2 |
75 |
3,1 |
0,013 |
0,0002 |
0,041 |
3,657 |
0,311 |
4,244 |
2,258 |
0,00008 |
0,404 |
3,254 |
4,061 |
3 |
102 |
3,5 |
0,010 |
0,0001 |
0,034 |
3,055 |
0,198 |
2,756 |
4,433 |
0,00015 |
0,413 |
2,642 |
3,467 |
4 |
82 |
3,5 |
0,012 |
0,0001 |
0,043 |
3,463 |
0,001 |
2,756 |
2,880 |
0,00010 |
0,406 |
3,057 |
3,869 |
5 |
50 |
4,7 |
0,020 |
0,0004 |
0,094 |
4,796 |
0,009 |
0,212 |
0,133 |
0,00000 |
0,395 |
4,401 |
5,191 |
6 |
30 |
8,1 |
0,033 |
0,0011 |
0,270 |
7,073 |
1,055 |
8,644 |
3,659 |
0,00013 |
0,410 |
6,663 |
7,483 |
7 |
60 |
4,6 |
0,017 |
0,0003 |
0,077 |
4,227 |
0,139 |
0,314 |
0,871 |
0,00003 |
0,398 |
3,829 |
4,625 |
8 |
32 |
6,8 |
0,031 |
0,0010 |
0,213 |
6,717 |
0,007 |
2,690 |
2,425 |
0,00008 |
0,405 |
6,313 |
7,122 |
9 |
19 |
10 |
0,053 |
0,0028 |
0,526 |
10,37 |
0,136 |
23,426 |
27,131 |
0,00093 |
0,496 |
9,873 |
10,865 |
10 |
51 |
3,7 |
0,020 |
0,0004 |
0,073 |
4,729 |
1,059 |
2,132 |
0,186 |
0,00001 |
0,395 |
4,334 |
5,124 |
∑ |
581 |
51,6 |
0,221 |
0,0065 |
1,415 |
|
2,923 |
49,604 |
46,681 |
0,0016 |
|
|
|
Пр |
110 |
|
0,009 |
|
|
2,933 |
|
|
|
0,00017 |
0,433 |
2,500 |
3,366 |
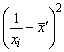
![]() ,
, ![]() .
.
Оскільки
![]() ,
,
![]() ,
то параметри а0
і а1 економетричної
моделі значущі.
,
то параметри а0
і а1 економетричної
моделі значущі.
2) Проведемо оцінку адекватності моделі за F-ритерієм Фішера. Для цього обчислимо
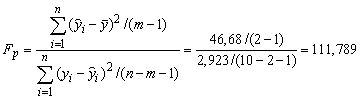 .
.
Табличне значення критерію
Фішера для рівня значущості α=0,05 і
степенів свободи k1=1
i k2=7
становить
![]() =5,59.
Оскільки
=5,59.
Оскільки
![]() ,
то економетрична модель адекватно
описує економічне явище.
,
то економетрична модель адекватно
описує економічне явище.
Проведемо оцінку довірчих границь базисних середніх та прогнозу за формулою:
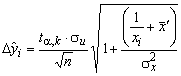 .
.
Маємо
![]() ;
;
![]() ;
.
;
.
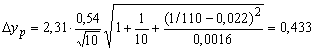 .
.
Тоді
![]() .
.
Основні питання для самоперевірки
1. Дайте визначення нелінійної функції.
2. Наведіть приклади нелінійних функцій.
3. Опишіть сферу використання степеневих функцій.
4. Опишіть сферу використання поліноміальних функцій.
5. У яких випадках можна проводити лінеаризацію нелінійних функцій.
6. Опишіть процедуру лінеаризації степенової функції.
7. Опишіть процедуру лінеаризації зворотної функції.
8. Опишіть процедуру лінеаризації показникової функції.
Лабораторна робота №7
ДОСЛІДЖЕННЯ БАГАТОФАКТОРНОЇ РЕГРЕСІЇ
Завдання: Визначити лінійну залежність між факторами, розрахувати параметри та коефіцієнти багатофакторної регресії, провести дослідження мультиколінеарності і автокореляції моделі. Зробити висновок.
Вихідні дані:
№ |
Y |
X1 |
X2 |
1 |
69,5+N |
21,1 |
52,10 |
2 |
75,9+N |
23,6+N |
57+N |
3 |
79,9 |
24,4+N |
60,7+N |
4 |
84,6+N |
24,8+N |
65,7+N |
5 |
89+N |
27+N |
69,9+N |
6 |
95,6+N |
28,6+N |
74,6+N |
7 |
99,8+N |
31+N |
77,8 |
8 |
103,1+N |
33,1 |
78+N |
9 |
107,5 |
33,1+N |
83+N |
10 |
111,9+N |
34,9 |
88,9+N |
11 |
114,5+N |
35,2 |
89,2 |
12 |
120,9+N |
36,4+N |
94,6+N |
13 |
122,8 |
37,2 |
97+N |
Методичні рекомендації до виконання роботи
Припустимо, що між показником Y і факторами Х1, Х2, ..., Хm існує лінійна залежність:
![]() ,
(7.1)
,
(7.1)
Оцінки параметрів регресії знаходимо використовуючи матричні операції за формулою:
![]() ,
(7.2)
,
(7.2)
де [Х] – матриця пояснюючих змінних Х1, Х2, ..., Хm, доповнена колонкою одиниць,
Y – вектор результативної змінної Y,
[Х]Т – транспонована матриця пояснюючих змінних.
Також можна здійснити розрахунок параметрів та інших коефіцієнтів багатофакторної регресії, скориставшись функціями програми Excel.
Для цього перш за все необхідно перевірити наявність пакету аналізу. В головному меню слід вибрати Сервис-Надстройки і включити пакет аналізу:
Рисунок 7.1 – Вибір пакету аналізу в MS Excel.
Вводимо початкові дані до MS Excel в стовпчики A, B та C:

Рисунок 7.2 – Ввід вихідних даних
В головному меню вибираємо Сервис - Аналіз даних-Регресія. Отримуємо діалогове вікно (рис.7.3).
Заповнюємо діалогове вікно:
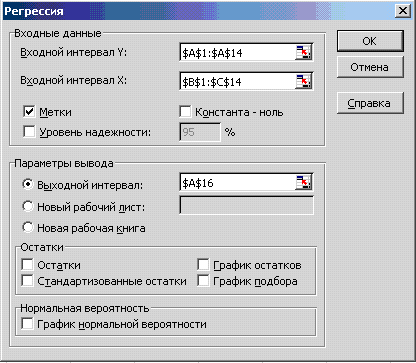
Рисунок 7.3 – Діалогове вікно
Таблиця 7.1 – Інтерпретація діалогового вікна
Входной интервал Y: |
Діапазон значень залежної змінної. |
Входной интервал X |
Діапазон значень незалежних змінних. Зауважте, що незалежні змінні повинні знаходитися в сусідніх стовпчиках. |
Метки |
Опція, що вказує, чи містить перший рядок назви стовпчиків |
Константа -ноль |
Опція, що вказує на наявність чи відсутність константи в регресії |
Параметри виводу
|
Адреса верхньої лівої чарунки для виводу результатів обчислень. Якщо вказується опція «Новый рабочий лист», то результати виводяться на новий лист. |
Отримані результати (таблиця 7.2) дають змогу зробити наступні висновки:
Параметри багатофакторної регресії становлять: β0= 4,8, β1=1,02, β2= 0,82. Відповідно рівняння багатофакторної регресії має вигляд:
y=4,8 +1,02Х1+0,82Х2
Множинний коефіцієнт кореляції (множественный R=0,9325) показує тісноту зв’язку між факторами та показником. Коефіцієнт детермінації (множественный R2=0,8696) показує рівень зміни показника при зміні факторів, а саме 0,8696% зміни показника залежить від зміни факторів.
Оцінка розрахункового критерію Фішера (F=73,3414) дозволяє зробити висновок про адекватність економетричної моделі вихідним даним
(Fрозр=73,3414 > Fтабл(0,95;2;10)=4,1).
Дослідження автокореляції
Одним із показників ступеня близькості одержаної лінії регресії до експериментальних даних є критерій Дарбіна-Уотсона. Він дає відповідь на запитання, чи є істотною автокореляція відхилень від лінії регресії. Іншими словами, з деякою надійністю критерій дає відповідь на запитання, чи виконується умова незалежності відхилень еt.
Автокореляція відхилень – це кореляція відхилень від лінії регресії з відхиленнями від цієї лінії, взятими з деяким запізненням, тобто це кореляція ряду е1,е2, ..., еn з рядом еk+1, еk+2, …, еk+n, де k – число, що характеризує запізнення.
Кореляція між сусідніми членами ряду (k=1) називається автокореляцією першого порядку:
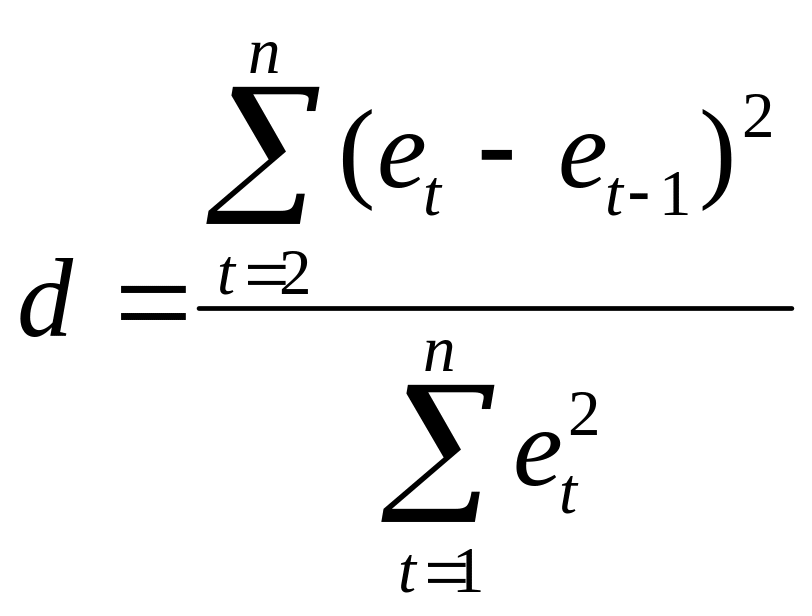 .
(7.3)
.
(7.3)
Відповідно d-статистика може набувати будь-якого значення з інтервалу (0;4).
Таблиця 7.2 - Результати регресійного аналізу
Регрессионная статистика |
|
|
|
|
|
|
|
||
Множественный R |
0,999136 |
|
|
|
|
|
|
|
|
R-квадрат |
0,998272 |
|
|
|
|
|
|
|
|
Нормированный R-квадрат |
0,997927 |
|
|
|
|
|
|
|
|
Стандартная ошибка |
0,790633 |
|
|
|
|
|
|
|
|
Наблюдения |
13 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Дисперсионный анализ |
|
|
|
|
|
|
|||
|
df |
SS |
MS |
F |
Значимость F |
|
|
|
|
Регрессия |
2 |
3612,672 |
1806,336 |
2889,666 |
1,54E-14 |
|
|
|
|
Остаток |
10 |
6,251 |
0,625102 |
|
|
|
|
|
|
Итого |
12 |
3618,923 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Коэффи циенты |
Стандартная ошибка |
t-статистика |
P-Значение |
Нижние 95% |
Верхние 95% |
Нижние 95,0% |
Верхние 95,0% |
|
Y-пересечение |
4,849522 |
1,303660 |
3,719929 |
0,003976 |
1,944787 |
7,754257 |
1,944787 |
7,754257 |
|
X1 |
1,025477 |
0,246688 |
4,156976 |
0,001958 |
0,475822 |
1,575133 |
0,475822 |
1,575133 |
|
X2 |
0,821052 |
0,092860 |
8,841844 |
0,000005 |
0,614147 |
1,027957 |
0,614147 |
1,027957 |
|
Для d-статистики визначені критичні межі (dl – нижня, dn – верхня), які дозволяють із заданою надійністю (Р=0,95; 0,99) дати відповідь, чи можна прийняти гіпотезу про відсутність автокореляції першого порядку чи ні
У залежності від значення d приймаємо, що:
при 0<d<dl відхилення додатно корельовані;
при dn<d<4-dn враховується гіпотеза про відсутність автокореляції;
при 4-dl<d<4 відхилення від’ємно корельовані;
при dl<d<dn або 4-dn<d<4-dl критерій не дає відповідь на запитання про наявність або відсутність кореляції.
Відхилення додатно корельовані |
? |
Враховується гіпотеза про відсутність автокореляції |
? |
Відхилення від’ємно корельовані |
0 - dl |
|
dn - 4-dn |
|
4-dl - 4 |
Якщо d-статистика набуває значення з п.4, то для одержання відповіді про наявність автокореляції першого порядку необхідно збільшити число спостережень. Величини dn i dl для двох надійних ймовірностей Р=0,95 і Р=0,99 наведено в таблицях.
При наявності автокореляції відхилень потрібно з’ясувати можливі причини її появи. Можливі причини автокореляції:
У регресію не включений фактор, який має суттєву роль при дослідженні економічного явища.
Вибраний вигляд стохастичної залежності не адекватний експериментальним даним.
При дослідженні явища числові дані отримані з великими похибками.
Для перевірки економетричної моделі на автокореляцію скористаємось вихідними даними з рисунка 7.2 і результатами аналізу даних (таблиця 7.2) та розрахуємо теоретичні значення показника Ур, а також відхилення теоретичних значень від емпіричних та коефіцієнт Дарбіна-Уотсона.
Результати розрахунків подамо у таблиці 7.3.
Таблиця 7.3 - Перевірка властивості автокореляції
№ |
Y |
X1 |
X2 |
Yr |
et = Y-Yr |
et2 |
(et-et-1)2 |
1 |
69,5 |
21,1 |
52,10 |
69,26 |
0,24 |
0,06 |
|
2 |
75,9 |
23,6 |
57 |
75,85 |
0,05 |
0,00 |
0,03 |
3 |
79,9 |
24,4 |
60,7 |
79,71 |
0,19 |
0,04 |
0,02 |
4 |
84,6 |
24,8 |
65,7 |
84,22 |
0,38 |
0,14 |
0,03 |
5 |
89 |
27 |
69,9 |
89,93 |
-0,93 |
0,86 |
1,70 |
6 |
95,6 |
28,6 |
74,6 |
95,43 |
0,17 |
0,03 |
1,21 |
7 |
99,8 |
31 |
77,8 |
100,52 |
-0,72 |
0,51 |
0,79 |
8 |
103,1 |
33,1 |
78 |
102,83 |
0,27 |
0,07 |
0,96 |
9 |
107,5 |
33,1 |
83 |
106,94 |
0,56 |
0,31 |
0,09 |
10 |
111,9 |
34,9 |
88,9 |
113,63 |
-1,73 |
2,99 |
5,24 |
11 |
114,5 |
35,2 |
89,2 |
114,18 |
0,32 |
0,10 |
4,19 |
12 |
120,9 |
36,4 |
94,6 |
119,85 |
1,05 |
1,11 |
0,54 |
13 |
122,8 |
37,2 |
97 |
122,64 |
0,16 |
0,03 |
0,79 |
|
1275 |
390,4 |
988,5 |
1275,00 |
0,00 |
6,25 |
15,61 |
Отже, критерій Дарбіна-Уотсона, розрахований за формулою 1.34 становить d=15,61/6,25=2,5. Знайшовши відповідні табличні значення критичних меж Дарбіна –Уотсона: dl=0.861 – нижня межа i dn=1.562 – верхня межа, утворюємо відповідні проміжки

 d=2.5
d=2.5
0 dl =0.861 dn =1.562 4-dn =2.438 4-dl =3.139 4
Оскільки розрахункове значення критерію-Дарбіна Уотсона знаходиться в межах від 4-dn до 4-dl, то можна зробити висновок, що критерій не дає відповідь про наявність чи відсутність автокореляції.
Основні питання для самоперевірки
1. Дайте визначення множинної регресії.
2. Опишіть алгоритм оцінки параметрів множинної регресії за допомогою матричних операцій.
3. Опишіть алгоритм оцінки множинної регресії в середовищі MS EXCEL.
4. Дайте характеристику множинному коефіцієнту кореляції.
5. Дайте характеристику множинному коефіцієнту детермінації.
6. Опишіть властивість мультиколінеарності.
7. За допомогою якого критерію можна оцінити загальну мультиколінеарність. Наведіть формулу розрахунку та опишіть процедуру оцінки.
8. За допомогою якого критерію можна оцінити мультиколінеарність пари незалежних змінних . Наведіть формулу розрахунку та опишіть процедуру оцінки.
9. За допомогою якого критерію можна оцінити мультиколінеарність незалежної змінної з усіма іншими. Наведіть формулу розрахунку та опишіть процедуру оцінки.
10. Дайте визначення поняття «автокореляція». Опишіть процедуру оцінки.
Лабораторна робота № 8
ПРОГНОЗУВАННЯ ЕКОНОМІЧНИХ ПОКАЗНИКІВ
Завдання: Провести прогнозування показників за допомогою наступних методів:
а) трендові моделі (екстраполяція);
б) метод середнього ковзання та ПЕВС
в) моделювання сезонних коливань рядами Фур’є.
Визначити найоптимальнішу модель для проведення прогнозу.
Вихідні дані:
Номер кварталу Х |
Об’єм продаж (тис.грн.) Y |
1 |
204+N |
2 |
209+N |
3 |
208 |
4 |
218+N |
5 |
215 |
6 |
222+N |
7 |
244+N |
8 |
234+N |
9 |
253+N |
10 |
263+N |
11 |
255 |
12 |
269+N |
13 |
252+N |
14 |
265+N |
15 |
268+N |
16 |
279 |
17 |
248+N |
Методичні рекомендації до виконання роботи
Метод прогнозування - сукупність способів і прийомів мислення, що дозволяють на основі аналізу ретроспективних, екзогенних (зовнішніх) і ендогенних (внутрішніх) даних, а також їх змін у розглянутому періоді часу вивести судження певної вірогідності відносно майбутнього розвитку об'єкта.
Перед тим як приступити безпосередньо до прогнозування майбутніх значень, прогнозист повинен спочатку зрозуміти ті кількісні закономірності (або хоча б частину з них), які лежать в основі бізнес-процесу. Єдине, чим він для цього володіє, це вихідні дані. Звідси висновок, що спочатку прогнозист повинен створити модель, яка достатньо добре описувала б вихідні дані.
При прогнозуванні на основі отриманої моделі може виникнути ситуація, коли модель перестає бути достовірною в силу будь-яких непередбачуваних змін. Тому цікаво буде знати про те, як наша модель реагувала б на них в минулому. З цією метою і використовують ідею ex-post прогнозування: вихідні дані розбивають на дві підгрупи, так щоб в другій групі були більш пізніші дані, які складають близько 15% всієї інформації. Ці дані будуть потім використані для тестування. При невеликому об’ємі інформації в другій групі можна розглядати 30% вихідних даних. Докладніше процедуру покажемо на прикладі.
В таблиці 8.1 наведені щоквартальні дані по об’ємах продаж за період з 1-го кварталу 1999р. по 1-й квартал 2003р.
Слід розбити дані в таблиці наступним чином. До першої групи віднесемо дані за перші 13 кварталів (тобто за період з 1-го квартралу 199р. по 1-й квартал 2002р. включно). А до другої групи – дані за чотири квартали, що залишились: з 2-го кварталу 2002р. по 1-й квартал 2003р. (тобто з 14-го по 17-й квартал). Наступну процедуру можна охарактеризувати як імітацію процесу прогнозування. Ми подумки перенесемося на рік назад відносно часу самого останнього значення ( в нашому випадку воно отримано в кінці 1-го кварталу 2003р.) до кінця 1-го кварталу 2002р.
Таблиця 8.1 – Дані про об’єми продаж
Номер кварталу Х |
Об’єм продаж (тис.грн.) Y |
1 |
207 |
2 |
209 |
3 |
204 |
4 |
214 |
5 |
215 |
6 |
234 |
7 |
244 |
8 |
254 |
9 |
253 |
10 |
263 |
11 |
259 |
12 |
272 |
13 |
254 |
14 |
265 |
15 |
268 |
16 |
270 |
17 |
248 |
І почнемо прогнозувати так, як би зараз був кінець 1-го кварталу 2002 року. Прогнози, отримані таким чином, називаються ex post прогнозами. Але спочатку ми повинні задати горизонт прогнозування, тобто визначити, на скільки кроків вперед буде наш прогноз. При цьому кожний раз ми будемо порівнювати отримані значення з фактичними даними. В цьому і полягає основна перевага ex post прогнозування. При звичайному прогнозуванні такої можливості немає. Нижче наведемо детальний алгоритм ex post прогнозування.
Алгоритм
Знаходимо лінію регресії L для перших 13 значень.
З рівняння L визначаємо прогноз на 14-й квартал.
Порівнюємо отриманий прогноз з наявною інформацією за 14-й квартал. Знаходимо похибку.
Повторюємо пунки 1-3 послідовно для перших 14,15 і 16 значень.
В результаті ми отримуємо таблицю, що містить ex-post прогнози і відповідні помилки для останніх чотирьох кварталів (таблиця 8.2)
Таблиця 8.2 – Результати розрахунку
Вихідна група |
Рівняння регресії |
Ex-post прогноз на наступний квартал |
Вихідні дані |
Помилка
|
Перші 13 кварталів |
Y = 196,31+5,824t |
(на 14-й кв.) Y = 277,85 |
У14 = 265 |
-12,85 |
Перші 14 кварталів |
Y = 198,14+5,457t |
(на 15-й кв.) Y = 280,00 |
У15 = 268 |
-12 |
Перші 15 кварталів |
Y = 199,74+5,157t |
(на 16-й кв.) Y = 282,25 |
У16 = 270 |
-12,25 |
Перші 16 кварталів |
Y = 201,27+4,887t |
(на 17-й кв.) Y = 284,35 |
У17 = 248 |
-36,35 |
Ex-post прогноз на 16-й квартал (див.третій рядок таблиці) отримуємо наступним чином:
Визначаємо рівняння регресії для перших 15-ти кварталів. В отримане рівняння Y = 199,74+5,157t підставляємо t=16. Отримуємо значення 282,25 і порівнюємо його з вихідним значенням, рівним 270. Отримана похибка е = -12,25. Таким чином, в нашому випадку ex post пронози – це ті прогнози, які ми отримали на протязі одного року (тобто починаючи з 2-го кварталу 2002р. і закінчуючи 1-м кварталом 2003р.), якщо б почали прогнозувати в кінці 1-го кварталу 2002р.
Трендові моделі (екстраполяція)
Тренд відображає усереднені тенденції зміни явища у часі. Припускається, що через фактор часу можна виразити вплив усіх основних факторів, іншими словами, хоча час не являється механізмом прояву закономірностей і тенденцій, він мовби акумулює дії основних факторів і виражає їх у рівнянні тренда.
Рівняння тренда може бути описане різними залежностями, серед яких:
лінійна y=a0+a1t
квадратична y=a0+a1t+a2t2
степенева y=aota1
показникова y=aoa1t
логарифмічна y=a1ln(x)+ao та інші.
При виборі виду рівняння необхідно вирішити два питання. По-перше, чи адекватно рівняння відповідає досліджуваним процесам, а у відношенні часового тренда - наскільки воно відображає закономірність тенденції, що склалася. По-друге, чи відповідає воно статистичним критеріям. Ці два питання повинні дати відповідь - наскільки логічно і статистично відібране рівняння відповідає процесам і явищам, що досліджуються.
Вибір виду рівняння проводять за допомогою зображення динамічного ряду на графіку. При цьому основним критерієм вибору найкращої кривої для прогнозування в більшості випадків обирають коефіцієнт детермінації:
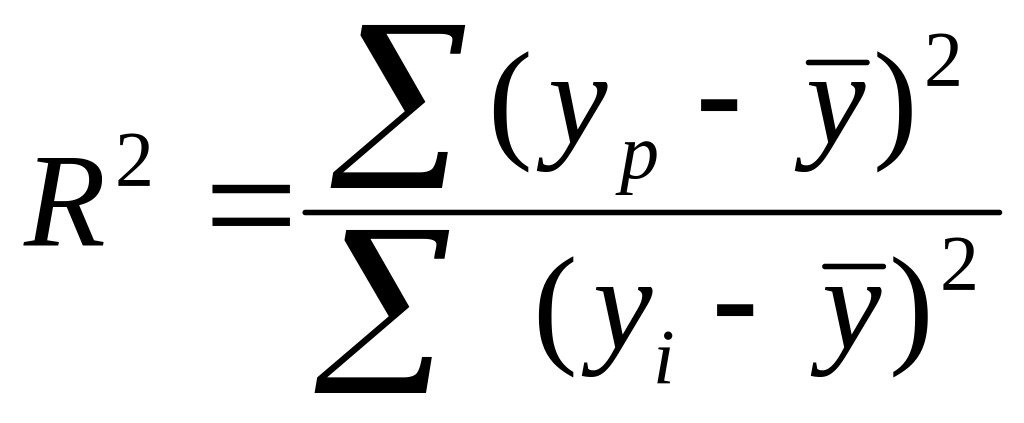 (8.1)
(8.1)
де yi – фактичне значення показника (вихідна інформація);
ур - вирівняне значення показника (розрахункові значення);
![]() -середнє значення показника.
-середнє значення показника.
Найкращою кривою вважається та, для якої коефіцієнт детермінації є найбільшим.
Визначення майбутнього значення показника здійснюється шляхом підстановки у рівняння тренда значення незалежної змінної t, яка відповідає величині горизонту прогнозування.
Слід зазначити, що екстраполяція тренда може бути застосована лише у тому випадку, якщо розвиток явища достатньо добре описується побудованим рівнянням і умови, які визначають тенденцію розвитку у минулому, не зазнають значних змін у майбутньому.
Таблиця 8.3 – Вихідні дані для прогнозування
Місяці t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
Значення показника dt |
9,66 |
10,53 |
11,98 |
12,09 |
13,27 |
14,99 |
15,21 |
16,05 |
17,98 |
18,37 |
Для визначення прогнозу за допомогою трендової лінії слід спочатку зобразити вихідні дані на графіку у вигляді діаграми розсіювання. Для цього слід скористатись майстром діаграм, вибравши вид діаграми - точкова. Далі, використовуючи меню "Діаграма", що з’являється на панелі інструментів при виділенні отриманої діаграми, слід вибрати функцію додавання лінії тренду. По черзі, вибираючи різні види ліній тренду та на вкладці "параметри лінії тренду", задавши функції, що дозволяють показувати рівняння регресії та значення коефіцієнта детермінації на діаграмі, отримаємо наступні результати регресійного вирівнювання.
Також, щоб зобразити на графіку прогнозні значення необхідно на вкладці "параметри лінії тренду" в полі Вперед ввести кількість бажаних періодів, протягом яких лінія тренду і буде продовжуватись вперед.
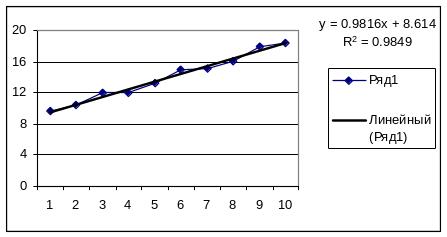
Рисунок 8.1 - Результат регресійного вирівнювання за лінійною залежністю
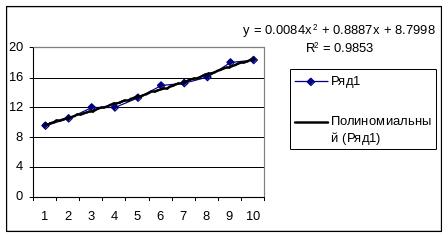
Рисунок 8.2 - Результат регресійного вирівнювання за поліноміальною залежністю
Отже, даний ряд динаміки найкраще описує поліноміальна залежність, оскільки коефіцієнт детермінації R2=0,9853 приймає для цієї залежності максимальне значення з трьох розрахованих.
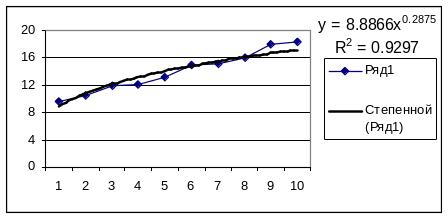
Рисунок 8.3 - Результат регресійного вирівнювання за степеневою залежністю
За виведеним рівнянням поліноміальної залежності y=0,0084х2+0,8887х+8,7998 розрахуємо значення показника на наступні періоди:
у11=0,0084*112+0,8887*11+8,7998=19,59
y12=0,0084*122+0,8887*12+8,7998=20,67
Отже, у 11 періоді значення показника становитиме 19,59, у 12 періоді - 20,67.
Метод середньої ковзання
При використанні методу ковзкого середнього (плинної середньої) прогноз будь-якого періоду є не що інше, як отримання середнього показника декількох результатів наглядів тимчасового ряду.
Таким чином методом прогнозування майбутнього значення показника являється усереднене m його минулих значень. Формально його можна визначити так:
 , (8.2)
, (8.2)
Cередня ковзання порядку L - це часовий ряд, що складається з середніх арифметичних L сусідніх значень Yi. Як L вибирається непарне число, зазвичай 3, 5 або 7, і ці схеми називають триточковою, п'ятиточковою і т.д.
При L=3 середнє розраховується по трьох значеннях Yi, одне з яких відноситься до минулого періоду, одне - до шуканого і одне - до майбутнього. Оскільки для i = 1 не існує минулого значення, то в перший період неможливо розрахувати значення mi. Для i = 2 згладжене значення буде середнім арифметичним Yi при i = 1, 2, 3; для i = 3 середнє арифметичне береться для 2-го, 3-го і 4-го значень Yi; у останній точці початкового інтервалу ковзаюче середнє також неможливо розрахувати через відсутність майбутнього значення по відношенню до того, що розраховується (таблиця 8.3). Отже, для того, щоб почати процес середнього ковзання, необхідно мати в запасі n-1 минулих значень спостережень.
Таблиця 8.3 - Прогнозування методом середньої ковзання
A |
B |
C |
D |
E |
F |
1 |
Місяці (t) |
Значення показника (dt) |
Прогноз Ut L=3 |
Прогноз Ut L=5 |
Прогноз Ut L=7 |
2 |
1 |
8.71 |
- |
- |
- |
3 |
2 |
7.64 |
7.75 |
- |
- |
4 |
3 |
6.9 |
6.94 |
7.16 |
- |
5 |
4 |
6.28 |
6.49 |
6.33 |
6.33 |
6 |
5 |
6.28 |
5.7 |
5.59 |
5.56 |
7 |
6 |
4.55 |
4.92 |
4.87 |
4.93 |
8 |
7 |
3.94 |
3.93 |
4.26 |
4.25 |
9 |
8 |
3.3 |
3.49 |
3.43 |
- |
10 |
9 |
3.23 |
2.89 |
- |
- |
11 |
10 |
2.15 |
- |
- |
- |
Значення прогнозу розраховується таким чином:
клітинка D3 - формула матиме вигляд (С2+С3+С4) / 3
D4 = (С3+С4+С5) / 3 і т.д.
E4 = (С2+С3+С4+С5+С6) / 5 і т.д.
F5 = (С2+С3+С4+С5+С6+С7+С8) / 7 і т.д.
Для розрахунку прогнозу за методом середньої ковзання також можна скористатись функцією Аналіз даних, що міститься в меню Сервіс програми Excel. (Для встановлення даної функції слід вибрати Сервіс - Надбудови - Пакет аналізу). У діалоговому вікні Аналіз даних, в якому містяться всі доступні функції аналізу даних слід вибрати інструмент аналізу - ковзне середнє (скользящее среднее), що дозволяє визначити середню ковзання при заданих L=3,5 чи 7.
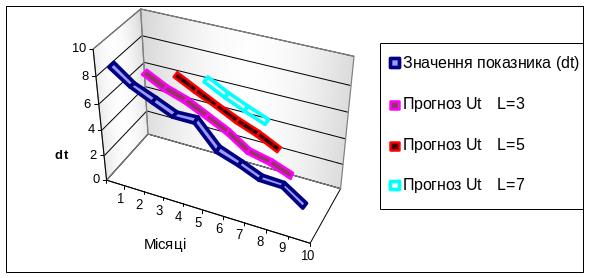
Рисунок 8.4 - Прогнозування методом середньої ковзання
Приклад. Розрахувати плиннi середнi, використовуючи данi про денний випуск продукцiї. Результати розрахункiв звести в таблицю.
Для будь-якого iнтервалу згладжування k плинну середню розраховуємо за формулою:
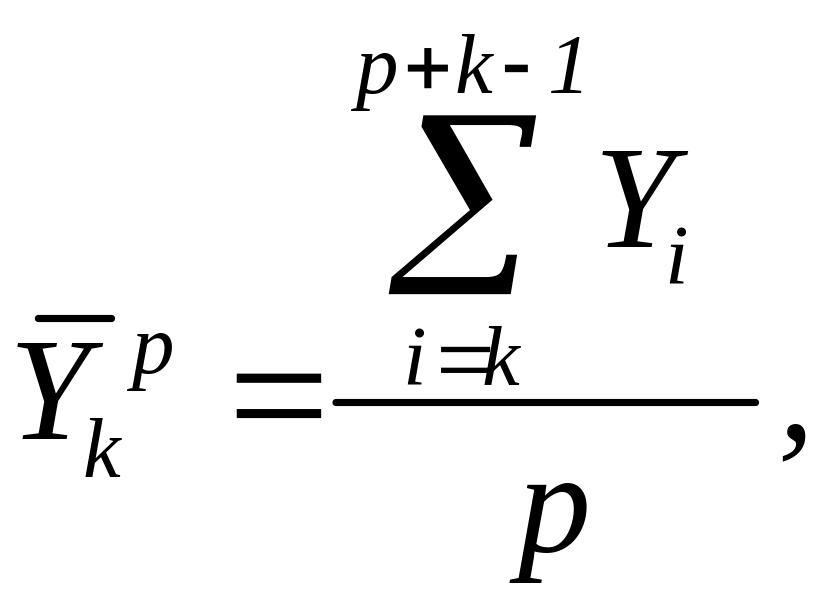 (8.3)
(8.3)
де
![]() - i-й
рiвень
ряду динамiки
(i=1,
2, 3, ..., n);
- i-й
рiвень
ряду динамiки
(i=1,
2, 3, ..., n);
![]() - k -а плинна середня при iнтервалi
згладжування р [k=1, 2,...,
n-(n-1)].
- k -а плинна середня при iнтервалi
згладжування р [k=1, 2,...,
n-(n-1)].
Наприклад, для р=3 четверта плинна дорiвнюватиме
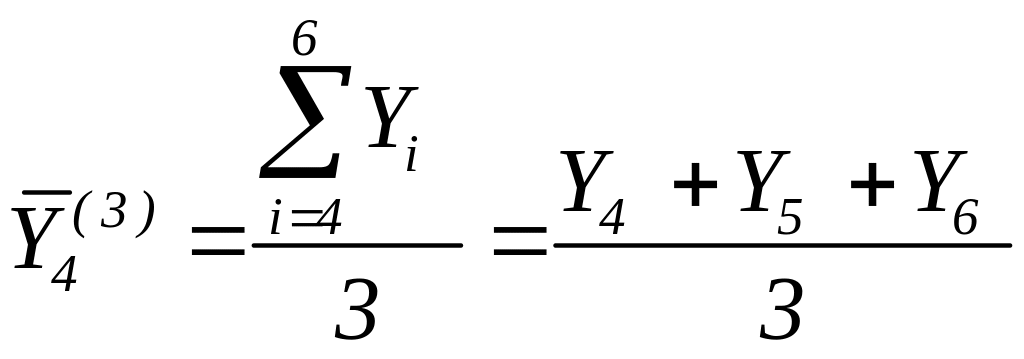 ,
(8.4)
,
(8.4)
а остання плинна середня
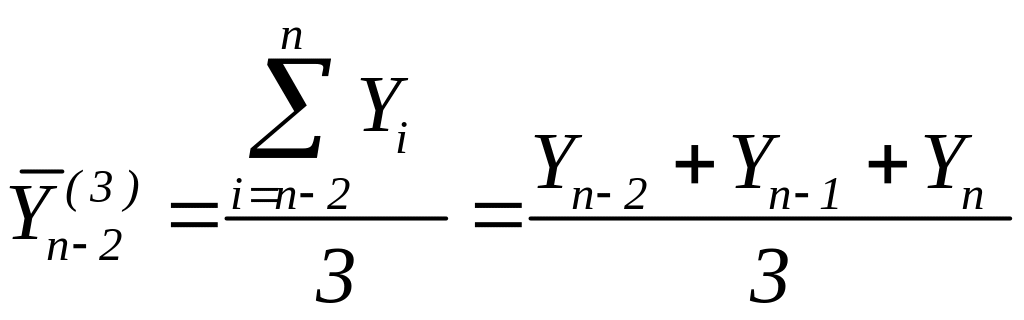 ,
(8.5)
,
(8.5)
У таблиці 8.4 наведено плиннi середнi триденна й п’ятиденна. Вихiдний та зрiвняний динамiчнi ряди (за допомогою п’ятиденної плинної середньої) зображенi на рис.8.5.
Таблиця 8.4 - Згладжування ряду динамiки за допомогою плинної середньої
Показники |
Робочі дні |
|||||||||||||||
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
||
1.Обсяг виробництва продукції, тис.грн. |
58 |
55 |
56 |
70 |
69 |
74 |
72 |
76 |
75 |
82 |
78 |
84 |
81 |
89 |
91 |
|
2. Плинна сумма, тис. грн.. |
3-денна |
- |
169 |
181 |
195 |
213 |
214 |
222 |
223 |
233 |
235 |
244 |
243 |
254 |
261 |
- |
5-денна |
- |
- |
308 |
324 |
341 |
361 |
366 |
378 |
383 |
395 |
400 |
414 |
423 |
- |
- |
|
3. Плинна середня, тис.грн. |
3-денна |
- |
56,3 |
60,3 |
65,0 |
71,0 |
71,3 |
77,0 |
75,7 |
82,7 |
76,7 |
84,3 |
80,7 |
67,7 |
87 |
- |
5-денна |
- |
- |
61,6 |
64,8 |
68,2 |
722 |
73,2 |
75,6 |
76,6 |
79,0 |
80,0 |
82,8 |
84,6 |
- |
- |
|

Рисунок 8.5 ‑ Графiк виробництва продукцii
Метод простої експоненціально зваженої середньої (ПЕВС)
Даний метод використовується для короткострокового прогнозування шляхом розрахунку зваженої середньої поточних даних і даних минулих періодів та найчастіше застосовується для прогнозування попиту.
Формула Брауна або основне рівняння, що визначає просту експоненціально зважену середню наступне:
![]() ,
(8.6)
,
(8.6)
де Ut - прогноз на поточний період
dt - фактичне значення показника за аналогічний минулий період
- константа згладжування (0<<1)
Значення константи згладжування вибирає укладач прогнозу. Якщо величина константи згладжування вибирається рівною нулю, то прогноз на наступний період буде рівний прогнозу на поточний період, тобто прогноз повністю заснований на даних минулого періоду і не враховує найпізніші із наявних фактичних даних.
З другого боку, якщо константа приймається рівною 1, то даним минулих періодів не приділяється ніякого значення, і прогноз повністю залежить від фактичних значень показника на поточний період. Такий підхід приймається, якщо йдеться про відкриття нового супермаркету, - зрозуміло, що в подібному випадку дані минулих періодів для складання прогнозу відсутні.
Аналітики більшості фірм при обробці рядів використовують "свої" традиційні значення . Так в аналітичному відділі Kodak традиційно використовують значення 0.38, а на фірмі Ford Motors - 0.28 або 0.3. Взагалі для фірм, що динамічно розвиваються, і ринків характерні вищі значення константи згладжування , чим для консервативних компаній і стабільних ринків. Проте реальність така, що вибір коефіцієнта був і залишиться украй суб'єктивним.
Якщо записати значення прогнозу для періоду t=1, то отримаємо:
![]() , (8.7)
, (8.7)
де U0 – початковий рівень згладжування, який можна задати наступними методами:
1)
![]() - приймається рівним першому значенню
із ряду фактичних значень,
- приймається рівним першому значенню
із ряду фактичних значень,
2)
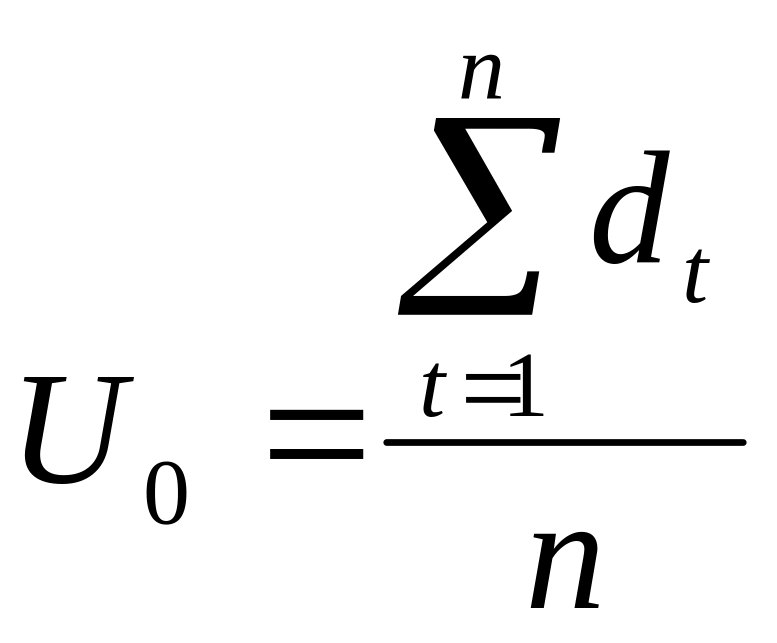 - середнє фактичних значень ряду,
- середнє фактичних значень ряду,
3)
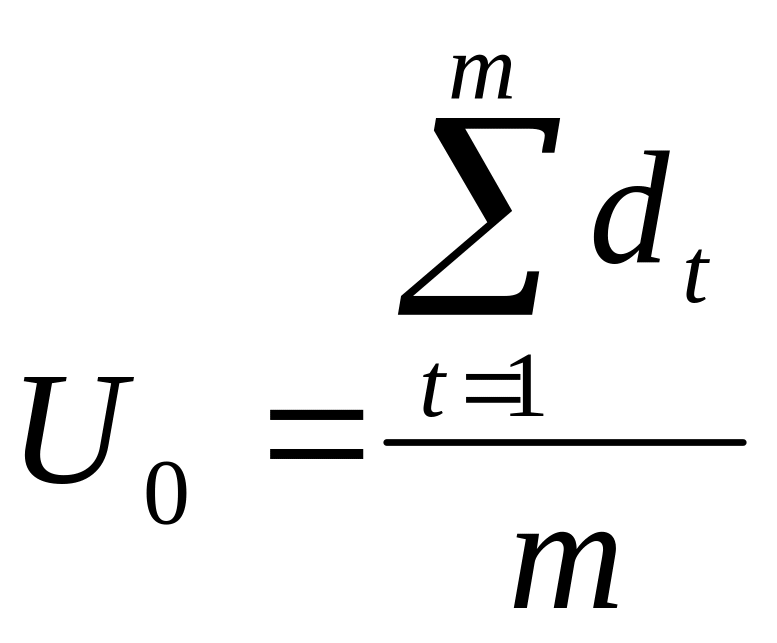 -
середнє m фактичних значень ряду,
-
середнє m фактичних значень ряду,
4)
![]() - експертна оцінка.
- експертна оцінка.
Експоненціально зважена середня має ряд переваг перед традиційною середньою ковзання.
для побудови прогнозу по експоненціально зваженому середньому необхідно задати лише початкову оцінку прогнозу; подальше прогнозування можливе одразу ж при поступленні свіжих даних. Таким чином, немає необхідності заново будувати процедуру обчислення прогнозу, як це було необхідно по методу середньої ковзання.
2) чутливість експоненціально зваженого середнього з метою підвищення адекватності прогностичної системи може бути в будь-який момент часу змінена шляхом зміни величини α (чутливість прогнозу – це здатність прогнозу реагувати на появу нових факторів). Чим вище значення α, тим вище чутливість середнього; чим нижче α, тим стійкішою стає експоненціально зважена середня. Чутливість методу середньої ковзання залежить від довжини ряду, а чутливість методу експоненціального згладжування – тільки від α.
Розрахунок прогнозу також можна здійснити використовуючи функцію Експоненціальне згладжування, що міститься в меню Сервіс - Аналіз даних.
Основна ідея методу ПЕВС полягає в тому, що кожен новий прогноз виходить за допомогою переміщення попереднього прогнозу в напрямі, який дав би кращі результати в порівнянні зі старим прогнозом. Константа згладжування є величиною, що самокоректується. Іншими словами, кожен новий прогноз є сумою попереднього прогнозу і поправочного коефіцієнту, який і пересуває новий прогноз в такому напрямі, що робить попередній результат більш точним.
Таблиця 8.5 - Прогнозування за методом ПЕВС при =0,6 та U0 = d1 (приклад розрахунку в MS Excel)
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
1 |
Місяці (t) |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
2 |
Значення показника (dt) |
8,71 |
7,64 |
6,90 |
6,28 |
6,28 |
4,55 |
3,94 |
3,3 |
3,23 |
2,15 |
3 |
a |
5,23 |
4,58 |
4,14 |
3,77 |
3,77 |
2,73 |
2,36 |
1,98 |
1,94 |
1,29 |
4 |
(1-a)Ut-1 |
3 |
3 |
3,23 |
2,95 |
2,69 |
2,58 |
2,12 |
1,80 |
1,51 |
1,38 |
5 |
Прогноз (Ut) |
8 |
8,07 |
7,37 |
6,71 |
6,45 |
5,31 |
4,49 |
3,78 |
3,45 |
2,67 |
 *dt
*dt ,48
,48 ,48
,48 ,71
,71
=0,6*С2
=(1-0,6)*С 5
=С3 + С4
=(1-0,6)*U0
Згладжування є дуже корисним в тих випадках, коли у тимчасовому ряді спостерігаються істотні відмінності в рівнях даних. Методи прогнозування, що використовують константу згладжування враховують ефекти стрибка функції набагато краще, ніж способи, що використовують регресивний аналіз.
Моделювання сезонних коливань економічних явищ рядами фур’є
Значна частина економічних явищ, таких як попит на товари та послуги, пасажиропотоки, виробництво в цукровій та консервній промисловості носить сезонний характер.
Для аналізу та прогнозування таких сезонних явищ використовують ряд Фур’є, який представляє сезонне явище у вигляді гармоніки.
У загальному вигляді ряд Фур’є можна записати так:
![]() ,
(8.8)
,
(8.8)
де
![]() ,
,
![]() ,
,
![]() –
параметри моделі,
–
параметри моделі,
t – фактор часу,
k – порядковий номер гармоніки,
m – кількість гармонік.
В економетричних дослідженнях кількість гармонік ряду Фур’є приймають не більшою 4, а потім визначають, яка із гармонік найбільш адекватно описує сезонні коливання економічних явищ.
Параметри ряду Фур’є , , визначаються методом найменших квадратів. Формули для розрахунку цих параметрів мають вигляд:
![]() ,
,![]() ,
,
![]() , (8.9)
, (8.9)
де n – кількість періодів часу, за які розглядається явище (місяців, днів, кварталів, років).
Для побудови економетричної моделі необхідно зробити перехід для фактора часу від натурального масштабу до радіанного або градусного. Цей перехід можна здійснити за формулою:
![]() ,
(8.10)
,
(8.10)
де n – кількість спостережень (або кількість інтервалів часу, за який аналізується сезонне явище), ti – фактор часу у радіанному (градусному) вираженні, n`i– натуральний ряд чисел від 0 до n-1 (0,1,2,…,n-1).
Запишемо місяці у радіанній формі (таблиця 8.6).
Таблиця 8.6 – Радіанна форма місяців
січень |
0 |
|
липень |
|
лютий |
|
|
серпень |
|
березень |
|
|
вересень |
|
квітень |
|
|
жовтень |
|
травень |
|
|
листопад |
|
червень |
|
|
грудень |
|
Для визначення параметрів моделі
та
необхідно
скласти таблицю значень тригонометричних
функцій
![]() (табл.
8.8).
(табл.
8.8).
Таблиця 8.8 – Значення тригонометричних функцій
|
|
|
|
|
|
1 |
0 |
1 |
1 |
0 |
0 |
2 |
|
0,866 |
0,5 |
0,5 |
0,866 |
3 |
|
0,5 |
-0,5 |
0,866 |
0,866 |
4 |
|
0 |
-1 |
1 |
0 |
5 |
|
-0,5 |
-0,5 |
0,866 |
-0,866 |
6 |
|
-0,866 |
0,5 |
0,5 |
-0,866 |
7 |
|
-1 |
1 |
0 |
0 |
8 |
|
-0,866 |
0,5 |
-0,5 |
0,866 |
9 |
|
-0,5 |
-0,5 |
-0,866 |
0,866 |
10 |
|
0 |
-1 |
-1 |
0 |
11 |
|
0,5 |
-0,5 |
-0,866 |
-0,866 |
12 |
|
0,866 |
0,5 |
-0,5 |
-0,866 |
Приклад. У таблиці 8.9 (стовп. 1,3) наведено статистичні дані реалізації по місяцях. Описати сезонні коливання реалізації зимової одежі рядами Фур’є та вибрати гармоніку, яка найбільш адекватно описує ці сезонні коливання.
Розв’язання. За статистичними даними визначимо параметри моделі для першої гармоніки. Маємо
![]()
![]() ;
;
![]() .
.
Запишемо ряд Фур’є для першої гармоніки:
![]() .
.
Знаходимо теоретичні значення
![]() (таблиця 8.9). Замість значень
(таблиця 8.9). Замість значень
![]() та
та
![]() у
ряд Фур’є підставимо їх значення із
таблиці 8.8.
у
ряд Фур’є підставимо їх значення із
таблиці 8.8.
Розраховуємо тісноту зв’язку (кореляційне
відношення) для першої гармоніки.
Для цього потрібно сформувати наступні
стовпці:
![]() ,
,
![]() .
.
Тоді кореляційне відношення для 1-ої гармоніки
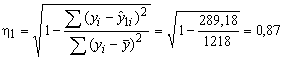 .
.
Розрахуємо параметри ряду Фур’є по
другій гармоніці; для цього необхідно
сформувати два стовпчики:
![]() та
та
![]() .
.
Таким чином, маємо дані для розрахунку
параметрів
![]() та
та
![]() :
:
![]()
![]() .
.
Ряд Фур’є для другої гармоніки матиме вигляд:
![]() .
.
Визначаємо тісноту зв’язку для другої гармоніки
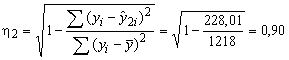 .
.
Оскільки
![]() ,
то ряд Фур’є по другій гармоніці більш
адекватно описує сезонні коливання
явища.
,
то ряд Фур’є по другій гармоніці більш
адекватно описує сезонні коливання
явища.
Будуємо графік сезонних коливань продажу (рис. 8.6).
Рисунок 8.6 – Графік
сезонних коливань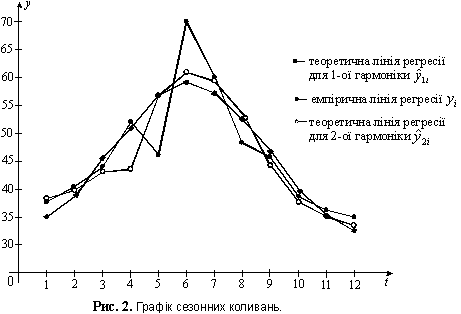
Таблиця 8.9 - Статистичні дані реалізації по місяцях
-
Місяці
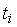 ,
рад.
,
рад.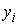
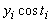
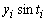
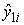
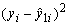

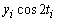

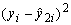
січень
0
37
37,000
0,000
34,96
4,161
81
37
0,000
37,88
0,769
лютий
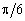
40
34,641
20,000
39,31
0,479
36
20
34,641
39,64
0,128
березень

44
22,000
38,105
45,45
2,101
4
-22
38,105
42,87
1,286
квітень
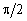
52
0,000
52,000
51,74
0,069
36
-52
0,000
48,82
10,104
травень
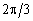
46
-23,000
39,837
56,49
110,023
0
-23
-39,837
56,16
103,142
червень
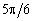
70
-60,622
35,000
58,43
133,869
576
35
-60,622
61,01
80,764
липень
60
-60,000
0,000
57,04
8,762
196
60
0,000
59,96
0,002
серпень
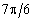
48
-41,569
-24,000
52,69
22,013
4
24
41,569
53,03
25,252
вересень

46
-23,000
-39,837
46,55
0,303
0
-23
39,837
43,97
4,132
жовтень
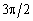
38
0,000
-38,000
40,26
5,116
64
-38
0,000
37,35
0,429
листопад
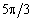
36
18,000
-31,177
35,51
0,239
100
-18
-31,177
35,18
0,677
грудень
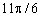
35
30,311
-17,500
33,57
2,044
121
17,5
-30,311
36,15
1,331
552
-66,239
34,428
552,0
289,180
1218
17,5
-7,794
552,0
228,014
Оцінка якості моделей прогнозування (перевірка їх адекватності і оцінка точності)
Заключним етапом розробки прогнозу є верифікація, яка являється процедурою оцінки достовірності, точності чи обґрунтованості прогнозу.
Вибір показників точності прогнозу залежить від об’єкта прогнозування і тих задач, які ставить перед собою дослідник у відношенні точності прогнозу.
Для оцінки отриманих значень прогнозу можуть бути використані такі показники:
сума квадратів похибок і середній квадрат похибки;
середня процентна похибка і середня похибка;
середня абсолютна процентна похибка;
стандартне відхилення.
Сума квадратів похибок обчислюється за формулою:
![]() (8.11)
(8.11)
де
![]() похибка прогнозу
визначена як різниця
між фактичним значенням dt
і прогнозом ft.
похибка прогнозу
визначена як різниця
між фактичним значенням dt
і прогнозом ft.
Середній квадрат похибки розраховується за формулою:
![]() або
або
![]() (8.12)
(8.12)
Чим меншим є СрКП, тим точнішим є метод прогнозування
Середня процентна похибка (СПП) і середня похибка (СП) – показники зміщеності прогнозу. При умові, що втрати при прогнозуванні, пов’язані із завищенням фактичного майбутнього значення, урівноважуються заниженням, ідеальний прогноз повинен бути незміщеним, і обидві міри повинні прямувати до нуля. З точки зору практики, бажано, щоб ці показники були достатньо малі. Найбільш популярний відносний показник зміщеності - середня процентна похибка обчислюється так:
![]() (8.13)
(8.13)
Абсолютне значення СПП не повинно перевищувати 5%, тобто при умові, що |СПП| < 5%, то прогноз вважається не зміщеним.
Середня похибка вже не являється відносним показником, а характеризує ступінь зміщеності прогнозу і розраховується за формулою:
![]() (8.14)
(8.14)
Середня абсолютна процентна похибка - це середнє абсолютних значень похибок прогнозів, виражених в процентах відносно фактичних значень показника. Таким чином, середня абсолютна процентна похибка
![]() (8.15)
(8.15)
Показник САПП, як правило, використовується при порівнянні точності прогнозів різнорідних об’єктів прогнозування, оскільки цей показник характеризує відносну точність прогнозу. Типові значення САПП і їх інтерпретація показані в таблиці 8.10.
Таблиця 8.10 - Інтерпретація типових значень САПП
САПП, % |
Інтерпретація |
САПП < 10 |
висока точність |
10 < САПП < 20 |
добра точність |
20 < САПП < 50 |
задовільна точність |
САПП > 50 |
незадовільна точність |
Розсіювання значень деякої змінної навколо середнього, як правило, вимірюють стандартним відхиленням. Для методу експоненціально зваженого середнього даний показник оцінюється за наступним алгоритмом:
обчислюємо похибку прогнозу
![]()
обчислюємо значення середнього абсолютного відхилення САВt
![]() (8.16)
(8.16)
причому початкове значення
![]()
обчислюємо стандартне відхилення за формулою
σt=КпрСАВt (8.17)
де Кпр – константа пропорційності, взята із інтервалу 1,2 – 1,3.
Збіг прогнозних значень з фактичними даними є малоймовірним. Тому в прогнозуванні використовують інтервальні значення прогнозу у вигляді довірчого інтервалу - максимальне і мінімальне значення.
При відносно малому горизонті прогнозування з достатньою ступінню впевненості можна стверджувати, що майбутнє значення прогнозованого показника буде знаходитись в наступному інтервалі:
від fмін = ft – σt до fмакс = ft + σt при ймовірності 75%
від fмін = ft – 2σt до fмакс = ft + 2σt при ймовірності 90%
від fмін = ft – 3σt до fмакс = ft + 3σt при ймовірності 95%.
Наявність довірчого інтервалу дозволяє розробити альтернативні варіанти стратегії дій підприємства з врахуванням можливих ситуацій на ринку.
Для оцінки достовірності прогнозу використовують коефіцієнт Трігга, який обчислюється за формулою:
![]() (8.18)
(8.18)
де СВt – середнє відхилення
![]() (13.50)
(13.50)
СВ0=е1 або СВ0=еt/n
САВt - середнє абсолютне відхилення (формула 8.16)
Якщо розрахункове значення коефіцієнту Трігга більше табличного Tт, то прогноз є достовірним. При цьому показник обчислюється для кожного кроку окремо. Коефіцієнт показує міру адекватності прогнозу щодо досліджуваного процесу.
Таблиця 8.11 - Критичні значення коефіцієнту Трігга
Рівень довіри (ймовірність), % |
Критичне значення коефіцієнта Трігга
|
||||
=0,1 |
=0,2 |
=0,3 |
=0,4 |
=0,5 |
|
85 90 95 99 100 |
0,32 0,35 0,42 0,53 1,00 |
0,45 0,50 0,58 0,71 1,00 |
0,57 0,63 0,71 0,82 1,00 |
0,67 0,72 0,80 0,92 1,00 |
0,77 0,82 0,88 0,94 1,00 |
Допускається розрахунок
критичного значення коефіцієнту, якщо
<0,8
і відповідно Тт=1,1![]() (для
ймовірності Р=95%), Тт=1,65
(для
ймовірності Р=99%).
(для
ймовірності Р=95%), Тт=1,65
(для
ймовірності Р=99%).
Основні питання для самоперевірки
Опишіть процедуру прогнозування за середньою ковзання.
Опишіть процедуру прогнозування за простою експоненціальною взваженою середньою. Які її переваги перед середньо ковзання?
В чому полягає особливість оцінки комбінованих трендів?
Опишіть особливості моделювання сезонних явищ за допомогою рядів Фур’є.
За допомогою яких показників можна оцінити точність отриманого прогнозу? Наведіть формули розрахунку.
Опишіть процедуру оцінки адекватності прогнозу.
Перелік рекомендованих джерел
Економіко-математичне моделювання. Навчальний посібник / Ю.В.Брагін. – К.: УМКВО, 1990. – 196с.
Пономаренко О.І., Пономаренко В.О. Системні методи в економіці, менеджменті та бізнесі. – К.:Либідь, 1995 – 240с.
Андрейчиков А.В., Андрейчикова О.Н. Анализ, синтез и планирование решений в экономике. – М.: Финансы и статистика. – 2001. – 368с.
Чарковський В.М., Хвостіна І.М., Запухляк І.Б. Математичне моделювання в економіці. – Івано-Франківськ: «Факел», 2004. – 128с.
Побігун С.А., Боднарук І.Р., Даляк Н.А., Артем’єв В.В. Використання економетричних, економіко-математичних моделей і методів прогнозування в економічних розрахунках: Навч.посібник - Івано-Франківськ: Факел, 2009. - 208с.
Орлова И.В., Половников В.А. Экономико-математические методы и модели: компьютерное моделирование: Учеб.пособие. - М.: Вузовский учебник, 2009. - 365с.
Экономико-математические методы и прикладные модели: Учеб.пособие для вузов/В.В.Федосеев, А.Н.Гармаш, И.В.Орлова и др.; Под ред. В.В.Федосеева. - М.:ЮНИТИ-ДАНА, 2005. - 304с.
Вітлінський В.В., Наконечний С.І. Ризик у менеджменті. К.: ТОВ Борисфен-М.: - 1996. - 366с.
Вітлінський В.В., Наконечний С.І., Шарапов О.Д. Економічний ризик і методи його вимірювання: Підручник.К.:ІЗМН, 1196. - 400с.
Лук'яненко І., Краснікова Л. "Економетрика: підручник". - К.:"Знання", 1998р. - 493с. ;
Лук'яненко І., Краснікова Л."Економетрика - практикум з використанням компютера". - К.:"Знання", 1998р. - 217с.;
Толбатов Ю.А. "Економетрика: підручник". - К.:"Четверта хвиля", 1997р. - 318с.;